5分钟教会你用Python采集CSDN的热榜
Posted 小小明-代码实体
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5分钟教会你用Python采集CSDN的热榜相关的知识,希望对你有一定的参考价值。
上次发了一篇《热榜标题词云实时更新词云上线,给标题起名提供参观建议》,今天突然上热榜一一段时间,还被范博at了。虽然对上热榜本身已经无感,但是被范博at还非常让我高兴的。
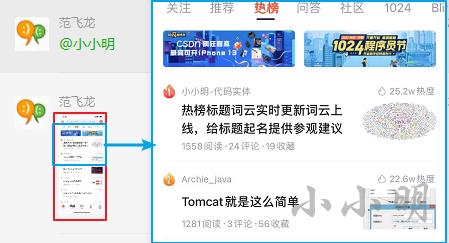
这到晚上后,有人在评论区问到热榜数据怎么爬。
热心的我,现在就花几分钟时间教会大家。
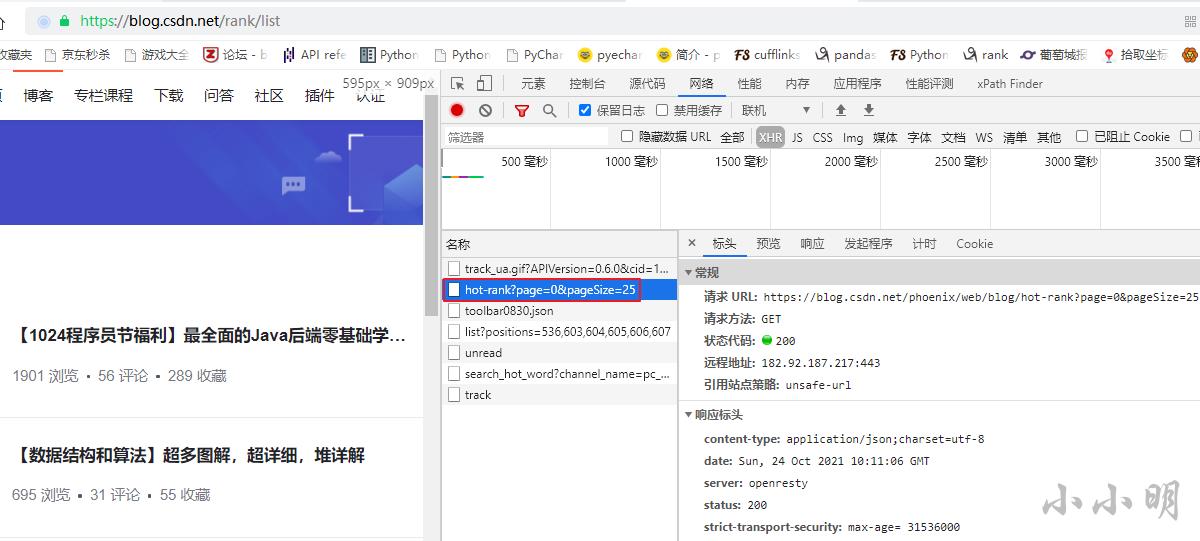
首先,打开热榜页面并打开开发者工具,监控xhr类型的请求:
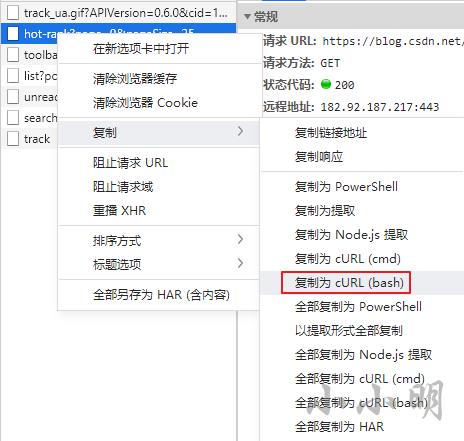
然后复制为curl(bash)类型的请求:
然后我们在jupyte中执行:
!curl2py
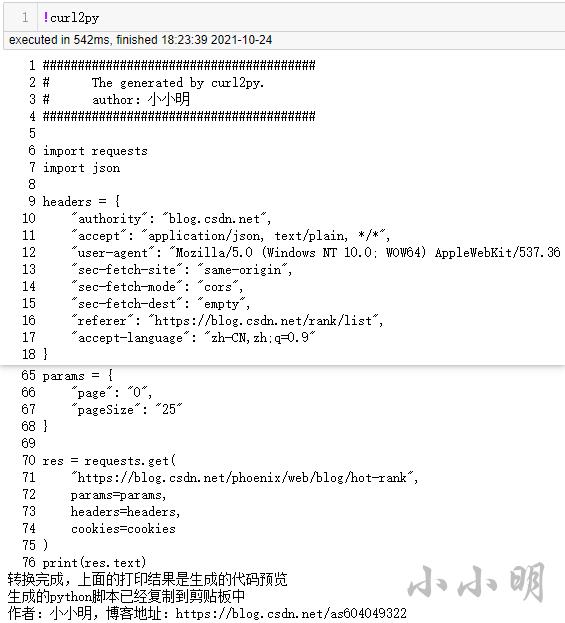
注意:该命令需要安装filestools
安装命令:pip install filestools
然后就可以将当前请求的python代码粘贴出来了,删除cookie部分后如下:
import requests
import json
headers = {
"authority": "blog.csdn.net",
"accept": "application/json, text/plain, */*",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"sec-fetch-site": "same-origin",
"sec-fetch-mode": "cors",
"sec-fetch-dest": "empty",
"referer": "https://blog.csdn.net/rank/list",
"accept-language": "zh-CN,zh;q=0.9"
}
params = {
"page": "0",
"pageSize": "25"
}
res = requests.get(
"https://blog.csdn.net/phoenix/web/blog/hot-rank",
params=params,
headers=headers,
)
print(res.text)
这样我们就能获取到热榜第一页的数据。
稍微改进一下代码,循环爬取四页:
import pandas as pd
import requests
headers = {
"authority": "blog.csdn.net",
"accept": "application/json, text/plain, */*",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"sec-fetch-site": "same-origin",
"sec-fetch-mode": "cors",
"sec-fetch-dest": "empty",
"referer": "https://blog.csdn.net/rank/list",
"accept-language": "zh-CN,zh;q=0.9"
}
session = requests.session()
session.get("https://blog.csdn.net/rank/list", headers=headers)
params = {
"page": "",
"pageSize": "25"
}
result = []
for i in range(4):
params["page"] = str(i)
res = session.get(
"https://blog.csdn.net/phoenix/web/blog/hot-rank", params=params, headers=headers)
df = pd.DataFrame(res.json()['data'])[[
"userName", "nickName", "articleTitle", "viewCount",
"commentCount", "favorCount", "articleDetailUrl", "hotRankScore"]]
result.append(df)
hot_rank = pd.concat(result, ignore_index=True)
hot_rank.commentCount = hot_rank.commentCount.astype(int)
hot_rank.favorCount = hot_rank.favorCount.astype(int)
hot_rank.viewCount = hot_rank.viewCount.astype(int)
hot_rank.hotRankScore = hot_rank.hotRankScore.astype(int)
hot_rank.index += 1
hot_rank.reset_index(inplace=True)
hot_rank.columns = ["排名", "csdnid", "昵称", "标题", "阅读", "评论", "收藏", "链接", "热度"]
hot_rank

这样我们就获取热榜100条的所有数据了。
就是这么简单,童鞋们都再也不用担心不会采集热榜了。
以上是关于5分钟教会你用Python采集CSDN的热榜的主要内容,如果未能解决你的问题,请参考以下文章