视觉-语言表征学习新进展:提词优化器「琥珀」带你用好CLIP
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视觉-语言表征学习新进展:提词优化器「琥珀」带你用好CLIP相关的知识,希望对你有一定的参考价值。
选自丨机器之心 MMLab@NTU
你是否还在为设计 CLIP 模型的提词器(prompt)而烦恼?到底是「a photo of a [class]」还是「a [class] photo」?对于特定任务(例如食物分类或是卫星图像识别),如何添加符合语境的上下文(context)?本文提出的提词优化器 CoOp(中文名:琥珀)能够给你答案。
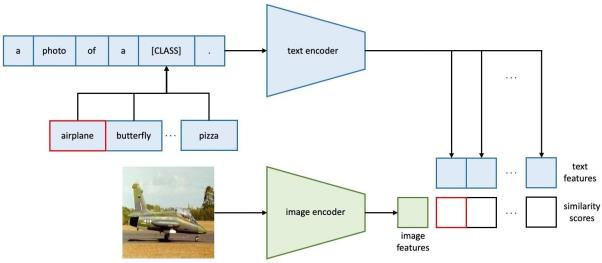
结合视觉和语言的预训练方法(Vision-Language Pretraining)最近成为视觉表征学习一种有前景的方向。不同于使用图像和离散标签进行学习的传统分类器,以 CLIP 为代表的视觉语言预训练模型利用了两个独立的编码器来对齐图像和原始文本。在这种范式下,监督来源变得更加灵活多样且容易获取(如图片评论或网络配图文案都可以做图片监督)。更重要的是,模型变得十分容易零样本(zero-shot)迁移到下游任务。这是因为下游任务的类别不必一定属于训练中离散标签的一种。只要提供下游任务的标签信息,通过适当提词器(prompt)生成的文本向量可以直接代替固定的离散标签。下图展示了 CLIP 模型的结构。
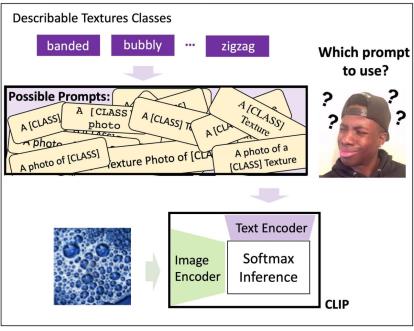
近日,来自新加坡南洋理工大学的研究者发现在实践中部署此类模型的主要挑战是对提词器的设计,这是因为设计合适的提词器需要专业领域的知识,尤其是针对专业类别名要设计专门的语境(即上下文,context)。同时,提词器的设计也需要花费大量时间来调整,因为微小的措辞变化可能会对性能产生巨大影响。例如在下图(a)中,在「a photo of [CLASS]」中的 [CLASS] 前加个「a」直接涨了将近 6 个点!此外,不同的下游任务需要的不同设计(例如图 b-d 中的「flower」、「texture」和「satellite」)也进一步阻碍了部署的效率。

为了克服这一挑战,该研究提出了一种名为上下文优化 (Context Optimization,英文名:CoOp,中文名:琥珀) 的新方法。

-
论文链接:https://arxiv.org/abs/2109.01134
-
代码链接:https://github.com/KaiyangZhou/CoOp
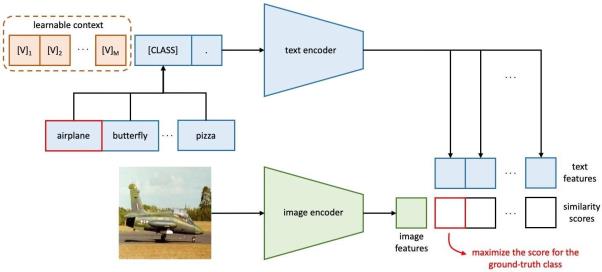
琥珀的主要思想是对提词器(prompt)中的上下文(context)用连续向量进行建模,而整个训练过程将仅对这几个上下文词向量进行端到端优化,而保持预训练参数不变。该方法完全自动化了提词器的设计过程,下图展示了琥珀的模型结构。
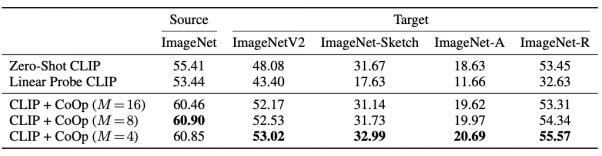
该研究在实验中使用了 11 个视觉数据集来验证琥珀的有效性:结果表明琥珀是一个十分高效的小样本学习方法,平均每个类别只需一到两张图片就可以击败基于手工提词器的零样本识别模型。当每个类别的图片有 16 张时,琥珀比手工提词器平均高出了大约 17 个百分点(最高可达 50 个百分点)。不仅如此,琥珀还对领域泛化表现出了极强的鲁棒性(见下图,其中 M 指代琥珀的提词器长度)。
不过,当研究者在词空间中寻找与优化得到的词向量距离最近的现实词汇时,很难找到有实际含义的词,因为研究者发现即便是最临近的现实词汇,其距离优化得到的词向量仍然相距甚远,并且在词空间中,临近的词向量不一定具有相似的含义。下图展示了 5 个数据集对应的距离最优解最近的 16 词提词器。这进一步表明人工设计的提词器可能始终无法达到琥珀的效果。
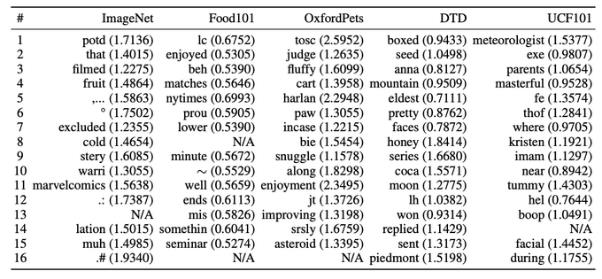
鉴于以上提词器可视化的结果,研究者大胆的推测,在一些数据集上,一些无厘头的提词器,例如「makka pakka akka yakka ikka akka [class]」甚至可能比「a photo of a [class]」在某些数据集上有更好的效果。

更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!
© THE END
投稿或寻求报道微信:MaiweiE_com
GitHub中文开源项目《计算机视觉实战演练:算法与应用》,“免费”“全面“”前沿”,以实战为主,编写详细的文档、可在线运行的notebook和源代码。
-
项目地址 https://github.com/Charmve/computer-vision-in-action
-
项目主页 https://charmve.github.io/L0CV-web/
推荐阅读
(更多“抠图”最新成果)
迈微AI研习社
微信号: MaiweiE_com CSDN、知乎: @Charmve
主页: github.com/Charmve GitHub: @Charmve
投稿: yidazhang1@gmail.com

如果觉得有用,就请点赞、转发吧!
以上是关于视觉-语言表征学习新进展:提词优化器「琥珀」带你用好CLIP的主要内容,如果未能解决你的问题,请参考以下文章
机器人自主学习新进展,百度飞桨发布四足机器人控制强化学习新算法
机器人自主学习新进展,百度飞桨发布四足机器人控制强化学习新算法
长文回顾 | Microsoft Cloud&AI 李琳婕: 多模态预训练模型UNITER, 通用的图像-文本语言表征学习