聊聊 Kafka:Producer Metadata 读取与更新机制
Posted 老周聊架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊 Kafka:Producer Metadata 读取与更新机制相关的知识,希望对你有一定的参考价值。
一、前言
我们上一篇说了 聊聊 Kafka:Producer 源码解析,这一篇我们来说下 Producer Metadata 的读取与更新机制。上一篇从宏观上介绍了 Producer 的宏观模型,其中通过 waitOnMetadata() 方法获取 topic 的 metadata 信息这一块东西很多,所以单独拎一篇出来讲。
二、Metadata
2.1 什么是 Metadata
Metadata 是指 Kafka 集群的元数据,包含了 Kafka 集群的各种信息,直接看源码便可知:
public class Metadata implements Closeable {
private final Logger log;
// retry.backoff.ms: 默认值为100ms,它用来设定两次重试之间的时间间隔,避免无效的频繁重试。
private final long refreshBackoffMs;
// metadata.max.age.ms: 默认值为300000,如果在这个时间内元数据没有更新的话会被强制更新。
private final long metadataExpireMs;
// 更新版本号,每更新成功1次,version自增1,主要是用于判断metadata是否更新
private int updateVersion;
// 请求版本号,每发送一次请求,version自增1
private int requestVersion;
// 上一次更新的时间(包含更新失败)
private long lastRefreshMs;
// 上一次更新成功的时间
private long lastSuccessfulRefreshMs;
private KafkaException fatalException;
// 非法的topics
private Set<String> invalidTopics;
// 未认证的topics
private Set<String> unauthorizedTopics;
// 元数据信息的Cache缓存
private MetadataCache cache = MetadataCache.empty();
private boolean needFullUpdate;
private boolean needPartialUpdate;
// 会收到metadata updates的Listener列表
private final ClusterResourceListeners clusterResourceListeners;
private boolean isClosed;
// 存储Partition最近一次的leaderEpoch
private final Map<TopicPartition, Integer> lastSeenLeaderEpochs;
}
MetadataCache:Kafka 集群中关于 node、topic 和 partition 的信息。(是只读的)
public class MetadataCache {
private final String clusterId;
private final Map<Integer, Node> nodes;
private final Set<String> unauthorizedTopics;
private final Set<String> invalidTopics;
private final Set<String> internalTopics;
private final Node controller;
private final Map<TopicPartition, PartitionMetadata> metadataByPartition;
private Cluster clusterInstance;
}
关于 topic 的详细信息(leader 所在节点、replica 所在节点、isr 列表)都是在 Cluster 实例中保存的。
// 保存了Kafka集群中部分nodes、topics和partitions的信息
public final class Cluster {
private final boolean isBootstrapConfigured;
// node 列表
private final List<Node> nodes;
// 未认证的topics
private final Set<String> unauthorizedTopics;
// 非法的topics
private final Set<String> invalidTopics;
// kafka内置的topics
private final Set<String> internalTopics;
private final Node controller;
// partition对应的信息,如:leader所在节点、所有的副本、ISR中的副本、offline的副本
private final Map<TopicPartition, PartitionInfo> partitionsByTopicPartition;
// topic和partition信息的对应关系
private final Map<String, List<PartitionInfo>> partitionsByTopic;
// topic和可用partition(leader不为null)的对应关系
private final Map<String, List<PartitionInfo>> availablePartitionsByTopic;
// node和partition信息的对应关系
private final Map<Integer, List<PartitionInfo>> partitionsByNode;
// 节点id与节点的对应关系
private final Map<Integer, Node> nodesById;
// 集群信息,里面只有一个clusterId
private final ClusterResource clusterResource;
}
// topic-partition: 包含 topic、partition、leader、replicas、isr
public class PartitionInfo {
private final String topic;
private final int partition;
private final Node leader;
private final Node[] replicas;
private final Node[] inSyncReplicas;
private final Node[] offlineReplicas;
}
看源码不难理解 Metadata 的主要数据结构,我们大概总结下包含哪些信息:
- 集群中有哪些节点;
- 集群中有哪些 topic,这些 topic 有哪些 partition;
- 每个 partition 的 leader 副本分配在哪个节点上,follower 副本分配在哪些节点上;
- 每个 partition 的 AR 有哪些副本,ISR 有哪些副本;
2.2 Metadata 的应用场景
Metadata 在 Kafka 中非常重要,很多场景中都需要从 Metadata 中获取数据或更新数据,例如:
- KafkaProducer 发送一条消息到指定的 topic 中,需要知道分区的数量,要发送的目标分区,目标分区的 leader,leader 所在的节点地址等,这些信息都要从 Metadata 中获取。
- 当 Kafka 集群中发生了 leader 选举,节点中 partition 或副本发生了变化等,这些场景都需要更新Metadata 中的数据。
三、Producer 的 Metadata 更新流程
Producer 在调用 doSend() 方法时,第一步就是通过 waitOnMetadata 方法获取该 topic 的 metadata 信息。
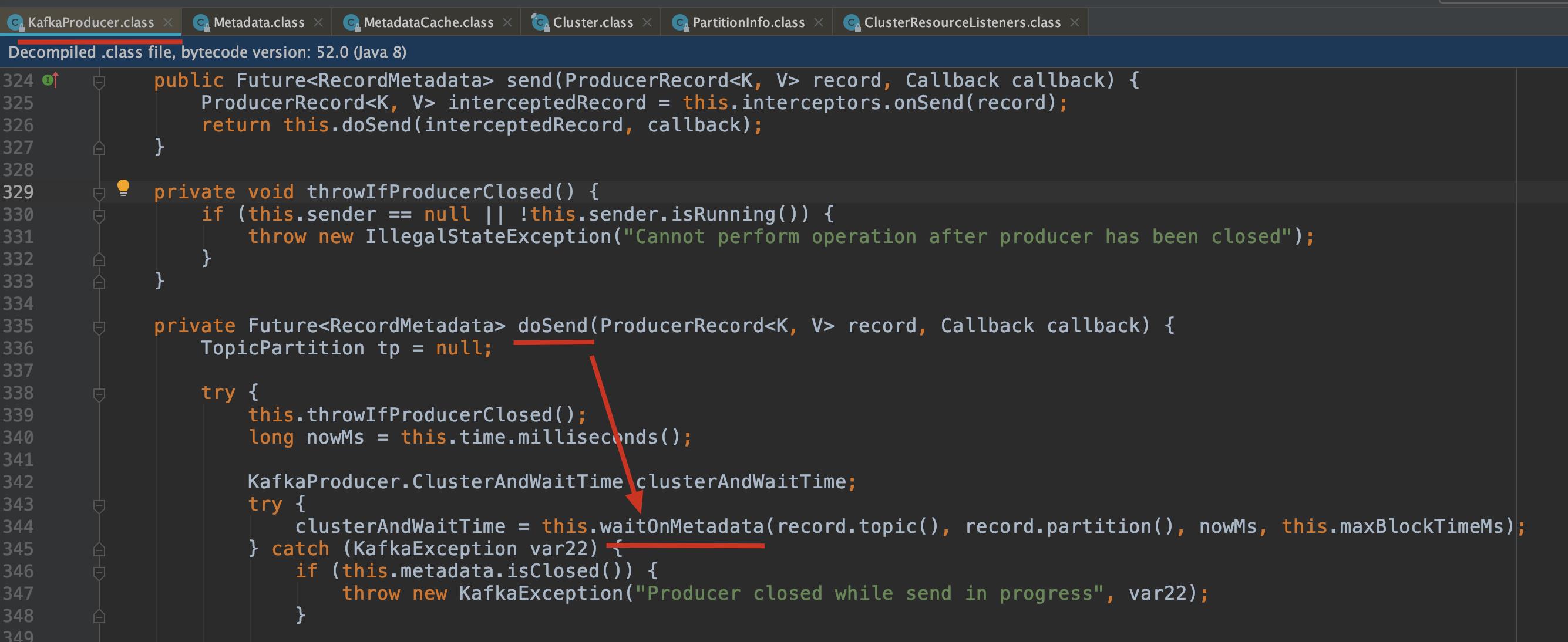
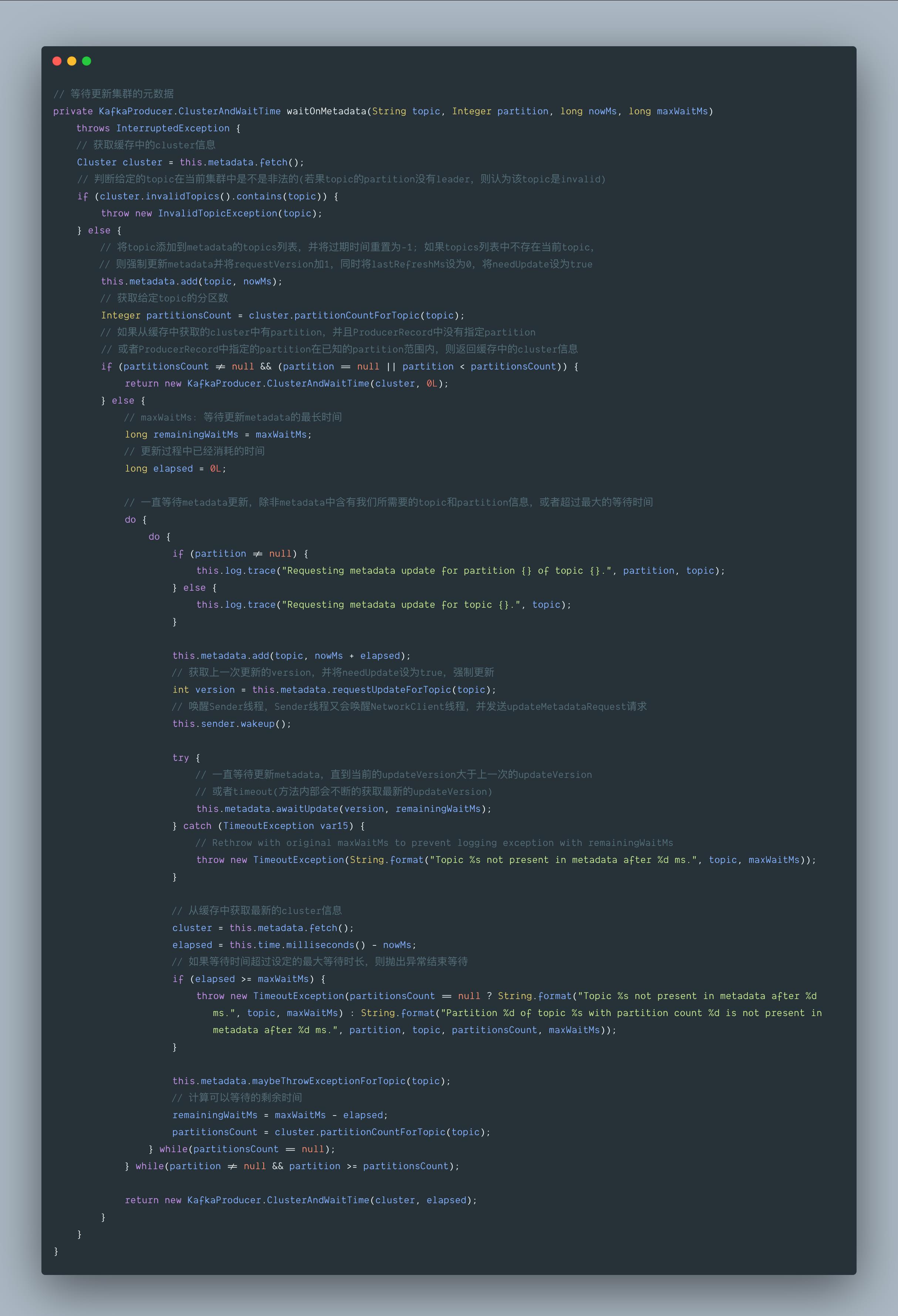
总结一下以上代码:
- 首先会从缓存中获取 cluster 信息,并从中获取 partition 信息,如果可以取到则返回当前的 cluster 信息,如果不含有所需要的 partition 信息时就会更新 metadata;
- 更新 metadata 的操作会在一个 do …while 循环中进行,直到 metadata 中含有所需 partition 的信息,该循环中主要做了以下事情:
- 调用 metadata.requestUpdateForTopic() 方法来获取 updateVersion,即上一次更新成功时的 version,并将 needUpdate 设为 true,强制更新;
- 调用 sender.wakeup() 方法来唤醒 Sender 线程,Sender 线程中又会唤醒 NetworkClient 线程,在 NetworkClient 中会对 UpdateMetadataRequest 请求进行操作,待会下面会详细介绍;
- 调用 metadata.awaitUpdate(version, remainingWaitMs) 方法来等待 metadata 的更新,通过比较当前的 updateVersion 与步骤 1 中获取的 updateVersion 来判断是否更新成功;
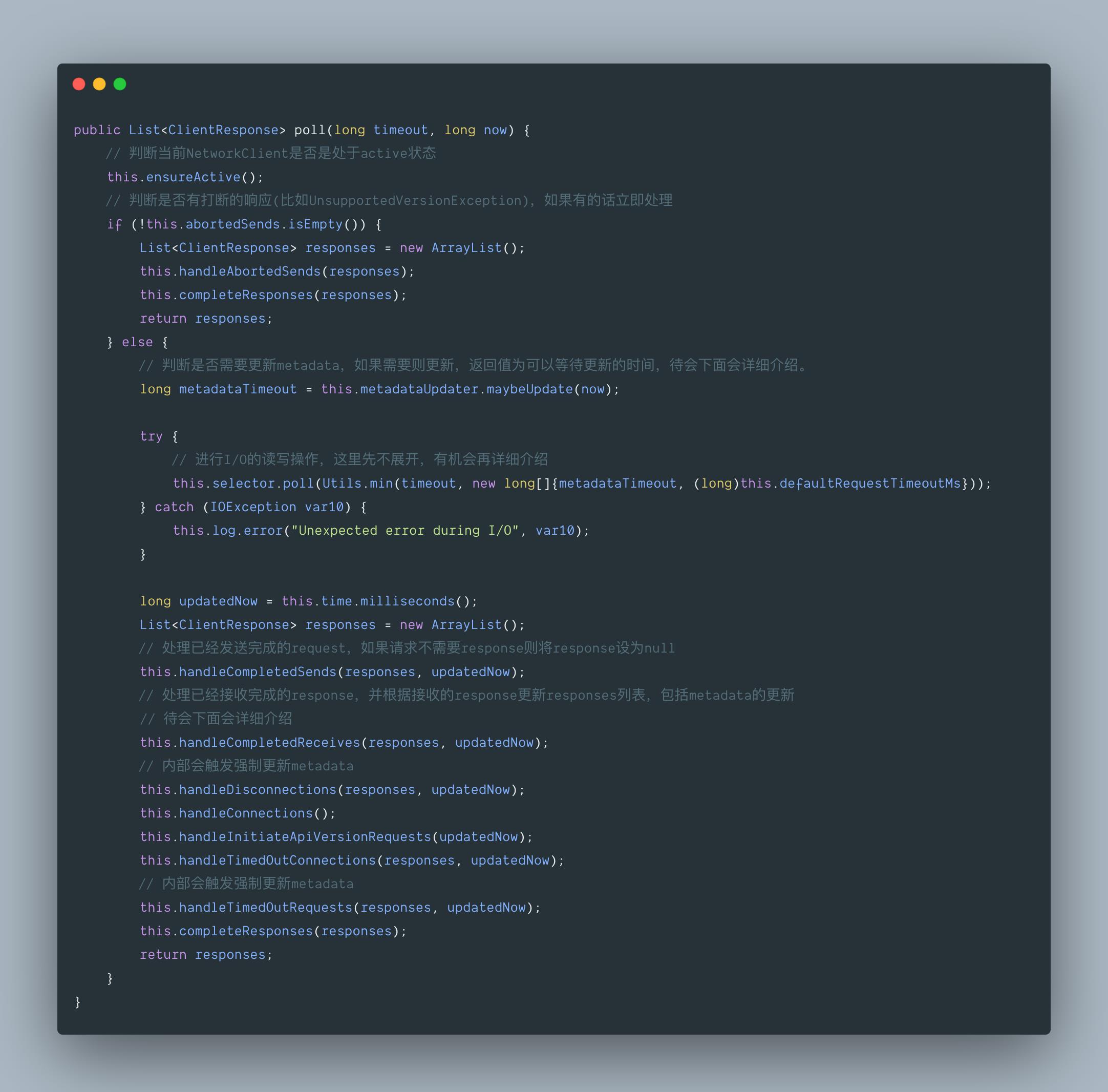
3.1 org.apache.kafka.clients.NetworkClient#poll
上面提到调用 sender.wakeup() 方法来唤醒 Sender 线程,Sender 线程中又会唤醒 NetworkClient 线程,在 NetworkClient 中会对 UpdateMetadataRequest 请求进行操作。在 NetworkClient 中真正处理请求的是 NetworkClient.poll() 方法,接下来让我们通过分析源码来看下 NetworkClient 是如何处理请求的。
3.2 org.apache.kafka.clients.NetworkClient.DefaultMetadataUpdater#maybeUpdate(long)
我们来看下 metadata 是如何更新的
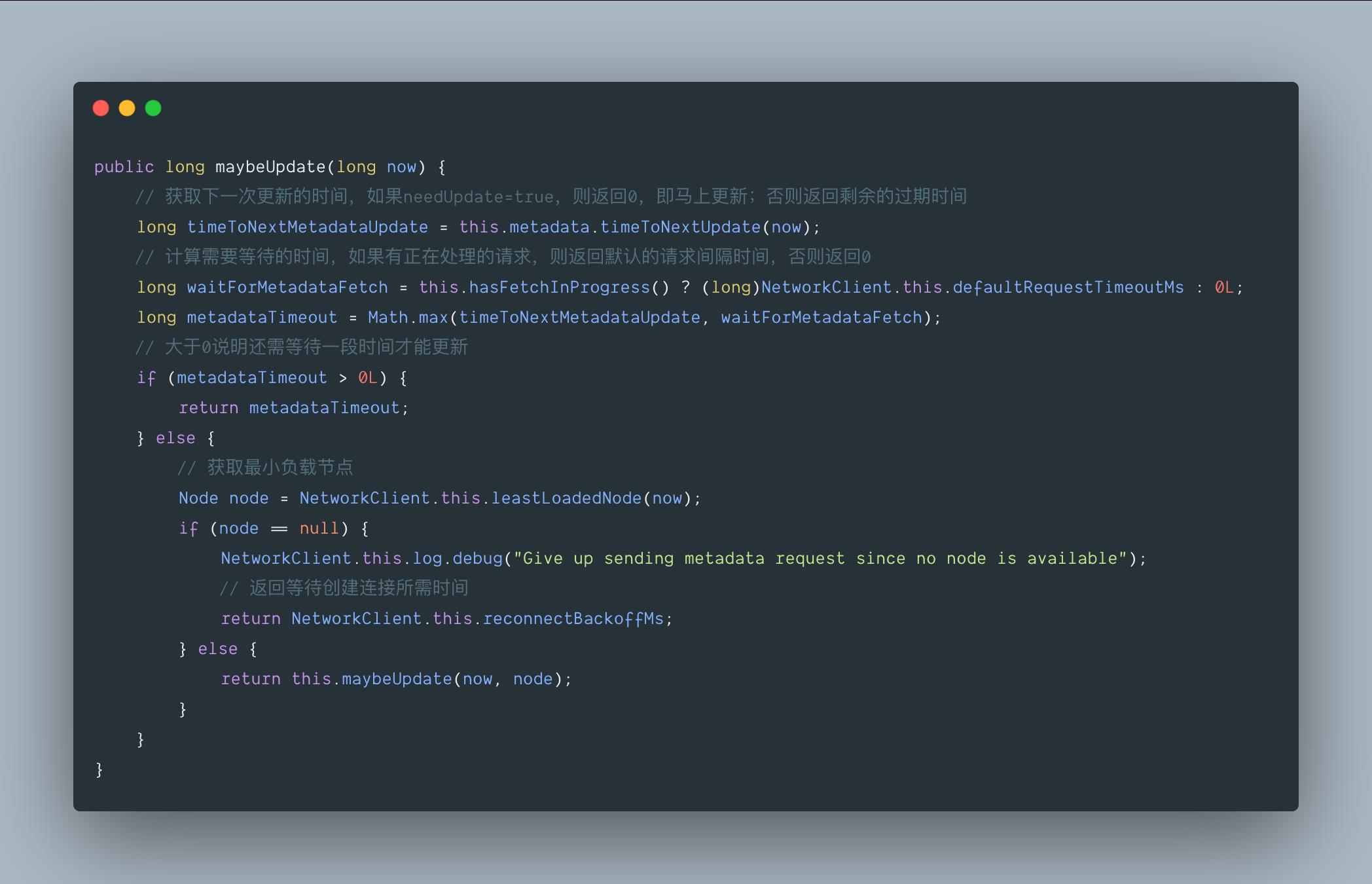
这里你可能会问,老周啊,最小负载节点是啥呀?
别急,我们来看下面这张图,你就理解了。
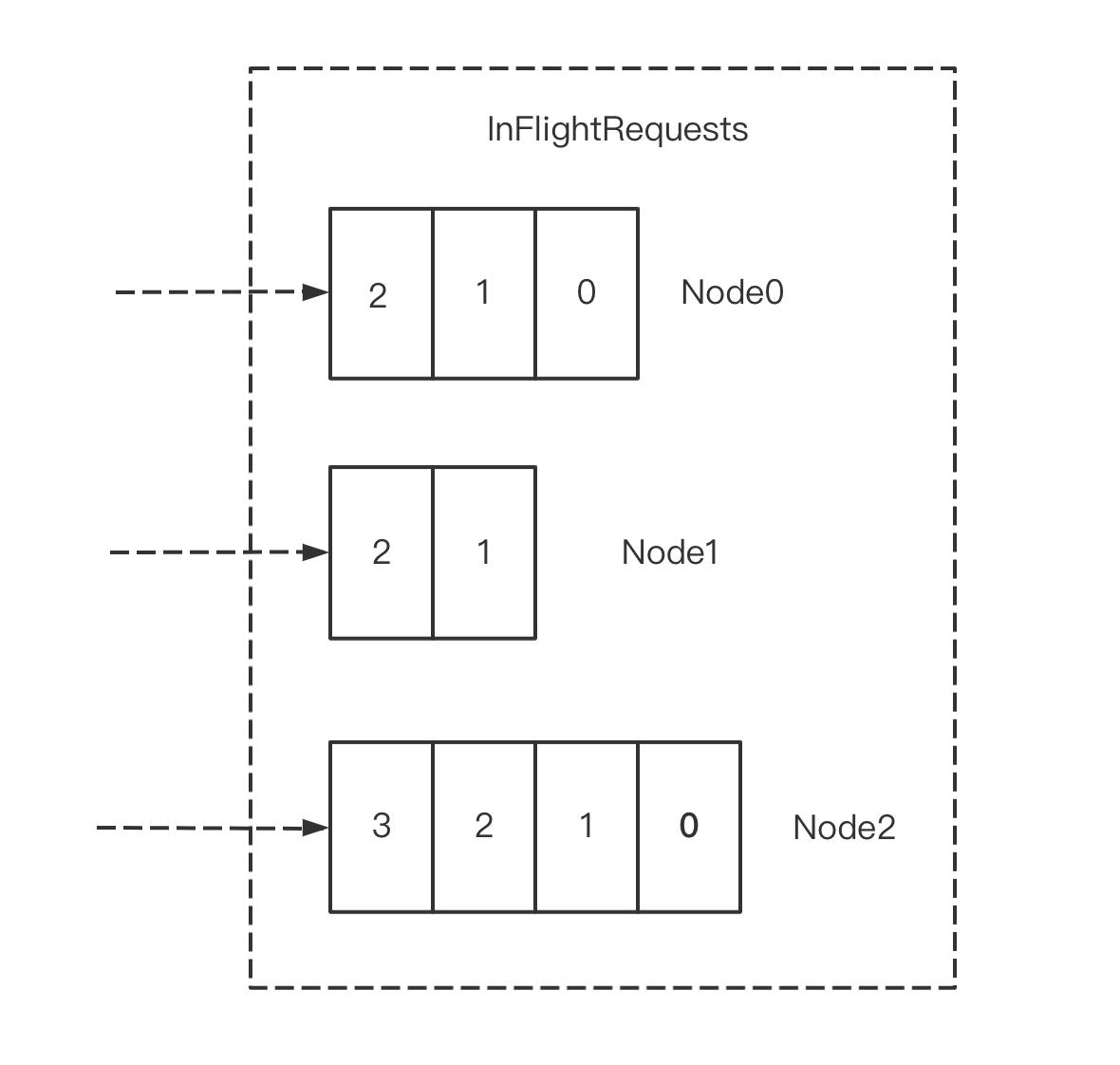
LeastLoadedNode 指 Kafka 集群中所有 Node 中负载最小的那一个 Node,它是由每个 Node 在 InFlightRequests 中还未确定的请求数决定的,未确定的请求越少则负载越小。如上图所示,Node1 即为 LeastLoadedNode。
3.3 org.apache.kafka.clients.Metadata#updateRequested
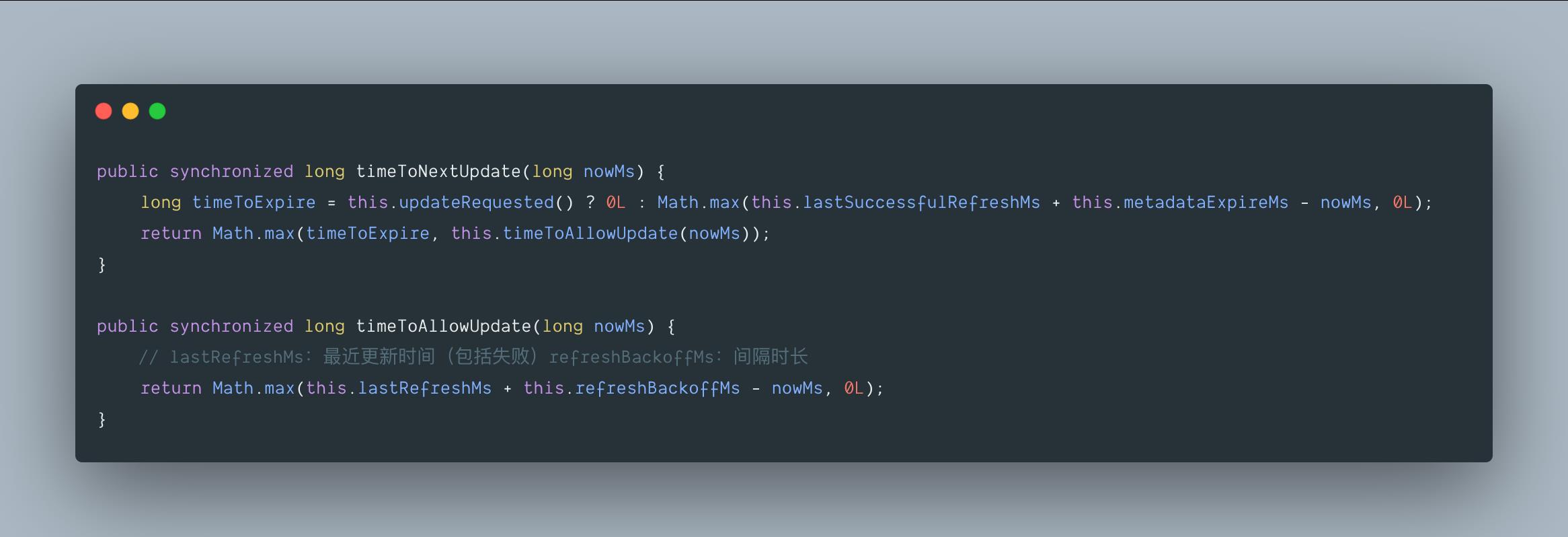
下次更新元数据信息的时间:当前 metadata 信息即将到期的时间即 timeToExpire 和 距离允许更新 metadata 信息的时间 即 timeToAllowUpdate 中的最大值。
timeToExpire:needUpdate 为 true,表示强制更新,此时该值为 0;否则的话,就按照定时更新时间,即元数据信息过期时间(默认是 300000 ms 即 5 分钟)进行周期性更新。
timeToAllowUpdate:默认就是 refreshBackoffMs 的默认值,即 100 ms。
3.4 org.apache.kafka.clients.NetworkClient.DefaultMetadataUpdater#maybeUpdate(long, org.apache.kafka.common.Node)
我们继续跟一下 maybeUpdate 方法:
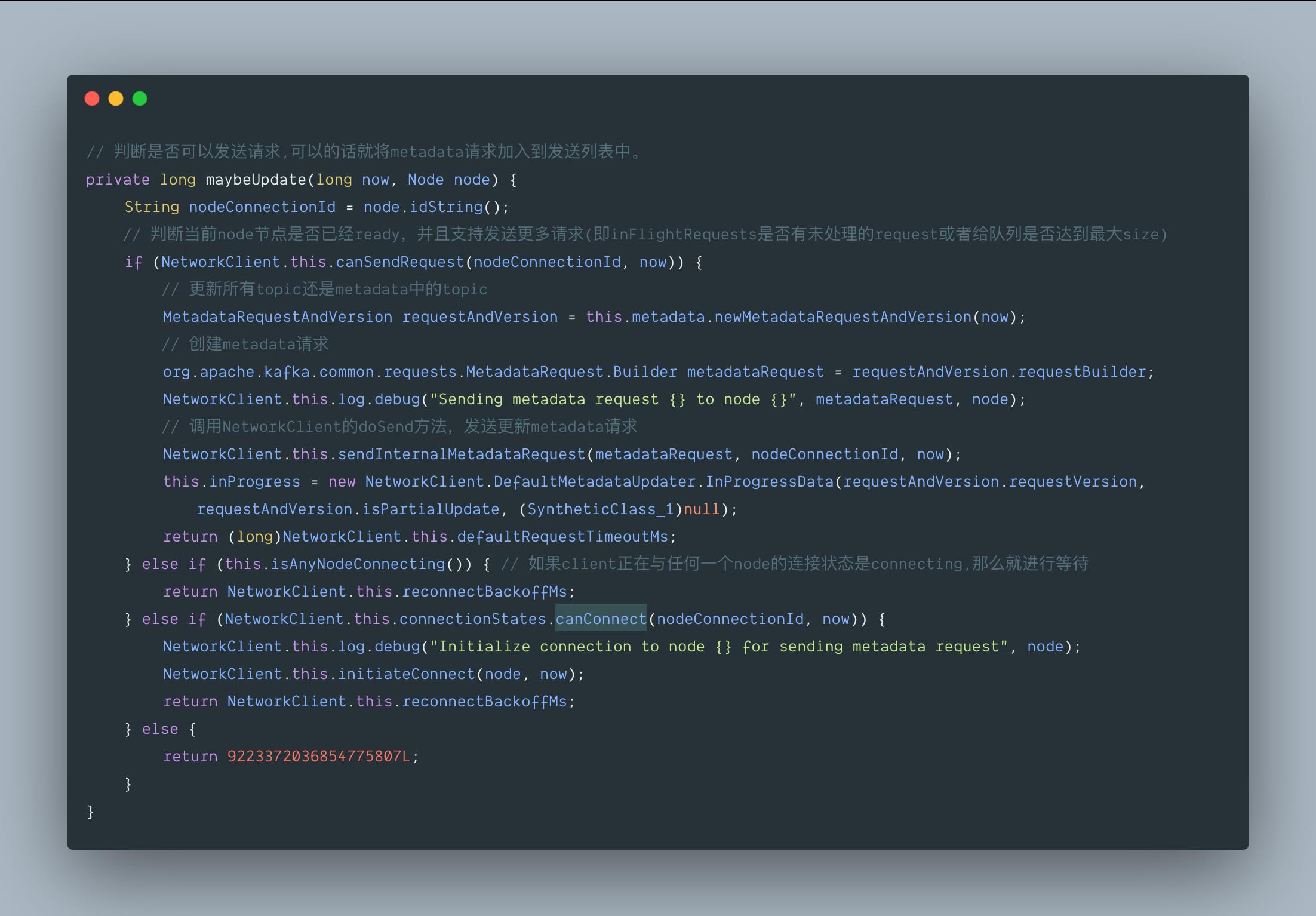
因此,每次 producer 请求更新 metadata 时,会有以下几种情况:
- 通道已经 ready,node 可以发送请求,那么就直接发送请求。
- 如果该 node 正在建立连接,则直接返回。
- 如果该 node 还没建立连接,则向 broker 初始化连接。
而 KafkaProducer 线程一直是阻塞在两个 while 循环中的,直到 metadata 更新:
- sender 线程第一次调用 poll,初始化与 node 的连接。
- sender 线程第二次调用 poll,发送 metadata 请求。
- sender 线程第三次调用 poll,获取 metadataResponse,并更新 metadata。
3.5 接收 Server 端的响应,更新 Metadata 信息
handleCompletedReceives 是如何处理任何已完成的接收响应,如下:
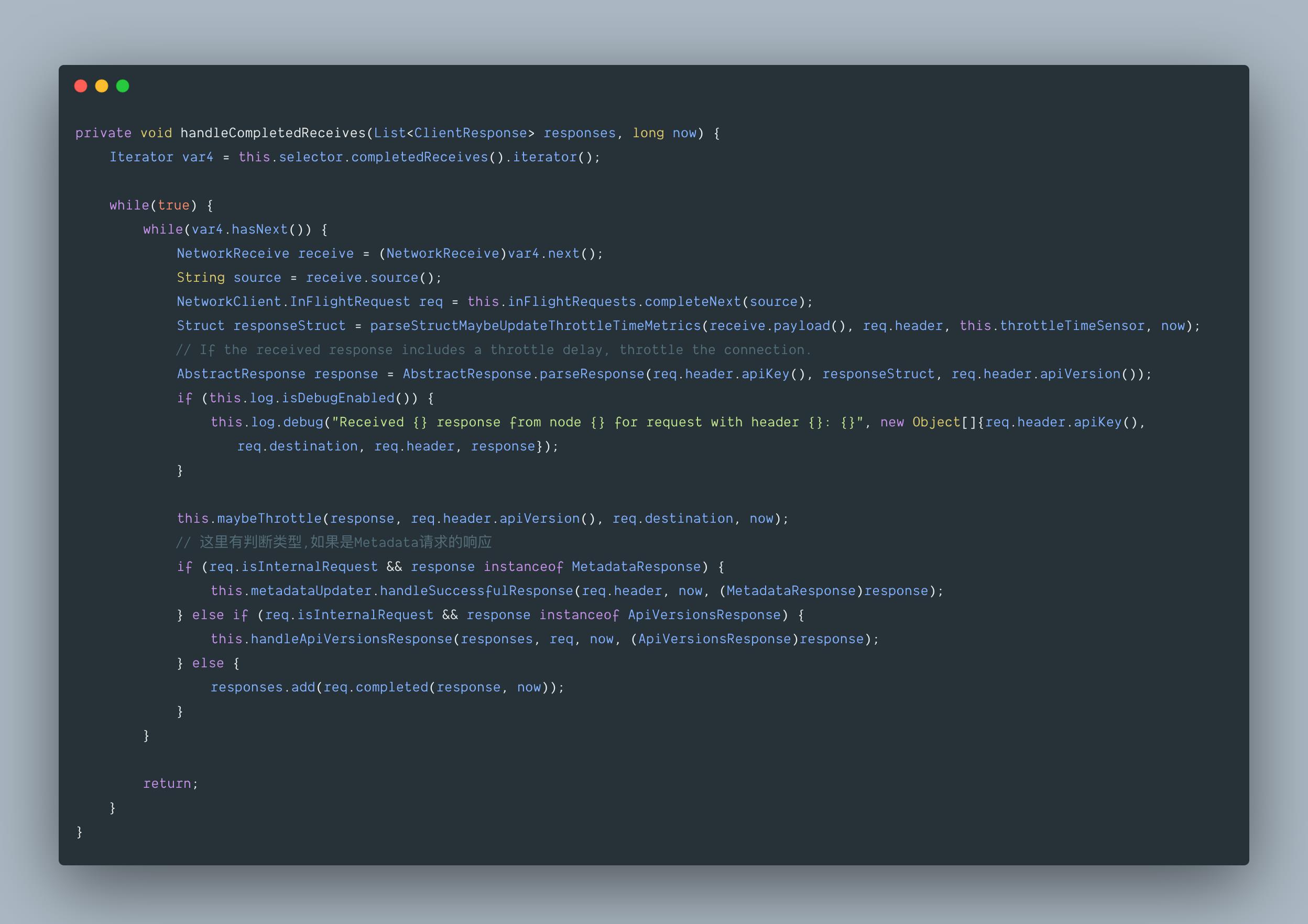
之后进一步调用 handleSuccessfulResponse。
四、总结
Metadata 会在下面两种情况下进行更新:
- 强制更新:调用 Metadata.requestUpdate() 将 needFullUpdate 置为 true 来强制更新。
- 周期性更新:通过 Metadata 的 lastSuccessfulRefreshMs 和 metadataExpireMs 来实现,一般情况下,默认周期时间就是 metadataExpireMs,5 分钟时长。
在 NetworkClient 的 poll() 方法调用时,会去检查两种更新机制,只要达到一种,就会触发更新操作。
Metadata 的强制更新会在以下几种情况下进行:
- initConnect 方法调用时,初始化连接;
- poll() 方法中对 handleDisconnections() 方法调用来处理连接断开的情况,这时会触发强制更新;
- poll() 方法中对 handleTimedOutRequests() 来处理请求超时时;
- 发送消息时,如果无法找到 partition 的 leader;
- 处理 Producer 响应(handleProduceResponse),如果返回关于 Metadata 过期的异常,比如:没有 topic-partition 的相关 meta 或者 client 没有权限获取其 metadata。
强制更新主要是用于处理各种异常情况。
好了,Producer Metadata 读取与更新机制就说到这,我们下一期再见。
以上是关于聊聊 Kafka:Producer Metadata 读取与更新机制的主要内容,如果未能解决你的问题,请参考以下文章