Kafka的相关原理
Posted 清晨丶暖阳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka的相关原理相关的知识,希望对你有一定的参考价值。

一、Kafka术语解释
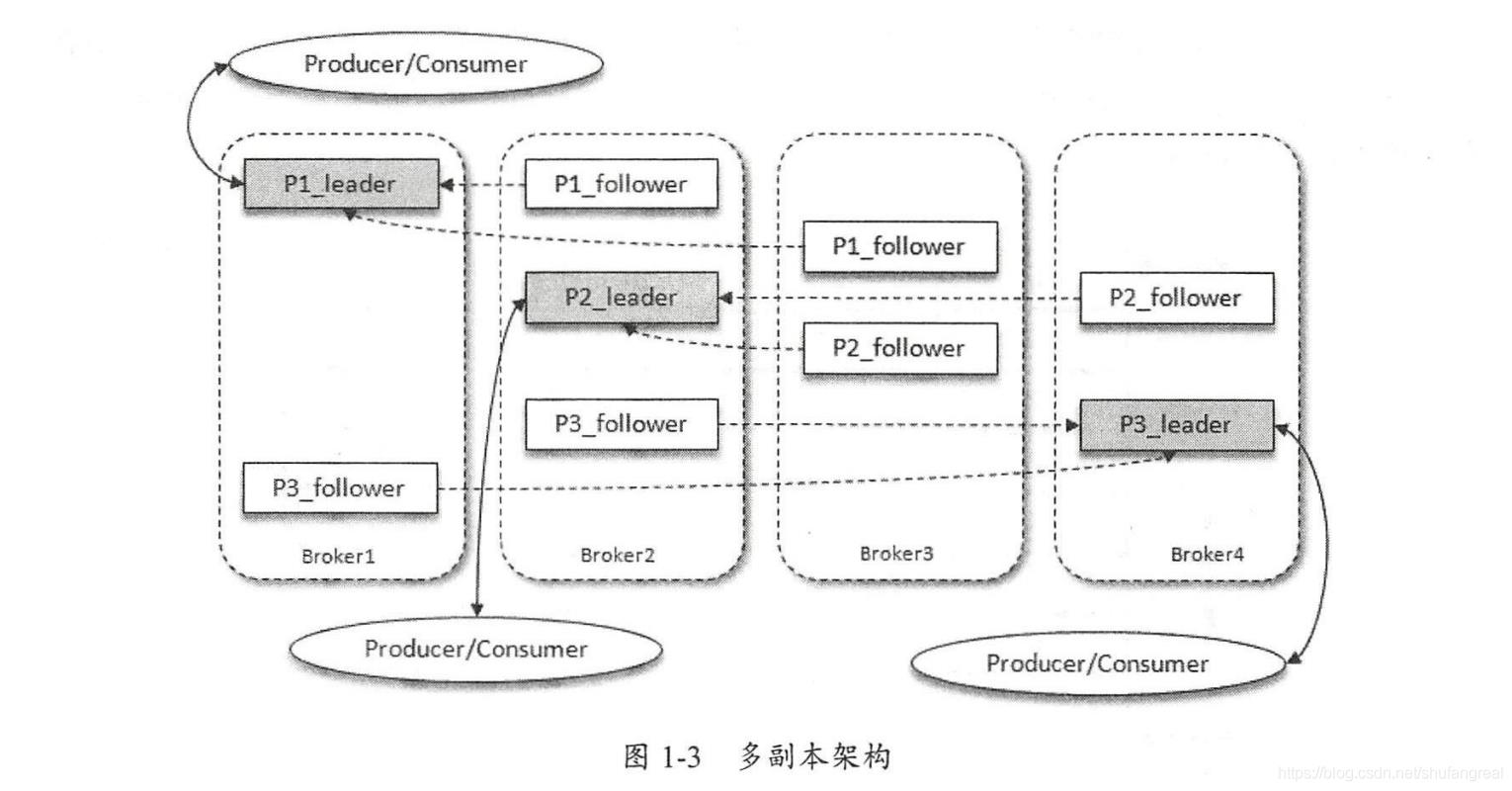
- Producer:kafka生产者,Kafka集群的数据都是生产者发送上报的;
- leastLoadedNode:kafka集群中负载最低的节点,通常生产者客户端向其发送MetaDataRequest(元数据请求)获取元数据信息,从而获取各个消息发送请求对应的元数据更新;
- Broker:每个Broker算是一个Kafka的集群节点;
- Consumer:a、每个Kafka的数据都会被1个或者多个Consumer线程所消费;b、kafka一个分区的数据只能同时被一个Consumer组中的一个Consumer线程所消费;
- Partition:每个Topic对应多个分区,根据Partitioner分区器将数据保存在不同的分区(Partition)中;
-
Replication:每个partition数据包含1到N个Replication,称为分区副本,一个分区对应的副本分布在不同的broker节点上;
-
AR:每个Partition的Leader副本在内存中维护的副本队列,AR(All Replications)= ISR + OSR;
-
ISR:内部副本同步队列=ISR,ISR中由leader按照LEO同步情况维护着Leader以及其它同步数据完整性较高的Follower,如果ISR中Follower的数据同步落后到某个标准,Leader会将其剔出ISR=>OSR
-
OSR:OSR是AR中分给ISR,但是ISR不需要的子项(被删除的无用Follower)
-
- Leader:一个分区中负责读、写的副本,它的数据一定是>=其它副本的,如果它挂了,通过ZK来选举一个新的Leader;
- Follower:一个分区中负责从Leader副本中同步数据,响应正常的为ISR,响应超时或故障则丢弃为OSR
- LEO:每个副本上下一条数据将被插入的offset;
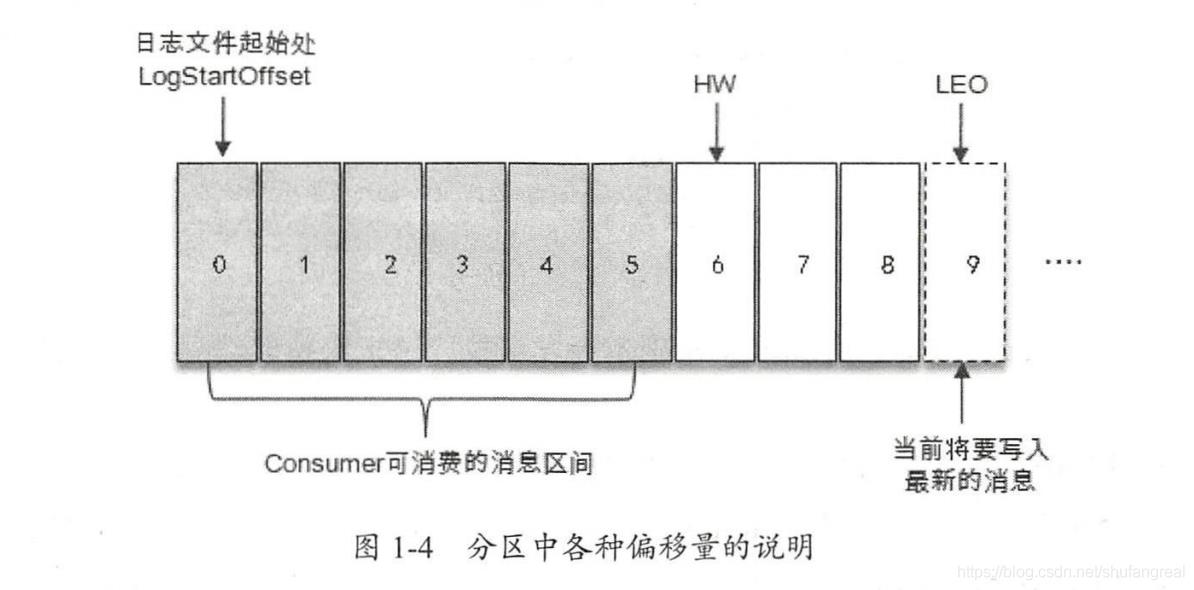
leader领导者的数据部分。 - HW:消费者只能消费 < HW 之前 offset 的数据,因为 >= HW 的数据对于 Consumer 来说是不可见的(HW = 一个分区副本对列中所有副本中最低的那个LEO)。
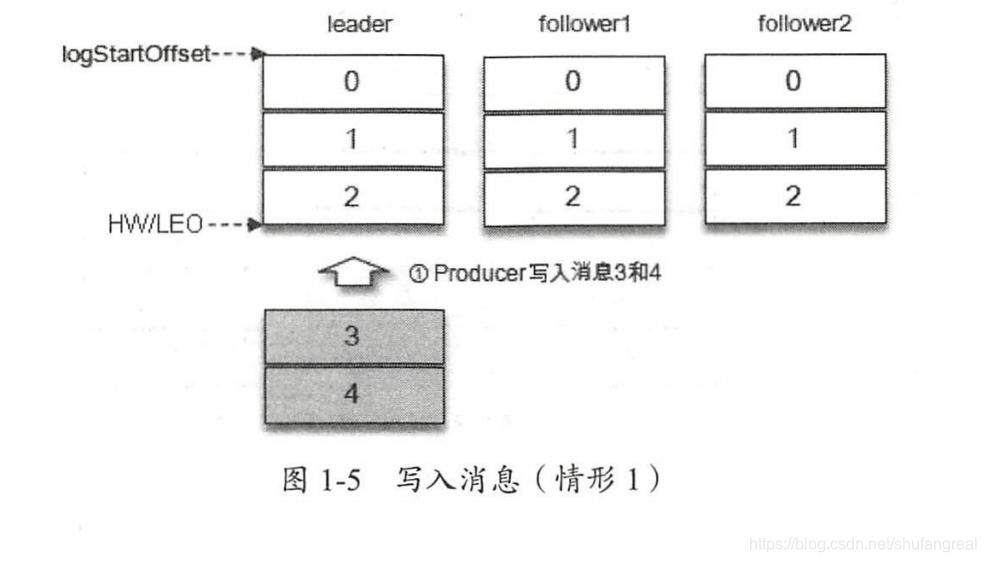
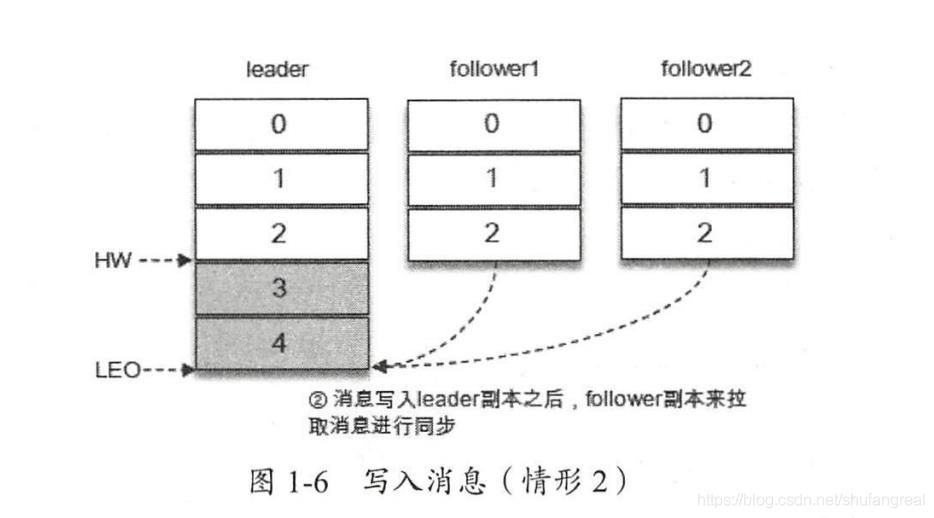
1、领导者和追随者消息的备份与存储图解
HW 与 LEO 之间的转换
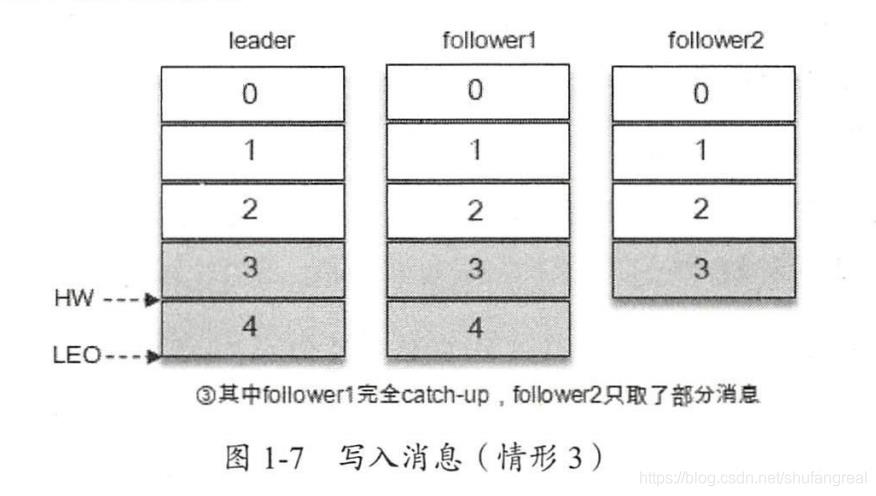
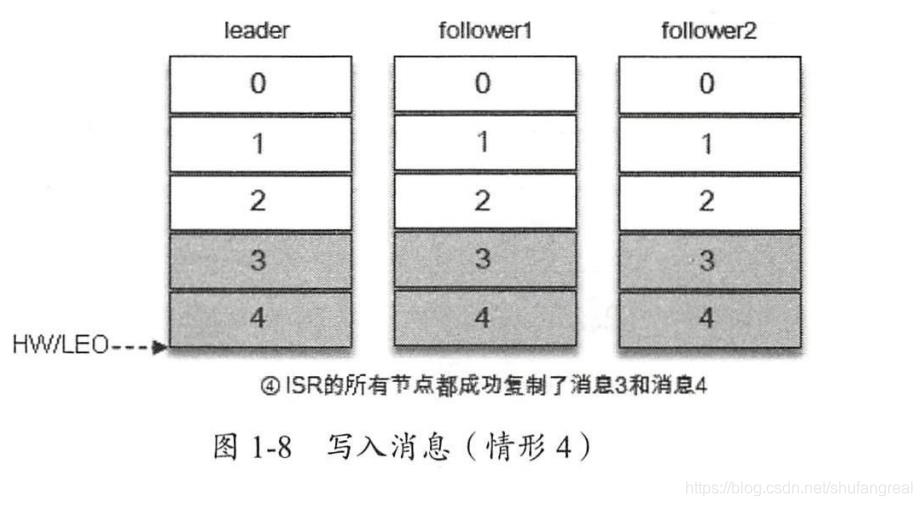
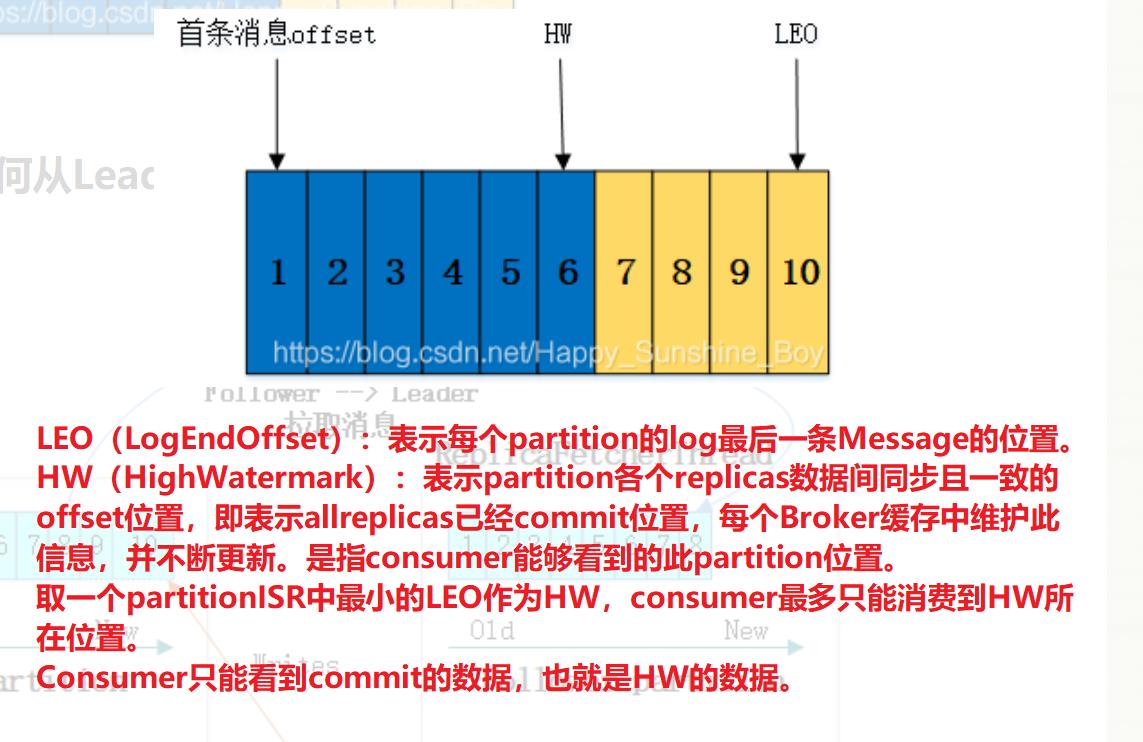
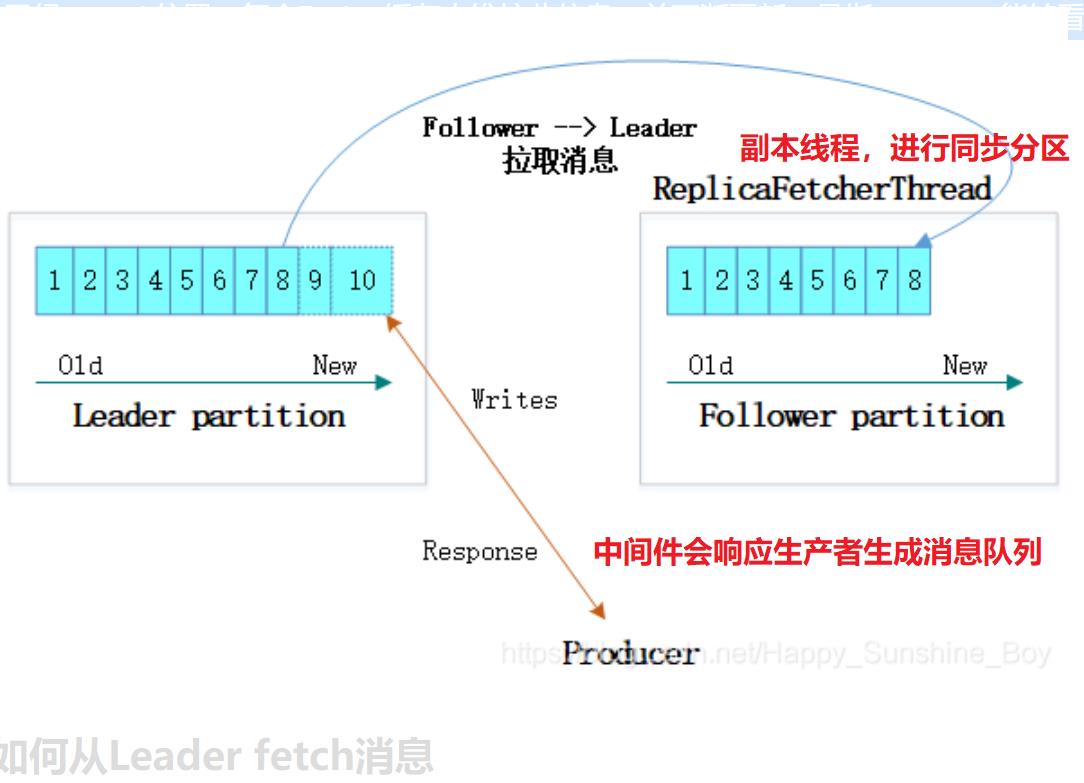
二、Kafka工作流程图
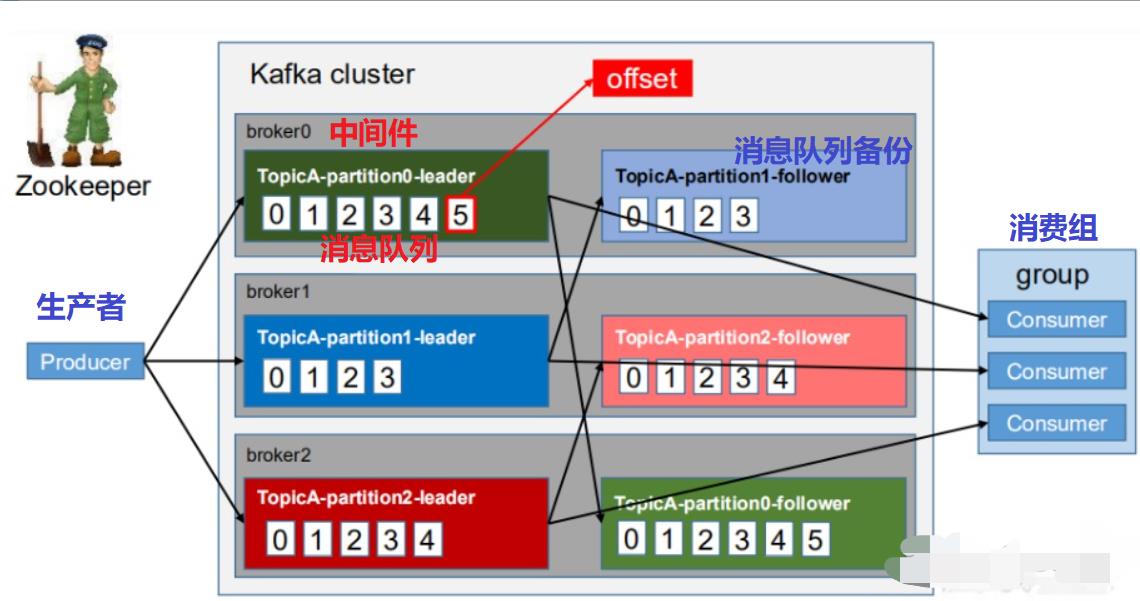
不管生产消息,还是消费消息,都是面向消息队列(topic),但消息队列实际上不过是逻辑上的概念,而分区(partition)才是物理上存储数据的概念。分区对于着data数据文件(.log)源于生产者,生产的新数据追加到log文件末端,每条数据都有自己的偏移量(offset),消费者根据记录自身消费到的offset来确定上次消费到的数据。便于恢复。
三、Kafka文件存储机制
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。每个 segment 对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic 名称+分区序号。例如,first 这个 topic 有三个分区,则其对应的文件夹为 first-0,first-1,first-2。
“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
以上是关于Kafka的相关原理的主要内容,如果未能解决你的问题,请参考以下文章