CSDN热榜排名追踪工具上线,随时查看热榜链路数据
Posted 小小明-代码实体
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CSDN热榜排名追踪工具上线,随时查看热榜链路数据相关的知识,希望对你有一定的参考价值。
大家好,我是小小明。
今天大家期待已久的热榜追踪神器上线了,包含历史热榜搜索器和近两日热榜排名等。
历史热榜追踪数据搜索:http://xxmdmst.top:8000/static/search.html
热榜涨粉榜top50:http://xxmdmst.top:8000/rankfollow/
热榜追踪程序演示
下面我们分别来看看这两个网页:
历史热榜追踪数据搜索
打开网页后界面如下:
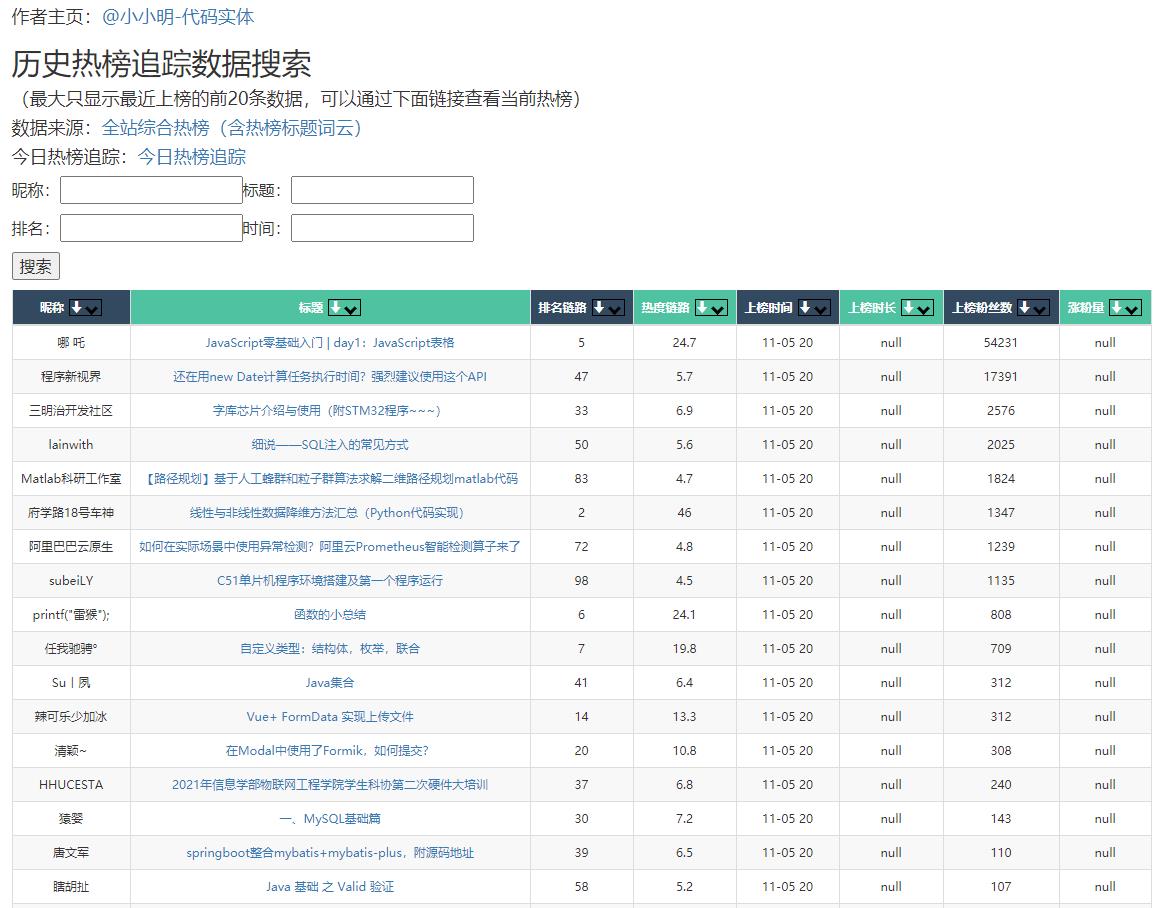
该网页默认展示最近上榜的20条数据,我们可以通过搜索找到我们需要的数据。
例如我们想查看昵称中包含java的用户上榜情况,可以再昵称输入框输入java后回车:
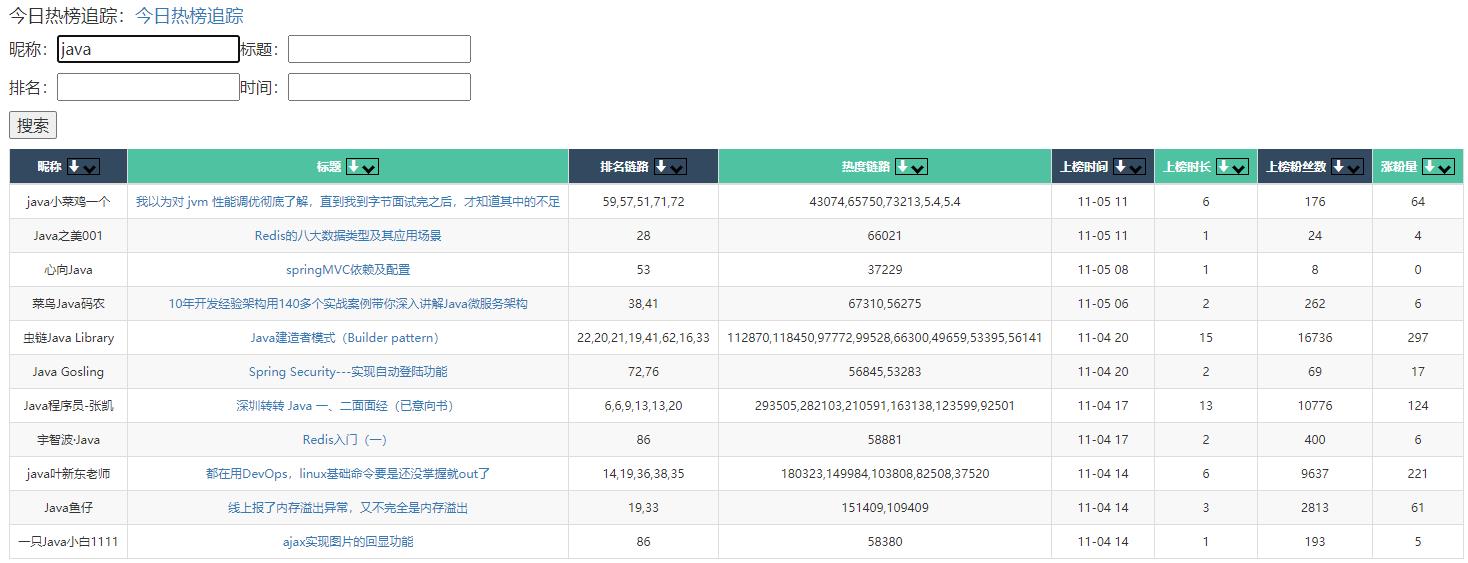
可以看到上榜时间,小时数,以及在热榜期间的涨粉量都一目了然。我们可以通过表格组件对查询结果进行二次排序:
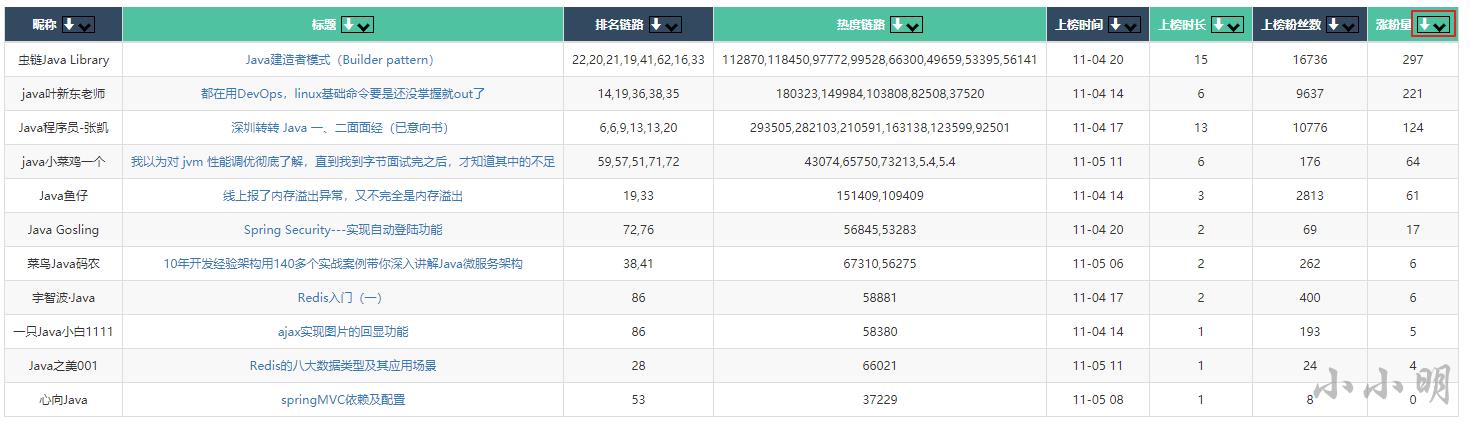
这就是按涨粉量排序后的结果。
当前目前我截图的数据热度链接比较长,我目前已经更新按照万为单位保留一位小数进行追加。
还可以搜索近20条标题包含python的上榜数据,多个条件也支持组合查询。
关于排名有一些搜索小技巧,这里的排名是根据排名链接进行搜索的,我们可以根据条件,1,搜索近期上过榜一的文章(不包含仅一上榜就到榜1的):
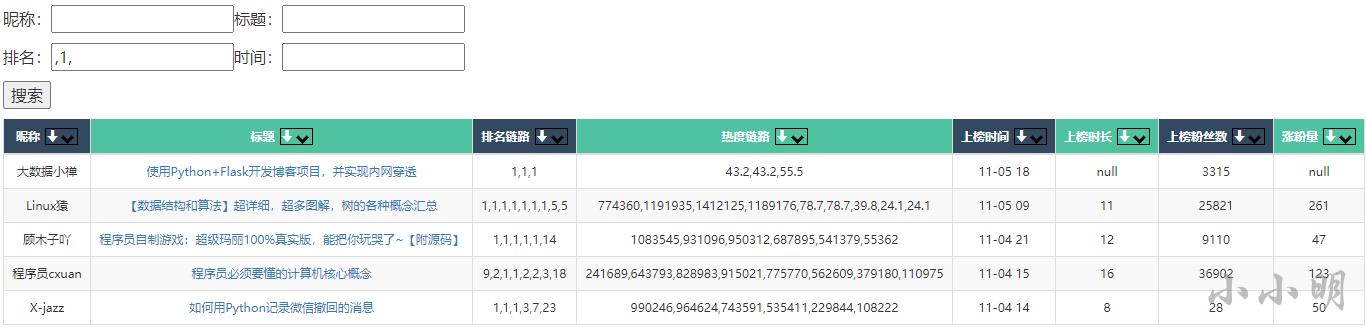
注意:上榜时长为null表示该条数据当前还在热榜中。
我们还可以通过_搜索上过榜前9的数据:
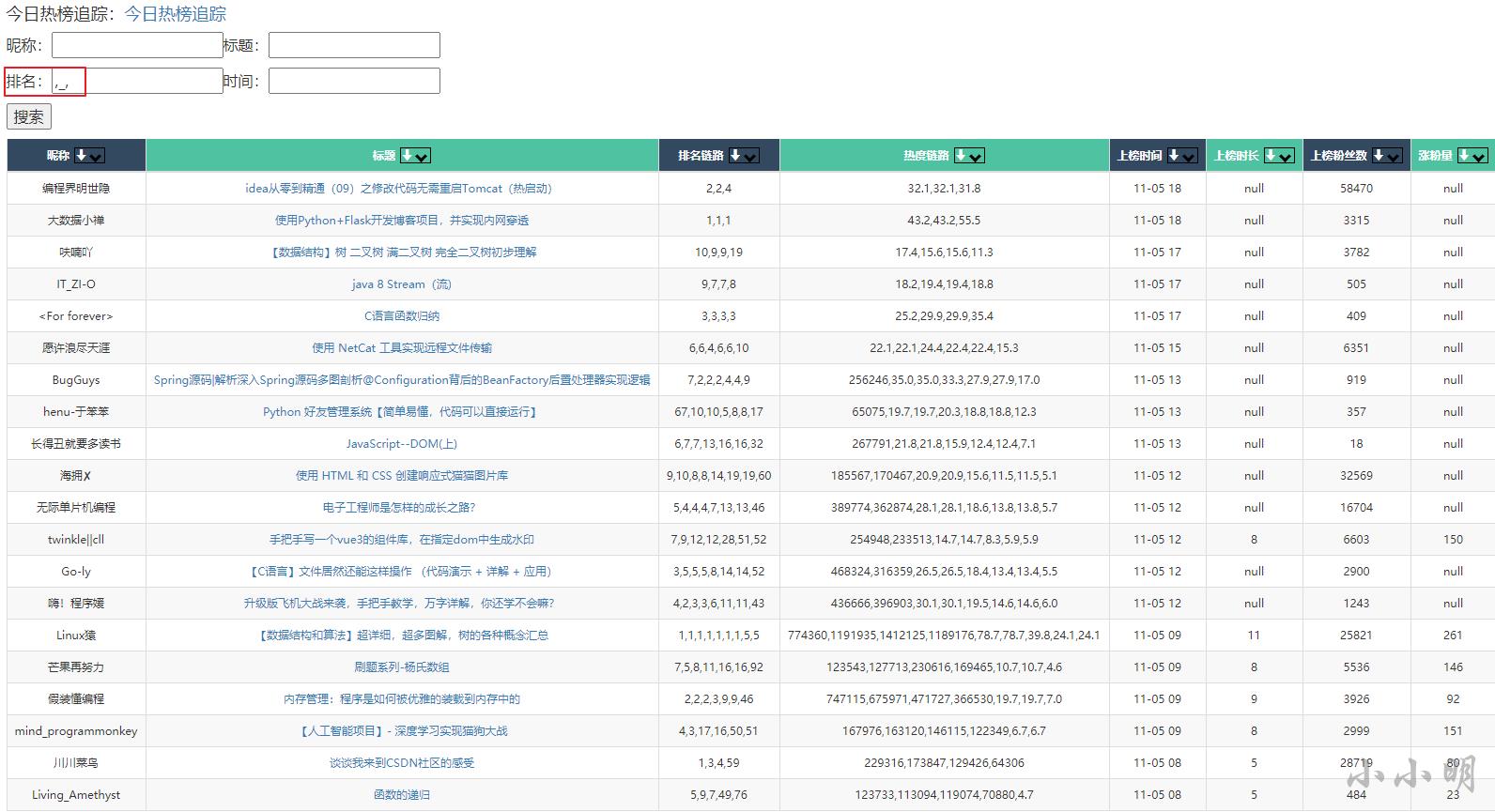
最后根据日期我们可以搜索指定日期上榜的数据,例如搜索11月4号上过榜前9的数据:
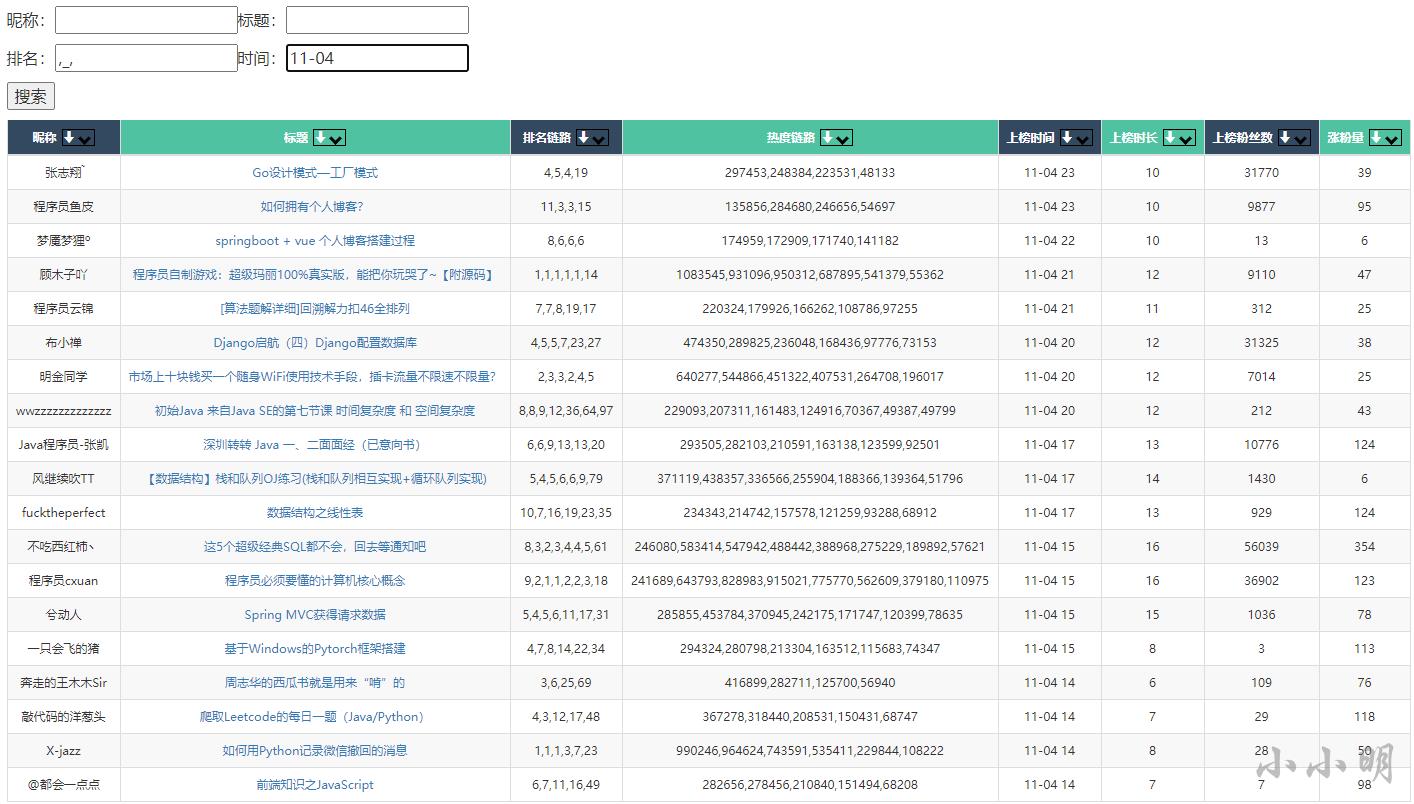
热榜追踪热榜涨粉top50
在另一个页面http://xxmdmst.top:8000/rankfollow/则显示今日热榜的涨粉top50:
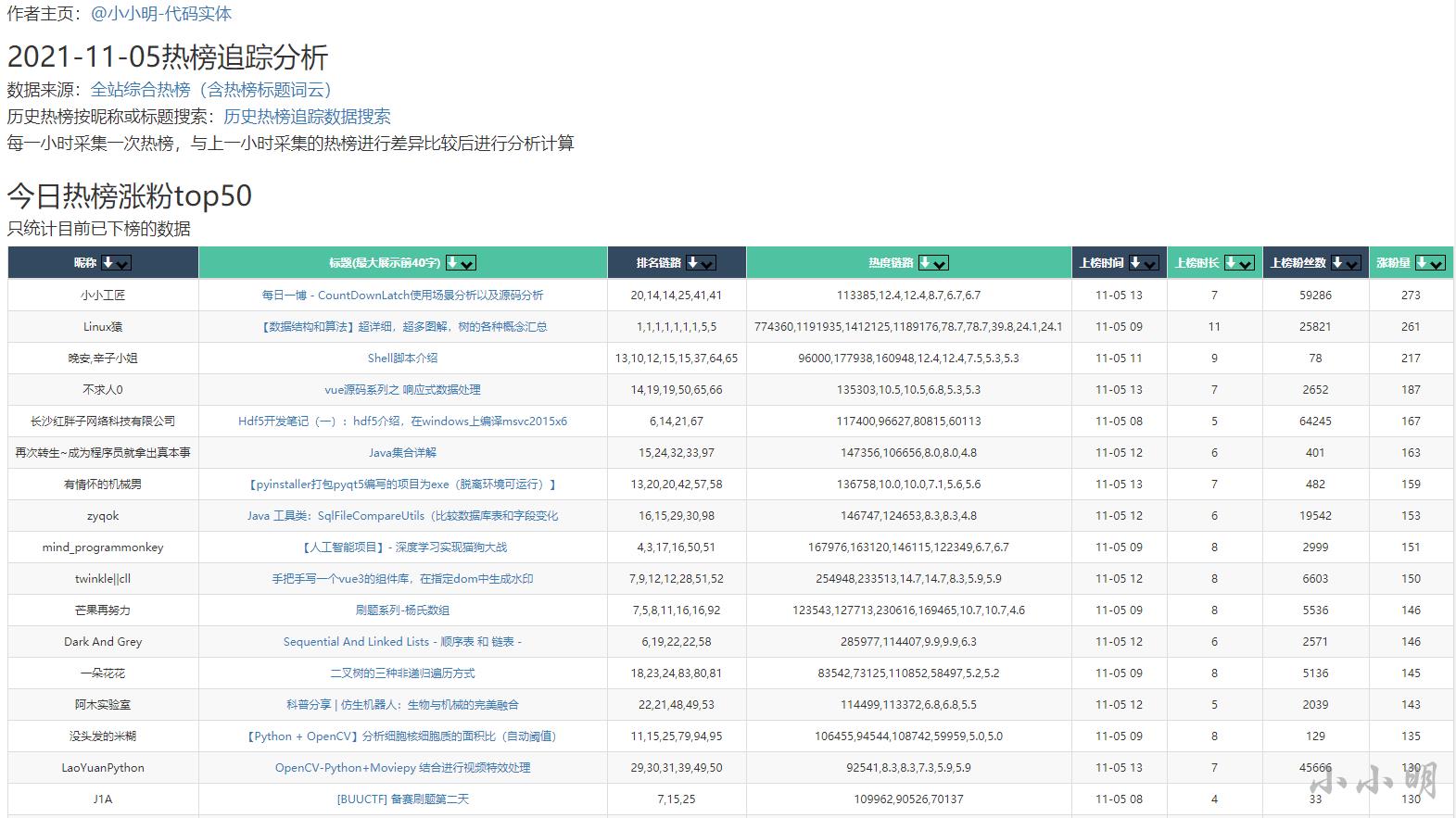
继续往下划还可以看到昨日热榜涨粉top50:
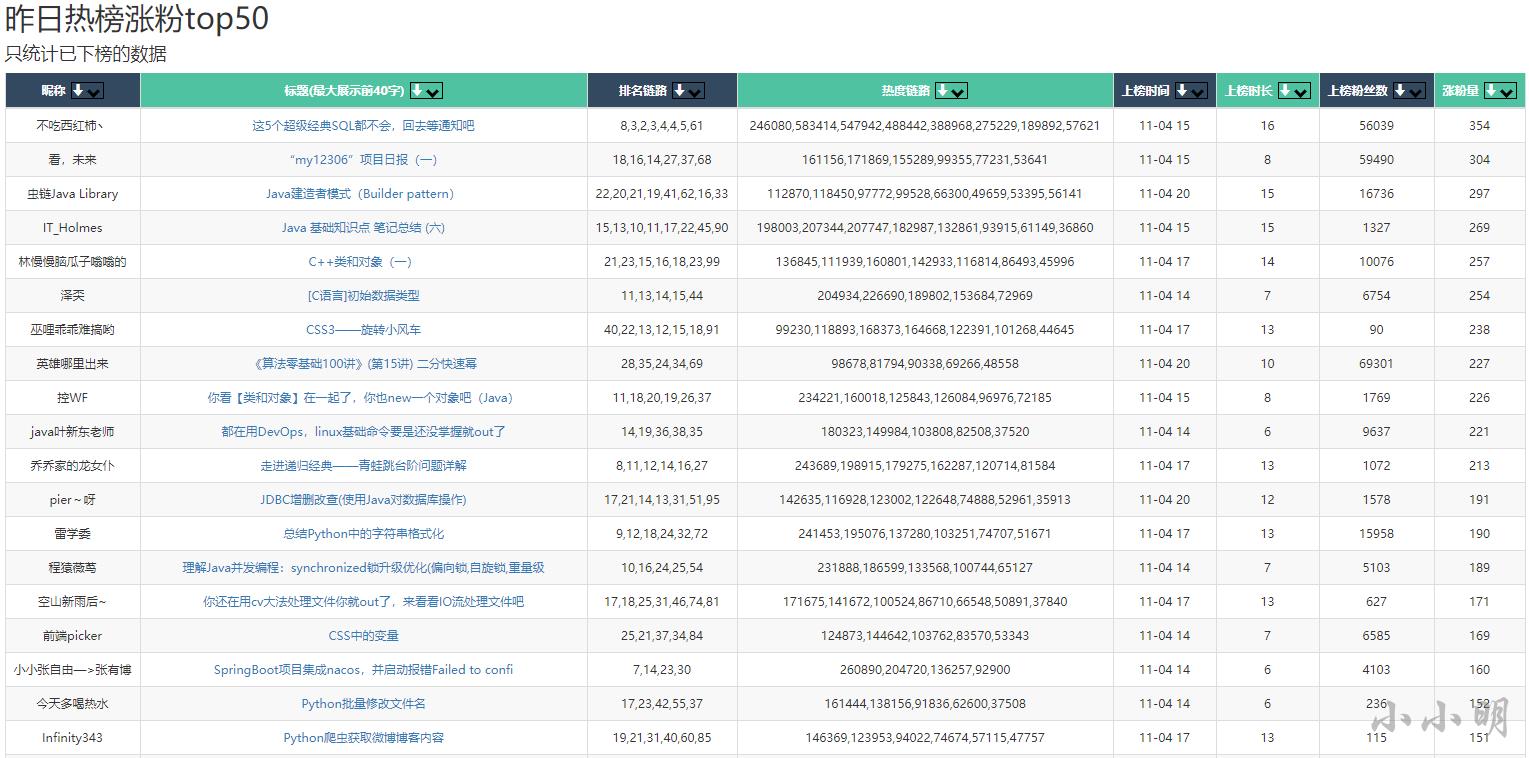
然后可以看到历史热榜涨粉top50:
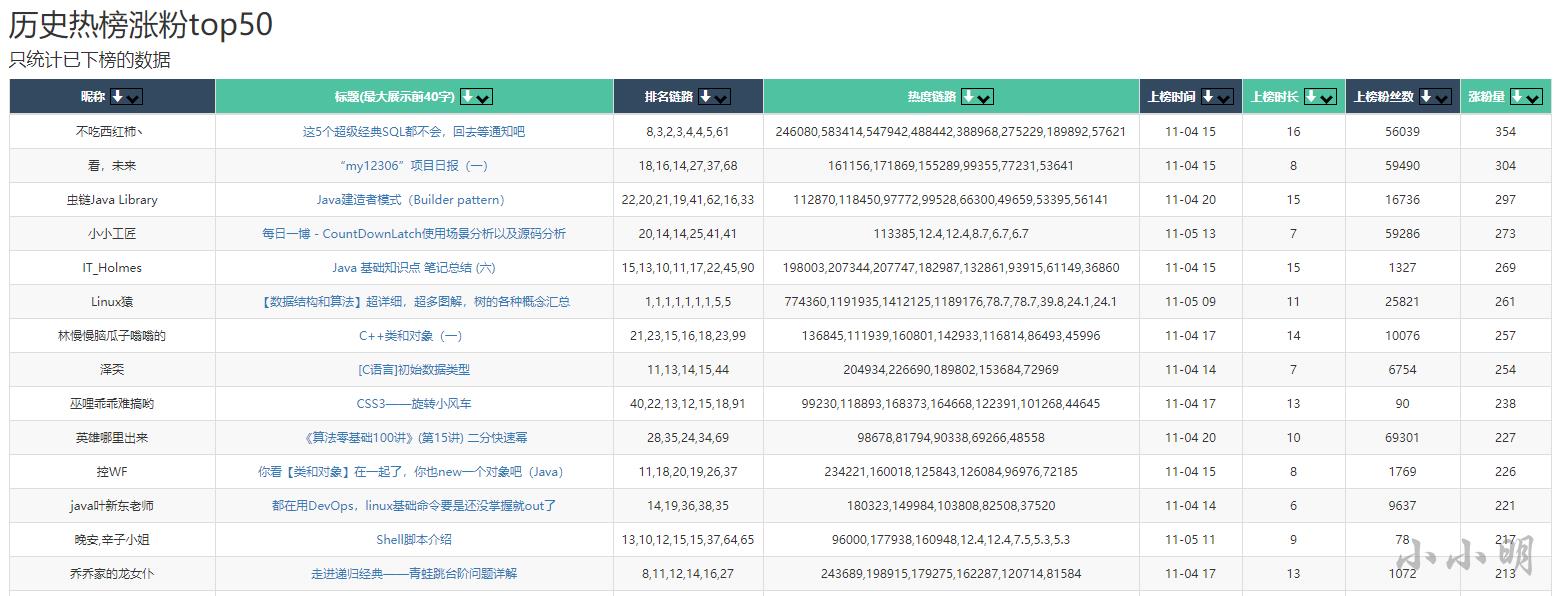
目前历史涨粉榜情况不佳是因为数据库重建后,采集程序昨天下午2点才重新启动。再过一星期,相信大家都能看到一个完全不一样的历史涨粉热榜。
最下面还有一个模块近10天上榜次数与涨粉量top50:

不过从昨天下午两点到现在还没有人能连续两次上榜,相信过两天后,我们能够看到上榜次数超过2次的用户出现。
热榜追踪程序的开发思路
采集程序开发
相信很多小伙伴更好奇该程序如何开发,那么下面我简单介绍一下该程序的开发思路与代码。
思路:有一个采集程序每小时执行一次,每次执行都获取当前热榜和历史热榜进行差异比较,划分为三类:
- 同时存在当前热榜和历史热榜中,说明是正在热榜的数据
- 不在当前热榜均在历史热榜中,说明是已下榜的数据
- 在当前热榜不在历史热榜中,说明是新上榜的数据
对于这三类数据,有不同的处理策略:
- 对正在热榜的数据追加更新排名链路和热度链路
- 对已下榜的数据,根据链接逐条采集当前粉丝数,填入下榜粉丝数字段中;同时根据当前时间更新下榜时间。
- 对于新上榜的数据,根据当前时间填入上榜时间,采集当前粉丝数填入上榜粉丝数字段中。
对于新上榜的每条数据,使用文章ID作为主键进行存储。
下面是以上思路的完整代码:
from sqlalchemy import create_engine
import pandas as pd
from datetime import datetime
from check_func import pares_url
from database import databases
uri = f'mysql+pymysql://{databases["USER"]}:{databases["PASSWORD"]}@{databases["HOST"]}:{databases["PORT"]}/{databases["NAME"]}'
engine = create_engine(uri)
# 更新当前热榜链条
sql = """UPDATE hot_rank_circle a,(SELECT
distinct n.id,
CONCAT(h.`排名链路`,',',n.`排名`) 排名链路,
CONCAT(h.`热度链路`,',',ROUND(n.热度/10000,1)) 热度链路
FROM hot_rank n JOIN hot_rank_circle h ON n.id=h.id
WHERE SUBSTRING_INDEX(h.热度链路,',',-1)!=n.热度) b
SET a.排名链路=b.排名链路,a.热度链路=b.热度链路 WHERE a.id=b.id;"""
engine.execute(sql)
# 更新下榜时的粉丝数
sql = """SELECT id,链接 FROM hot_rank_circle
WHERE id NOT IN (SELECT DISTINCT id FROM hot_rank)
AND 下榜时间 IS NULL;"""
id2url = pd.read_sql(sql, engine)
if id2url.shape[0] != 0:
fan_nums = []
for url in id2url.链接.values:
data = pares_url(url)
# print(url, data)
fan_nums.append(data.get('粉丝'))
id2url['链接'] = fan_nums
id2url.to_sql(name="tmp", con=engine, if_exists="replace", index=False)
sql = "UPDATE hot_rank_circle, tmp SET hot_rank_circle.下榜粉丝数=tmp.链接 WHERE hot_rank_circle.id=tmp.id;"
engine.execute(sql)
# 更新下榜时间
sql = """UPDATE hot_rank_circle SET 下榜时间=NOW()
WHERE id NOT IN (SELECT distinct id FROM hot_rank)
AND 下榜时间 IS NULL;"""
engine.execute(sql)
# 增加新上榜数据
sql = """SELECT distinct n.昵称, n.标题, n.链接, n.排名 排名链路, ROUND(n.热度/10000,1) 热度链路
FROM hot_rank n
LEFT JOIN hot_rank_circle h
ON n.id=h.`id`
WHERE h.id IS NULL;"""
hot_rank = pd.read_sql(sql, engine)
idx = hot_rank.链接.apply(lambda s: s[s.rfind("/") + 1:]).astype("int")
hot_rank.insert(0, "id", idx)
# hot_rank.热度链路 = (hot_rank.热度链路 / 10000).round(1)
# date = str(datetime.now())[5:13]
hot_rank["上榜时间"] = datetime.now()
hot_rank["下榜时间"] = None
fan_nums = []
for url in hot_rank.链接.values:
data = pares_url(url)
# print(url, data)
fan_nums.append(data.get('粉丝'))
hot_rank['上榜粉丝数'] = fan_nums
hot_rank['下榜粉丝数'] = None
hot_rank.to_sql(name="hot_rank_circle", con=engine, if_exists="append", index=False)
数据查询页开发
restful接口开发:
def rank_follow_search(request):
if request.method == "POST":
return HttpResponse("不支持的请求类型")
args = []
name = request.GET.get("name", "").replace("'", "").replace('"', "").replace(";", "")
if name:
args.append(f"昵称 LIKE '%%{name}%%'")
title = request.GET.get("title", "").replace("'", "").replace('"', "").replace(";", "")
if title:
args.append(f"标题 LIKE '%%{title}%%'")
rank = request.GET.get("rank", "").replace("'", "").replace('"', "").replace(";", "")
if rank:
args.append(f"排名链路 LIKE '%%{rank}%%'")
date = request.GET.get("date", "").replace("'", "").replace('"', "").replace(";", "")
if date:
args.append(f"上榜时间 LIKE '%%{date}%%'")
args = " AND ".join(args)
if not args:
args = "1=1"
# print(args)
sql = f"""SELECT 昵称,标题,链接,排名链路,热度链路,
SUBSTRING(上榜时间,6,8) 上榜时间,
(TO_DAYS(下榜时间)-TO_DAYS(上榜时间))*24+HOUR(下榜时间)-HOUR(上榜时间) 上榜时长,
上榜粉丝数,下榜粉丝数-上榜粉丝数 涨粉量 FROM hot_rank_circle
WHERE {args}
ORDER BY 上榜时间 DESC,上榜粉丝数 DESC LIMIT 20;"""
try:
df = pd.read_sql(sql, engine)
df.fillna("null", inplace=True)
return JsonResponse(df.to_dict(orient="records"), safe=False)
except Exception as e:
return JsonResponse({'status': -1, 'msg': str(e)})
虽然本程序完全无所谓SQL注入,但是防SQL注入还是得养成习惯,这里我就简单粗暴的采用了去掉查询条件中引号和分号来达到防SQL注入的目的。当然这种方法也可能一些特殊的方案防不住,期待大佬们能够指出。
前端展示页开发:
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>热榜追踪数据搜索</title>
<link href="/static/css/bootstrap.min.css" rel="stylesheet">
<link rel="stylesheet" type="text/css" href="/static/css/demo.css">
<link rel="stylesheet" href="/static/dist/excel-bootstrap-table-filter-style.css"/>
<script type="text/javascript" src="/static/js/jquery-1.11.0.min.js"></script>
<script src="/static/js/vue.min.js"></script>
<script type="text/javascript" src="/static/dist/excel-bootstrap-table-filter-bundle.js"></script>
</head>
<body>
<div class="container">
<div class="row">
<div class="col-md-12">
<h4>作者主页:<a href='https://xxmdmst.blog.csdn.net/' target="_blank">@小小明-代码实体</a></h4>
<h2>历史热榜追踪数据搜索</h2>
<h4>(最大只显示最近上榜的前20条数据,可以通过下面链接查看当前热榜)</h4>
<h4>数据来源:<a href="/hotrank/all/" target="_blank">全站综合热榜(含热榜标题词云)</a></h4>
<h4>今日热榜追踪:<a href="/rankfollow/" target="_blank">今日热榜追踪</a></h4>
<div id="in">
<p>昵称:<input id="name">标题:<input id="title"></p>
<p>排名:<input id="rank">时间:<input id="date"></p>
</div>
<p>
<button id="run">搜索</button>
</p>
</div>
</div>
<table id="table1" class="table table-bordered table-intel">
<thead>
<tr>
<th class="no-filter">昵称</th>
<th class="no-sort no-filter">标题</th>
<th class="no-sort no-filter">排名链路</th>
<th class="no-sort no-filter">热度链路</th>
<th class="no-filter">上榜时间</th>
<th class="no-filter">上榜时长</th>
<th class="no-filter">上榜粉丝数</th>
<th class="no-filter">涨粉量</th>
</tr>
</thead>
<tbody>
<tr v-for="row in rows">
<td>{{ row.昵称 }}</td>
<td><a href='{{ row.链接 }}' target="_blank">{{ row.标题 }}</a></td>
<td>{{ row.排名链路 }}</td>
<td>{{ row.热度链路 }}</td>
<td>{{ row.上榜时间 }}</td>
<td>{{ row.上榜时长 }}</td>
<td>{{ row.上榜粉丝数 }}</td>
<td>{{ row.涨粉量 }}</td>
</tr>
</tbody>
</table>
</div>
<script type="text/javascript">
$(function () {
$('#table1').excelTableFilter({
'captions': {a_to_z: '升序排列', z_to_a: '降序排列', search: '搜索', select_all: '全部选择'}
});
});
$(function () {
var vm = new Vue({
el: '#table1',
data: {
rows: []
}
});
window.vm = vm;
$.get("/api/rank_follow_search/", function (data) {
vm.rows = data;
});
});
let func = function () {
let name = $('#name').val();
let title = $('#title').val();
let rank = $('#rank').val();
let date = $('#date').val();
var url = `/api/rank_follow_search/?name=${name}&title=${title}&rank=${rank}&date=${date}`;
console.log(url)
$.get(url, function (data) {
vm.rows = data;
});
};
$("#in").keypress(function (even) {
if (even.which == 13) {
func()
}
});
$('#run').click(func);
</script>
</body>
</html>
这里我使用了vue进行数据绑定,这样就可以大幅度简化代码,原本几十行JavaScript代码才是实现的动态数据修改变成了vm.rows = data;这一行。而且HTML部
以上是关于CSDN热榜排名追踪工具上线,随时查看热榜链路数据的主要内容,如果未能解决你的问题,请参考以下文章