基于云原生的大数据实时分析方案实践
Posted 琦彦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于云原生的大数据实时分析方案实践相关的知识,希望对你有一定的参考价值。
1 方案介绍
大数据处理技术现今已广泛应用于各个行业,为业务解决海量存储和海量分析的需求。但数据量的爆发式增长,对数据处理能力提出了更大的挑战,同时对时效性也提出了更高的要求。实时分析已成为企业大数据分析中最关键的术语,这意味企业可将所有数据用于大数据实时分析,实现在数据接受同时即刻为企业生成分析报告,从而在第一时间作出市场判断与决策。典型的场景如电商大促和金融风控等,基于延迟数据的分析结果已经失去了价值。另外随着云原生时代的到来,云原生天生具有的高效部署、敏捷迭代、云计算资源成本和弹性扩展等优势,正在加速和缩短业务系统落地过程。云原生同样可助力大数据这一过程。
本文主要介绍如何利用 Kubernetes 实现云原生大数据实时分析平台。
2 总体架构
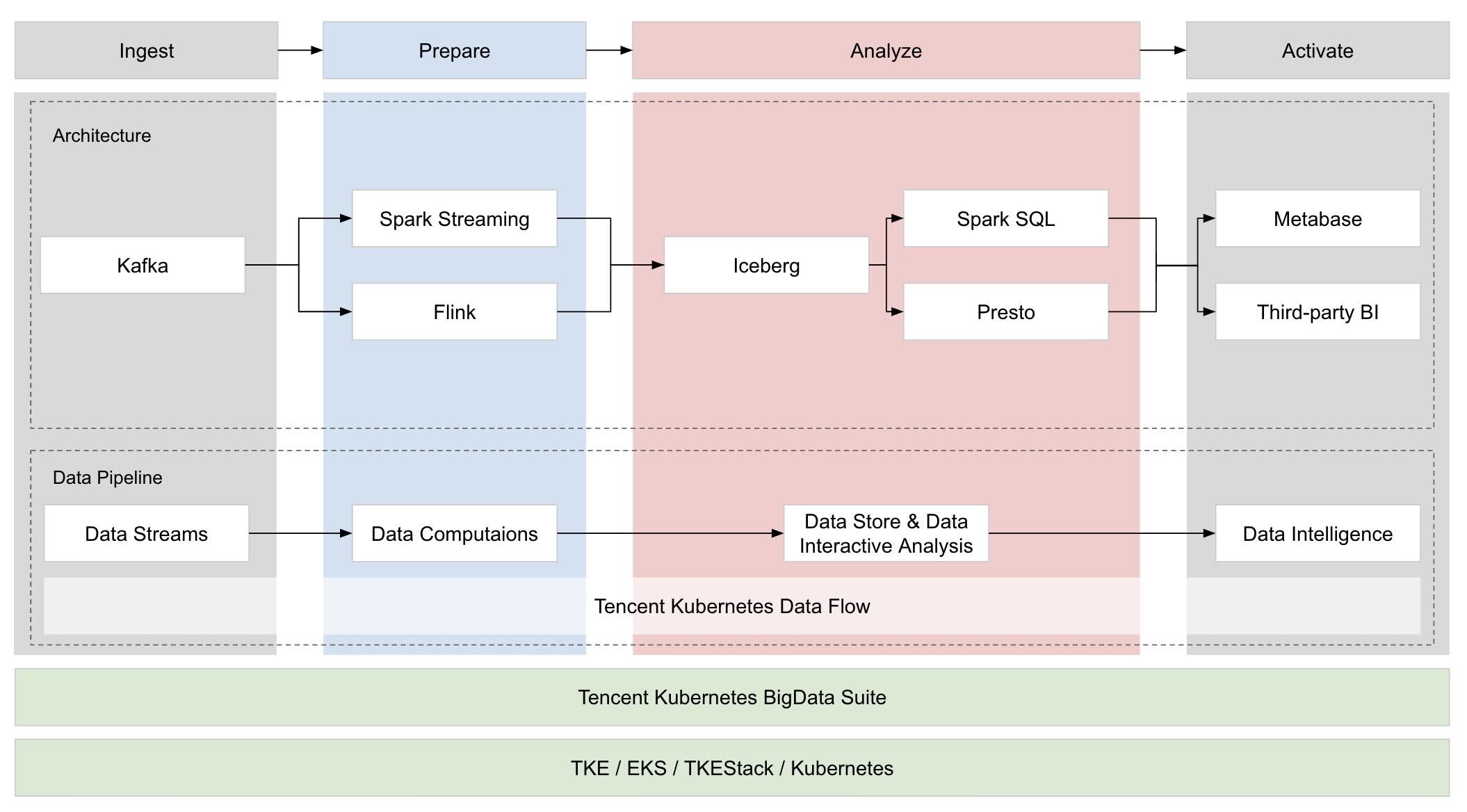
-
Data Streams:基于 Kafka 的数据流接入方案
-
Data Computations:基于 Spark Streaming 与 Flink 的流计算方案
-
Data Pipeline:基于 TKDF(Tencent Kubernetes Data Flow) 的数据工作流方案
-
Data Store:基于 Iceberg 与 HDFS 的数据湖方案
-
Data Interactive Analysis:基于 Spark SQL 与 Presto 的 SQL 交互式分析方案
-
Data Intelligence:基于 Metabase 的数据可视化方案以及若干数据接入方式
-
Data Infrastructure:基于 TKBS(Tencent Kubernetes Bigdata Suite)的云原生大数据套件方案,可帮助用户一键在 Kubernetes 上部署生产可用的大数据平台;基于 TKE / EKS / TKEStack 的 Kubernetes 引擎方案,可为用户提供生产、管控和使用 Kubernetes 集群服务
3 数据接入流
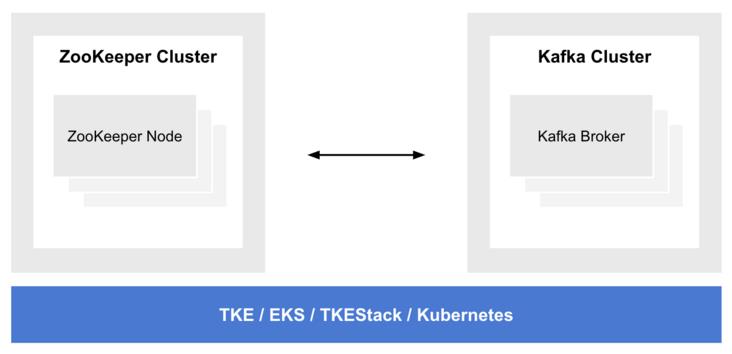
在实时分析中,需要持续、快速、实时地接受源源不断的数据与事件,作为整个分析平台的数据来源与入口。这个过程最好是基于流的、高吞吐、可扩展、可对接主流计算引擎。我们选择 Apache Kafka 作为事件流处理的解决方案。
Apache Kafka 是一个分布式流处理平台,被很多公司广泛使用于数据管道、流分析、数据集成,消息中间件等领域。Kafka 适合场景包括:
-
消息队列:构造实时流数据管道,它可以在系统或应用之间可靠地获取数据
-
流处理:构建实时流式应用程序,对这些流数据进行转换或者影响
Apache Kafka 可通过容器化部署在 Kubernetes,充分利用 Kubernetes 资源自动部署、自动扩展、一次配置任意运行等能力做到云原生赋能。
4 数据计算
在传统的数据处理流程中,总是先收集数据,然后将数据放到数据库中。当人们需要的时候通过数据库对数据做查询,得到答案或进行相关的处理。这样看起来虽然非常合理,但是结果却非常的紧凑,尤其是在一些实时搜索应用环境中的某些具体问题,类似于 MapReduce 方式的离线处理并不能很好地解决问题。这就引出了一种新的数据计算结构 - 流计算方式。它可以很好地对大规模流动数据在不断变化的运动过程中实时地进行分析,捕捉到可能有用的信息,并把结果发送到下一计算节点。
在云原生下,我们将流计算引擎容器化和迁移到 Kubernetes 上,利用 Kubernetes 自动化部署、HPA 等能力实现计算资源动态创建、调度与伸缩。云原生赋予了流计算即拿即用资源的能力。

当前主流的流计算引擎均可顺畅的运行在 Kubernetes 之上。
4.1 Spark on Kubernetes
Spark 在 2.3 之后,支持将集群创建和托管到 Kubernetes 中,以 native 方式运行。
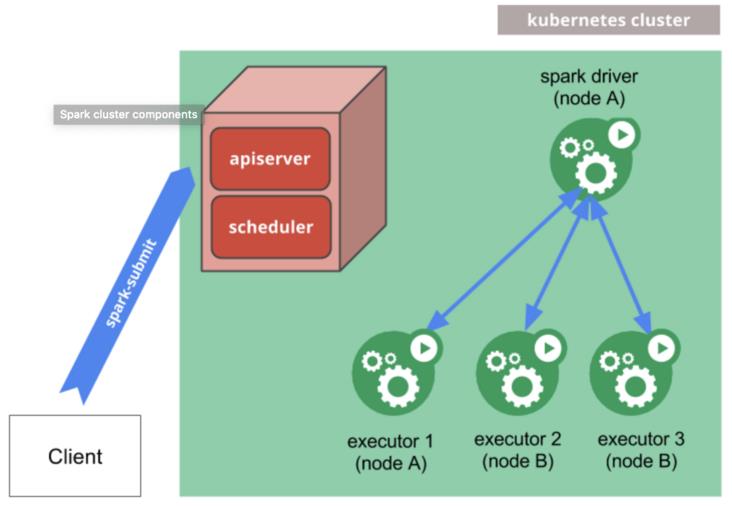
Kubernetes 可帮助 Spark 任务分配和管理计算资源,提供网络和存储,管理任务生命周期,动态的横向扩展能力,以及连接 Kubernetes 生态其他服务的能力。
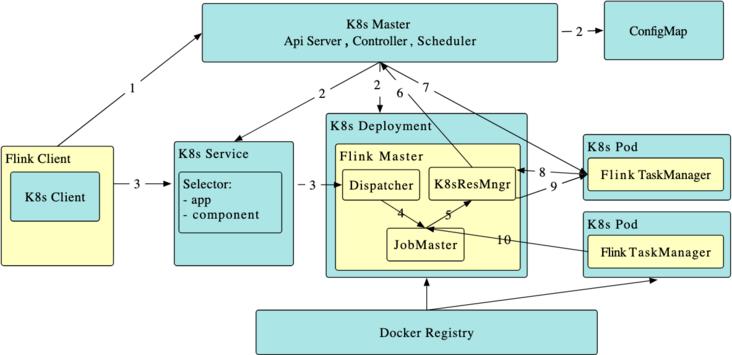
4.2 Flink on Kubernetes
Flink 在 Kubernetes 上支持 standalone 与 native 两种模式。standalone 相当于利用 Kubernetes Deployment、Service、Configmap 等在 Kubernetes 上创建一个完整 Flink 集群。native 方式类似 Spark native,是通过内置于 Flink Client 的 K8s Client 与 Kubernetes 集群交互,负责组件资源的创建和销毁。Flink 新引入的 Application 模式,更是可以在提交 Job 的同时动态创建 Flink 集群。
5 数据工作流
数据工作流(Data Pipeline)可以理解为一个贯穿数据产品或数据系统的管道,而数据就是管道载体的运输对象。数据工作流连接了数据处理分析的各个环节,将整个庞杂的系统变得井然有序,便于管理和扩展。
我们根据生产经验,设计和研发了基于云原生的数据工作流方案 TKDF,以帮助用户集中精力从数据中获取所需要的信息,而不是把精力花费在管理日常数据和管理数据库方面。
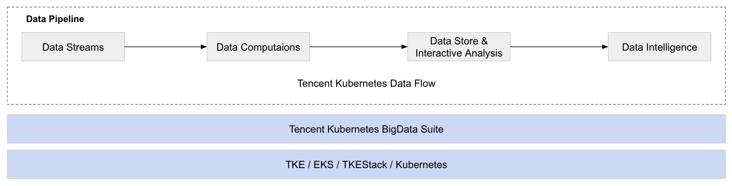
TKDF 有以下优势:
-
基于云原生
-
YAML 声明式定义
-
支持主流数据源
-
接口式封装,可插件化增加新的数据源实现
-
完整的数据生命周期管理
-
原生支持 Spark Streaming
-
计算模型抽象,支持基数统计近似、漏斗模型、模糊计算、产品运营指标等
6 数据湖
现今大数据存储和处理需求越来越多样化,在后 Hadoop 时代,如何构建一个统一的数据湖存储,并在其上进行多种形式的数据分析,成了企业构建大数据生态的一个重要方向。怎样快速、一致、原子性地在数据湖存储上构建起 Data Pipeline,成了亟待解决的问题。并且伴随云原生时代到来,云原生天生具有的自动化部署和交付能力也正催化这一过程。
基于 Hadoop 的云原生数据湖
传统方式下,用户在部署和运维大数据平台时通常采用手动或半自动化方式,这往往消耗大量人力,稳定性也无法保证。Kubernetes 的出现,革新了这一过程。Kubernetes 提供了应用部署和运维标准化能力,用户业务在实施 Kubernetes 化改造后,可运行在其他所有标准 Kubernetes 集群中。在大数据领域,这种能力可帮助用户快速部署和交付大数据平台(大数据组件部署尤为复杂)。尤其在大数据计算存储分离的架构中,Kubernetes 集群提供的 Serverless 能力,可帮助用户即拿即用的运行计算任务。并且再配合离在线混部方案,除了可做到资源统一管控降低复杂度和风险外,集群利用率也会进一步提升,大幅降低成本。
我们使用 TKBS 在 Kubernetes 上构建 Hadoop 数据湖:

基于 Iceberg 的云原生实时数据湖
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table.
Apache Iceberg 是由 Netflix 开发开源的,其于2018年11月16日进入 Apache 孵化器,是 Netflix 公司数据仓库基础。Iceberg 本质上是一种专为海量分析设计的表格式标准,可为主流计算引擎如 Presto、Spark 等提供高性能的读写和元数据管理能力。Iceberg 不关注底层存储(如 HDFS)与表结构(业务定义),它为两者之间提供了一个抽象层,将数据与元数据组织了起来。
Iceberg 主要特性包括:
-
ACID:具备 ACID 能力,支持 row level update/delete;支持 serializable isolation 与 multiple concurrent writers
-
Table Evolution:支持 inplace table evolution(schema & partition),可像 SQL 一样操作 table schema;支持 hidden partitioning,用户无需显示指定
-
接口通用化:为上层数据处理引擎提供丰富的表操作接口;屏蔽底层数据存储格式差异,提供对 Parquet、ORC 和 Avro 格式支持
依赖以上特性,Iceberg 可帮助用户低成本的实现 T+0 级数据湖。我们使用 Iceberg + HDFS 的方式在 Kubernetes 上构建云原生数据湖。
我们使用 Kubernetes 负责应用自动化部署与资源管理调度,为上层屏蔽底层环境复杂性。通过 TKBS 一键式部署云原生数据湖。Iceberg + HDFS 实现了基于 Hadoop 生态的实时数据湖,为大数据应用提供数据访问及存储能力。Spark、Flink、Presto 等计算引擎以 native 或 standalone 方式运行于 Kubernetes 集群中,资源可随提交任务即拿即用。与在线业务混部后,更能大幅提升集群资源利用率。
-
Resource Layer:使用 Kubernetes 提供资源管控能力
-
Data Access Layer:使用 Iceberg 提供 ACID、table 等数据集访问操作能力
-
Data Storage Layer:使用 HDFS 提供数据存储能力
-
Data Computation Layer:使用 Spark / Flink / Presto on Kubernetes 提供流批计算能力或实现 SQL 引擎
7 交互式分析
实时分析除了持续实时分析外(Continuous real-time analytics),还包括交互式分析(On-demand real-time analytics)。交互式分析是一种反应式分析方法,用户通过查询获取分析结果(比如输入 SQL 语句)。我们采用 SQL 语句作为交互式查询语句,支持 Spark SQL 与 Presto 两种 SQL 查询引擎。
7.1 Presto on Kubernetes
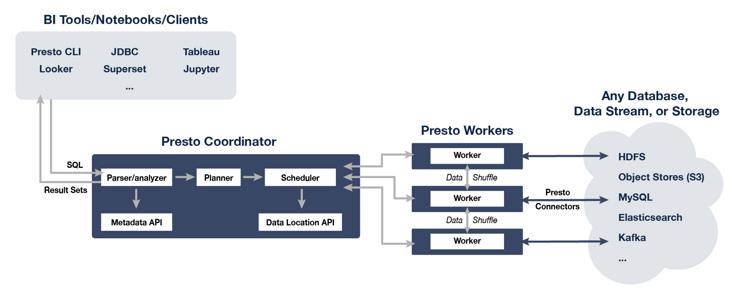
Presto 是由 Facebook 开源的分布式 SQL 查询引擎,专门为交互式查询所设计,提供分钟级乃至亚秒级低延时的查询性能。它既可支持非关系数据源,例如 HDFS、Amazon S3、Cassandra、MongoDB 和 HBase,又可支持关系数据源,例如 mysql、PostgreSQL、Amazon Redshift、Microsoft SQL Server 和 Teradata。
Presto 查询引擎是 Master-Slave 架构,由一个 Coordinator节点,一个 Discovery Server 节点,多个 Worker 节点组成。
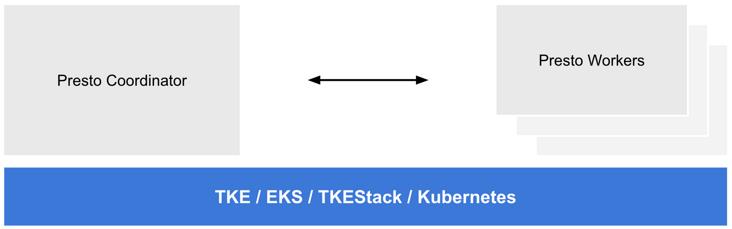
我们通过 standalone 方式将 Presto 集群部署在 Kubernetes 上:
7.2 Spark SQL on Kubernetes
Spark SQL 是 Spark 结构化数据的执行模块,可支持使用 SQL 在 Spark 查询分析结构化数据 DataFrames、Datasets。我们同样支持使用 Spark SQL 作为交互式分析引擎,将执行的 Spark 任务以 native 方式运行在 Kubernetes 上。
8 数据智能分析
我们正处于大数据和数字化转型的时代,数据无处不在,运用数据驱动的思想和策略在实践中逐渐成为共识。数据的价值已在科学研究和工商业的不同领域得到充分展现。数据智能工具和技术的应用可以帮助决策者更好地理解所收集的信息,从而开发出更好的业务流程。我们通过提供数据接口与接入外部 BI 来达成这一目的。
8.1 数据接口
我们通过以下方式提供交互式入口或数据接口,以帮助用户使用或接入第三方系统:
-
图形化界面:基于 Metabase 的开源 BI 系统
-
JDBC 接口:通过 Spark Thrift Server 或 Presto JDBC Driver 的连接
-
命令行接口:通过 Spark SQL CLI 或 Presto CLI 连接
8.2 数据可视化
Metabase 是一个开源的商业智能工具,你可以向它提出关于数据的问题(数据查询),而获取有意义的格式化结果(图形化视图)。我们可通过它理解数据、分析数据,以数据驱动决策。
Metabase 支持诸多数据源及计算引擎接入:

我们利用官方提供的 Helm 包,可以方便的将 Metabase 部署于 Kubernetes 上。
9 数据基础设施
9.1 TKBS
TKBS(Tencent Kubernetes Bigdata Suite)是我们根据生产经验开发的云原生大数据套件项目,用户可使用 TKBS 一键在 Kubernetes 上部署生产可用的大数据平台。TKBS 当前已支持 Hadoop 主要组件以及主流大数据组件的部署。
TKBS 主要特点如下:
-
兼容社区:支持原生 Kubernetes
-
一键部署:采用 Helm 应用化封装
-
云原生增强:与腾讯云 TKE、EKS、CBS、CLB、COS 和 CHDFS 等云服务深度整合;支持开源 TKEStack
-
存算分离:支持存储计算分离架构
-
自动扩缩容:支持自动 HPA 和 CA,节省运营成本
-
离在线混部:支持与在线业务混合部署,提升资源利用率
9.2 TKE / EKS / TKEStack
我们使用腾讯云 TKE / EKS 或开源 TKEStack 帮助我们生产和管理 Kubernetes 集群。
-
TKE:腾讯云容器服务(Tencent Kubernetes Engine ,TKE)基于原生 kubernetes 提供以容器为核心的、高度可扩展的高性能容器管理服务
-
EKS:腾讯云弹性容器服务(Elastic Kubernetes Service,EKS)是腾讯云容器服务推出的无须用户购买节点即可部署工作负载的服务模式
-
TKEStack:腾讯云 TKE 团队开源的一款集强壮性和易用性于一身的企业级容器编排引擎,以极简的向导式界面提供了容器应用的全生命周期管理能力,帮助用户在私有云环境中敏捷、高效地构建和发布应用程序
10 结尾
云原生的到来不止为大数据部署和交付带来了变革,它更是帮助大数据连接了一个生态。利用云原生生态,真正做到了为大数据赋予云的能力,使得大数据可以“生长在云端”。另外,云原生在大数据领域的应用,也同样帮助云原生拓展了能力边界,丰富了落地场景,为未来“Everything native on Cloud”打下夯实基础。
TKBS 已上线腾讯云 TKE 应用市场,下个版本会加入对实时分析完整方案与 TKDF 的支持。我们希望凭借基于 TKBS 与 TKDF 的大数据实时分析方案,可以帮助用户缩短大数据交付过程,简化大数据系统部署与运维复杂度,让用户聚焦在挖掘数据价值本身。另一方面,借助云原生架构,我们希望能帮助用户的大数据业务与云发生联系,为用户带来更多的可能性,帮助用户创造更多的价值。
生于云上,为云而生!
以上是关于基于云原生的大数据实时分析方案实践的主要内容,如果未能解决你的问题,请参考以下文章
前沿分享|数澜科技联合创始人&副总裁 江敏:基于云原生数据仓库AnalyticDB PostgreSQL的最佳实践