知识图谱知识表示
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识图谱知识表示相关的知识,希望对你有一定的参考价值。
【知识图谱】知识表示
前言

提纲:
- 概述
- 一阶谓词逻辑表示法
- 产生式规则表示法
- 框架表示法
- 脚本表示法
- 语义网表示法
- 知识图谱中的知识表示
- 分布式知识表示
- 本章小结
1. 概述
知识定义
-
Feigenbaum
知识是经过削减、塑造、解释和转换的信息。简单地说, 知识是经过加工的信息。 -
Bernstein
知识是由特定领域的描述、关系和过程组成的。 -
Hayes-Roth
知识是事实、信念和启发式规则。从知识库的观点看,知识是某领域中所涉及的各有关方面的一种符号表示。
知识分类
-
陈述性知识 (declarative knowledge):用于描述领域内有关概念、事实、事物的属性和状态等。
- 太阳从东方升起
- 一年有春夏秋冬四个季节
-
过程性知识 (procedural knowledge): 用于指出如何处理与领域相关的信息,以求得问题的解。
- 菜谱中的炒菜步骤
- 如果信道畅通,请发绿色信号
-
元知识 (meta knowledge):关于知识的知识,包括怎样使用规则、解释规则、校验规则、解释程序结构等知识。
知识表示
知识表示:把人类知识表示成机器能处理的数据结构。对
知识进行表示的过程就是把知识编码成某种数据结构的过
程。
知识表示方法:
- 陈述性知识表示:将知识表示与知识的运用分开处理,在知识表示时,并不涉及如何运用知识的问题,是一种静态的描述方法。
- 过程性知识表示:将知识表示与知识的运用相结合,知识寓于程序中,是一种动态的描述方法。
知识表示准则
- 表示知识的范围是否广泛
- 是否适于推理
- 是否适于加入启发信息
- 是否适于计算机处理
- 是否有高效的求解算法
- 陈述性表示还是过程性表示
- 能否表示不精确知识
- 能否在同一层次上和不同层次上模块化
- 知识和元知识能否用统一的形式表示
- 表示方法是否自然
2. 一阶谓词逻辑表示法
基本概念:命题与联结词
一阶谓词逻辑是最早用在人工智能领域的知识表示方法之一。它以数理逻辑为基础,是到目前为止能够表达人类思维和推理的一种最精确的形式语言。其表现方式和人类自然语言也非常接近,容易为计算机理解和操作, 并支持精确推理。
命题 (proposition):具有真假意义的陈述句。
- 太阳从东方升起
- 一年有春夏秋冬四个季节
逻辑联结词 (logical connective):用于将多个原子命题
组合成复合命题。
- ¬:否定联结词,¬𝑃表示对原命题的否定。
- ∨:析取联结词,𝑃 ∨ 𝑄表示两个命题存在“或”的关系。
- ∧:合取联结词,𝑃 ∧ 𝑄表示两个命题存在“与”的关系。
- →:蕴含联结词,𝑃 → 𝑄表示“如果𝑃,则𝑄”。
- ↔:等价联结词,𝑃 ↔ 𝑄表示“𝑃当且仅当𝑄”。
复合命题与原子命题的真值关系表

基本概念:个体词、谓词与量词
个体词:领域内可以独立存在的具体或抽象的客体。
- 太阳从东方升起:太阳
- 小王与小张同岁:小王、小张
在谓词逻辑中,个体可以是常量也可以是变量(变元)。
- 个体常量:表示具体的或特定的个体。
- 个体变量:表示抽象的或泛指的个体。
- 个体域(论域):个体变量的取值范围,可以是有限集合,也可以是无穷集合。
谓词(predicate):用来刻画个体性质以及个体之间相
互关系的词。
- 命题:𝑥是有理数
𝑥是个体变量,“…是有理数”是谓词,记为Rational,命题符号:Rational(𝑥) 。 - 命题:小王与小张同岁
小王和小张是个体常量,“…与…同岁”是谓词,记为SameAge, 命题符号:SameAge(小王, 小张) 。
n元谓词:含有n个个体符号的谓词P(𝑥1, 𝑥2, ⋯ , 𝑥𝑛) 。
- 一元谓词(𝑛 = 1):表示𝑥1具有性质P。
- 多元谓词(𝑛 ≥ 2):表示𝑥1, 𝑥2, ⋯ , 𝑥𝑛具有关系P。
函数:又称函词,是从若干个个体到某个个体的映射。
- Father(小张):小张的父亲
- Sum(1,2) :1与2的加和
谓词与函数的区别:
- 谓词实现的是从个体域中的个体到真或假的映射,而函数实现的是从个体域中的一个(或若干)个体到另一个个体的映射,无真值可言。
- 在谓词逻辑中,函数本身不能单独使用,它必须嵌入到谓词中。
量词(quantifier):是表示个体数量属性的词。
- 全称量词:符号化为 ∀(All)
- 日常生活和数学中所用的“一切的”、“所有的”、“每一 个”、“任意的”、“凡”、“都”等词可统称为全称量词。
- 𝑥表示个体域里的某个个体,∀𝑥 P( 𝑥) 表示个体域里所有个体都具有性质P。
- 存在量词:符号化为 ∃(Exist)
- 日常生活和数学中所用的“存在”、“有一个”、“有的”、 “至少有一个”等词可统称为存在量词。
- 𝑦表示个体域里的某个个体,∃𝑦 Q( 𝑦 ) 表示个体域里存在个体𝑦 具有性质Q。
谓词逻辑表示法
用谓词逻辑既可以表示事物的状态、属性、概念等事实性
知识,也可以表示事物间具有因果关系的规则性知识。
谓词逻辑表示知识的一般步骤:
- 定义谓词及个体,确定每个谓词及个体的确切含义。
- 根据所要表达的事物或概念,为每个谓词中的变量赋以特定的值。
- 根据所要表达的知识的语义,用适当的逻辑联结词将各个谓词连接起来形成谓词公式。
谓词逻辑表示法示例
用谓词逻辑表示下列知识:
- 北京是一个美丽的城市,但她不是一个沿海城市。
- 北京是中国的首都。
- 每一个国家的首都都必定位于这个国家。
① 定义谓词和个体域如下:
- BCity 𝑥 :𝑥是一个美丽的城市
- CCity 𝑥 :𝑥是一个沿海城市
- CapitalOf 𝑥, 𝑦 : 𝑥是𝑦的首都
- LocatedIn 𝑥, 𝑦 : 𝑥位于y
- 𝑥 ∈ {城市}, 𝑦 ∈ {国家}
② 将个体带入谓词中,得到:
- BCity (Beijing)
- CCity (Beijing)
- CapitalOf (Beijing,China)
- CapitalOf (𝑥, y)
- LocatedIn (𝑥, 𝑦)
③ 根据语义,用逻辑联结词连接:
- BCity (Beijing) ∧ ¬CCity (Beijing)
- CapitalOf (Beijing,China)
- ∀x, y CapitalOf (𝑥, 𝑦) → LocatedIn (𝑥, y)
谓词逻辑表示法特性
优点:
- 精确性:可以较准确地表示知识并支持精确推理。
- 通用性:拥有通用的逻辑演算方法和推理规则。
- 自然性:是一种接近于人类自然语言的形式语言系统。
- 模块化:各条知识相对独立,它们之间不直接发生联系,便于知识的添加、删除和修改。
缺点:
- 表示能力差:只能表示确定性知识,不能表示非确定
性知识、过程性知识和启发式知识。 - 管理困难:缺乏知识的组织原则,知识库管理困难。
- 效率低:把推理演算与知识含义截然分开,往往使推
理过程冗长,降低了系统效率。
3. 产生式规则表示法
基本概念:事实与规则
产生式系统是用规则序列的形式来描述问题的思维过程, 形成求解问题的思维模式。系统中的每一条规则称为一个产生式。目前产生式规则表示法已成为专家系统首选的知识表示方式,也是人工智能中应用最多的一种知识表示方式
事实:断言一个语言变量的值或断言多个语言变量之间关系的陈述句。
- 雪是白的
语言变量:雪;语言变量的值:白 - 小王与小张同岁
语言变量:小王、小张;语言变量之间的关系:同岁
确定性事实:一般用三元组的形式表示为
- (对象,属性,值)或(关系,对象1,对象2)
不确定性事实:一般用四元组的形式表示为
- (对象,属性,值,置信度)
- (关系,对象1,对象2,置信度)
规则:也称为产生式,通常用于表示事物之间的因果关系。
确定性规则:通常表示为𝑃 → 𝑄 或 IF 𝑃 THEN 𝑄
- 𝑃是产生式的前提或条件;
- 𝑄是一组结论或操作,用于指出前提𝑃所指示的条件被满足时,应该得出的结论或应该执行的操作。
不确定性规则:通常表示为𝑃 → 𝑄 (置信度) 或 IF 𝑃 THEN 𝑄(置信度)
- 𝑃是产生式的前提或条件,𝑄是一组结论或操作。
- 已知事实与前提条件不能精确匹配时,只要按照置信度的要求模糊匹配,再按特定算法将不确定性传递到结论。
产生式系统结构
产生式系统(production system)由数据库、规则库和推理机三部分组成。
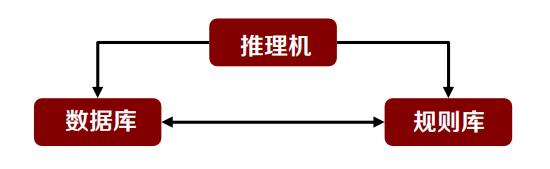
数据库:用来存放问题的初始状态、已知事实、推理的中间结果和最终结论等。
规则库:用来存放与求解问题有关的所有规则。
推理机:用来控制整个系统的运行,决定问题求解的线路,包括匹配、冲突消解、路径解释等。
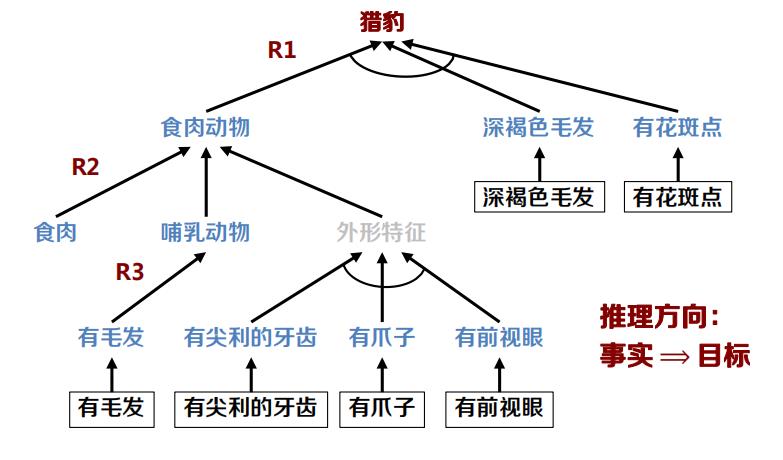
正向推理的产生式系统
正向推理:从已知事实出发,通过规则求得结论。
数据驱动方式或自底向上的方式。
推理过程:
- 规则库中的规则前件与数据库中的事实进行匹配,得 到匹配的规则集合;
- 使用冲突消解算法,从匹配规则集合中选择一条规则 作为启用规则;
- 执行启用规则的后件,并将该规则的后件送入数据库; 重复上述过程直至达到目标。
正向推理的产生式系统示例
动物识别产生式系统:目标 = A是猎豹?
- 已有知识(规则库):
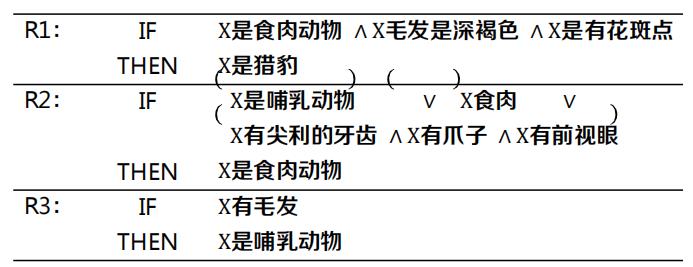
已知事实(事实库)
- A有爪子; A有前视眼;
- A有毛发; A有尖利的牙齿;
- A毛发是深褐色; A有花斑点
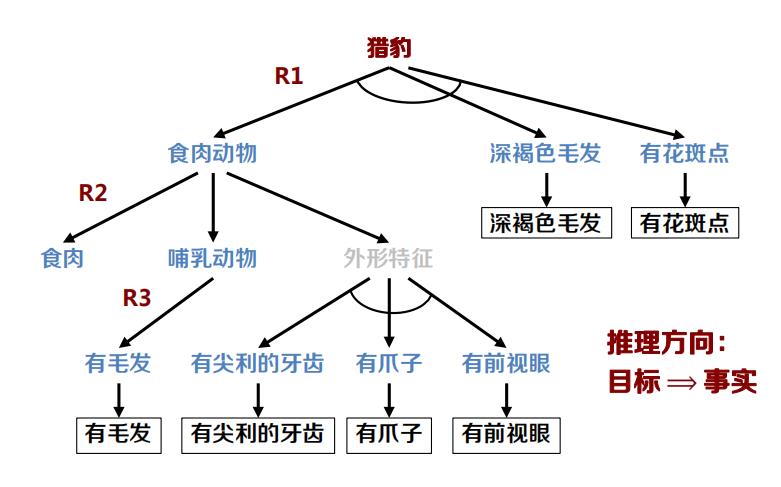
反向推理:从目标出发,反向使用规则,求得已知事实。
目标驱动方式或自顶向下的方式。
推理过程:
- 规则库中的规则后件与目标事实进行匹配,得到匹配 的规则集合;
- 使用冲突消解算法,从匹配规则集合中选择一条规则作为启用规则;
- 将启用规则的前件作为子目标;
重复上述过程直至各子目标均为已知事实。
产生式规则表示法特性
优点:
- 有效性:既可以表示确定性知识,又可以表示不确定性知识,有利于启发性和过程性知识的表达。
- 自然性:用“如果…,则…”表示知识,直观、自然。
- 一致性:所有规则具有相同的格式,并且数据库可被所有规则访问,便于统一处理。
- 模块化:各条规则之间只能通过数据库发生联系,不能相互调用,便于知识的添加、删除和修改。
缺点:
- 效率低:求解是反复进行的“匹配—冲突消解—执行” 过程,执行效率低。
- 表示的局限性:不能表示结构性或层次性知识。
4. 框架表示法
框架表示法是以框架理论为基础发展起来的一种结构化知识表示方式,适用于表达多种类型的知识。框架理论认为人们对现实世界中各种事物的认识都是以一种类似于框架的结构存储在记忆当中,当面临一个新事物时, 就从记忆中找出一个适合的框架,并根据实际情况对其 细节加以修改补充,从而形成对当前事物的认识。
框架(frame):是一种描述所论对象属性的数据结构。
- 框架名:用来指代某一类或某一个对象。
- 槽:用来表示对象的某个方面的属性。
- 侧面:有时一个属性还要从不同侧面来描述。
- 值:槽/侧面的取值,可以为原子型,也可以为集合型。
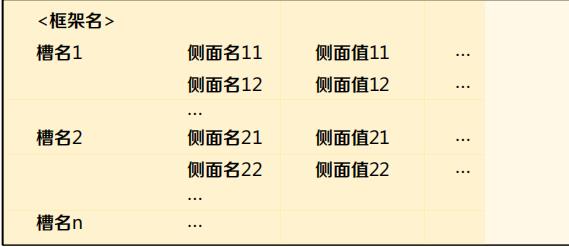
框架分为两种类型:
- 类框架(class frame)用于描述一个概念或一类对象。
- 实例框架(instance frame)用于描述一个具体的对象。
框架的层次结构:
- 子类-subclass of->父类:类框架之间的包含关系。
- 实例-instance of->类:实例框架和类框架的从属关系。 下层框架可以从上层框架继承某些属性和值。后文对两者不做区分,统称为“类属”关系。
框架示例
汶川地震是中华人民共和国自建国以来影响最大的一次地震, 发生于2008年5月12日14时28分04秒,里氏震级8.0级,直接 严重受灾地区达10万平方公里。这次地震危害极大,共遇难 69227人,受伤374643人,失踪17923人。其中四川省68712名同胞遇难,17921名同 胞失踪,共有5335名学生遇难,1000多 名失踪。直接经济损失8452亿元。
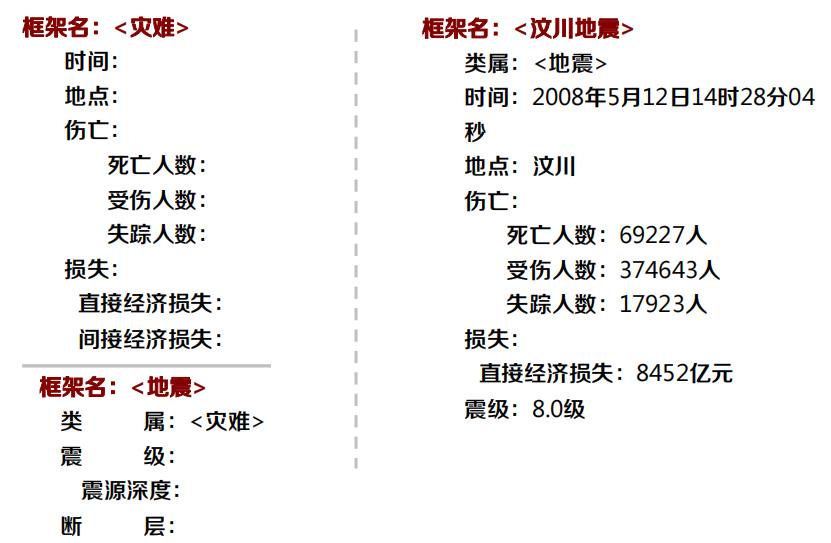
框架系统
框架表示法特性
优点:
- 结构化:分层次嵌套式结构,既可以表示知识的内部 结构,又可以表示知识之间的联系。
- 继承性:下层框架可以从上层框架继承某些属性或值, 也可以进行补充修改,减少冗余信息并节省存储空间。
- 自然性:框架理论符合人类认知的思维过程。
- 模块化:每个框架是相对独立的数据结构,便于知识 的添加、删除和修改。
缺点:
- 不能表示过程性知识
- 缺乏明确的推理机制。
代表性知识库:FrameNet
针对词汇的概念进行框架形式的建模
https://framenet.icsi.berkeley.edu/fndrupal/
针对词汇的概念进行框架形式的建模
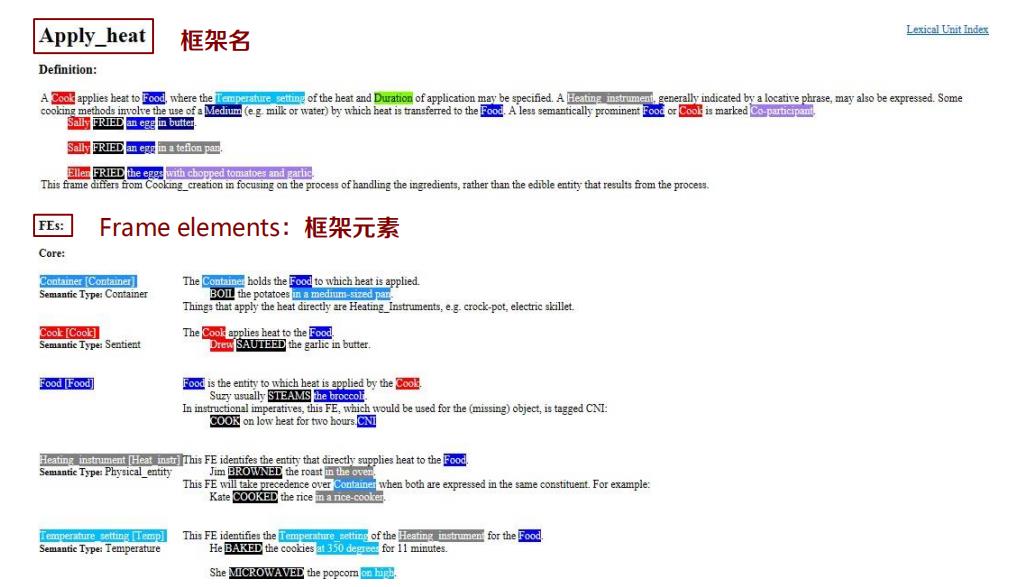

针对词汇的概念进行框架形式的建模

5. 脚本表示法
脚本
脚本由一组槽组成, 用来表示特定领域内一些事件的发生序列,类似于电影剧本。脚本表示的知识有明确的时间或因果顺序,必须是前一个动作完成后才会触发下一个动作。与框架相比, 脚本用来描述一个过程而非静态知识。
- Winston
一个脚本(script)是一个事件序列,包含了紧密相关的 动作及改变状态的框架。
- Luger-Stubblfield
一个脚本是一个描述特定上下文中的原型事件序列(ste- reotyped eventsequence)的结构化表示。
脚本组成
- 进入条件:给出脚本中所描述事件的前提条件。
- 角色:用来描述事件中可能出现的人物。
- 道具:用来描述事件中可能出现的相关物体。
- 场景:用来描述事件发生的真实顺序。一个事件可以由多个场景组成,而每个场景又可以是其他事件的脚本。
- 结果:给出在脚本所描述事件发生以后所产生的结果。
脚本示例
例:用脚本表示去餐厅吃饭
(1) 进入条件:① 顾客饿了,需要进餐;② 顾客有足够的钱。
(2) 角色:顾客,服务员,厨师,老板。
(3) 道具:食品,桌子,菜单,账单,钱。
(4) 场景:
场景1:进入—— ① 顾客进入餐厅;② 寻找桌子;③ 在桌子旁坐下。
场景2:点菜—— ① 服务员给顾客菜单;② 顾客点菜;
③ 顾客把菜单还给服务员;④ 顾客等待服务员送菜。
场景3:等待—— ① 服务员告诉厨师顾客所点的菜;②厨师做菜,顾客等待。
场景4:吃饭—— ① 厨师把做好的送给服务员;② 服务员把菜送给顾客;
③ 顾客吃菜。
场景5:离开—— ① 服务员拿来账单;② 顾客付钱给服务员;
③ 顾客离开餐厅。
(5) 结果:① 顾客吃了饭,不饿了;② 顾客花了钱;③ 老板赚了钱;④ 餐厅食品少了。
脚本表示法特性
缺点:
相较于框架表示,脚本表示表达能力更受约束,表示范围更窄,不具备对于对象基本属性的描述能力,也难以描述复杂事件发展的可能方向。
优点:
在非常狭小的领域内,脚本表示却可以更细致地刻画步骤和时序关系,适合于表达预先构思好的特定知识或顺序性动作及事件,如故事情节理解、智能对话系统、机票酒店预订等。
6. 语义网表示法
语义网的概念来源于万维网(world wide web),是万维网的变革与延伸,是Web of documents向Web of data的转变,其目标是让机器或设备能够自动识别和理解万维网上的内容,使得高效的信息共享和机器智能协同成为可能。
语义网(semantic web)≠ 语义网络(semantic network)
起源:传统万维网中html所表达的页面信息和组织方法, 主要面向用户直接阅读,没有将信息的表现形式、内在结构和表达内容分离,没有提供机器可读的语义信息,因而非常不利于机器的理解和处理。
契机:XML的出现将数据的内容与布局区分开来,为语义更丰富、更自然的Web内容表达打开了新局面。
目标:为Web信息提供机器可以理解的语义,实现Web 信息资源在语义层上的全方位互联,从而帮助机器对Web 上异构、分布式信息进行有效检索和访问。
语义网
本质:以Web数据的内容(即语义)为核心,用机器能够理解和处理的方式链接起来的海量分布式数据库。
特征:
- Web上的事物拥有唯一的URI
- 事物之间由链接关联(如人物 地点、事件、建筑物)
- 事物之间链接显式存在并拥有不同类型
- Web上事物的结构显式存在
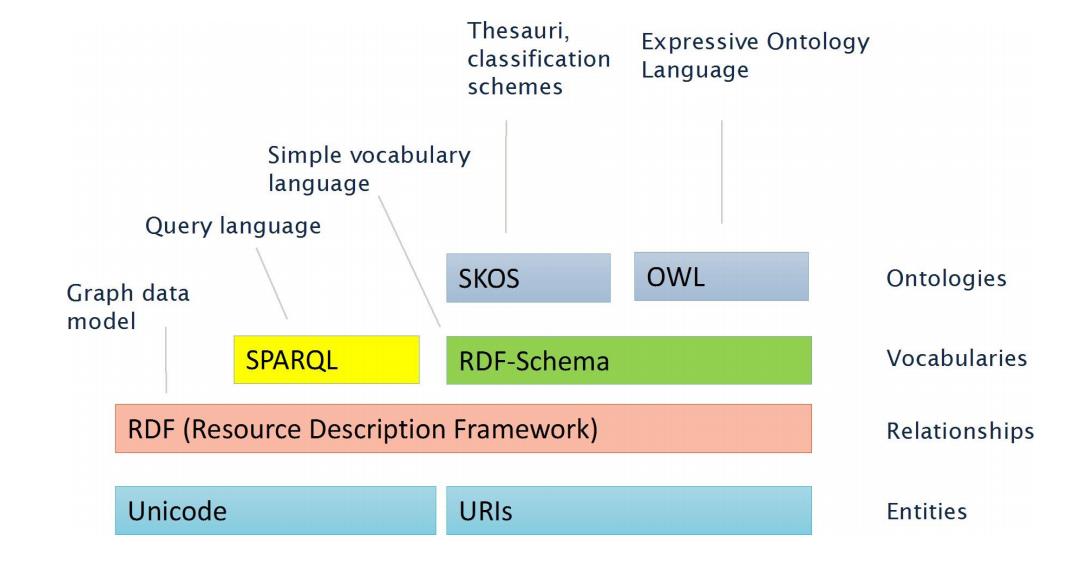
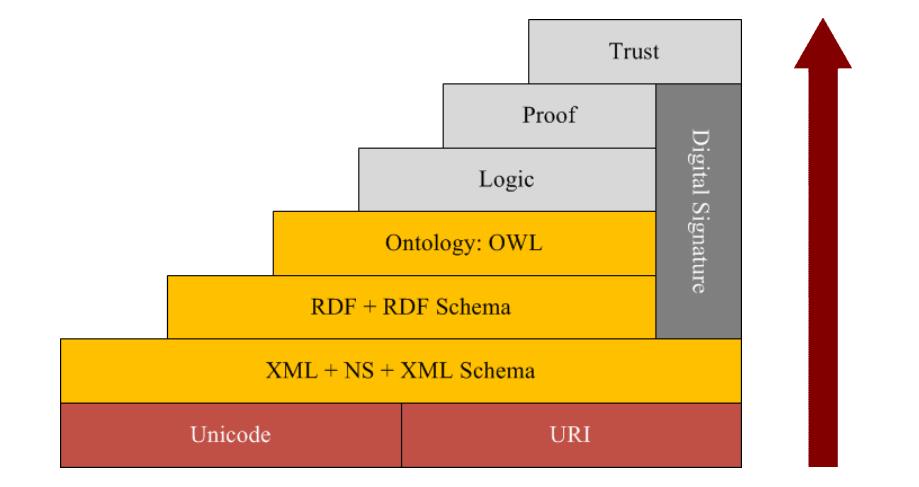
语义网体系结构
语义网提供了一套为描述数据而设计的表示语言和工具, 用于形式化的描述一个知识领域内的概念、术语和关系。
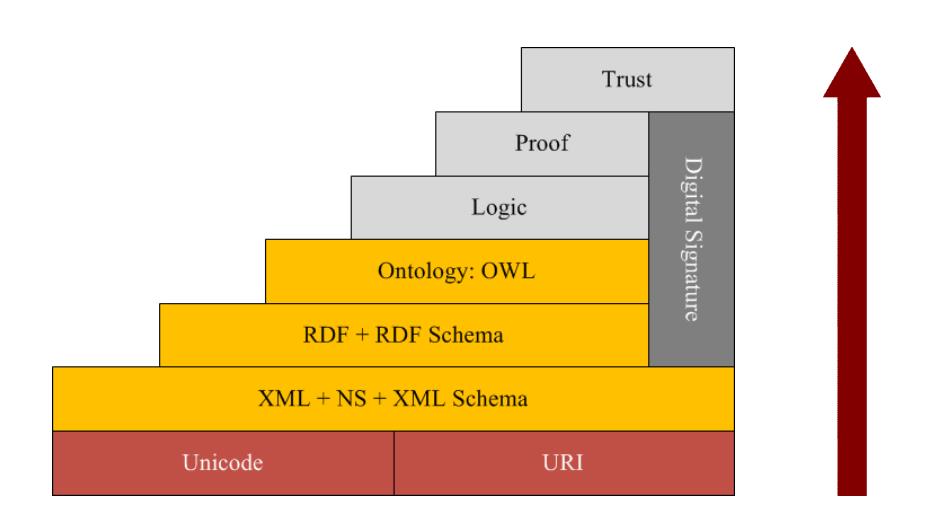
第一层:Unicode和URI (uniform resource identifier, 通用资源标识符),是整个语义网的基础。Unicode处理资源的编码,实现网上信息的统一编码;URI 负责标识资源, 支持网上对象和资源的精细标识。
第二层:XML+NS+XML Schema,用于表示数据的内容 和结构。通过XML标记语言将网上资源信息的结构、内容和数据的表现形式进行分离。
第三层:RDF+RDF Schema,用于描述网上资源及其类型,为网上资源描述提供一种通用框架和实现数据集成的元数据解决方案。
第四层:Ontology Vocabulary,用于描述各种资源之间的联系,揭示资源本身及资源之间更为复杂和丰富的语义联系,明确定义描述属性或类的术语语义及术语间关系。
第五层:逻辑层,主要提供公理和推理规则,为智能推理提供基础。该层用来产生规则。
第六层:证明层,执行逻辑层产生的规则,并结合信任层的应用机制来评判是否能够信赖给定的证明。
第七层:信任层,注重于提供信任机制,以保证用户代理在网上进行个性化服务和彼此间交互合作时更安全可靠。
核心层为XML、RDF、ONTOLOGY,用于表示信息的语义。
XML
XML(eXtensible Markup Language,可扩展标记语言) 是最早的语义网表示语言,它取消了HTML的显示样式和布局描述能力,突出了数据的语义和元素结构描述能力。

用于显示数据,侧重于如何表现信息

用于存储和传输数据,侧重于如何结构化地描述信息
3## XML:元素
XML的元素代表XML文档所描述的“事件”,比如书籍、 作者和出版商。
一个元素由起始标签、元素内容和结尾标签构成。
<author>Thomas B. Passin</author>
用户可以随意地选择标签名,只有很少的限制。
元素具有嵌套结构,并且没有约束嵌套的深度。
<author>
<name>Thomas B. Passin</name>
<gender>Male</gender>
<phone>+61-7-3875 507</phone>
</author>
XML:属性
与HTML类似,XML也可拥有属性,即元素名称-值对, 可以表达与元素相同的语义。
<author name=“Thomas B. Passin” gender=“Male” phone=“+61-7-3875 507”/>
属性也可以与元素混合使用,但是不能嵌套。
<author name=“Thomas B. Passin” gender=“Male” >
<phone>+61-7-3875 507</phone>
</author>
XML:特性
优点:
- 结构化的数据表示方式,使得数据内容与其形式分离。
- 良好的可扩展性,使用者可创建和使用自己的标记,可定义行业领域特殊的标记语言,进行数据共享和交换。
- 包含文档类型声明,其数据可被任何XML解析器提取、 分析、处理,可以轻松地跨平台应用。
缺点:
- XML是一种元标记语言,任何组织或个人都可以用它来定义新的标记和标准,容易产生冲突和混乱。
- XML文档作为数据集合使用时,相当于一个数据库, 确不具备数据库管理系统那样完备的功能。
- 数据是以树状结构存储的,插入和修改比较困难。
RDF
RDF(Resource Description Framework,资源描述框架)是一种资源描述语言,利用当前的多种元数据标准来描述各种网络资源,形成人机可读,并可由机器自动处理的文件。
RDF的核心思想:
利用Web标识符(URI)来标识事物,通过指定的属性和 相应的值描述资源的性质或资源之间的关系。
RDF数据模型
RDF的基本数据模型包括资源、属性和陈述。
- 资源(resource):一切能够以RDF描述的对象都叫资源,用唯一的URI来表示。
- 属性(property):用来描述资源的特征或资源之间的关系,每一个属性都有特定的意义。
- 陈述(statement):特定的资源加上一个属性和相应的属性值就是一个陈述,其中资源是主体(subject), 属性是谓词(predicate),属性值是客体(object)。
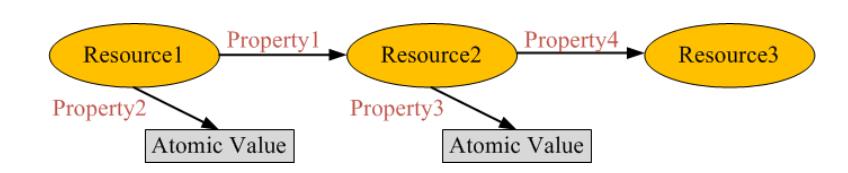
RDF描述示例
考查以下陈述的RDF图表示:
这篇文章(Document_001)的作者(Author_001)名为Eric Miller, 他的工作单位是Home, Inc.,他的电子邮件地址是em@home.com, 他的头衔是Dr.
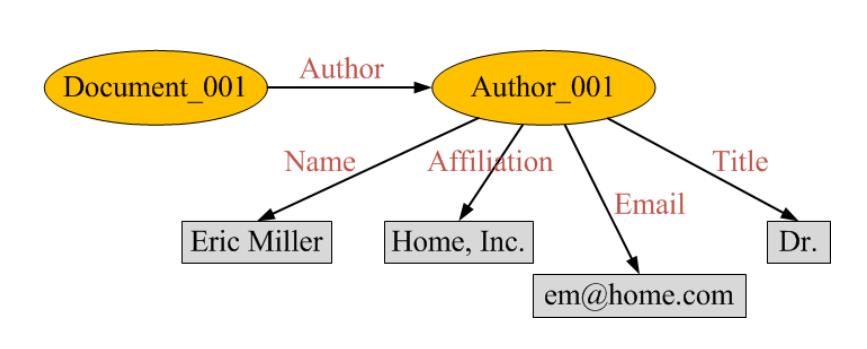
RDF Schema
RDFS是RDF的扩展,它在RDF的基础上提供了一组建模原语,用来描述类、属性以及它们之间的关系。
- Class, subClassOf:描述类别层次结构。
- Property, subPropertyOf:描述属性层次结构。
- domain, range:声明属性所应用的资源类和属性值类。
- type:声明一个资源是一个类的实例。

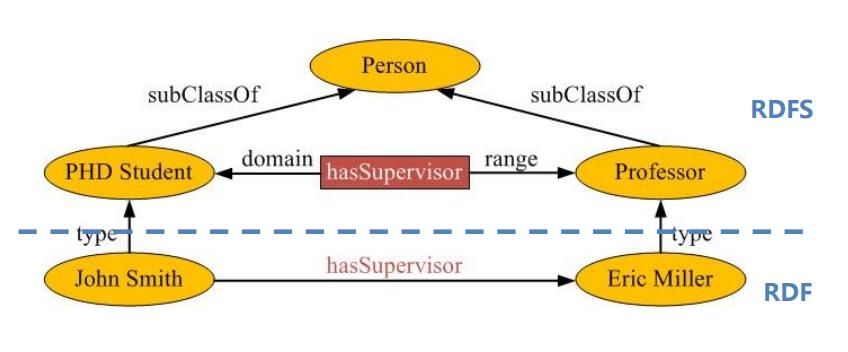
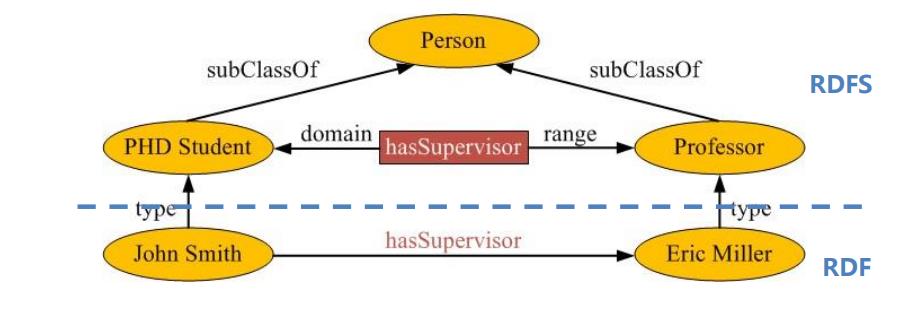

RDFS词汇表
RDFS允许定义自己的词汇表(vocabulary):
- 类别集合和属性集合
- 与其它词汇表中词汇的关系
词汇表示例:
Dublin core terms: creator, date, …
FOAF terms: characterization of persons
Good relations: e-Commerce terms
Creative commons: copyright classes, license relations,
schema.org terms: events, organizations, places, reviews,
RDF(S)特性
优点:
简单:资源以三元组的形式描述,简单、易控制。
易扩展:描述和词汇集分开,具备良好的可扩展性。
包容性:允许定义自己的词汇集,并可以无缝使用多种 词汇集来描述资源。
易综合:RDF认为一切都是资源,这样很容易综合描述。
缺点:
不能准确描述语义:同一个概念有多种词汇表示,同一 个词汇有多种含义(概念)。
没有推理模型,不具备推理能力。
为什么需要Ontology
- Ontology(本体)通过对概念的严格定义和概念与概念 之间的关系来确定概念的精确含义,表示共同认可的、可共享的知识。
- 对于ontology来说,author,creator和writer是同一个概念,而doctor在大学和医院分别表示的是两个概念。因 此在语义网中,ontology具有非常重要的地位,是解决语义层次上Web信息共享和交换的基础。
本体的定义
哲学界:对世界上客观存在物的系统地描述,即存在论。
知识工程界:
- 1991/Neches:本体定义了主题领域的词汇的基本术 语和关系,以及利用这些术语和关系构成的规定这些词 汇外延的规则。
- 1993/Gruber:本体是概念模型的明确的规范说明。
- 1997/Borst:本体是共享概念模型的形式化规范说明。
- 1998/Studer:本体是共享概念模型的明确的形式化规范说明。
An ontology is a formal, explicit specification of a shared conceptualization
概念模型 (conceptualization):本体是通过抽象客观世界的概念而得到的模型,其表示的含义独立于具体的环境状态。
明确性 (explicit):本体所使用的概念及使用这些概念的约束都有明确的定义,没有二义性。
形式化 (formal):本体是计算机可处理的,而非自然语言。
共享 (shared):本体体现的是共同认可的知识,反映的是 相关领域中公认的概念集合,它所针对的是团体而非个体。
本体的组成:𝑂={𝐶,𝑅,𝐹,𝐴,𝐼}
概念 (concept) 或类 (class):可以指任何事物,从语义上讲,它表示的是对象的集合。
学生、教授、演员、歌手
关系 (relation):描述概念之间的语义关联。
part-of、kind-of、instance-of、attribute-of
函数 (function):一类特殊的关系,该关系中的第n个元素可由前n-1个元素唯一决定。
father-of(x, y)表示y是x的父亲
公理 (axiom):代表永真断言。
如果A是B的子女,B是C的子女,则A是C的子孙
实例 (instance):某类概念所指的具体个体,即对象。
John Smith是概念学生的实例
OWL
OWL (Web Ontology Language,Web本体语言)是在语义网上表示本体的推荐语言,作为RDF(S)的扩展,其目的是提供更多原语以支持更加丰富的语义表达并支持推理。
OWL的三个子语言:
- OWL Lite:提供一个分类层次和简单属性约束。
- OWL DL:提供推理系统,保证计算完备性和可判定性。
- OWL Full:支持完全自由的RDF语法,但是不具备可 计算性保证。
表达能力:OWL Lite < OWL DL < OWL Full
OWL建模原语
类运算式 (class descriptions):
枚举
owl:oneOf
属性值约束
owl:allValuesFrom, owl:someValuesFrom, owl:hasValue
属性基数约束
owl:maxCadinality, owl:minCadinality, owl:cadinality
交集、并集、补集
owl:intersectionOf, owl:unionOf, owl:complementOf
类公理 (class axioms):
子类、等价类、不相交类
rdfs:subClassOf, owl:equivalentClass, owl:disjointWith

语义网知识描述语言体系
XML (http://www.w3.org/XML/) 提供了一种结构化文 档的表层语法,但没有对文档含义施加任何语义约束 。
RDF (http://www.w3.org/TR/2002/WD-rdf-concepts- 20021108/) 是一个关于对象(资源)和它们之间关系的 数据模型,该模型具备简单语义,能够用XML语法表示。
RDF Schema (http://www.w3.org/TR/2002/WD-rdf- schema-20021112/)是一组描述RDF资源的类和属性的 建模原语,提供了关于这些类和属性的层次结构的语义。
OWL (http://www.w3.org/TR/2004/REC-owl-ref- 20040210/) 添加了更多用于描述类和属性的建模原语, 支持更加丰富的语义表达并支持推理。
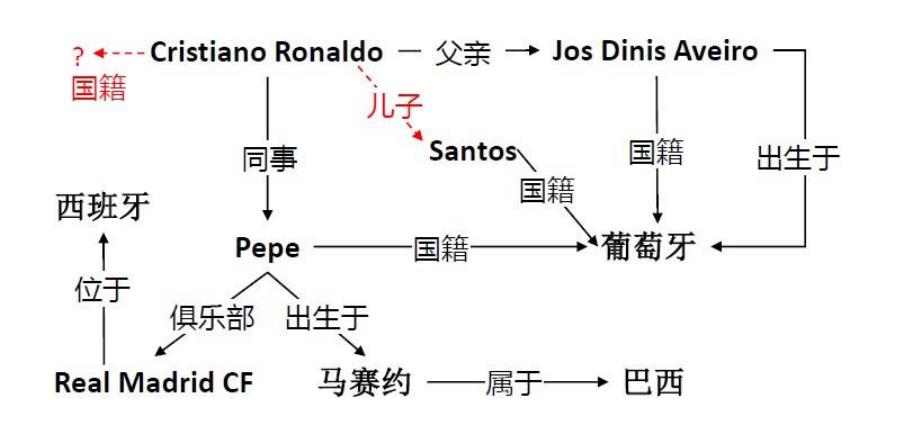
7. 知识图谱中的知识表示
知识图谱的概念最早出现于Google公司的知识图谱项 目,体现在使用Google搜索引擎时,出现于搜索结果右侧的相关知识展示。
截止到2016年底,Google 知识图谱中的知识数量已经达到了600亿条,关于1500 个类别的5.7亿个实体,以及它们之间的3.5万种关系。
实体、关系和事实
实体 (entity):现实世界中可区分、可识别的事物或概念。
- 客观对象:人物、地点、机构
- 抽象事件:电影、奖项、赛事
关系 (relation):实体和实体之间的语义关联。
- BornInCity, IsParentOf, AthletePlaysForTeam
事实 (fact):陈述两个实体之间关系的断言,通常表示为 (head entity, relation,tail entity) 三元组形式。
狭义知识图谱
狭义知识图谱:具有图结构的三元组知识库。
- 知识库中的实体作为知识图谱中的节点。
- 知识库中的事实作为知识图谱中的边,边的方向由头实体指向尾实体,边的类型就是两实体间关系类型。
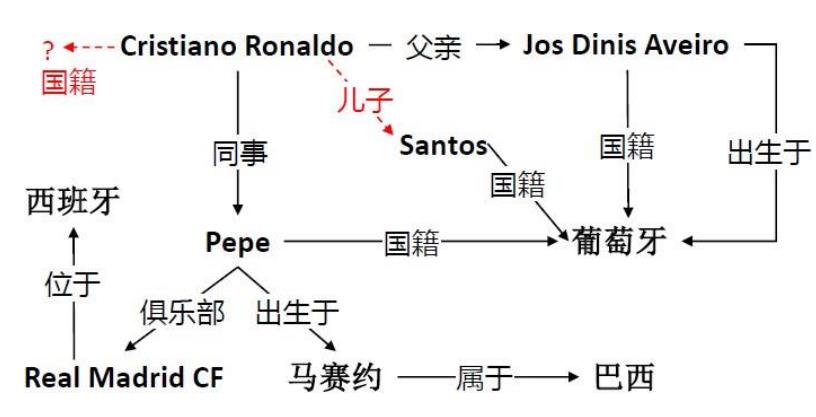
知识图谱特性
-
知识图谱不太专注于对知识框架的定义,而专注于如何以工程的方式,从文本中自动抽取或依靠众包的方式获取并组建广泛的、具有平铺结构的知识实例,最后再要求使用它的方式具有容错、模糊匹配等机制。
-
知识图谱的真正魅力在于其图结构,可以在知识图谱上运行搜索、随机游走、网络流等大规模图算法,使知识图谱与图论、概率图等碰撞出火花。
8. 分布式知识表示
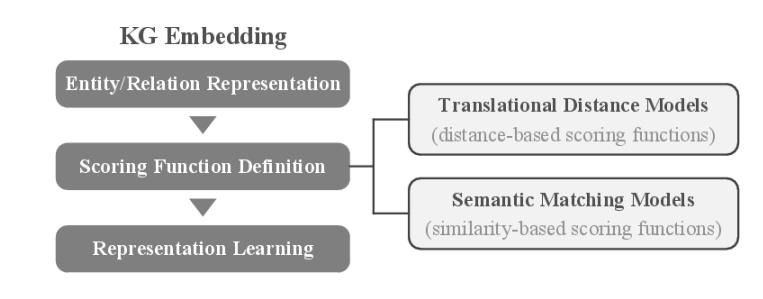
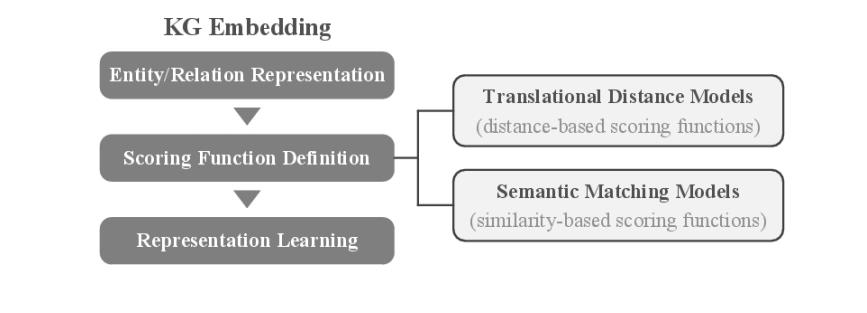
核心思想:将符号化的实体和关系在低维连续向量空间进 行表示,在简化计算的同时最大程度保留原始的图结构。
- 将实体和关系在向量空间进行表示(向量/矩阵/张量)。
- 定义打分函数,衡量每个三元组成立的可能性。
- 构造优化问题,学习实体和关系的低维连续向量表示。
¹Wang et al. Knowledge Graph Embedding: A Survey of Approaches and Applications. IEEE TKDE, to appear, 2017.http://ieeexplore.ieee.org/document/8047276/
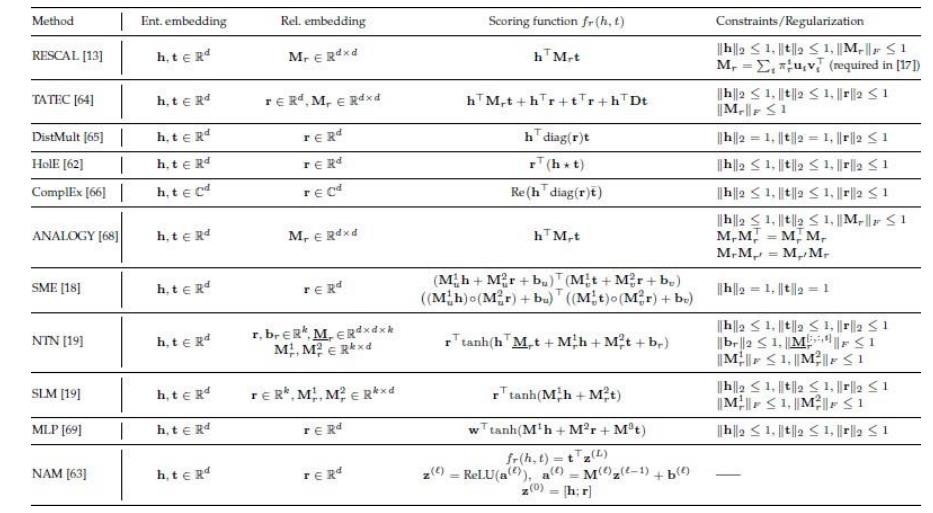
方法类型:
位移距离模型 (translational distance models):采用基于距离的打分函数来衡量三元组成立的可能性。
语义匹配模型 (semantic matching models):采用基于相似度的打分函数来衡量三元组成立的可能性。
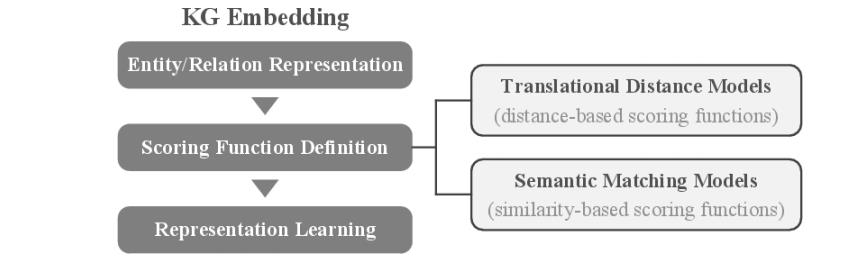
位移距离模型
代表性方法:TransE及其变种
- head entity + relation = tail entity
China – Beijing = France – Paris = capital-of Beijing + capital-of = China
Paris + capital-of = France
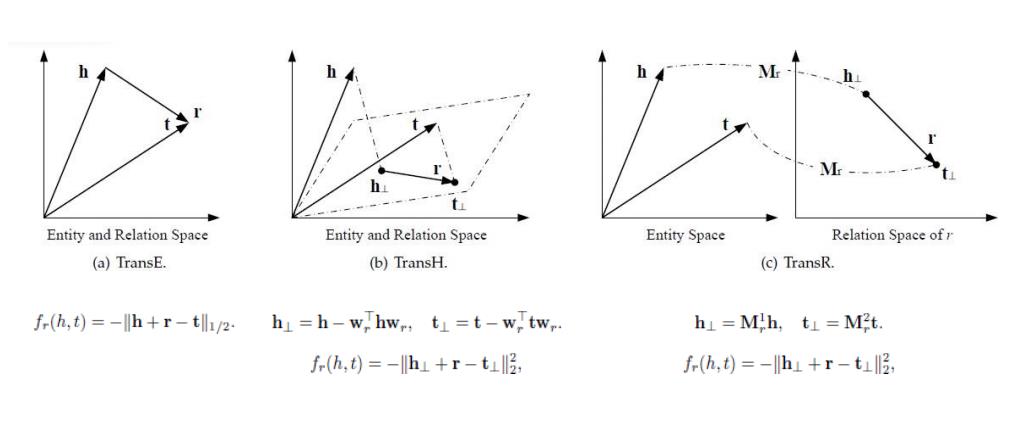

语义匹配模型
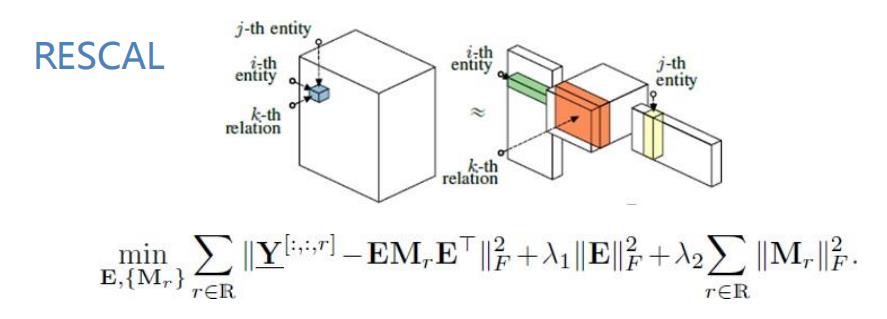
代表性方法:RESCAL及其变种
- matching(relation, composition(head, tail))
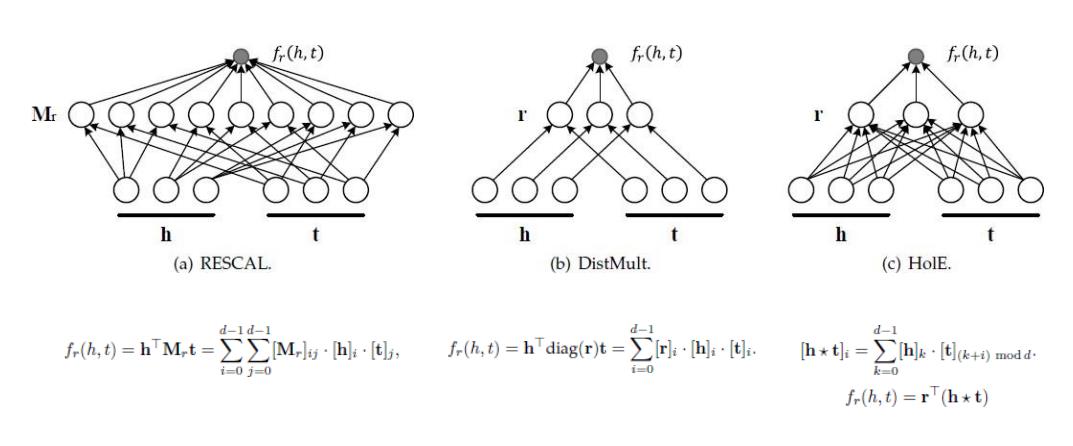
代表性方法:神经网络
matching via neural network architectures
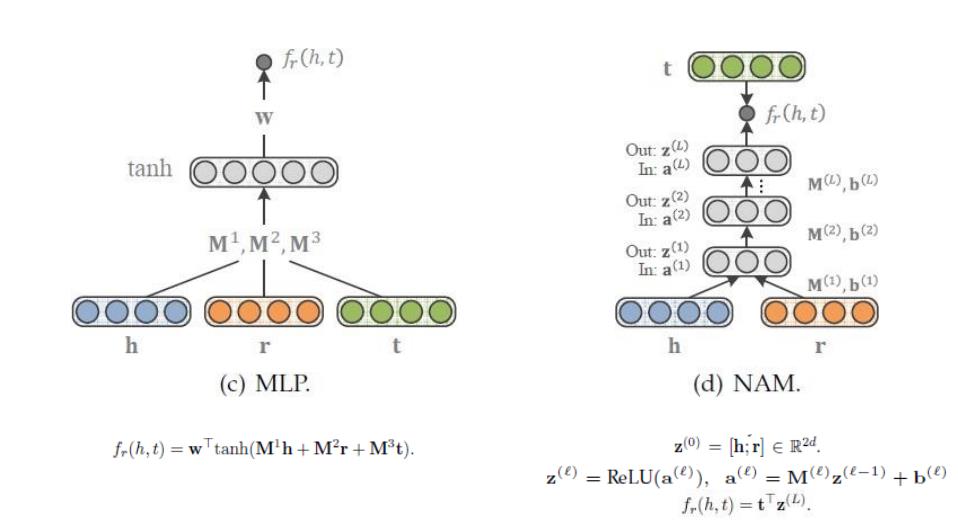
模型训练
开放世界假设 (Open World Assumption, OWA):知识图谱仅包括正确的事实,那些不在其中出现的事实要么是错误的,要么是缺失的。
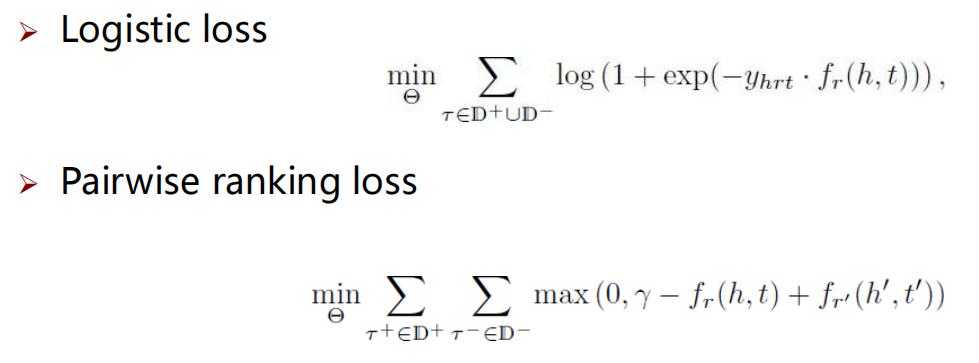
关键:以何种策略生成负样本。
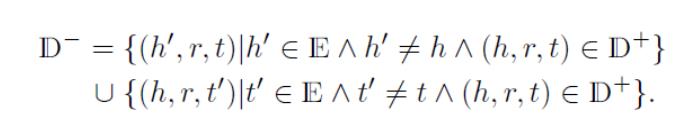
封闭世界假设 (Closed World Assumption, CWA):但凡未在知识图谱中出现的事实都是错误的。
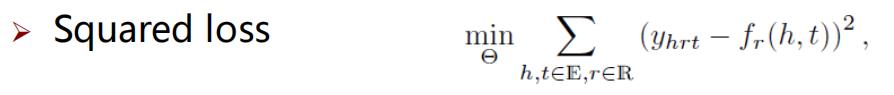
等价于分解由知识图谱表示成的三阶张量。
9. 本章小结
一阶谓词逻辑表示法
通过个体、谓词、量词、逻辑联结词来表示事物的状态、 属性等事实性知识,以及事物间因果关系的规则性知识。
定义谓词及个体,确定每个谓词及个体的确切含义。
依据所要表达的事物,为谓词中的变量赋以特定的值。
用逻辑联结词将各个谓词连接起来形成谓词公式。
优点:精确性、通用性、自然性、模块化。
缺点:表示能力差、管理困难、效率低。
产生式规则表示法
产生式系统结构:数据库 + 规则库 + 推理机
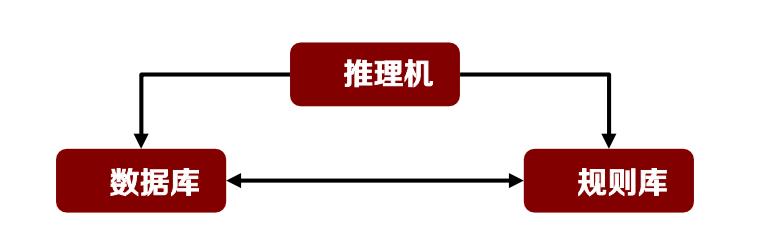
数据库:存放已知事实、推理的中间结果和最终结论。
规则库:存放与求解问题有关的所有规则。
推理机:控制整个系统的运行,决定问题求解的线路。
框架表示法
框架是一种描述所论对象属性的数据结构,由框架名、槽、 侧面和值四部分组成。
框架类型:类框架 + 实例框架
层次结构:子类-subclass of->父类、实例-instance of->类
优点:结构化、继承性、自然性、模块化。
缺点:不能表示过程性知识、缺乏明确的推理机制。
脚本表示法
脚本是描述特定上下文中的原型事件序列的结构化表示,由 进入条件、角色、道 具、场景和结果五部分组成。
缺点:表达能力非常有限,表示范围窄,不具备对于对象基 本属性的描述能力,也难以描述复杂事件发展的可能方向。
优点:在非常狭小的领域内,脚本表示却可以更细致地刻画 步骤和时序关系,适合于表达预先构思好的特定知识或顺序 性动作及事件。
语义网表示法
语义网提供了一套为描述数据而设计的表示语言和工具, 用于形式化的描述一个知识领域内的概念、术语和关系。
XML (http://www.w3.org/XML/) 提供了一种结构化文 档的表层语法,但没有对文档含义施加任何语义约束 。
RDF (http://www.w3.org/TR/2002/WD-rdf-concepts- 20021108/) 是一个关于对象(资源)和它们之间关系的 数据模型,该模型具备简单语义,能够用XML语法表示。
RDF Schema (http://www.w3.org/TR/2002/WD-rdf- schema-20021112/) 是一组描述RDF资源的类和属性的 建模原语,提供了关于这些类和属性的层次结构的语义。
OWL (http://www.w3.org/TR/2004/REC-owl-ref- 20040210/) 添加了更多用于描述类和属性的建模原语, 支持更加丰富的语义表达并支持推理。
知识图谱中的知识表示
狭义知识图谱:具有图结构的三元组知识库。
知识库中的实体作为知识图谱中的节点。
知识库中的事实作为知识图谱中的边,边的方向由头实体指向尾实体,边的类型就是两实体间关系类型。
分布式知识表示
核心思想:将符号化的实体和关系在低维连续向量空间进 行表示,在简化计算的同时最大程度保留原始的图结构。
实体关系表示(向量/矩阵/张量)
打分函数定义(距离函数/相似度函数)
表示学习(开放世界假设/封闭世界假设)

加油!
感谢!
努力!
以上是关于知识图谱知识表示的主要内容,如果未能解决你的问题,请参考以下文章
B.特定领域知识图谱知识推理方案[一]:基于表示学习的知识感知推理算法[对抗负采样Logic Rule,链接预测任务]在关系预测推荐场景下应用