Canal实时同步MySQL数据至Kafka集群,安装部署
Posted 学而知之@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Canal实时同步MySQL数据至Kafka集群,安装部署相关的知识,希望对你有一定的参考价值。
一、前言
本集群基于Canal-Admin实现,并包括Canal-Admin部署流程。Canal-Admin由阿里官方提供,为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作。
二、安装环境准备
1、 Canal-Admin部署节点:
172.16.3.234:8089
2、 Zookpeer集群:
172.16.3.234:2181
172.16.3.235:2181
172.16.3.236:2181
3、 Kafka集群:
172.16.3.237:9092
172.16.3.239:9092
172.16.3.240:9092
4、Canal 集群(与ZK部署在相同的服务器):
172.16.3.234
172.16.3.235
172.16.3.236
5、 MySQL数据库信息:
数据库IP:172.16.3.70
6、 安装文件准备:
canal.admin-1.1.4.tar.gz
canal.deployer-1.1.4.tar.gz
下载地址:https://github.com/alibaba/canal/releases/tag/canal-1.1.4/
说明:Canal-Admin需要mysql存储配置信息,暂用测试库作为配置信息存储库*
7、 MySQL配置,开启binlog:
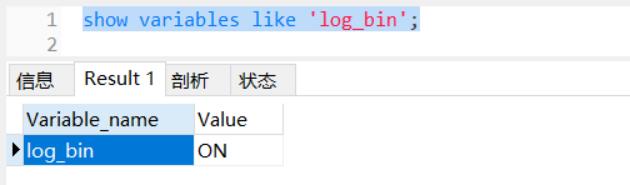
7.1 Mysql环境检查:
-- 是否开启用了日志
show variables like 'log_bin';
-- 怎样知道当前的日志
show master status;
-- 查看mysql binlog模式
show variables like 'binlog_format';
-- 获取binlog文件列表
show binary logs;
-- 查看当前正在写入的binlog文件
show master status\\G;
-- 查看指定binlog文件的内容
show binlog events in ‘mysql-bin.000002’
7.2 登录到数据库所在的服务器并编辑mysql配置文件/etc/my.cnf
vim /etc/my.cnf
[mysqld]
log_bin=mysql_bin ## 开启 binlog
binlog-format=Row ## 选择 ROW 模式
server-id=1 ## 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
注:三个配置必须全部填写,否则导致bingo数据读取不到
7.3 重启数据库
service mysqld restart;
7.4 数据库重启后, 测试 my.cnf 配置是否生效
show variables like 'binlog_format';

三、Canal-Admin安装配置
1、 Admin安装、配置
1.1 创建canal-admin 文件夹
mkdir /data/canal-admin
1.2 解压canal.admin-1.1.4.tar.gz安装包到 canal-admin
tar –zxvf canal.admin-1.1.4.tar.gz –C canal-admin
查看一下文件目录:

1.3 修改配置文件:application.ym
vim /data/canal-admin/conf/application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 172.16.3.70:3306 ## 保存配置信息的数据库IP及端口
database: canal_manager ## 保存配置信息的数据库名
username: root ## 登录数据库的用户名
password: ADuls2MuUt ## 登录数据的密码
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://$spring.datasource.address/$spring.datasource.database?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin ## 登录canal-admin 的用户名
adminPasswd: 123456 ## 登录canal-admin 的密码
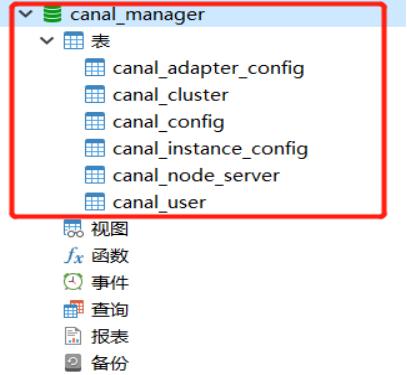
1.4 创建 保存配置信息的数据库
- 找到 /data/canal-admin/conf目录下的canal_manager.sql文件

- 进入数据库,将sql复制后直接执行,生成如下信息:
1.5 创建一个同步数据用的账户,并授权
CREATE USER canal IDENTIFIED BY ‘canal’;
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON . TO ‘canal’@’%’;
GRANT ALL PRIVILEGES ON . TO ‘canal’@’%’ ;
FLUSH PRIVILEGES;
1.6 启动canal-admin
cd /data/canal-admin/bin
sh startup.sh
1.7 打开浏览器输入:172.16.3.234:8089
用户名:admin
密码:123456
2、canal集群配置
2.1 点击集群管理,新建集群
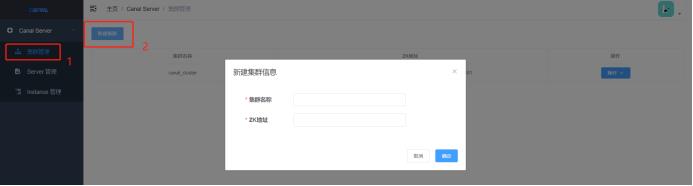
输入集群名称:canal_cluster (自定义)
输入ZK地址:
172.16.3.234:2181, 172.16.3.235:2181,172.16.3.236:2181
2.2 点击操作,选择主配置

对主配置进行更改,详细配置信息如下:canal.properties
#################################################
######### common argument #############
#################################################
# tcp bind ip
# canal server绑定的本地IP信息
canal.ip =
# canal server注册到外部zookeeper、admin的ip信息
# register ip to zookeeper
canal.register.ip =
# canal server提供socket服务的端口
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal数据端口订阅的ACL配置
canal.user = canal
canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
# admin管理指令链接端口
canal.admin.manager = 172.16.3.234:8089
canal.admin.port = 11110
canal.admin.user = admin
# admin管理指令链接的ACL配置 密码默认值为admin的密文
canal.admin.passwd = 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
# canal server链接zookeeper集群的链接信息
canal.zkServers = 172.16.3.234:2181,172.16.3.235:2181,172.16.3.236:2181
# flush data to zk
# canal持久化数据到zookeeper上的更新频率,单位毫秒
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = kafka
# flush meta cursor/parse position to file
canal.file.data.dir = $canal.conf.dir
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
# canal内存store中可缓存buffer记录数,需要为2的指数
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
# 内存记录的单位大小,默认1KB,和buffer.size组合决定最终的内存使用大小
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
# canal内存store中数据缓存模式
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
# 是否开启心跳检查
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
# canal发生mysql切换时,在新的mysql库上查找binlog时需要往前查找的时间,单位秒
canal.instance.fallbackIntervalInSeconds = 60
# network config
# 网络链接参数
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
# ddl语句是否单独一个batch返回
canal.instance.get.ddl.isolation = false
# parallel parser config
# 是否开启binlog并行解析模式
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
# binlog并行解析的异步ringbuffer队列
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
# 是否开启tablemeta的tsdb能力
canal.instance.tsdb.enable = true
# 主要针对h2-tsdb.xml时对应h2文件的存放目录
canal.instance.tsdb.dir = $canal.file.data.dir:../conf/$canal.instance.destination:
# jdbc url的配置
canal.instance.tsdb.url = jdbc:h2:$canal.instance.tsdb.dir/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
#################################################
######### destinations #############
######### 配置instance列表定义 #############
#################################################
#当前server上部署的instance列表
canal.destinations = example
# conf root dir 目录所在的路径
canal.conf.dir = ../conf/MySQL-1
# auto scan instance dir add/remove and start/stop instance 开启instance自动扫描
canal.auto.scan = true
# instance自动扫描的间隔时间,单位秒
canal.auto.scan.interval = 5
# 全局的tsdb配置方式的组件文件
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
# 全局配置加载方式
canal.instance.global.mode = spring
canal.instance.global.lazy = false
# 全局的manager配置方式的链接信息
canal.instance.global.manager.address = $canal.admin.manager
# 全局的spring配置方式的组件文件
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ #############
##################################################
canal.mq.servers = 172.16.3.237:9092,172.16.3.239:9092,172.16.3.240:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = test
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace
#canal.mq.namespace =
##################################################
######### Kafka Kerberos Info #############
##################################################
canal.mq.kafka.kerberos.enable = false
canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf"
canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"
3、server安装、配置
3.1 安装、配置
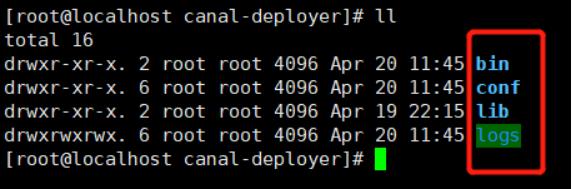
创建canal-deployer文件夹, 将canal.deployer-1.1.4.tar.gz解压到该目录
mkdir canal-deployer
tar –zxvf canal.deployer-1.1.4.tar.gz –C canal-deployer
查看目录
3.2 更改各个节点的配置文件
说明:由于集群基于canal-admin搭建集群,所以各个节点配置时需要按照canal_local.properties的格式进行配置
将canal_local.properties文件内容覆盖到canal.properties,并编辑
cd /data/canal-deployer/conf/
1、复制并覆盖原文件内容
cat canal_local.properties > canal.properties
2、修改配置文件
vim canal.properties
# register ip
canal.register.ip = 172.16.3.234 ## 当前服务器的IP
# canal admin config
canal.admin.manager = 172.16.3.234:8089 ## canal admin的IP和端口
canal.admin.port = 11110
canal.admin.user = admin ## 登录名
## 登录密码 ‘123456’ 的铭文
canal.admin.passwd = 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster = canal_cluster ## 前面创建的集群名称
注:铭文密码可以通过MySQL进行查询:
select password('123456')
3.3 将canal文件夹分别发送到 另外2台服务器
scp -r canal-deployer root@172.16.3.235:/data
scp -r canal-deployer root@172.16.3.236:/data
-- 输入密码:********(根据自己情况)
3.4 修改canal.properties中canal.register.ip参数为各自服务器ip,其余参数保持不变
canal.register.ip = 172.16.3.235
canal.register.ip = 172.16.3.236
3.5 分别启动三台服务器上的canal服务
cd /data/canal-deployer/bin/
sh startup.sh
3.6 刷新浏览器,点击server管理,发现已自动加入三个实例

四、instance安装、配置
注:根据实际表创建相应的任务
任务说明:将mysql下canal数据库中表canal_to_kafka表中数据实时同步到kafka中,前提需先创建好topic:ODS_MYSQL_CONNECT_T1(名称自定义)
bin/kafka-topics.sh --create --zookeeper 172.16.3.234:2181, 172.16.3.235:2181, 172.16.3.236:2181 --topic ODS_MYSQL_CONNECT_T1 --replication-factor 3 --partitions 3
4.1 创建instance
点击instance管理,新建instance,输入instance名称ODS_MYSQL_TOPIC,选择test集群,点击后面的载入模板,并修改

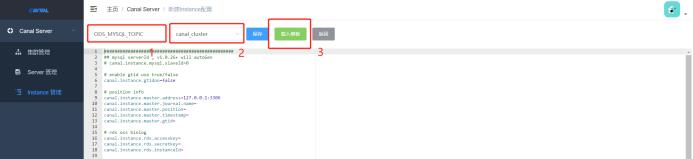
需要修改的配置信息:
# position info
canal.instance.master.address=172.16.3.70:3306 ## 数据库IP:端口号
# username/password
canal.instance.dbUsername=root ## 数据库登录名
canal.instance.dbPassword=ADuls2MuUt ## 数据库登录密码
# table regex
canal.instance.filter.regex=canal.canal_to_kafka ## 库名.表名
# mq config
canal.mq.topic=ODS_MYSQL_CONNECT_T1 ## kafka topic名
canal.mq.partitionsNum=3 ## topic分区数
canal.mq.partitionHash=canal.canal_to_kafka:id ## 数据库名.表名.主键
4.2 查看instance

instance 已正常启动
4.3 验证数据
4.3.1 打开kafka 相应的Topic进行消费 :
bin/kafka-console-consumer.sh --bootstrap-server 172.16.3.237:9092,172.16.3.239:9092,172.16.3.240:9092 --topic ODS_MYSQL_CONNECT_T1 --from-beginning
4.3.2 修改connect库中表canal_to_kafka的数据,发现kafka控制台已打印出相应修改的数据,实时同步数据成功

五、问题汇总
5.1 启动顺序问题
首先canal的服务需要去canal-admin上去读取配置文件,所以canal-admin需要先启动,就是要先有UI界面,然后再启动canal服务
5.2 元数据问题
在主配置里面canal.instance.global.spring.xml这个配置如果选择的是:
file-instance.xml(一般是单机模式)元数据保存在conf/实例/instance.xml
default-instance.xnl (为集群模式)元数据保存在zookeeper里面/otter/canal/destinations (需要配置zookeeper地址)
5.3 zookeeper改变
如果主配置的zookeeper地址改变了,需要修改集群的zookeeper和主配置的canal.zkServers参数,最好同时删除conf目录下的所有实例和zookeeper里面保存的所有实例。最后重启canal-admin,再重启canal服务
六、写在最后
本文主要阐述了canal集群的搭建,兄弟们在实操过程中,如果遇到任何问题都可以直接私信,老弟随时恭候着。另外欢迎各位兄弟关注我的公*号,定时分享一线互联网大厂最新技术资料,一起探讨、进步~

以上是关于Canal实时同步MySQL数据至Kafka集群,安装部署的主要内容,如果未能解决你的问题,请参考以下文章