长文回顾 | Microsoft Cloud&AI 李琳婕: 多模态预训练模型UNITER, 通用的图像-文本语言表征学习
Posted 将门创投
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了长文回顾 | Microsoft Cloud&AI 李琳婕: 多模态预训练模型UNITER, 通用的图像-文本语言表征学习相关的知识,希望对你有一定的参考价值。
本文为的文字内容整理
分享嘉宾:Microsoft Dynamic 365 AI Research 研究工程师 李琳婕
感谢整理人:DataFun 付一韬
背景
UNITER训练数据集
UNITER预训练模型
UNITER下游任务组成
结论
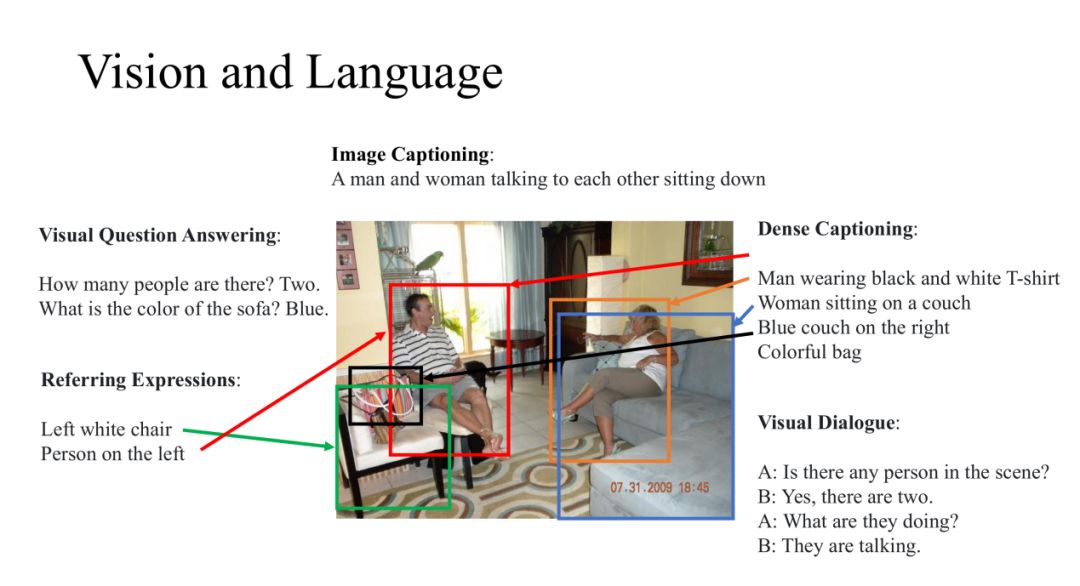
我们的工作都是在Vision和Language研究上面,这些任务需要的模型不仅要对图像或者其他视觉输入进行识别,而且对自然语言也要有很好的理解。这些研究都是在图像和自然语言处理的交界处,所以近年来涌现了很多有意思的新方向。例如:
(1) Image Captioning:给定一张图片,我们可以概括图片内容;
(2) Visual Question Answering:对这张图片进行提问,让模型回答相关的问题;
(3) Dense Captioning:我们也会对图片的细节感兴趣,针对图片的特定区域进行描述;
(4) Referring Expressions:给定一个描述语句,并定位该语句的指定区域;
(5) Visual Dialogue:针对图片还可以进行多轮问答;
▌UNITER训练 数据集
在过去的五年中,Vision+NLP的研究者们做出了很多的努力去提出很多新的任务,同时建起了很多大的数据集,以下列出的是非常有名的数据:

1. 免费数据集上的自监督学习
上面所提到的标注数据需要大量的资金支持,并不是所有研究所都有这个资本收集获得这样的数据集。我们都知道这样的标注数据是很有用的,但是图片和文本本身中就带有这样的标注信息,我们通过自监督的方式进行学习。
① Self-SupervisedLearning for Vision

在图像中我们可以训练CNN模型对一张灰度图片进行上色,从而用CNN来学习对这张图片的表示,这样的图片在网上也是随处可见的。我们还可以使用其他的任务来训练CNN对图片的表示,然后使用这些图片表示来应用到其他分类任务上面。
② Self-SupervisedLearning for NLP

在最近一年里面,NLP也有很大的图谱,具有代表性的工作是Bert和GPT2。这两个任务都是使用Transfomer,Bert应用的是Transformer Encoder,GPT2应用的是Transformer Decoder。这两个工作有一个共同点就是使用了大量免费的数据进行训练。
③ Vision+ NLP

对于Vision+NLP的免费数据集也是有很多的,比如instagram就有随处可见一对相对应的图片和文本,虽然这些文本不是确切的描述图片,但也是高度相关的。
2. 我们的数据集
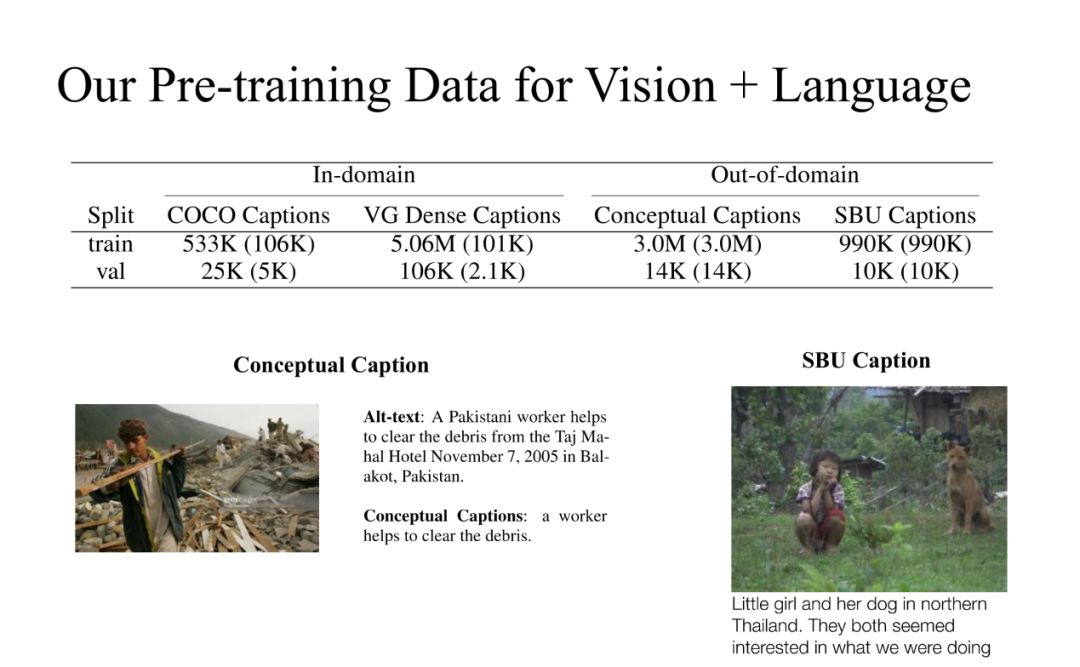
在我们这个实验中,合并了四个公开数据,这四个公开数据分为In-domain和Out-of-domain。
▌UNITER预训练模型
1. UNITER两段式训练任务
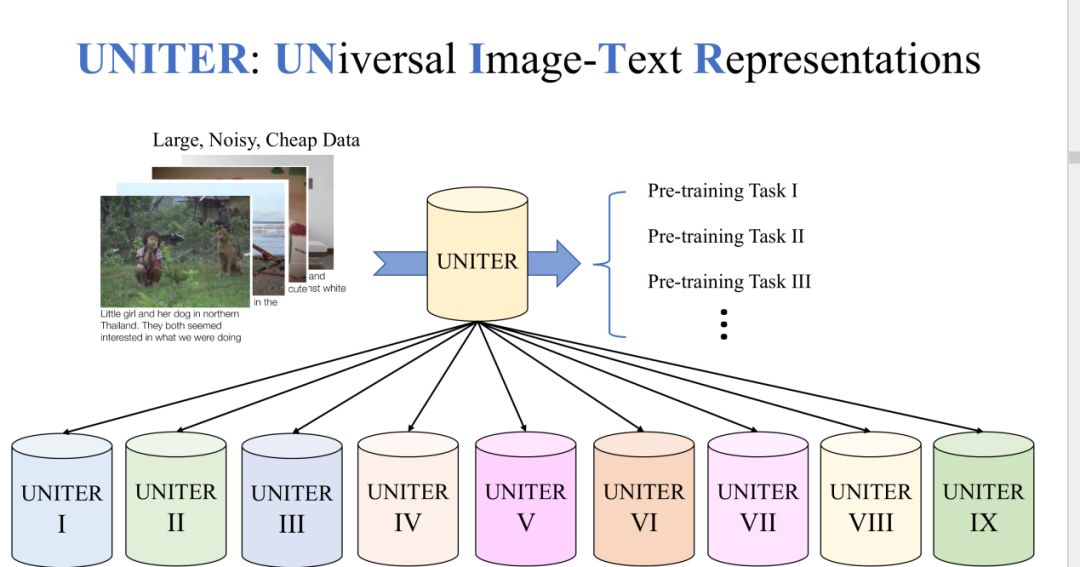
对于UNITER模型我们采用了两段式的训练。先在大量的公开数据集上面做一个预训练任务,在这个阶段可以获取一个健壮的模型。在预训练完成之后,我们将模型通过fine-tuning适应到下游的任务当中。一般来说,在下游任务中的数据都是比较小的,干净的数据集。
我们发现之前的预训练模型只能适应一到两个的下游任务中,我们的目标是让模型可以适应到更多的下游任务。所以在我们的实验中,考虑了9个数据集并且它们之间都有很大的不同,并且有9个fine-tune的模型。
2. 输入方式

我们的数据输入方式是Image-TextPair形式存在的。我们先对image通过模型转换成一系列region,再将text转换成token的序列,将这两部分输入到UNITER模型中。
3. 预训练模型
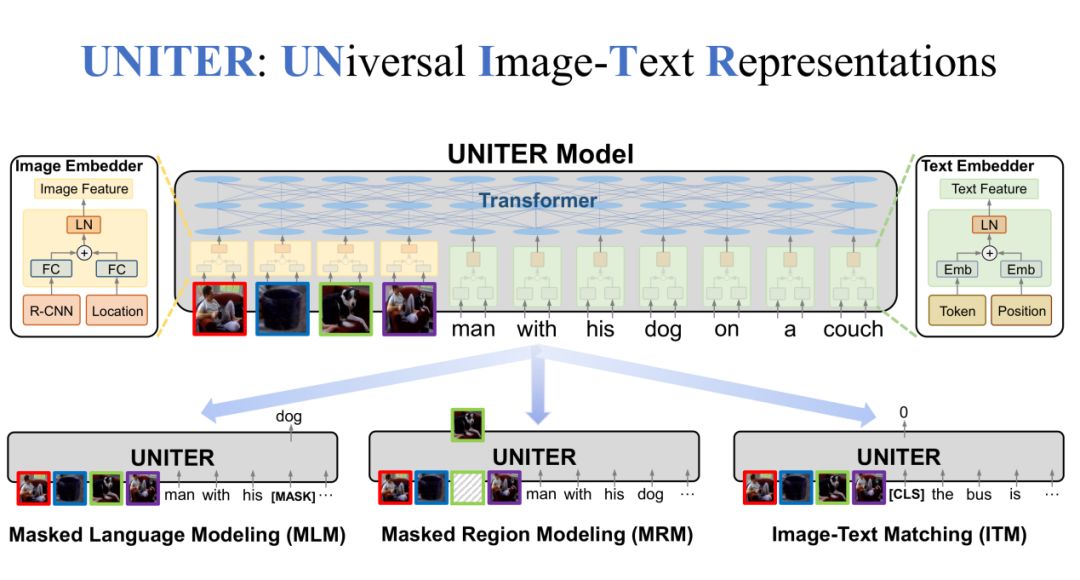
在UNITER模型中,一共有三个部分,分别是Image Embedder、Text Embedder和整体的Transformer模型。在Image Embedder中,Region特征和Location特征通过FC层相加,再经过LN层得到Image特征。在Text Embedder中,Token特征和Position特征经过Embedding之后相加,再经过LN层得到Text特征。最后,Image特征和Text特征经过Transformer得到最终的联合特征。
除此之外,我们还设定了一些预训练任务。比如,随机MASK一些文本中的词,然后对这些MASK的词进行还原,这是MLM任务;同样,我们还可以MASK一些图片中的区域,然后进行还原,这是MRM任务;第三个任务是我们随机抽取positive Image-Text Pair和negative Image-Text Pair,让模型来预测输入的是positive还是negative,这是ITM任务。
MLM预训练任务
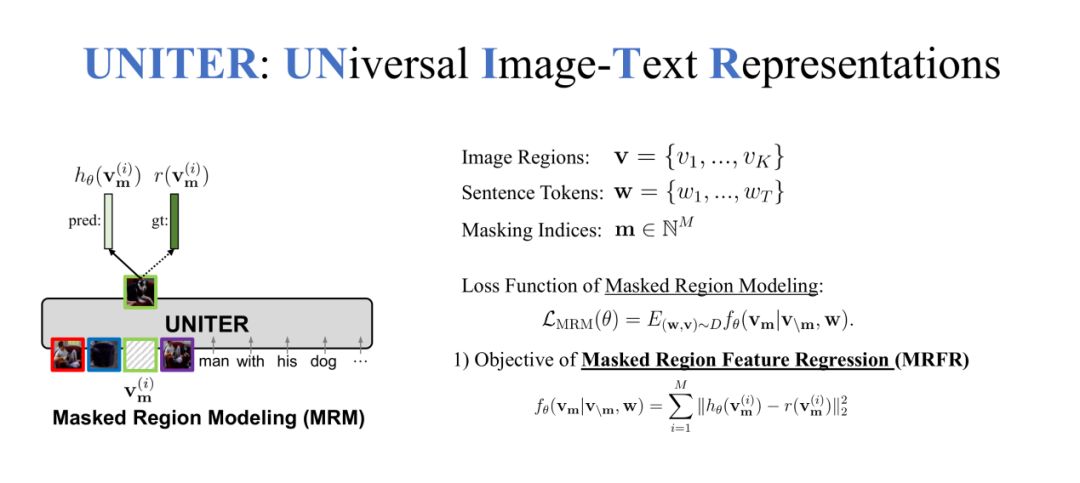
在Masked LanguageModeling(MLM)预训练任务中,我们输入是Image-TextPair,获取到image regions和sentence tokens。在sentence tokens中随机MASK掉一些token,让UNITER来还原这些token。
MRM预训练任务(MRFR)
在第二个MaskedRegion Modeling(MRM)预训练任务中,我们MASK的不是token而是region,需要还原这些缺失的region。我们在MRM任务中提出了三种不同的方法,第一种方法是Masked Region Feature Regression(MRFR)。
对于每个region都有一个特征,这是一个高维的向量,可以让UNITER来预测这个高维的向量,我们希望UNITER输出的向量尽可能的接近被MASK掉的region特征向量,所以使用L2 loss来让两个向量的距离尽可能的小,使两个特征尽可能相似。
MRM预训练任务(MRC)

MRM的第二种方法是Masked Region Classification(MRC),每一个region得到特征向量之后R-CNN都会预测一个label,我们让UNITER来对MASK的region进行预测,使模型学习到每个MASK region的分类。
MRM预训练任务(MRC-kl)

MRM的第三种方法是Masked Region Classification-KLDivergence(MRC-kl),除了对MASK region计算分类label,还可以计算UNITER与R-CNN对MASK region的分布差异,我们希望UNITER的region分布要尽可能接近R-CNN的region分布,loss使用KL散度。
ITM预训练任务

最后的预训练任务是Image-TextMatching(ITM),我们对输入的Image-TextPair随机替换Image或者Text,最后预测输入的Image和Text是否有对应关系,所以这是一个二分类的问题。
4. 优化训练方式
由于计算资源的限制,我们需要一些方法来加速训练速度,这里面使用了三个技巧。分别是Dynamic Batching、Gradient Accumulation和Mixed-precision Training。
DynamicBatching

在Dynamic Batching这种方法是对训练过程中动态的选择batch中的sample。因为Transformer的复杂度是跟region和word的数量(L)二次方相关的。一般来说batch中的长度都是像上图左部分那样,所有输入都pad成同样的长度,蓝色是输入的部分,白色是pad的部分,可以看出浪费了很多空间。
我们的方法是将长度相近的sample放到同一个batch中,这样可以减少pad的长度,从而减少计算空间。
GradientAccumulation

在实验中,我们使用了4个GPU,主要时间是浪费在GPU之间交换数据上面了,所以我们使用Gradient Accmulation的方法来减少GPU之间的交互频率上,从而减少训练时间。
Mixed-precisionTraining
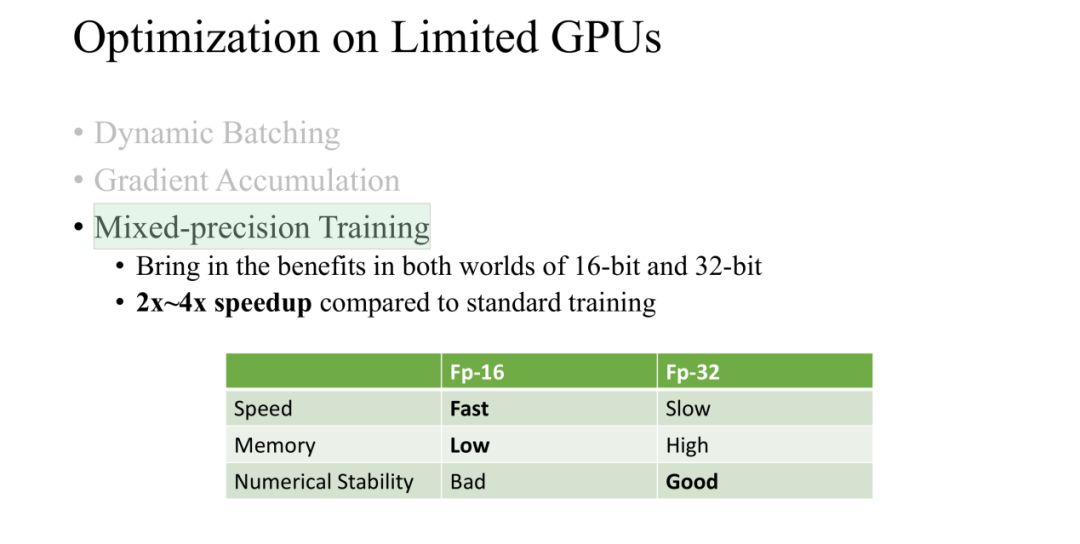
在训练过程中,我们使用了Mixed-precision的方法进行训练,分别使用16-bit和32-bit,节省了空间从而batch size可以增大,这样就减少了训练时间。
▌下游任务组成
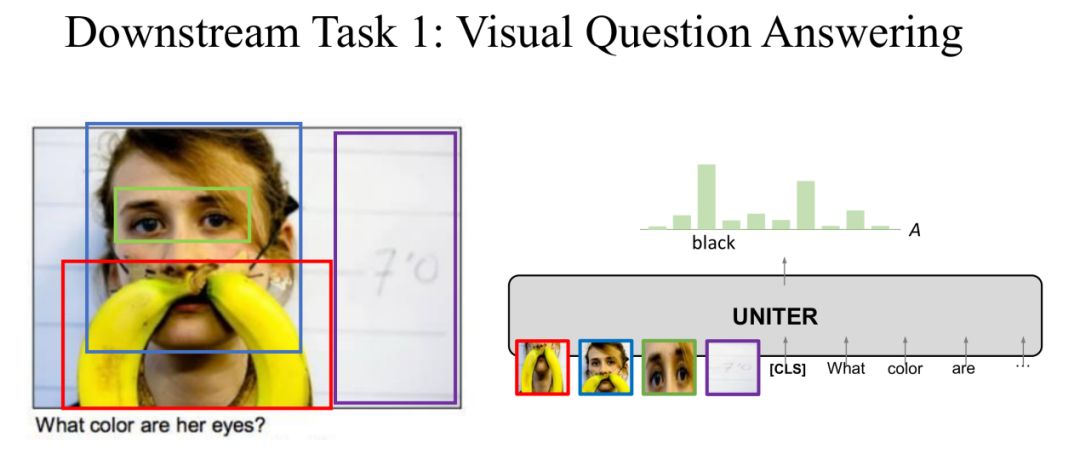
在第一个下游任务VQA中,对于一个图片回答图片内容相关的问题。将图片和问题输入到UNITER中,输出是答案的分布,取概率最大的答案为预测答案。
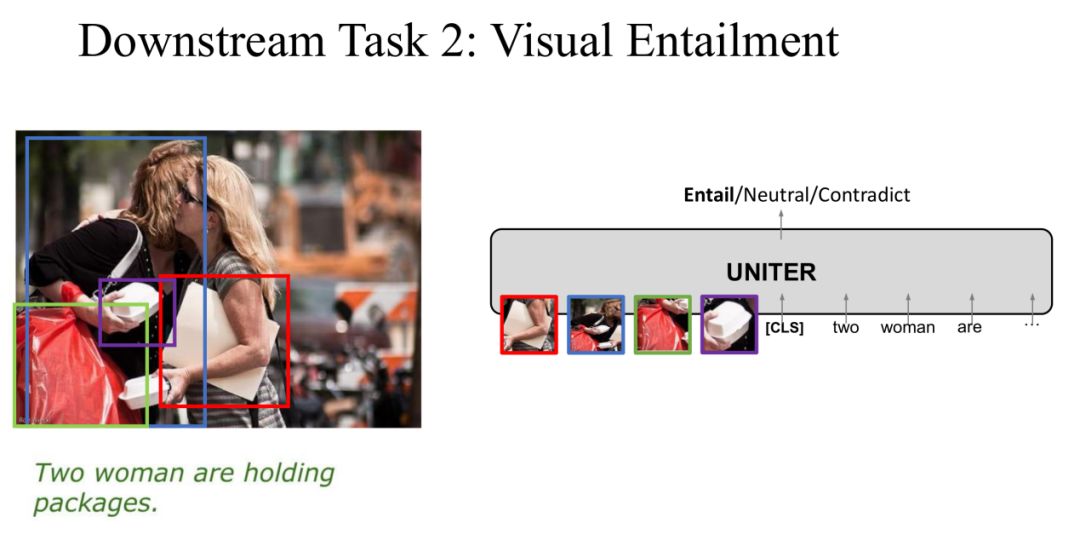
Task 2: Visual Entailment

在第二个任务VisualEntailment中,Image是Premise,Text是Hypothesis,我们的目标是预测Text是不是“Entailment Image”,一共有三个label分别是Entailment、Neutral和Contradiction。
同样,我们将Image和Text输入到UNITER中,输出是三个label中的一个作为预测分类。
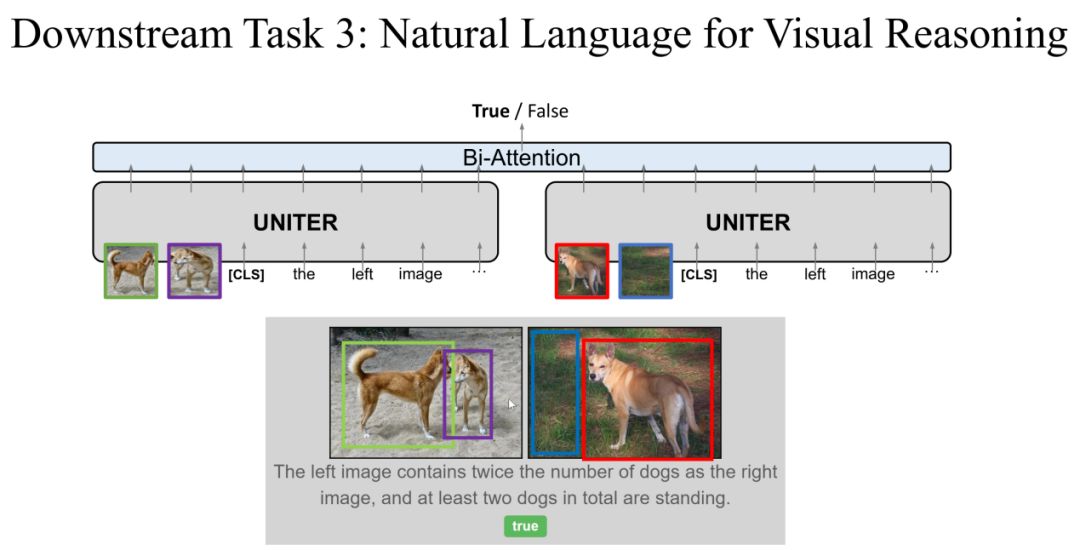
Task 3: Natural Languagefor Visual Reasoning

第三个任务是NLVR(Natural Language for Visual Reasoning),这个任务不同于前两个任务,同时输入两张Image和一个描述,输出是描述与Image的对应关系是否一致,label为两个(true/false)。
在这个任务中,我们对UNITER的模型进行稍微的改进,一个描述与两个Image分别输入到UNITER中,两个输出在经过Bi-Attention层输出预测的label。在这个任务上面我们证明了对UNITER进行稍微的改动就可以处理不一样的任务。
Task 4: Visual Commonsense Reasoning

第四个任务是VisualCommonsense Reasoning,它是以选择题形式存在的,对于一个问题有四个备选答案,模型必须从四个答案中选择出一个答案,然后再从四个备选理由中选出选择这个答案的理由。
在训练的过程中,我们将问题和四个备选答案连接到一起再分别与图片输入到UNITER中,输出为四个得分,得分最高的为预测答案。同理,在选择理由的时候将问题、答案和四个备选理由分别连接到一起输入到UNITER中。

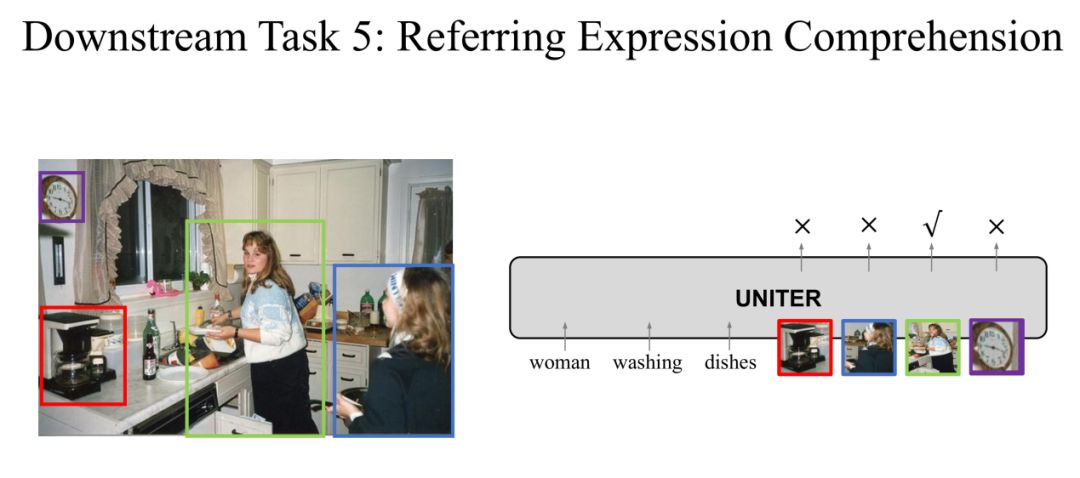
Task 5: Referring Expression Comprehension

在第五个ReferringExpression Comprehension任务中,输入是一个句子,模型要在图片中圈出对应的region。
对于这个任务,我们可以对每一个region都输出一个score,score最高的region作为预测region。
Task 6: Image-TextRetrieval
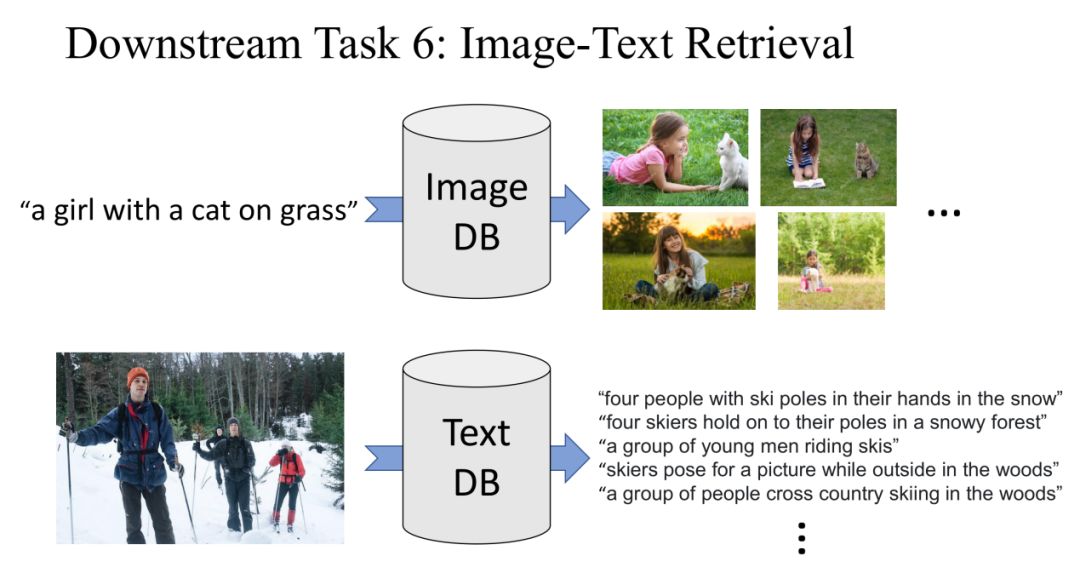
在最后一个Image-TextRetrieval任务中,首先我们给定一个句子,在Image DataBase中获取与句子相关的Image。另外,我们还可以给定一个Image,在Text DataBase中获取与图片相关的Text。
这个任务与我们预训练的Image-TextMatching任务非常相似,所以在fine-tune的过程中我们选择positive pair和negative pair的方式来训练我们的模型。UNITER的目标就是预测positive还是negative。

▌结论
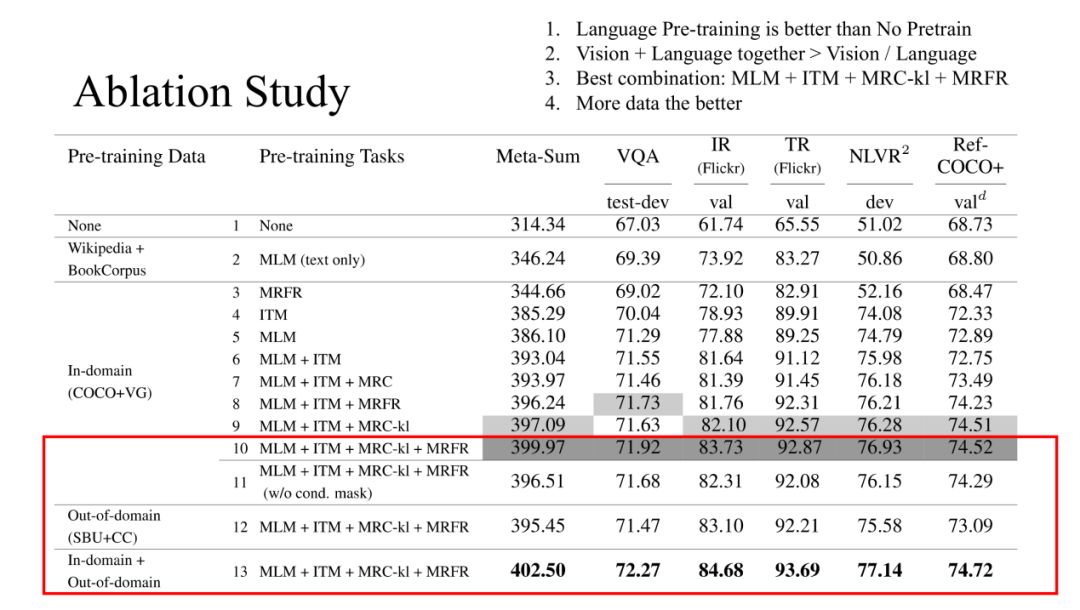
以上是我们针对不同预训练任务的组合在5个下游任务的表现对比。从表中我们可以得出:
(1) 有文本的预训练任务比没有文本的预训练任务效果更好;
(2) Vison+Language组合的预训练效果要好于单独的Vision/Language;
(3) 最好的预训练组合是:MLM+ITM+MRC-kl+MRFP;
(4) 将上面提到的四个数据一起训练效果最好,这也证明数据越多效果越好。
2. 综合任务成绩比较
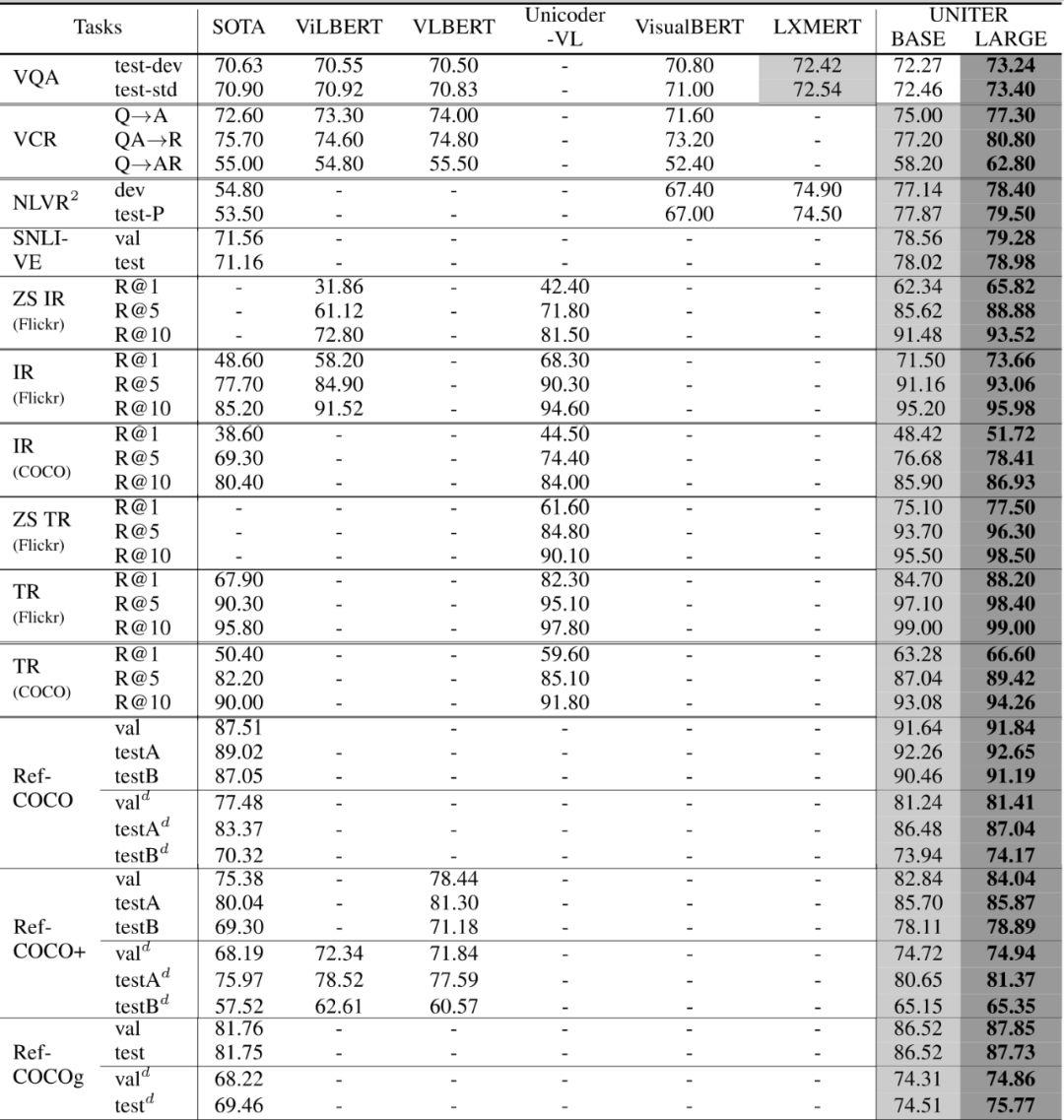
上面表格展现了UNITERBase和Large在6个下游任务,包含9个数据集的表现效果。UNITER-Base在9个数据集上面几乎都好于其他的模型,而UNITER-Large取得了当前最好的效果。


来扫我呀
关于我门
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门技术社群以及将门创投基金。将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
将门创新服务专注于使创新的技术落地于真正的应用场景,激活和实现全新的商业价值,服务于行业领先企业和技术创新型创业公司。
将门技术社群专注于帮助技术创新型的创业公司提供来自产、学、研、创领域的核心技术专家的技术分享和学习内容,使创新成为持续的核心竞争力。
将门创投基金专注于投资通过技术创新激活商业场景,实现商业价值的初创企业,关注技术领域包括机器智能、物联网、自然人机交互、企业计算。在近四年的时间里,将门创投基金已经投资了包括量化派、码隆科技、禾赛科技、宽拓科技、杉数科技、迪英加科技等数十家具有高成长潜力的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”: bp@thejiangmen.com
将门创投
让创新获得认可!
微信:thejiangmen
bp@thejiangmen.com
点击“❀在看”,让更多朋友们看到吧~
以上是关于长文回顾 | Microsoft Cloud&AI 李琳婕: 多模态预训练模型UNITER, 通用的图像-文本语言表征学习的主要内容,如果未能解决你的问题,请参考以下文章