什么是联邦学习
Posted 跨链技术践行者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是联邦学习相关的知识,希望对你有一定的参考价值。
联邦学习是一种带有隐私保护、安全加密技术的分布式机器学习框架,旨在让分散的各参与方在满足不向其他参与者披露隐私数据的前提下,协作进行机器学习的模型训练。
经典联邦学习框架的训练过程可以简单概括为以下步骤:
-
协调方建立基本模型,并将模型的基本结构与参数告知各参与方;
-
各参与方利用本地数据进行模型训练,并将结果返回给协调方;
-
协调方汇总各参与方的模型,构建更精准的全局模型,以整体提升模型性能和效果。
联邦学习框架包含多方面的技术,比如传统机器学习的模型训练技术、协调方参数整合的算法技术、协调方与参与方高效传输的通信技术、隐私保护的加密技术等。此外,在联邦学习框架中还存在激励机制,数据持有方均可参与,收益具有普遍性。
Google首先将联邦学习运用在Gboard(Google键盘)上,联合用户终端设备,利用用户的本地数据训练本地模型,再将训练过程中的模型参数聚合与分发,最终实现精准预测下一词的目标。
除了分散的本地用户,联邦学习的参与者还可以是多家面临数据孤岛困境的企业,它们拥有独立的数据库但不能相互分享。联邦学习通过在训练过程中设计加密式参数传递代替原有的远程数据传输,保证了各方数据的安全与隐私,同时满足了已出台的法律法规对数据安全的要求。
02 联邦学习的架构思想
联邦学习的架构分为两种,一种是中心化联邦(客户端/服务器)架构,一种是去中心化联邦(对等计算)架构。
-
针对联合多方用户的联邦学习场景,一般采用的是客户端/服务器架构,企业作为服务器,起着协调全局模型的作用;
-
而针对联合多家面临数据孤岛困境的企业进行模型训练的场景,一般可以采用对等架构,因为难以从多家企业中选出进行协调的服务器方。
在客户端/服务器架构中,各参与方须与中央服务器合作完成联合训练,如图2-1所示。当参与方不少于两个时,启动联邦学习过程。
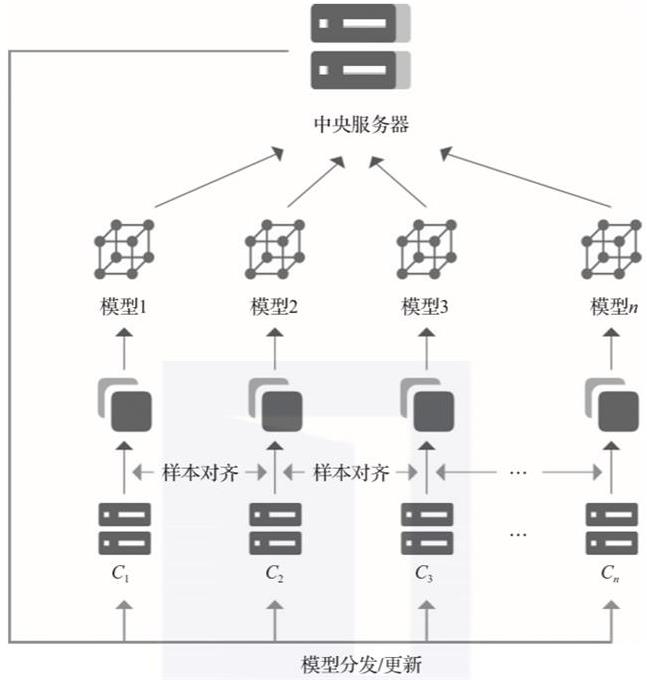
▲图2-1 联邦学习系统客户端/服务器架构
在正式开始训练之前,中央服务器先将初始模型分发给各参与方,然后各参与方根据本地数据集分别对所得模型进行训练。接着,各参与方将本地训练得到的模型参数加密上传至中央服务器。中央服务器对所有模型梯度进行聚合,再将聚合后的全局模型参数加密传回至各参与方。
在对等计算架构中,不存在中央服务器,所有交互都是参与方之间直接进行的,如图2-2所示。
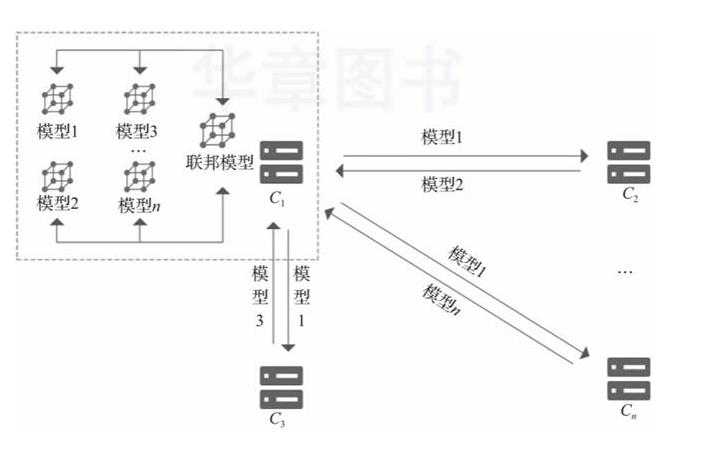
▲图2-2 联邦学习对等系统架构
当参与方对原始模型训练后,需要将本地模型参数加密传输给其余参与联合训练的数据持有方。因此,假设本次联合训练有n个参与方,则每个参与方至少需要传输2(n-1)次加密模型参数。
在对等架构中,由于没有第三方服务器的参与,参与方之间直接交互,需要更多的加解密操作。在整个过程中,所有模型参数的交互都是加密的。目前,可以采用安全多方计算、同态加密等技术实现。全局模型参数的更新可运用联邦平均等聚合算法。当需要对参与方数据进行对齐时,可以采用样本对齐等方案。
03 联邦学习的应用场景
根据各方数据集的贡献方式不同,可以将联邦学习具体分为横向联邦学习、纵向联邦学习和联邦迁移学习,每种技术细分对应不同场景。
1. 横向联邦学习
如图2-3所示,横向联邦学习适用于各数据持有方的业务类型相似、所获得的用户特征多而用户空间只有较少重叠或基本无重叠的场景。例如,各地区不同的商场拥有客户的购物信息大多类似,但是用户人群不同。
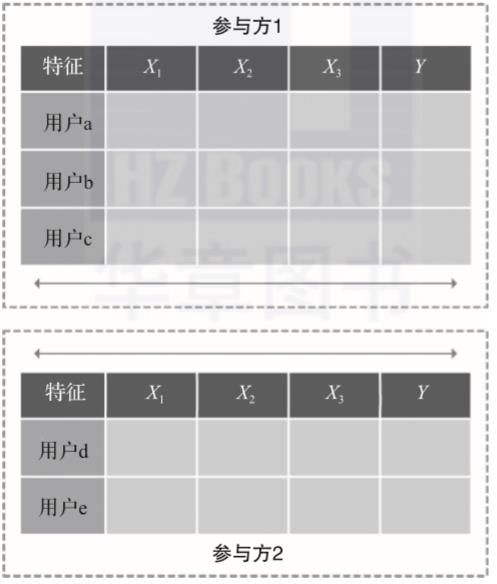
▲图2-3 横向联邦学习图解
横向联邦学习以数据的特征维度为导向,取出参与方特征相同而用户不完全相同的部分进行联合训练。在此过程中,通过各参与方之间的样本联合,扩大了训练的样本空间,从而提升了模型的准确度和泛化能力。
2. 纵向联邦学习
如图2-4所示,纵向联邦学习适用于各参与方之间用户空间重叠较多,而特征空间重叠较少或没有重叠的场景。例如,某区域内的银行和商场,由于地理位置类似,用户空间交叉较多,但因为业务类型不同,用户的特征相差较大。
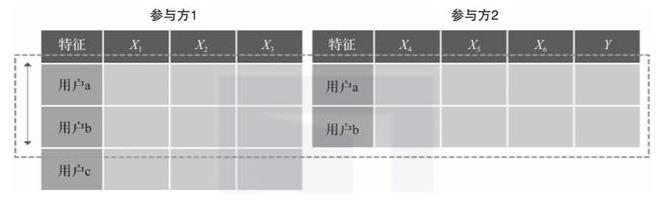
▲图2-4 纵向联邦学习图解
纵向联邦学习是以共同用户为数据的对齐导向,取出参与方用户相同而特征不完全相同的部分进行联合训练。因此,在联合训练时,需要先对各参与方数据进行样本对齐,获得用户重叠的数据,然后各自在被选出的数据集上进行训练。
此外,为了保证非交叉部分数据的安全性,在系统级进行样本对齐操作,每个参与方只有基于本地数据训练的模型。
3. 联邦迁移学习
联邦迁移学习是对横向联邦学习和纵向联邦学习的补充,适用于各参与方用户空间和特征空间都重叠较少的场景。例如,不同地区的银行和商场之间,用户空间交叉较少,并且特征空间基本无重叠。在该场景下,采用横向联邦学习可能会产生比单独训练更差的模型,采用纵向联邦学习可能会产生负迁移的情况。
联邦迁移学习基于各参与方数据或模型之间的相似性,将在源域中学习的模型迁移到目标域中。大多采用源域中的标签来预测目标域中的标签准确性。
04 联邦学习的优势与前景
分布式机器学习框架通过集中收集数据,再将数据进行分布式存储,将任务分散到多个CPU/GPU机器上进行处理,从而提高计算效率。与之不同的是,联邦学习强调将数据一开始就保存在参与方本地,并且在训练过程中加入隐私保护技术,拥有更好的隐私保护特性。
各参与方的数据一直保存在本地,在建模过程中,各方的数据库依然独立存在,而联合训练时进行的参数交互也是经过加密的,各方通信时采用严格的加密算法,难以泄露原始数据的相关信息,因而联邦学习保证了数据的安全与隐私。
此外,联邦学习技术可使分布式训练获得的模型效果与传统中心式训练效果相差无几,训练出的全局模型几乎是无损的,各参与方能够共同获益。
在大数据与人工智能快速发展的当下,联邦学习解决了人工智能模型训练中各方数据不可用、隐私泄露等问题,因而应用前景十分广阔。联邦学习可用于在海量数据集下的模型训练,实现部门、企业及组织之间的联动。例如:
-
在智慧金融领域中,可以根据多方数据建立更准确的业务模型,从而实现合理定价、定向业务推广、企业风控评定等;
-
在智慧城市中,实现各政府机构之间、企业与政府之间的联合,实现更准确的实时交通预测,更简化的机关办事步骤,更高效的信息内容查询,更全面的安全防控检测等;
-
在智慧医疗中,联邦学习可以综合各医院之间的数据,提高医疗影像诊断的准确性,预警病人的身体情况等。
上述举例只是联邦学习可用领域中的一部分,未来它将覆盖更广阔的应用场景。
05 小结
本文对联邦学习进行了系统性概述。联邦学习基于分布式机器学习框架,拥有严格的隐私保护策略,保证了各参与方数据的安全。联邦学习有客户端/服务器架构和对等架构两种架构,不同的架构下交互方式不同。
不论是在何种架构下,联邦学习过程都可以保证隐私安全,符合数据条例和参与方共同受益原则。基于场景中各方数据的特征对比,联邦学习可以分为横向联邦学习、纵向联邦学习和联邦迁移学习。此外,在智慧城市、智慧医疗、智慧金融等实际场景中,联邦学习拥有广阔的应用和发展前景。
以上是关于什么是联邦学习的主要内容,如果未能解决你的问题,请参考以下文章