Presto高性能引擎在美图的实践
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Presto高性能引擎在美图的实践相关的知识,希望对你有一定的参考价值。
导读:本文的主题是Presto高性能引擎在美图的实践,首先将介绍美图在处理ad-hoc场景下为何选择Presto,其次我们如何通过外部组件对Presto高可用与稳定性的增强。然后介绍在美图业务中如何做到合理与高效的利用集群资源,最后如何利用Presto应用于部分离线计算场景中。使大家了解Presto引擎的优缺点,适合的使用场景,以及在美图的实践经验。
01
技术选型
Presto是一个Ad-Hoc的ROLAP解决方案。ROLAP的优缺点简单介绍如下:

ROLAP优点:
ROLAP适合非常灵活的查询。
ROLAP查询性能相对比较高。
ROLAP针对MPP架构支持实时数据的写入与实时分析。
Presto内置支持各种聚合的算子,如sum、count,擅长计算一些指标如PV、UV,适合多维度聚合查询。
ROLAP缺点:
所有计算和分析都是基于内存去完成的,对内存的需求比较大。
线上实际使用过程中发现,查询周期相对比较长时(如查一年、两年的数据),经常会遇到数据量会过大的问题,会线性影响查询性能。
对比MOLAP由于需要提前做一次预计算,Presto则存在一定的性能差距。
MOLAP的典型技术实现是Druid和Kylin。两者均通过做预计算,创建对应的cube,来实现一个性能上比较快的OLAP方案。但是,这是以牺牲业务灵活性为代价的。相比来说,Presto有更好的灵活性。
我们内部调研了三个Ad-Hoc的ROLAP技术组件选型,包括Hive on Spark,Impala和Presto。
1. Hive on Spark

Hive on Spark的优点,首先是在美图内部广泛使用,经受住了时间的考验。其次是使用上的灵活性,因为已经使用了很多年,相对比较熟悉,做过较多二次改造,包括源码增强和一些重点模块重构。
缺点也是显而易见的,Hive on Spark在查询一些相对比较大的任务,容易发生shuffle、OOM和数据倾斜等问题。其次,Hive on Spark和其他竞品如Impala和 Presto相比,查询速度很慢,明显无法满足在线查询的需求。
2. Impala
Impala的优点,首先是轻量快速,支持近实时的查询。其次,所有计算均在内存中完成,减少了计算延迟和磁盘IO开销。
但缺点也比较多,首先是主节点缺乏高可用的机制(HA机制)。其次是零容忍问题,即一个查询发送过来的话,如果其中一个节点查询失败,会导致整个查询都失败。再次,我们在使用过程中发现它对自定义函数支持的不是很好。另外,Impala强依赖于CDH的生态,跟我们现有架构不能很好的融合。我们现有架构使用了一些开源社区的组件。如果强依赖于CDH, 当我们要做版本升级、补丁升级或者代码重构后的升级时,存在过度依赖CDH而操作不友好的问题。最后,就是查询数据量过大的话,会发生比较严重的性能下降。此外,还有对于并发的支持,不是特别好。
3. Presto
最后来看今天的主角Presto。Presto优点首先是轻量快速,支持近乎实时查询。其次,它的社区活跃度也比较高,文档也比较完善,基本可以兼容业务上所有的SQL,也能扛住比较大的并发。
当然Presto也有一些缺点,一是零容忍问题,如果一个失败,一个节点上的查询失败,会导致整个查询的失败。再就是主节点缺乏HA的机制。HA这个缺点,业界也有方案可以去完善。在下一个章节,会分享美图是如何完善HA机制的。
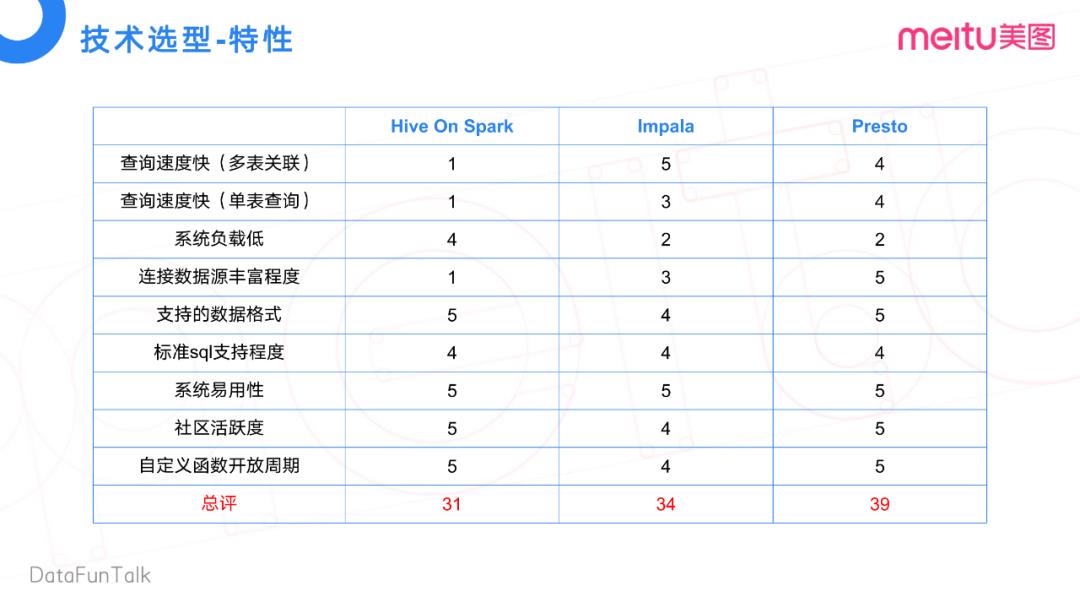
我们通过对比三个组件的一些特性,包括多表关联、单表查询和系统负载等,得到了一个打分。分数越高越适合我们的业务场景,优势越明显。表格中可以看到,Presto总计39分是最高的,最符合我们的业务场景。
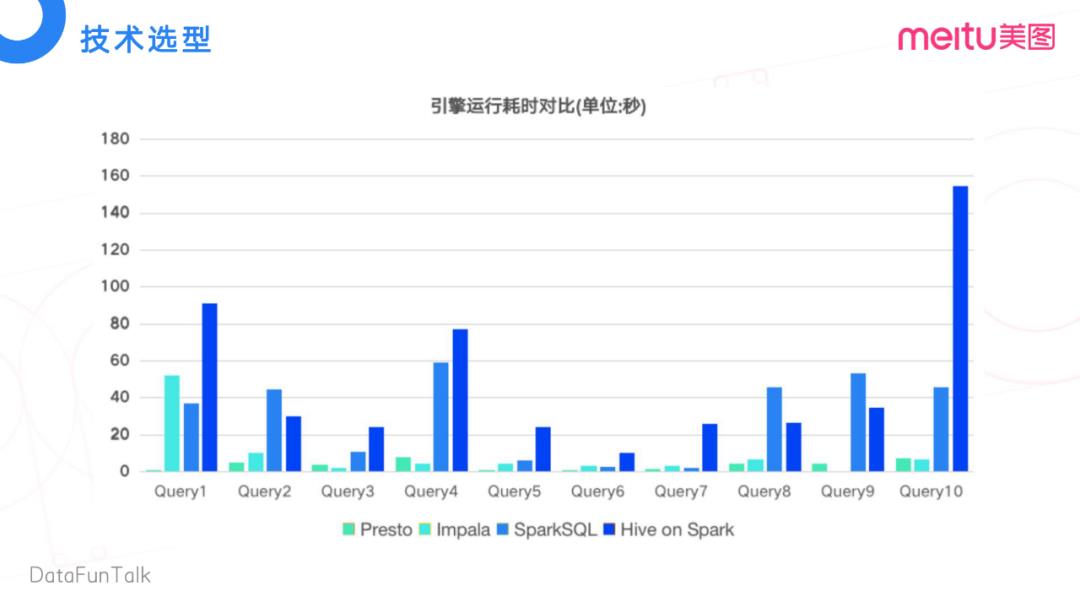
同时我们也做了计算性能上的对比。Presto的性能最好,Impala略微差一些。可能比较细心的同学会发现,在Query 9里面,Impala的结果是空白的,这是因为Impala不兼容Query 9中的语法。这里面我们也对比了在美图内部用的比较多的Spark SQL,由于上篇文章没讲到Spark SQL,所以这里只做了一个性能的比较。基于这些维度考虑,我们最终选择了Presto。
02
Coordinator HA
1. 单点问题
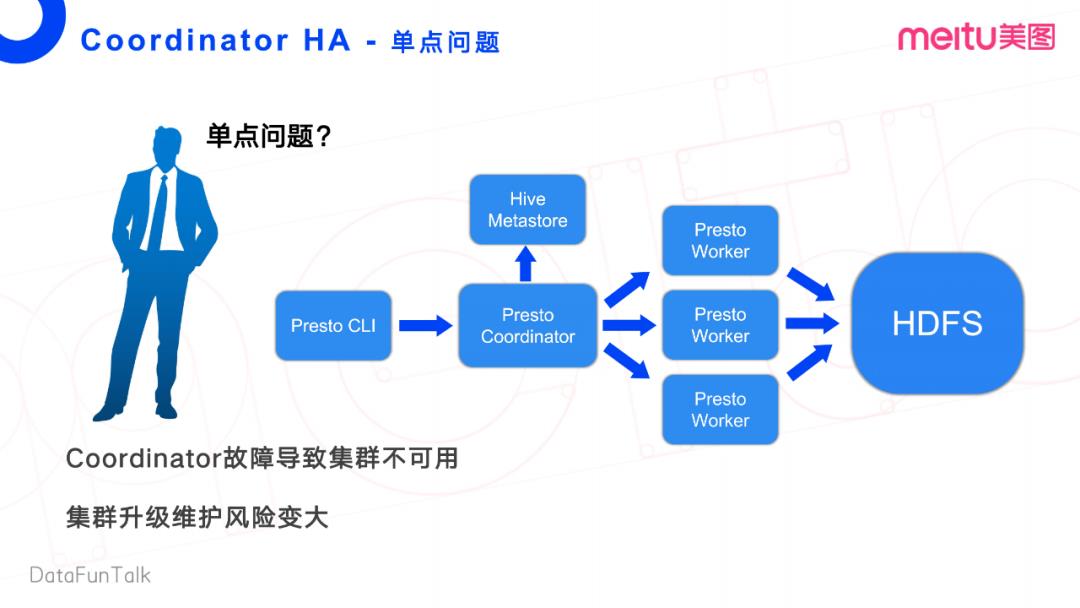
前面提到,Presto有一个比较致命的缺陷,就是缺乏主节点的HA高可用性。在这一章节中,看看我们如何去克服和完善这个组件。
首先,我们看一看Presto的整体流程。Presto Client端发送一个查询请求给Presto的Coordinator, Coordinator先去Hive Metastore获取这个任务执行过程中所需的一些源数据信息,再将任务转发给它对应的Worker节点,然后Worker节点从文件系统里面去拉数据做计算。
这个流程中,显而易见致命的缺点是Coordinator的单节点。Coordinator故障会导致整个集群的不可用,会严重影响线上业务。此外,Coordinator对集群升级也带来比较大的风险。
2. 方案
这里面整理了业界广泛使用的两个方案。
方案一:
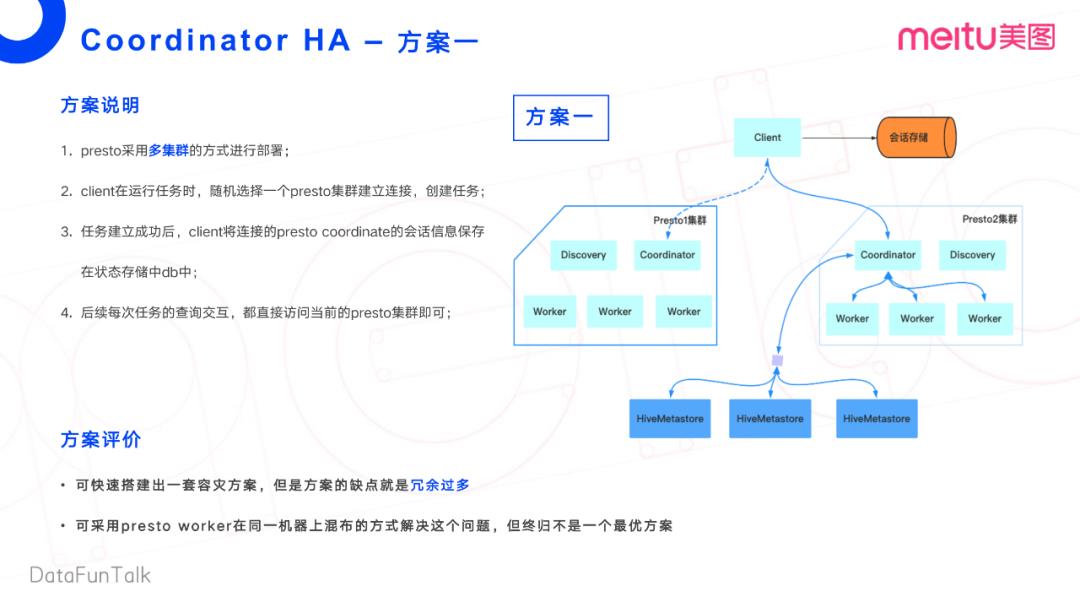
方案一是多集群部署的方式,分为两个集群,分别为Presto集群一和Presto集群二。Client端在运行任务时,会按照一定的规则去选择某一个Presto集群,建立连接,创建任务。任务建立完成后,Client端将连接的Presto Coordinator会话信息保存起来,存储在DB里面。这样当Presto集群挂掉之后,当前会话会有一些任务失败,在连接到新的集群之后,可以做任务恢复。最后,每一次任务进行交互的时候,都直接访问当前获取连接的Presto集群即可。
这个方案本身没有问题,可以快速的搭建出一套容灾方案。但是其缺点也是显而易见的。其实只需要一套集群,但是做了过多的冗余,用了两套集群来完成在线查询的业务,在成本方面不能接受。当然基于这个方案,也可以在同一个机器上做混部,相当于一个机器多个Worker实例。但会存在管理难度比较大的问题,可能会涉及到Worker与Worker之间的资源抢占,终归不是最优的方案。
这里稍微点一下,这边Meta Store有三台机器,是为了实现高可用。Coordinator接收到任务,会去获取任务的一些源数据信息。此时通过三个Meta Store进行轮询选择。当一台Meta Store挂掉之后,还有两个实例可以用。这个方案一被pass掉了,因为不能接受它的冗余。
方案二:
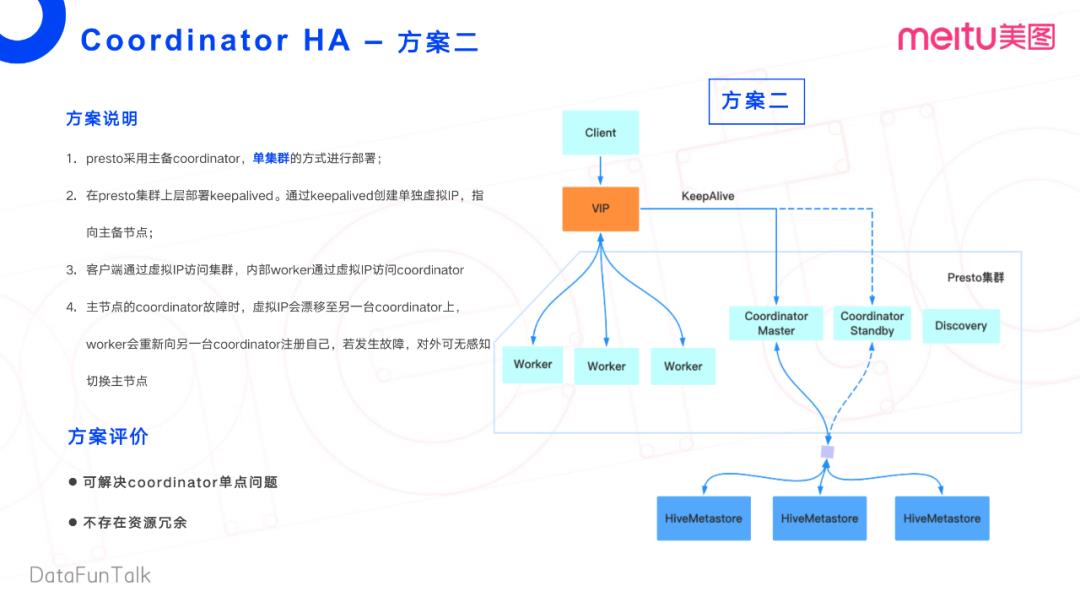
接下来看方案二,Presto采取了一个主备的Coordinator单集群部署方式。这个是大规模集群比较常见的部署方式。
首先,在Presto集群上层部署一个KeepAlived的第三方服务。然后通过KeepAlived创建单独的虚拟IP(Virtual IP),指向对应的主备节点。这样,客户端通过虚拟IP访问集群,内部Worker也通过虚拟IP访问Coordinator节点。主节点故障时,KeepAlived通过内部的服务注册Discovery机制,注册到一台新的Coordinator上,这样对虚拟IP的访问会飘移至另外一台Coordinator,同样Worker节点也会访问另外一台Coordinator。
总结来说:如果Coordinator master发生了故障,可以业务无感知的切换到备用Coordinator上。这个方案可以解决我们Coordinator单点的问题,也不存在任何的资源浪费的问题。
3. 实施步骤
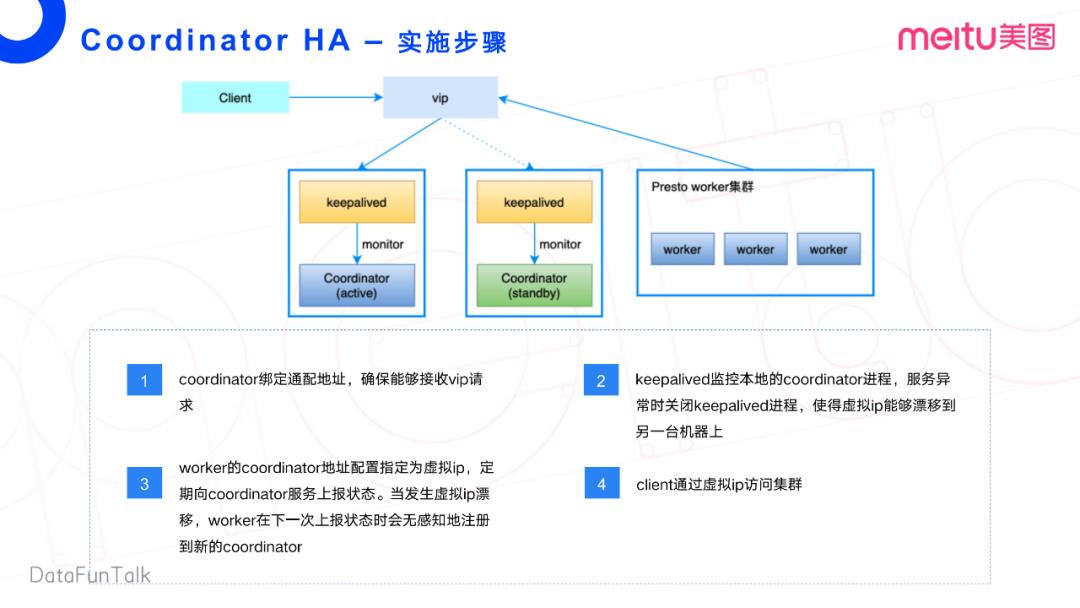
接下来我们再细细的看一下方案二的一个大致的实施步骤。第一,需要绑定一个通配地址,也就是类似0.0.0.0这么一个通配地址,确保能接受VIP的请求。如果是同网段,这样的IP也可以, 只要他的这个网络环境是互通的就可以了。
第二点就是使用KeepAlived去监控本地的Coordinator进程。当服务发生异常时,去关闭这个KeepAlived进程,使得这个VIP可以漂移到另外一台机器上。将Worker的Coordinator地址配置成对应的VIP,然后定期上报状态。其实再展开一点,Worker并不是向真正的Coordinator服务上报状态,而是向Discovery这个服务去上报状态。Discovery相当于是Coordinator的一个进程。当发生虚拟IP漂移的时候,Worker会在下一次上报状态的时候,无感知的去注册到新的Coordinator。Client可以继续通过VIP去访问集群。
可能会有点绕,大家只要记住,Coordinator和Worker都是通过这个VIP去进行关联与信息交互。在网上,这个方案也相对比较成熟,具体的代码和配置都可以找到。
03
跨集群调度
1. 背景介绍
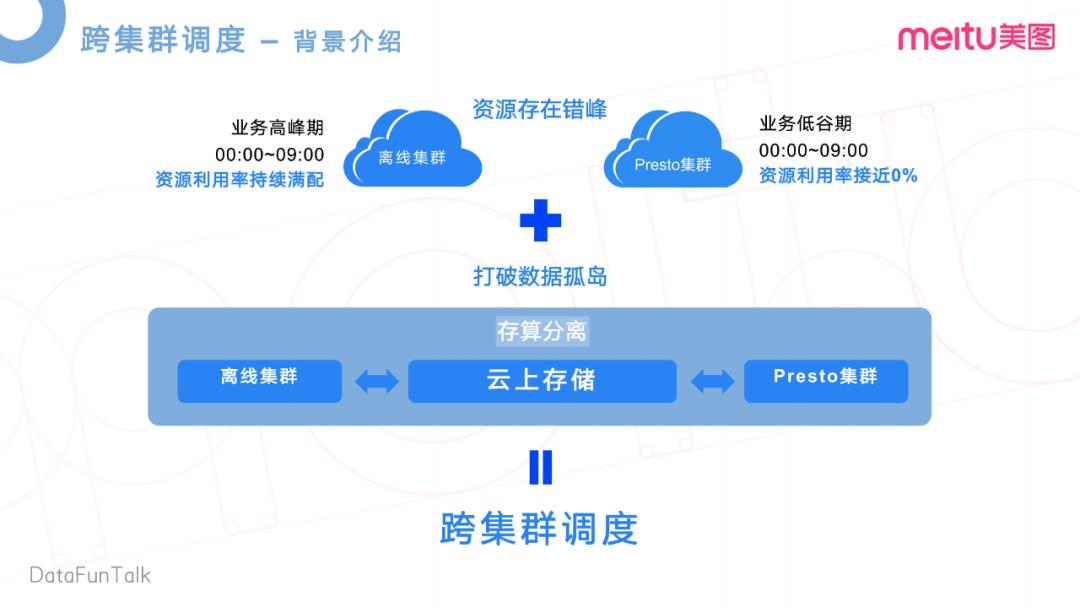
第三部分,我们来介绍一下美图内部跨集群调度的实现。这是基于我们的业务特性去做的一个优化。我们内部有两套集群,其中一个为离线集群,主要就是跑一些统计报表,离线查询之类的任务,另一个是Presto集群。他们存在一个资源错峰状态,离线集群业务高峰是在凌晨的0点到9点,会将资源利用率持续打满。Presto本身是一个在线查询的集群,基本上凌晨没人使用,0点到9点是它的一个业务低谷,资源利用率接近0%。这样存在一个资源错峰。我们想把Presto在业务低谷的这部分资源利用上。
可能大家会有个疑问,传统的集群部署基本上都是从自己的HDFS去拉取数据。如果资源要互通的话,就需要去访问各个集群上的文件,才能做下一步的计算。
2. 架构演进
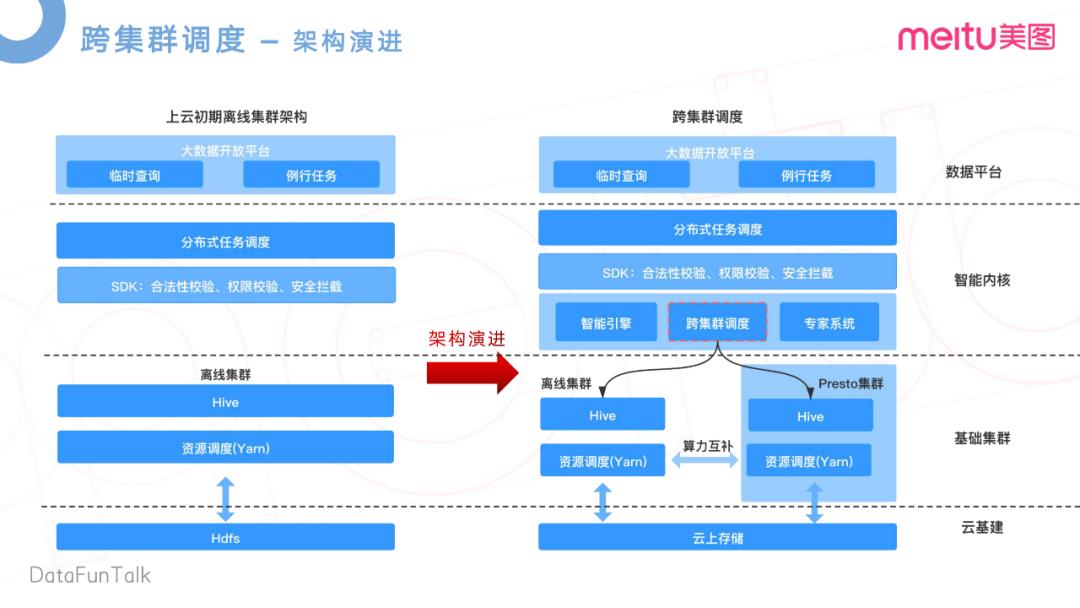
美图在去年完成了一个上云的操作,在云上使用了存算分离的架构,实现了数据的统一存储。这样的好处是打破了传统架构的数据孤岛的问题,离线集群和Presto集群可以无差别的访问云上的存储,即离线集群可以访问到Presto集群上的数据,Presto上的数据也可以访问到离线集群的数据。基于这两点,我们就提出了一个跨集群调度的概念,去减轻离线集群的高峰负载,提升Presto集群凌晨业务低谷资源使用率。
在上云初期,因为有数据孤岛,各自集群有各自的HDFS,数据没法互通。如图所示,这是上云初期架构示意图。在上层,是对应的大数据开放平台,做一些临时查询,和一些例行任务。在下一层,是自研的一个分布式调度系统,主要是做任务的一些日常调度。再下来,我们开发了一个检验层,做一些合法性的校验。任务合法性,是指这个任务所携带的参数和语法,是否合法等。在这里还做了统一的权限校验等数据安全的拦截。这些校验完成之后,才会转发给离线集群,通过Yarn去做资源调度,以及跟HDFS的交互。
3. 转发策略
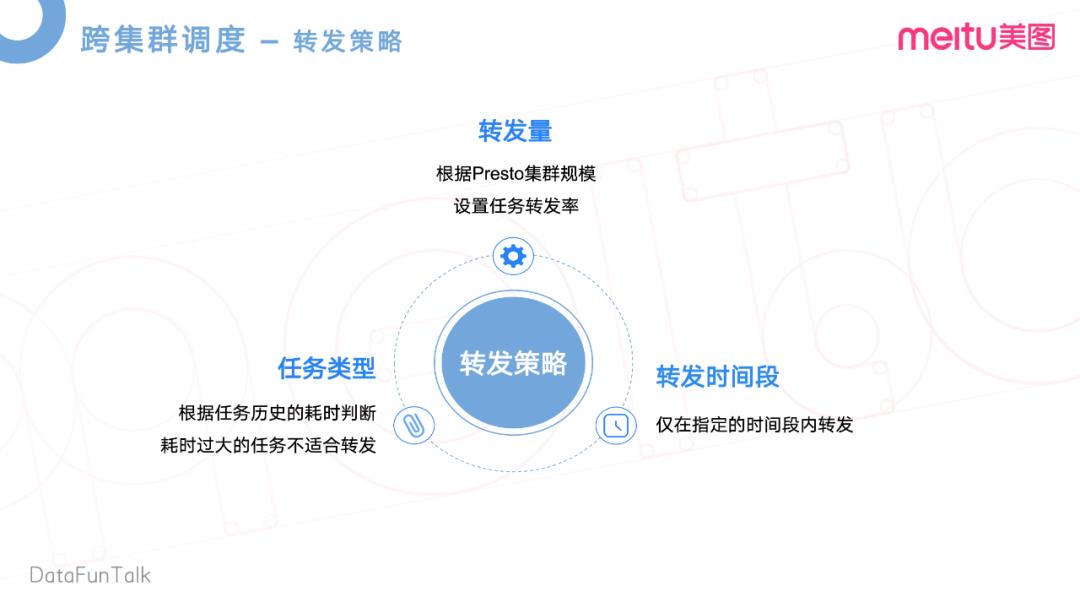
在实现跨区域调度之后,团队内部研发了一个智能内核。智能内核其实里面有三个比较核心的东西,一个是智能引擎,也就是和团队现在一起在做的事情。跨集群调度就是通过这个任务根据评估离线集群和Presto集群的一个业务集群负载,去转发到各自的集群,去分担各自的集群压力,或者说提升一个资源的利用率。这边也实现了一个算力互补的这么一个东西,当然最底层是通过我们的云基建,云上存储进行实现的。当然我们在评估这个转发,就是什么样的任务可以去转发到Presto上呢,我们也做了一些简单的转发策略,比如说转发量上,我们会根据Presto集群规模,去设置一些离线任务的转发率。
再就是转发的时间段,需要在指定的时间段内转发。因为业务低峰是0点到9点,那么在9点之后,分析师同学已经上班了,可以开始去做一些在线查询的一些操作。那不能影响他们的业务,所以我们需要规定一个转发时间段。还有一些任务的类型,需要判断历史任务的一些耗时,若耗时比较大的任务,就不适合做这个转发。
4. 实施步骤
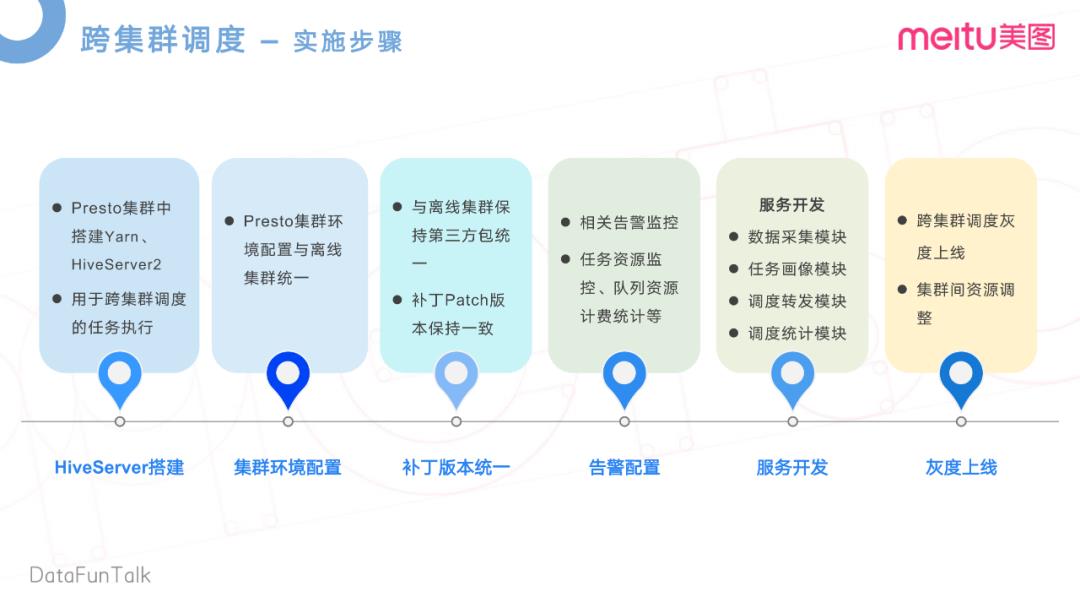
具体的实施步骤跟大家简单的看一下。
首先是Hive Server服务的搭建。在离线集群上,我们用了Hive on Spark。了解过Hive on Spark的同学呢,就知道他们其实是通过Hive Server进行任务接收的。我们在Presto集群内去搭建和部署自己的Yarn和Hive Server环境,主要是用于跨区域调度的任务、接受和执行等。再就是,因为Hive集群的这个任务要转发至Presto集群上运行,所以离线集群的配置也要和Presto集群做一些统一。
其次是用到的一些第三方包,还有一些补丁。在内部团队也做了比较多的代码重构。需要去将这些代码去Merge到Presto的集群上,做好补丁的统一,还有相关告警配置,队列资源计费统计。再就是一些服务开发,这个服务开发主要就是用于我们的专家系统,还有智能引擎的一些服务模块,最后就是灰度上线。
当前面的这些环境全部都做好之后,开始灰度,灰度覆盖率由小到大做任务的转发。可以看一下这个收益分析。离线集群的资源在夜间它的消耗降低了10%,因为集群间已经实现了算力互补,可以将离线集群的一部分机器去迁移至Presto集群上,那也相当于对Presto做一个扩容。这样Presto的集群性能也提高了19%。
04
展望未来

最后,我们对未来进行一个展望。在大数据场景下,根据任务属性的不同可以分为三类任务:大shuffle任务,中大型任务和小型任务。
大shuffle任务数据量非常大,查询级别在数百亿,还有比如说做多维度的cube构建,或者grouping set类似这样的操作,比较适合Hive on Spark运行。因为Hive on Spark是基于磁盘进行计算,稳定性相对高。
中大型任务的数据量相对比较大,SQL语句也比较复杂,比较适合Hive on Spark或者Spark SQL。在日常使用中,我们发现Spark on SQL的性能明显优于Hive on Spark。但是,对于在这部分中大型任务,团队内正在尝试使用Presto来解决时效性或者运行时间问题。
小型任务的数据量比较小,SQL也比较简单,非常适合Presto去做。Presto对小型任务也有比较好的性能表现。
用一句话来总结:对于中大型任务和小型任务,会将原来的Hive on Spark或者Spark SQL的运行方式,逐步切换到Presto上,来达到性能提升的目的。
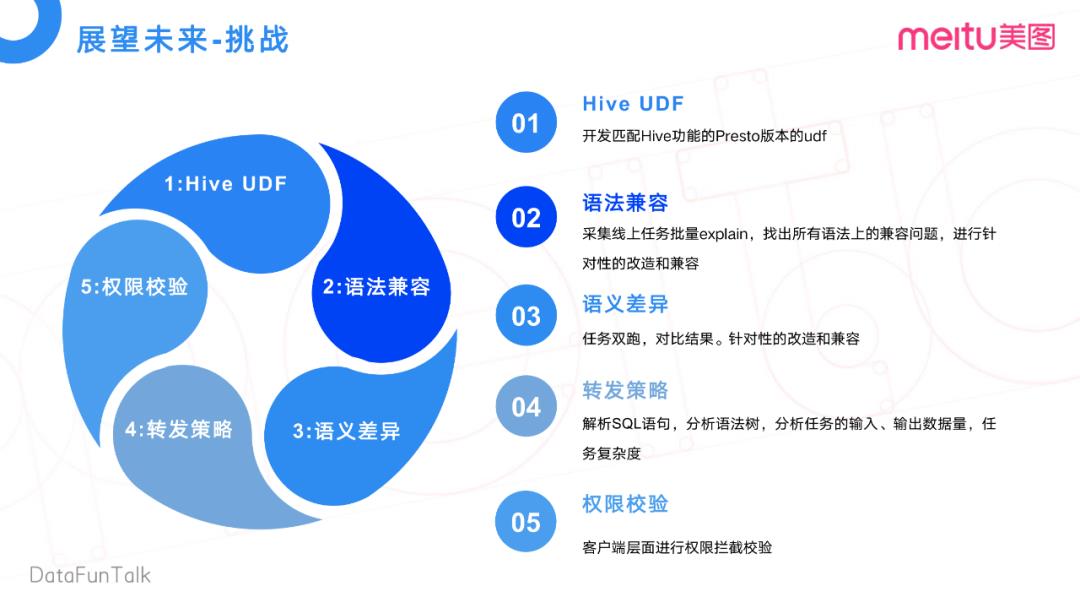
目前的架构也遇到了一些挑战:
比如,在离线统计Hive集群上,有些UDF有一些语法兼容的问题,还有一些语义差异。
比如某个任务,在离线集群上用了一个Hive UDF,在Presto上也要实现对应的UDF。现在这个完全是靠人力去开发对应的UDF。当然,后面也在想一些更好的方式,如何去快速的适配Hive上已有的UDF。
再就是一些语法上的兼容,比如说Hive语法在Presto上去跑,它不一定能兼容。那么我们会去采集线上所有的任务,去做一个提前的预编译,去找出语法上的一个兼容性问题,然后针对性的有选择的去做一些改造和兼容。为什么是有选择性呢?我们不一定会将线上所有任务都都扔到Presto上,只是有选择性把一些中小任务放Presto上执行。
还有就是语义的差异,我们会用Hive和Presto两个引擎执行,然后对比结果,针对性的做一些改造的兼容。再就是转发策略,什么样的任务能够转发到Presto上呢?我们会分析它的一个SQL语句,包括一些语法树的分析,还有任务的输入输出,任务复杂度的一些分析。
最后一点,是权限校验。我们会在客户端层做一个基于多引擎级别的统一权限校验。
05
问答环节
Q:是否考虑过使用Doris来对接Hive,性能相比Presto会快。
A:Doris暂时没有考虑,我们有在做ClickHouse。ClickHouse在我们内部慢慢做起来了之后,随着业务的接入,框架的相对比较成熟之后,也会考虑将ClickHouse接入到多引擎的这个架构里面。所以说Doris我们现在没有用。
Q:Presto在查询大数据性能和Hive on Mapreduce差的很多吗?可以对比一下吗?
A:Presto在查询中小型任务性能远远好于Hive on Mapreduce,但如果查询大任务的话就不一定了,因为Presto主要基于内存上的计算。在线上其实也发现,如果一个任务查询的时间周期比较长的话,拉取数据的量级也比较大,计算复杂度高。任务很可能会失败,甚至会拖垮整个集群。所以我们会在客户端做一定的拦截去保护,相当于一定的熔断机制,就不让这样的任务发到Presto集群内部。所以若一个非常大的查询的话,我还是比较建议将这样的任务去转发到Hive on MR或者说Hive on Spark这样的引擎上。中小型任务可以尝试在Presto引擎上执行。
Q:更进一步了解智能引擎是如何工作的?
A:智能引擎一个核心的概念,就是会对历史的一些做一些分析,得到任务画像系统。当任务下一次任务再运行后,会根据这个画像系统里面的存储的一些任务metric信息,去指定给我们下层的最适合的引擎,就是相当于最适合的任务交给最适合的引擎执行。例如我们有MapReduce,Hive on Spark, Spark SQL引擎还有包括说后面会继续引入的Presto,那么什么样的任务适合什么样的引擎执行,这正是智能引擎做的事。
分享嘉宾:

以上是关于Presto高性能引擎在美图的实践的主要内容,如果未能解决你的问题,请参考以下文章
B站Presto + Alluxio:B站数据库系统性能提升实践