Presto 常用性能优化技巧
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Presto 常用性能优化技巧相关的知识,希望对你有一定的参考价值。
Presto 是一个用于分析的开源分布式 ANSI SQL 查询引擎,支持计算和存储的分离。性能对于一些分析查询尤其重要,因此 Presto 有许多设计特性来最大化 Presto 的速度,比如内存中的流水线执行(memory pipelined execution)、分布式的扩展架构和大规模并行处理(MPP)设计。Presto支持的具体性能特性:
•数据压缩(SNAPPY, LZ4, ZSTD 以及 GZIP)•数据分区•表统计信息:由 ANALYZE 命令收集并存储在 Hive metastore 中,这些数据可以提供给 Presto 的查询计划器,以产生比较好的执行计划;•Presto 使用基于成本的优化器(cost-based optimizer),正如您通常所期望的那样,它依赖于收集的表统计信息来实现最佳功能。
本文,我们将介绍一些 Presto 常用的性能优化技巧。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
Presto 性能优化技巧
以下建议可以帮助您实现 Presto 集群的最大性能:
•将 Presto 的 coordinator 和 workers 配置在单独的实例/服务器上,只有在非常小的规模的开发/测试使用时,才建议让 coordinator 和 worker 共享同一个实例。•始终根据实例的可用内存资源调整 Presto 的 java 内存配置。每个节点上的 etc/jvm.config 配置文件需要在启动 Presto 之前配置。一个有用的经验法则是:在每个节点的 jvm.config 文件中设置 -Xmx 为可用物理内存的 80%,然后根据对工作负载的监视进行调整。•如果使用 HDFS 或 S3 存储,可以考虑使用 ORC 格式来存储数据。Presto 对于 ORC 有许多优化,比如列式读取、谓词下推,以及跳过读取部分文件。•使用分区。我们可以在使用 CTAS 时通过 partitioned_by 参数来启用分区,具体参见 https://prestodb.io/docs/current/sql/create-table-as.html•使用分桶。在创建表时,使用 bucketed_by 和 bucket_count 来分别指定分桶列以及分桶的个数。•如果我们可以选择 MetaStore ,请为我们的 Presto 集群选择 Hive 而不是 Glue 。Hive 有一些 Glue 没有的特性,比如列级统计和动态过滤,它们可以提高查询性能。最终的决定将取决于系统和需求的特定组合。以下是对两者区别的总结:Presto Performance Tips 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据•收集表统计信息以确保生成最有效的查询计划,这意味着查询会尽可能快地运行。使用 ANALYZE TABLE命令来完成此操作。在数据发生重大变化时,定期对查询中涉及的所有表执行ANALYZE TABLE 命令。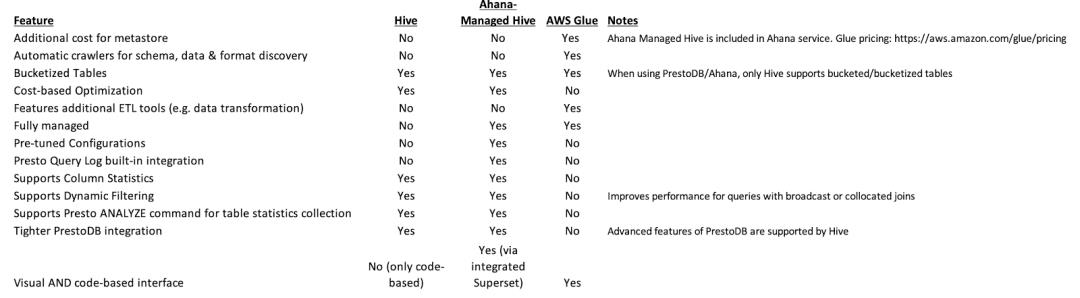 •如果您正在使用分区,请确保存储上的分区和 metastore 中的分区信息同步。比如我们有一张 default.customer 表,我们可以在表创建完时执行
•如果您正在使用分区,请确保存储上的分区和 metastore 中的分区信息同步。比如我们有一张 default.customer 表,我们可以在表创建完时执行 CALL system.sync_partition_metadata(‘default’, ‘customer’, ‘full’); 来同步分区;另外,在后面新增分区时可以使用这个命令来同步分区。•默认情况下,Presto 不会自动进行 JOIN 重排(re-ordering)。这只在启用基于成本的优化(CBO)特性时才会发生(见下文)。默认情况下,我们需要确保较小的表出现在 JOIN 关键字的右侧。记住: LARGE LEFT (把大表放在 JOIN 的左边)。如果我们在执行一个 JOIN 查询,你应该尝试启用基于成本的优化(CBO)特性,设置 SET session join_distribution_type=’AUTOMATIC’; 和 SET session join_reordering_strategy=’AUTOMATIC’;•当有1个或多个 JOIN 时,我们应该启用 Dynamic Filtering,特别是当有一个较小的维度表用于探测一个较大的事实表时。动态过滤被下推到 ORC 和 Parquet readers,可以加速对分区表和非分区表的查询。动态过滤是一种 JOIN 优化,旨在提高 Hash join 的性能。启用这个功能需要设置 SET session enable_dynamic_filtering=TRUE; 如果可行的话,对原始表进行排序,这可以大大提高性能,特别是动态过滤这个功能。•监控 Coordinator 节点过载的情况。如果 PrestoDB 集群有许多(>50) workers,那么根据工作负载和查询情况,单个 coordinator 节点可能会超载。coordinator 节点有很多职责,比如解析、分析、计划和优化查询、合并来自 Worker 的结果、任务跟踪和资源管理。再加上与集群中其他节点的所有内部通信都是通过 http 进行的重量级负担,我们可以体会到事情是如何开始大规模地变慢的。同时,尝试通过在更大的云实例上运行来增加 Coordinator 可用的资源,因为更多的 CPU 和内存可能会有所帮助。•为 workers 选择正确的实例,以确保它们有足够的 I/O。为 workers 节点选择正确的实例类型很重要。大多数分析工作负载都是 IO 密集型的,因此可用的网络 IO 数量可能是一个限制因素。总体吞吐量将决定查询性能。监视 worker 节点的 IO 活动以确定是否存在 IO 瓶颈是一个好主意。•考虑启用资源组(Resource Groups)。这是 Presto 的工作负载管理器,它用于限制资源使用,并可以对在其中运行的查询执行队列策略,或者在子组之间划分资源。查询属于单个资源组,并使用来自该组的资源。一个资源组表示打包在一起的可用 Presto 资源,以及与 CPU、内存、并发性、队列和优先级相关的限制。除了对排队查询的限制外,当资源组耗尽资源时,不会导致正在运行的查询失败;相反,新的查询会排队。资源组可以有子组,也可以接受查询,但不能两者兼得。更多细节请参见文档:https://prestodb.io/docs/current/admin/resource-groups.html
最后,为了帮助进行速度测试,Presto 内置了 TPC-DS 和 TPC-H 数据源,以生成不同规模的基准测试所需的数据。例如,1TB TPC-H 数据集由8张表中大约86.6亿条记录组成。
本文翻译自:https://ahana.io/learn/presto-performance/
以上是关于Presto 常用性能优化技巧的主要内容,如果未能解决你的问题,请参考以下文章