简单看看 Go 1.17 的新版调用规约
Posted qcrao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单看看 Go 1.17 的新版调用规约相关的知识,希望对你有一定的参考价值。
Go 1.17 修改了用了很久的基于栈的调用规约,在了解 Go 的调用规约之前,我们得知道什么是调用规约。
x86 calling convention[1],简单概括一下,其实就是语言对于函数之间传参的一种约定。调用方要知道我要把参数按照什么形式,什么顺序传给被调用函数,被调用函数也遵守该规范去相应的位置找到传入的参数内容。
老版本的 Go 的参数传递图我们已经在很多很多地方见过了,这里贴一个我之前画的:
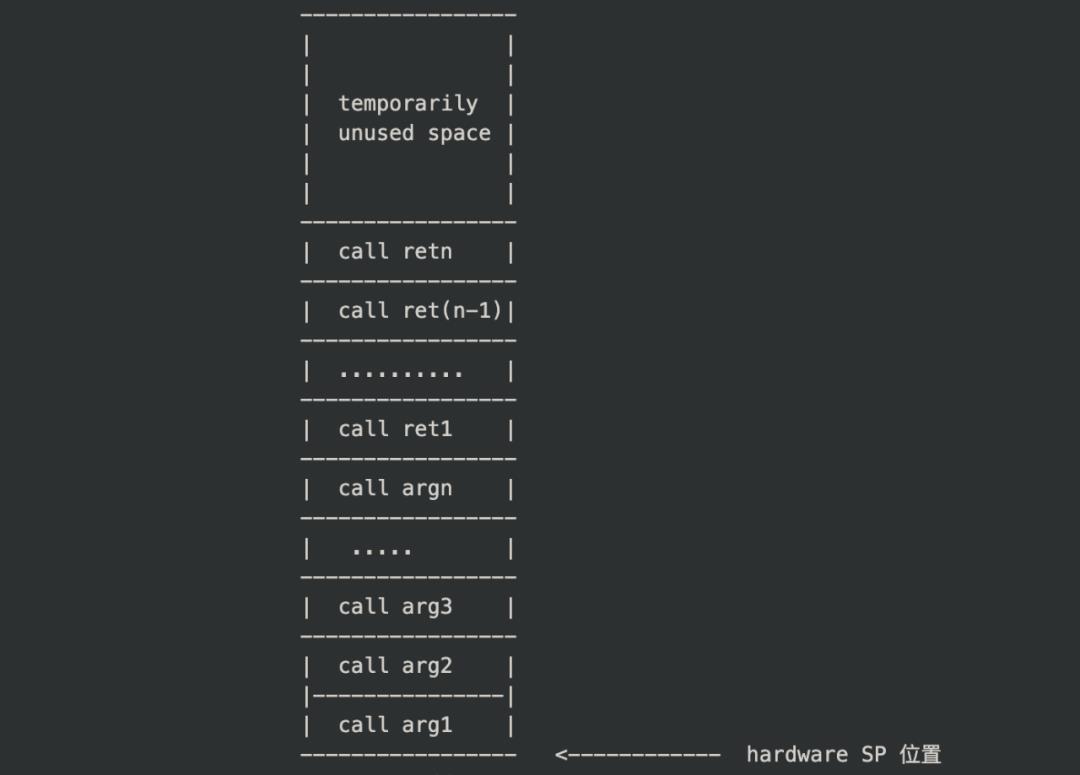
可以看到入参和返回值都在栈上,按顺序,从低地址,到高地址排列。
这种基于栈的传参在设计和实现上确实要简单,但栈上传参会导致函数调用过程中数次发生从寄存器和内存之间的参数搬运操作。比如 call 的时候,要把参数全搬到 SP 的位置(这里从寄存器 -> 内存);ret 的时候,也要把参数从寄存器搬到 FP 位置。ret 完毕之后,要把返回值从内存 -> 寄存器。
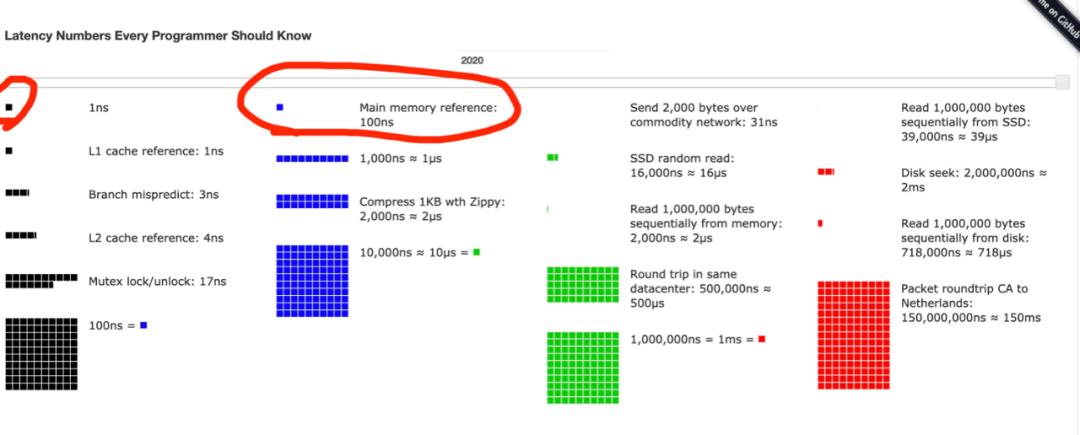
寄存器是 CPU 内部的组件,而主存一般都在外部,两者之间有数量级的性能差异,所以一直有人说 Go 的函数调用性能很差,需要优化(虽然这些人大概率也不是从系统整体性能考虑去做优化的)。
Go 1.17 设计了一套基于寄存器传参的调用规约,目前只在 x86 平台下开启,我们可以通过反汇编对其进行简单的观察。这里依然为了简化问题,我们只用 int 参数(float 使用的不是通用寄存器,其它数据结构需要展开传参,也不难,就是稍微麻烦一点)。
package main
//go:noinline
func add(x int, y int, z int, a, b, c int, d, e, f int, g, h, l int) (int, int, int, int, int, int, int, int, int, int, int) {
println(x, y)
return 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
}
func main() {
println(add(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12))
}稍微多传一些参数方便我们观察,输入 12 个参数,返回 11 个值。
直接看反汇编的结果,首先是对 main.add 的调用部分:
TEXT main.main(SB) /Users/xargin/test/abi.go
abi.go:15 0x1054e60 4c8da42478ffffff LEAQ 0xffffff78(SP), R12
abi.go:15 0x1054e68 4d3b6610 CMPQ 0x10(R14), R12
abi.go:15 0x1054e6c 0f865a020000 JBE 0x10550cc
abi.go:15 0x1054e72 4881ec08010000 SUBQ $0x108, SP
abi.go:15 0x1054e79 4889ac2400010000 MOVQ BP, 0x100(SP)
abi.go:15 0x1054e81 488dac2400010000 LEAQ 0x100(SP), BP
abi.go:16 0x1054e89 48c704240a000000 MOVQ $0xa, 0(SP) // 第 10 个参数
abi.go:16 0x1054e91 48c74424080b000000 MOVQ $0xb, 0x8(SP) // 第 11 个参数
abi.go:16 0x1054e9a 48c74424100c000000 MOVQ $0xc, 0x10(SP) // 第 12 个参数
abi.go:16 0x1054ea3 b801000000 MOVL $0x1, AX // 第 1 个参数,后面以此类推
abi.go:16 0x1054ea8 bb02000000 MOVL $0x2, BX
abi.go:16 0x1054ead b903000000 MOVL $0x3, CX
abi.go:16 0x1054eb2 bf04000000 MOVL $0x4, DI
abi.go:16 0x1054eb7 be05000000 MOVL $0x5, SI
abi.go:16 0x1054ebc 41b806000000 MOVL $0x6, R8
abi.go:16 0x1054ec2 41b907000000 MOVL $0x7, R9
abi.go:16 0x1054ec8 41ba08000000 MOVL $0x8, R10
abi.go:16 0x1054ece 41bb09000000 MOVL $0x9, R11
abi.go:16 0x1054ed4 e807fdffff CALL main.add(SB)
abi.go:16 0x1054ed9 48898424f8000000 MOVQ AX, 0xf8(SP)可以看到,官方只使用了 9 个通用寄存器,依次是 AX,BX,CX,DI,SI,R8,R9,R10,R11,超出部分,按顺序放在栈上。
然后是 main.add 的返回值部分:
TEXT main.add(SB) /Users/xargin/test/abi.go
.... 省略 print 的部分
abi.go:6 0x1054c2f 48c74424400a000000 MOVQ $0xa, 0x40(SP) // 第 10 个返回值
abi.go:6 0x1054c38 48c74424480b000000 MOVQ $0xb, 0x48(SP) // 第 11 个返回值
abi.go:6 0x1054c41 b801000000 MOVL $0x1, AX // 第 1 个返回值,后面以此类推
abi.go:6 0x1054c46 bb02000000 MOVL $0x2, BX
abi.go:6 0x1054c4b b903000000 MOVL $0x3, CX
abi.go:6 0x1054c50 bf04000000 MOVL $0x4, DI
abi.go:6 0x1054c55 be05000000 MOVL $0x5, SI
abi.go:6 0x1054c5a 41b806000000 MOVL $0x6, R8
abi.go:6 0x1054c60 41b907000000 MOVL $0x7, R9
abi.go:6 0x1054c66 41ba08000000 MOVL $0x8, R10
abi.go:6 0x1054c6c 41bb09000000 MOVL $0x9, R11
abi.go:6 0x1054c72 488b6c2418 MOVQ 0x18(SP), BP
abi.go:6 0x1054c77 4883c420 ADDQ $0x20, SP
abi.go:6 0x1054c7b c3 RET返回值和输入使用了完全相同的寄存器序列,同样在超出 9 个返回值时,多出的内容在栈上返回。
在传统的调用规约中,一般会区分 caller saved registers 和 callee saved registers,但在 Go 中,所有寄存器都是 caller saved,也就是由 caller 负责保存,在 callee 中不保证不对其现场进行破坏。
这里可以看到,返回值直接 把入参使用的寄存器 覆盖掉了,也可以证明这一点。
因为函数调用不需要通过栈来传参了,所以在一些函数调用嵌套层次比较深的场景下,goroutine 栈本身使用的内存也有一定概率会降低。不过因为暂时手边没有什么生产环境,暂时也无法验证就是了。
在 Go 语言中,除了基本的函数调用传参,在 reflect 包中有 reflect.Call 的 API 也可以执行函数调用;此外还有 defer 语句中也可以执行函数调用,在创建 goroutine 时也涉及给函数传参。
我们同样可以使用反汇编的手段,来观察这些场景下是否已经进行了基于寄存器的调用优化,本文就不再赘述了。
[1]
x86 calling convention: https://en.wikipedia.org/wiki/X86_calling_conventions
以上是关于简单看看 Go 1.17 的新版调用规约的主要内容,如果未能解决你的问题,请参考以下文章
腾讯再投500亿元资金助力共同富裕;数学家将π计算到62.8万亿位;Go 1.17正式发布|极客头条...