Pytorch实战__LSTM做文本分类
Posted hello_JeremyWang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch实战__LSTM做文本分类相关的知识,希望对你有一定的参考价值。
0. 介绍
首先需要指出的是,代码是从李宏毅老师的课程中下载的,并不是我自己码的。这篇文章主要是在原代码中加了一些讲解和注释,以及将繁体字改成了简体字。
我们需要处理的问题是将Twitter上的文字评论分为正面和负面。具体的要求如下:

我们使用到的模型如下所示:
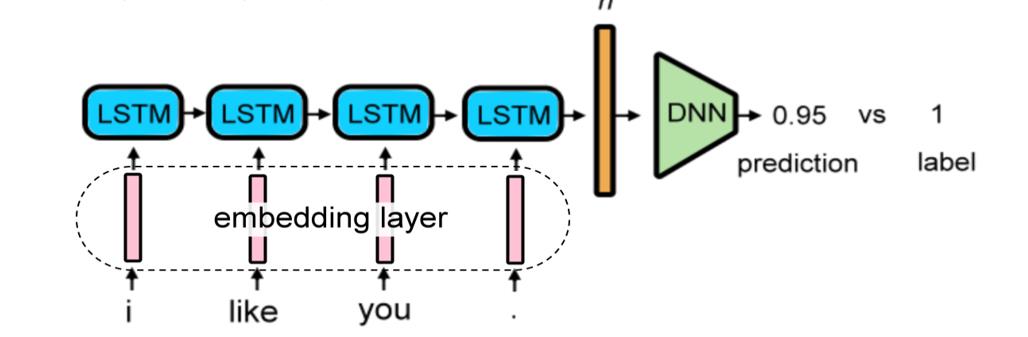
其中,word embedding是将词语转换为向量,以便于后续放入LSTM中进行训练。在下面的代码中,作者选用的是word2vec模型(Skip-gram、CBOW等)完成这个转换。具体的算法大家可以在CSDN或者B站搜索大佬们的文章来学习。
1. 下载数据
path_prefix = './'
!gdown --id '1lz0Wtwxsh5YCPdqQ3E3l_nbfJT1N13V8' --output data.zip
!unzip data.zip
!ls
# this is for filtering the warnings
import warnings
warnings.filterwarnings('ignore')
2. 读入数据
因为数据的格式并不是一般的格式,所以需要写一个自己的读取函数
import torch
import numpy as np
import pandas as pd
import torch.optim as optim
import torch.nn.functional as F
def load_training_data(path='training_label.txt'):
# 把training时需要的data读入
# 如果是'training_label.txt',需要读取它的label,如果是'training_nolabel.txt',不需要读取label(本身也没有label)
if 'training_label' in path: #判断training_label这几个字在不在path中,以判断需不需要读取label
#读入存在txt中文本数据的常用方式
with open(path, 'r') as f:
lines = f.readlines() #一行一行读入数据
lines = [line.strip('\\n').split(' ') for line in lines]
x = [line[2:] for line in lines] #第二列之后是文本数据
y = [line[0] for line in lines] #第一列是label
return x, y
else:
with open(path, 'r') as f:
lines = f.readlines()
x = [line.strip('\\n').split(' ') for line in lines]
return x
def load_testing_data(path='testing_data'):
# 把testing时需要的data读进来
with open(path, 'r') as f:
lines = f.readlines()
X = ["".join(line.strip('\\n').split(",")[1:]).strip() for line in lines[1:]]
X = [sen.split(' ') for sen in X]
return X
def evaluation(outputs, labels): #定义自己的评价函数,用分类的准确率来评价
#outputs => probability (float)
#labels => labels
outputs[outputs>=0.5] = 1 # 大於等於0.5為有惡意
outputs[outputs<0.5] = 0 # 小於0.5為無惡意
correct = torch.sum(torch.eq(outputs, labels)).item()
return correct
3. 定义word2vec模型
word2vec模型可以将词语转换为向量,并且能很神奇地保留词语的相似度等性质。具体的算法流程可以在csdn、知乎或者B站上搜索大佬们的文章。我们在这里使用word2vec是为了后续将文字转换为向量,以便于输入相应的神经网络来学习。(神经网络只认数字不认英文的嘛)
# 这个block是用来训练word to vector 的 word embedding
# 注意!这个block在训练word to vector时是用cpu,可能要花到10分钟以上(我试了一下,确实是要很久)
import os
import numpy as np
import pandas as pd
import argparse
from gensim.models import word2vec
def train_word2vec(x):
# 训练word to vector 的 word embedding
#size是神经网络的层数,window是窗口长度,min_count是用来忽略那些出现过少的词语,worker是线程数,iter是循环次数
model = word2vec.Word2Vec(x, size=250, window=5, min_count=5, workers=12, iter=10, sg=1)
return model
if __name__ == "__main__":
print("loading training data ...")
train_x, y = load_training_data('training_label.txt')
train_x_no_label = load_training_data('training_nolabel.txt')
print("loading testing data ...")
test_x = load_testing_data('testing_data.txt')
model = train_word2vec(train_x + train_x_no_label + test_x)
print("saving model ...")
# model.save(os.path.join(path_prefix, 'model/w2v_all.model'))
model.save(os.path.join(path_prefix, 'w2v_all.model')) #将模型保存这一步可以使得后续的训练更方便,是一个很好的习惯
4. 定义数据预处理类
因为我们要面对的是文本数据,所以必须要进行数据预处理。为了后续的操作方便,作者在这里将其封装成了一个类。具体包括:
- 把之前训练好的word2vec模型读进来,保存训练好的embedding(这个embedding包含了训练word2vec模型时使用的各个参数)
- 把"PAD"或"UNK"加进embedding_matrix
- 制作embedding_matrix
- 将输入的句子的长度变成一致的,方便后续输入神经网络中
- 实现word2indx,把句子里面的字变成相对应的index
- 将label转为tensor格式
from torch import nn
from gensim.models import Word2Vec
class Preprocess():
def __init__(self, sentences, sen_len, w2v_path="./w2v.model"): #首先定义类的一些属性
self.w2v_path = w2v_path
self.sentences = sentences
self.sen_len = sen_len
self.idx2word = []
self.word2idx = {}
self.embedding_matrix = []
def get_w2v_model(self):
# 把之前训练好的word to vec 模型读进来
self.embedding = Word2Vec.load(self.w2v_path)
self.embedding_dim = self.embedding.vector_size #embedding的维度就是训练好的Word2vec中向量的长度
def add_embedding(self, word):
# 把word("<PAD>"或"<UNK>")加进embedding,并赋予他一个随机生成的representation vector
# 因为我们有时候要用到"<PAD>"或"<UNK>",但它俩本身没法放到word2vec中训练而且它俩不需要生成一个能反应其与其他词关系的向量,故随机生成
vector = torch.empty(1, self.embedding_dim)#生成空的
torch.nn.init.uniform_(vector)#随机生成
self.word2idx[word] = len(self.word2idx)#在word2idx放入对应的index
self.idx2word.append(word)#在idx2word中放入对应的word
self.embedding_matrix = torch.cat([self.embedding_matrix, vector], 0)#在embedding_matrix中加入新的vector
def make_embedding(self, load=True):
print("Get embedding ...")
# 取得训练好的 Word2vec word embedding
if load:
print("loading word to vec model ...")
self.get_w2v_model()
else:
raise NotImplementedError
# 制作一个 word2idx 的 dictionary
# 制作一个 idx2word 的 list
# 制作一个 word2vector 的 list
for i, word in enumerate(self.embedding.wv.vocab):
print('get words #{}'.format(i+1), end='\\r')
#e.g. self.word2index['哈'] = 1
#e.g. self.index2word[1] = '哈'
#e.g. self.vectors[1] = '哈' vector
self.word2idx[word] = len(self.word2idx)
self.idx2word.append(word)
self.embedding_matrix.append(self.embedding[word])
print('')
self.embedding_matrix = torch.tensor(self.embedding_matrix)
# 將"<PAD>"和"<UNK>"加进embedding里面
self.add_embedding("<PAD>")
self.add_embedding("<UNK>")
print("total words: {}".format(len(self.embedding_matrix)))
return self.embedding_matrix
def pad_sequence(self, sentence):
# 将每个句子变成一样的长度
if len(sentence) > self.sen_len: #多的直接截断
sentence = sentence[:self.sen_len]
else: #少的添加"<PAD>"
pad_len = self.sen_len - len(sentence)
for _ in range(pad_len):
sentence.append(self.word2idx["<PAD>"])
assert len(sentence) == self.sen_len
return sentence
def sentence_word2idx(self):
# 把句子里面的字变成相对应的index
sentence_list = []
for i, sen in enumerate(self.sentences):
print('sentence count #{}'.format(i+1), end='\\r')
sentence_idx = []
for word in sen:
if (word in self.word2idx.keys()):
sentence_idx.append(self.word2idx[word])
else:
sentence_idx.append(self.word2idx["<UNK>"])
# 将每个句子变成一样的长度
sentence_idx = self.pad_sequence(sentence_idx)
sentence_list.append(sentence_idx)
return torch.LongTensor(sentence_list)
def labels_to_tensor(self, y):
# 把labels转成tensor
y = [int(label) for label in y]
return torch.LongTensor(y)
5. 制作Dataset
这一步相对比较简单,只是做了Dataset类
# 建立了dataset所需要的'__init__', '__getitem__', '__len__'
# 好让dataloader能使用
import torch
from torch.utils import data
class TwitterDataset(data.Dataset):
"""
Expected data shape like:(data_num, data_len)
Data can be a list of numpy array or a list of lists
input data shape : (data_num, seq_len, feature_dim)
__len__ will return the number of data
"""
def __init__(self, X, y):
self.data = X
self.label = y
def __getitem__(self, idx):
if self.label is None: return self.data[idx]
return self.data[idx], self.label[idx]
def __len__(self):
return len(self.data)
6. 建立模型
建立我们之后要使用的LSTM模型,主要包括三块:
- embedding layer
- LSTM
- 全连接神经网络
embedding layer可以理解为将我们的文字进行编码,以使得LSTM可以看得懂,具体用到的方法就是word2vec模型。
LSTM模型主要需要输入:
- input_size: 输入特征维数,即每一行输入元素的个数
- hidden_size: 隐藏层状态的维数,即隐藏层节点的个数,这个和单层感知器的结构是类似的。
- num_layers: LSTM 堆叠的层数,默认值是1层,如果设置为2,第二个LSTM接收第一个LSTM的计算结果。
- batch_first: 输入输出的第一维是否为 batch_size,默认值 False。因为 Torch 中,人们习惯使用Torch中带有的dataset,dataloader向神经网络模型连续输入数据,这里面就有一个 batch_size 的参数,表示一次输入多少个数据。 在 LSTM 模型中,输入数据必须是一批数据,为了区分LSTM中的批量数据和dataloader中的批量数据是否相同意义,LSTM 模型就通过这个参数的设定来区分。
- dropout: 默认值0。是否在除最后一个 RNN 层外的其他 RNN 层后面加 dropout 层。
- bidirectional: 是否是双向 RNN,默认为:false,若为 true,则:num_directions=2,否则为1。
全连接神经网络主要是为了将LSTM的输出和最终的预测进行一下转换。
import torch
from torch import nn
class LSTM_Net(nn.Module):
def __init__(self, embedding, embedding_dim, hidden_dim, num_layers, dropout=0.5, fix_embedding=True):
super(LSTM_Net, self).__init__()
# 制作 embedding layer
self.embedding = torch.nn.Embedding(embedding.size(0),embedding.size(1))
self.embedding.weight = torch.nn.Parameter(embedding)#embedding层的参数直接调用我们之前用word2vec训练的embedding里面的参数
# 是否將 embedding fix住,如果fix_embedding为False,在训练过程中,embedding也会跟着被训练
self.embedding.weight.requires_grad = False if fix_embedding else True
self.embedding_dim = embedding.size(1)
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.dropout = dropout
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers, batch_first=True)
self.classifier = nn.Sequential( nn.Dropout(dropout),
nn.Linear(hidden_dim, 1),
nn.Sigmoid() )
def forward(self, inputs):
inputs = self.embedding(inputs)
x, _ = self.lstm(inputs, None)
# x 的 dimension (batch, seq_len, hidden_size)
# 取用 LSTM 最后一个的 hidden state(我的理解是最后一个的输出对于整个文本的理解是最到位的)
x = x[:, -1, :]
x = self.classifier(x)
return x
7. 定义模型训练函数
这个训练的过程跟之间的训练较为相似。注释给的很详细,可以通过注释理解一下。
import torch
from torch import nn
import torch.optim as optim
import torch.nn.functional as F
def training(batch_size, n_epoch, lr, model_dir, train, valid, model, device):
total = sum(p.numel() for p in model.parameters())#总的参数
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)#需要训练的参数
print('\\nstart training, parameter total:{}, trainable:{}\\n'.format(total, trainable))#看看模型的参数
model.train() # 将model的模式设为train,这样optimizer就可以更新model的参数
criterion = nn.BCELoss() # 定义损失函數,这里我们使用binary cross entropy loss
t_batch = len(train)
v_batch = len(valid)
optimizer = optim.Adam(model.parameters(), lr=lr) # 将模型的参数传给optimizer,并赋予适当的learning rate
total_loss, total_acc, best_acc = 0, 0, 0
for epoch in range(n_epoch):
total_loss, total_acc = 0, 0
# 做training
for i, (inputs, labels) in enumerate(train):
inputs = inputs.to(device, dtype=torch.long) # device为"cuda",将inputs变成torch.cuda.LongTensor
labels = labels.to(device, dtype=torch.float) # device為"cuda",将labels变成torch.cuda.FloatTensor,因为等等要放入criterion,所以类型要是float
optimizer.zero_grad() # 由于loss.backward()的gradient会累加,所以每次做完一个batch后需要调零
outputs = model(inputs) # 將input餵給模型
outputs = outputs.squeeze() # 去掉最外面的dimension,好让outputs可以放入criterion()
loss = criterion(outputs, labels) # 计算此时模型的training loss
loss.backward() # 算loss的gradient
optimizer.step() # 更新训练模型的參數
correct = evaluation(outputs, labels) # 计算此时模型的training accuracy
total_acc += (correct / batch_size)
total_loss += loss.item()
print('[ Epoch{}: {}/{} ] loss:{:.3f} acc:{:.3f} '.format(
epoch+1, i+1, t_batch, loss.item(), correct*100/batch_size), end='\\r')
print('\\nTrain | Loss:{:.5f} Acc: {:.3f}'.format(total_loss/t_batch, total_acc/t_batch*100))
# 这段做validation
model.eval() # 将model的模式设为eval,这样model的参数就会固定住
with torch.no_grad():
total_loss, total_acc = 0, 0
for i, (inputs, labels) in enumerate(valid):
inputs = inputs.to(device, dtype=torch.long)
labels = labels.to(device, dtype=torch.float)
outputs = model(inputs)
outputs = outputs.squeeze()
loss = criterion(outputs, labels)
correct = evaluation(outputs, labels)
total_acc += (correct / batch_size)
total_loss += loss.item()
print("Valid | Loss:{:.5f} Acc: {:.3f} ".format(total_loss/v_batch, total_acc/v_batch*100))
if total_acc > best_acc:
# 如果validation的結果好于之前所有的結果,就把当下的模型存下來以便后续的预测使用
best_acc = total_acc
#torch.save(model, "{}/val_acc_{:.3f}.model".format(model_dir,total_acc/v_batch*100))
torch.save(model, "{}/ckpt.model".format(model_dir))
print('saving model with acc {:.3f}'.format(total_acc/v_batch*100))
print('-----------------------------------------------')
model.train() # 将model的模式设为train,这样optimizer就可以更新model的參數(因為刚刚转为eval模式)
8.定义模型测试函数
import torch
from torch import nn
import torch.optim as optim
import torch.nn.functional as F
def testing(batch_size, test_loader, model, device):
model.eval()
ret_output = []
with torch.no_grad():
for i, inputs in enumerate(test_loader):
inputs = inputs.to(device, dtype=torch.long)
outputs = model(inputs)
以上是关于Pytorch实战__LSTM做文本分类的主要内容,如果未能解决你的问题,请参考以下文章
[Pytorch系列-61]:循环神经网络 - 中文新闻文本分类详解-3-CNN网络训练与评估代码详解