自动驾驶的Pipline -- 如何打造自动驾驶的数据闭环?(下)
Posted 架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶的Pipline -- 如何打造自动驾驶的数据闭环?(下)相关的知识,希望对你有一定的参考价值。
转载自:
https://zhuanlan.zhihu.com/p/390147950
三篇文章全集:
6 相关的机器学习技术
最后,谈一下数据闭环所采用的机器学习技术,其实就是选择什么训练数据和如何迭代更新模型的策略。主要有以下几点:
- 主动学习
- OOD检测和Corner Case检测
- 数据增强/对抗学习
- 迁移学习/域自适应
- 自动机器学习(AutoML )/元学习(学习如何学习)
- 半监督学习
- 自监督学习
- 少样本/ 零样本学习
- 持续学习/开放世界
下面分别讨论:
6.1)主动学习
主动学习(active learning)的目标是找到有效的方法从无标记数据池中选择要标记的数据,最大限度地提高准确性。主动学习通常是一个迭代过程,在每次迭代中学习模型,使用一些启发式方法从未标记数据池中选择一组数据进行标记。因此,有必要在每次迭代中为了大子集查询所需标签,这样即使对大小适中的子集,也会产生相关样本。
如图是一个主动学习闭环示意图:在无标注数据中查询、标注所选择数据、添加标注数据到训练集和模型训练。
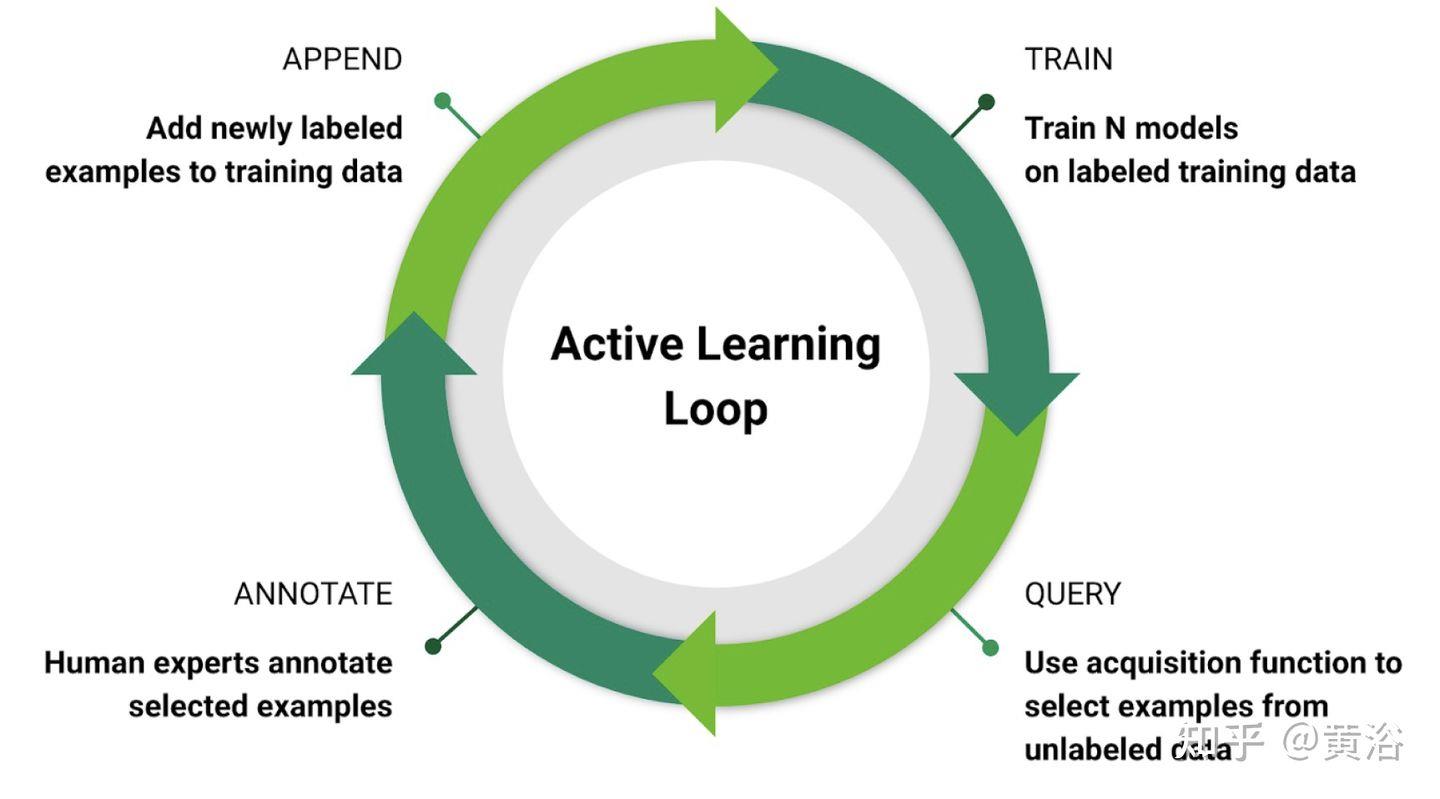
一些方法把标注和无标注数据放在一起,故此采用监督学习和半监督学习进行训练。
贝叶斯主动学习方法通常使用非参数模型(如高斯过程)来估计每个查询的预期进步或一组查询后的预期错误。
基于不确定性主动学习方法尝试使用启发式方法,比如最高熵,和决策边界的几何距离等来寻找困难例子(hard examples)。
如图是英伟达基于主动学习的挖掘数据方法:
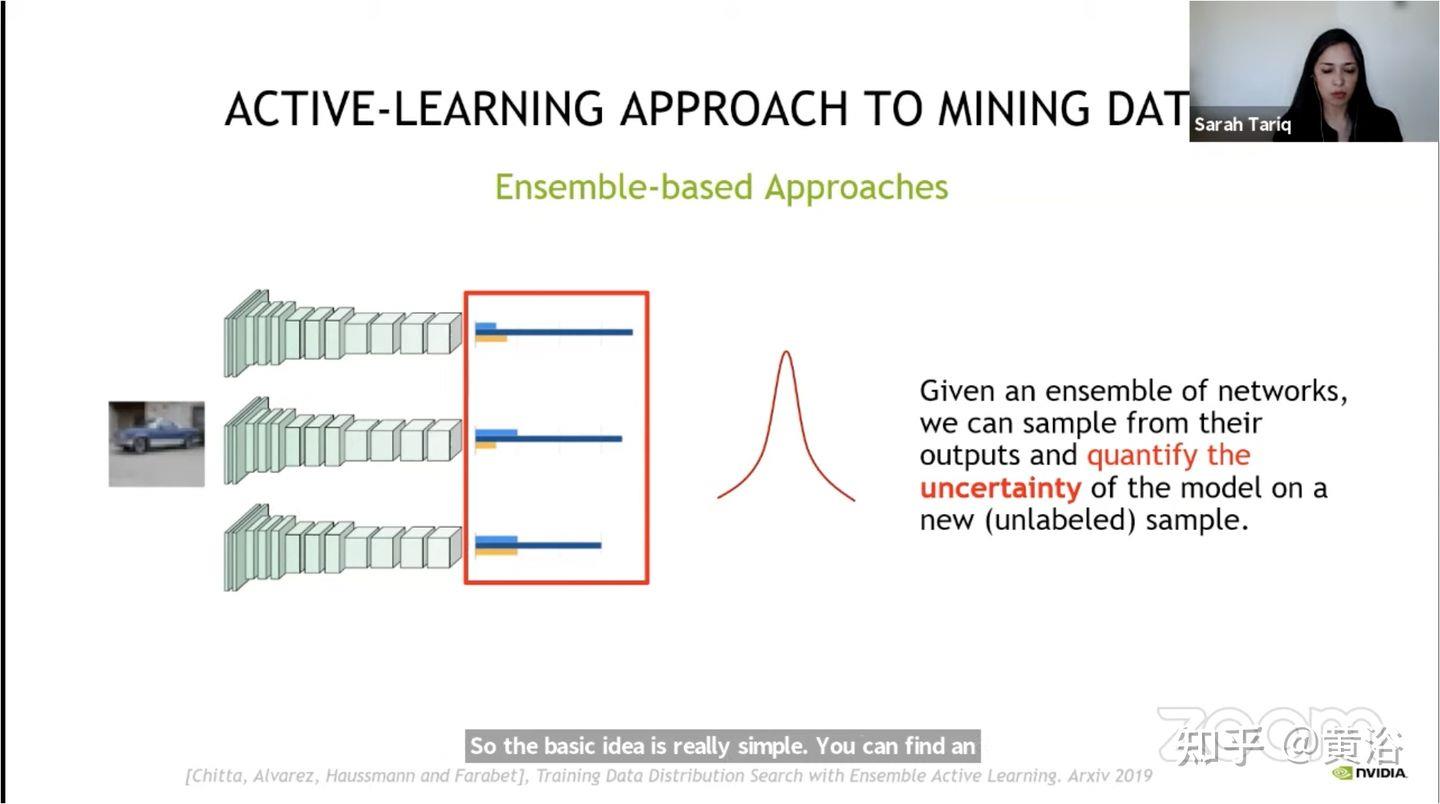
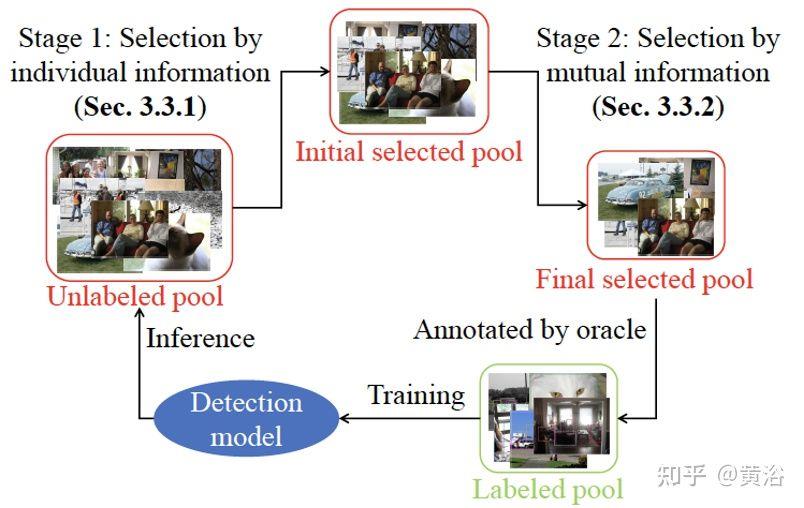
还有其他的主动学习实例方法:
“Deep Active Learning for Efficient Training of a LiDAR 3D Object Detector“

“Consistency-based Active Learning for Object Detection“
6.2)OOD检测和Corner Case检测
机器学习模型往往会在out-of-distribution(OOD) 数据上失败。 检测OOD是确定不确定性(Uncertainty)的手段,既可以安全报警,也可以发现有价值的数据样本。
不确定性有两种来源:任意(aleatoric)不确定性和认知(epistemic)不确定性。
导致预测不确定性的数据不可减(Irreducible)不确定性,是一种任意不确定性(也称为数据不确定性)。任意不确定性有两种类型:同方差(homo-scedastic)和异方差(hetero-scedastic)。
另一类不确定性是由于知识和数据不适当造成的认知不确定性(也称为知识/模型不确定性)。
最常用的不确定性估计方法是贝叶斯近似(Bayesian approximation)法和集成学习(ensemble learning)法。
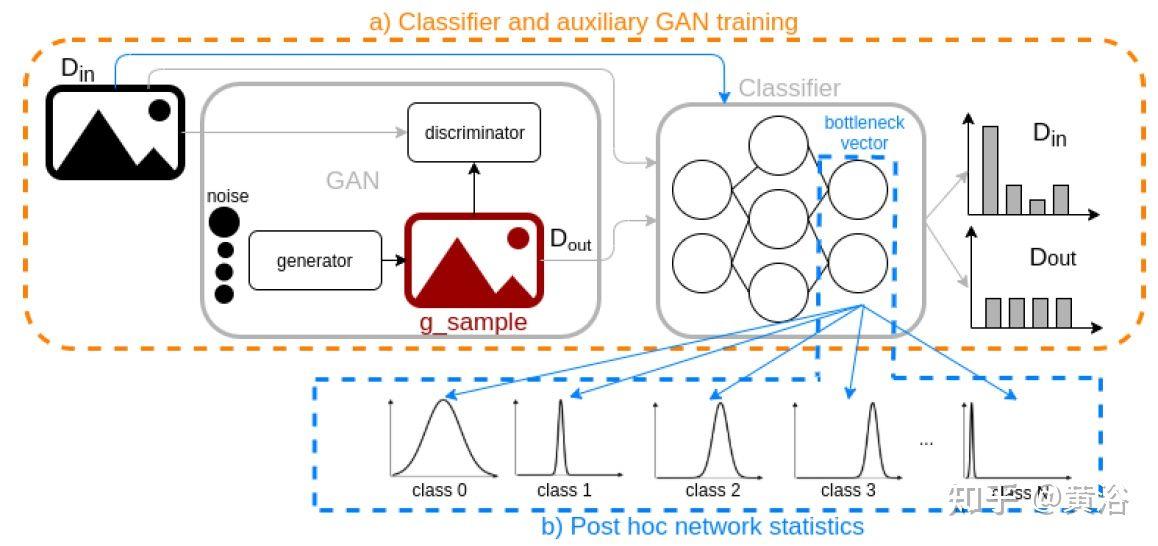
一类 OOD 识别方法基于贝叶斯神经网络推理,包括基于 dropout 的变分推理(variational inference)、马尔可夫链蒙特卡罗 (MCMC) 和蒙特卡罗 dropout等。
另一类OOD识别方法包括 (1) 辅助损失或NN 架构修改等训练方法,以及 (2) 事后统计(post hoc statistics)方法。
数据样本中有偏离正常的意外情况,即所谓的corner case。可靠地检测此类corner case,在开发过程中,在线和离线应用都是必要的。
在线应用可以用作安全监控和警告系统,在corner case情况发生时进行识别。离线应用将corner case检测器应用于大量收集的数据,选择合适的训练和相关测试数据。
最近的一些实例工作有:
“Towards Corner Case Detection for Autonomous Driving“

“Out-of-Distribution Detection for Automotive Perception“
“Corner Cases for Visual Perception in Automated Driving: Some Guidance on Detection Approaches“

6.3)数据增强/对抗学习
过拟合(Overfitting)是指当机器学习模型学习高方差的函数完美地对训练数据建模时出现的现象。数据增强(Data Augmentation)增强训练数据集的大小和质量,克服过拟合,从而构建更好的机器学习模型。
图像数据增强算法包括几何变换、色彩空间增强、内核过滤器、混合图像、随机擦除、特征空间增强、对抗训练(adversarial training)、生成对抗网络(generative adversarial networks,GAN)、神经风格迁移(neural style transfer)和元学习(meta-learning)。
激光雷达点云数据的增强方法还有特别的一些:全局变换(旋转、平移、尺度化)、局部变换(旋转、平移、尺度化)和3-D滤波。
对抗性训练可以成为寻找增强方向的有效方法。通过限制对抗网络(adversarial network)可用的增强和畸变变换集,通过学习得到导致错误的增强方式。这些增强对于加强机器学习模型中的弱点很有价值。
值得一提的是,CycleGAN 引入了一个额外的 Cycle-Consistency 损失函数,稳定 GAN 训练,应用于图像到图像转换(image-to-image translation)。实际上CycleGAN 学习从一个图像域转换到另一个域。
机器学习模型错误背后的一个常见原因是一种称为数据集偏差或域漂移(dataset bias / domain shift)的现象。 域适应方法试图减轻域漂移的有害作用。对抗训练方法引入到域适应,比如对抗鉴别域适应方法(Adversarial Discriminative Domain Adaptation,ADDA)。
最近出现的一些新实例方法:
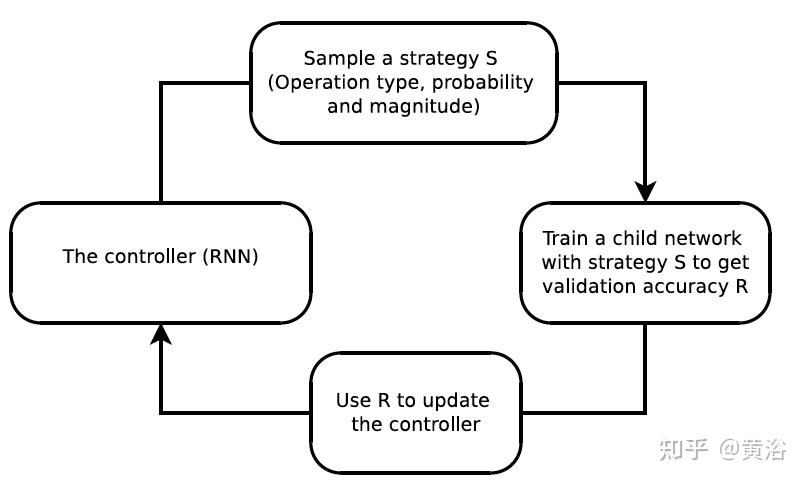
“AutoAugment: Learning Augmentation Strategies from Data“
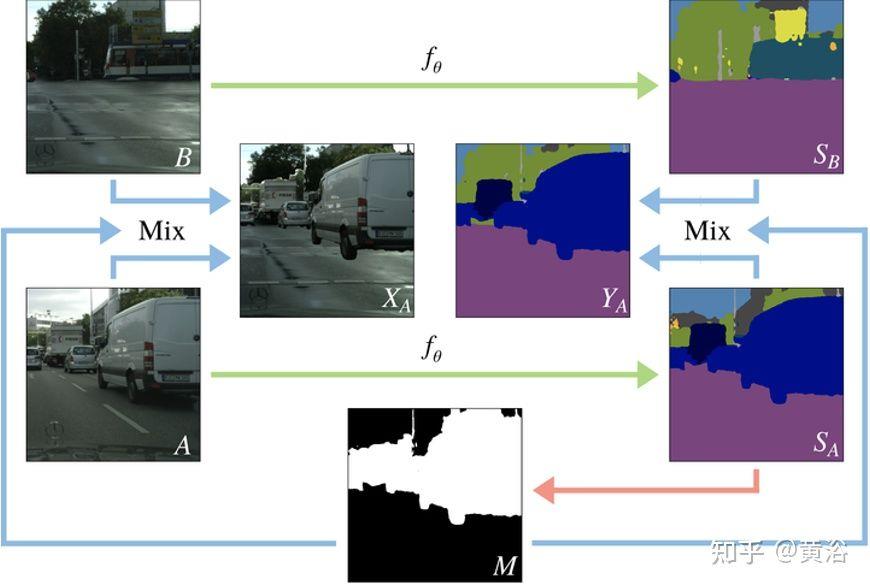
“Classmix: Segmentation-based Data Augmentation For Semi-supervised Learning“
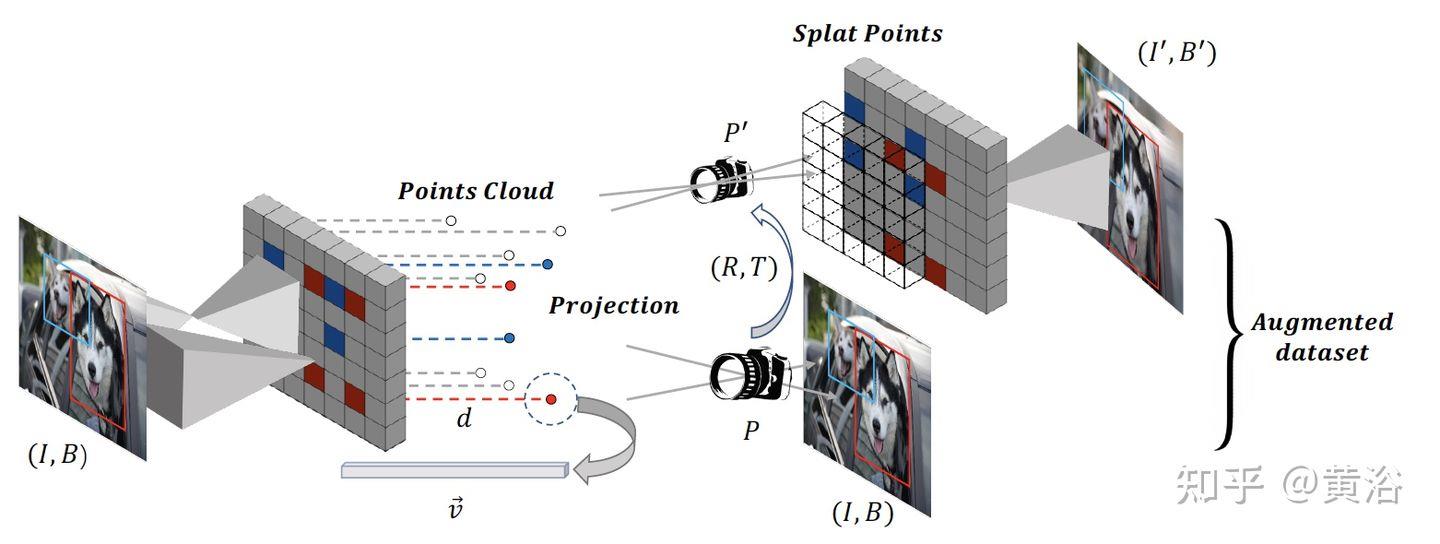
“Data Augmentation for Object Detection via Differentiable Neural Rendering“
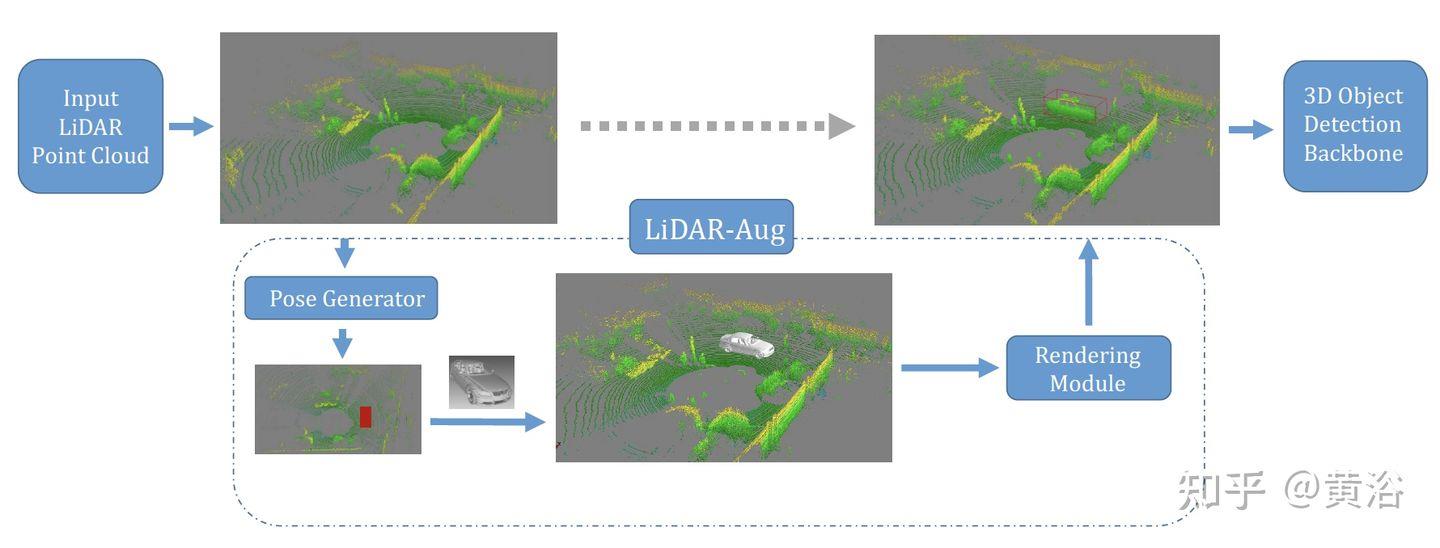
“LiDAR-Aug: A General Rendering-based Augmentation Framework for 3D Object Detection“
“Adaptive Object Detection with Dual Multi-Label Prediction“
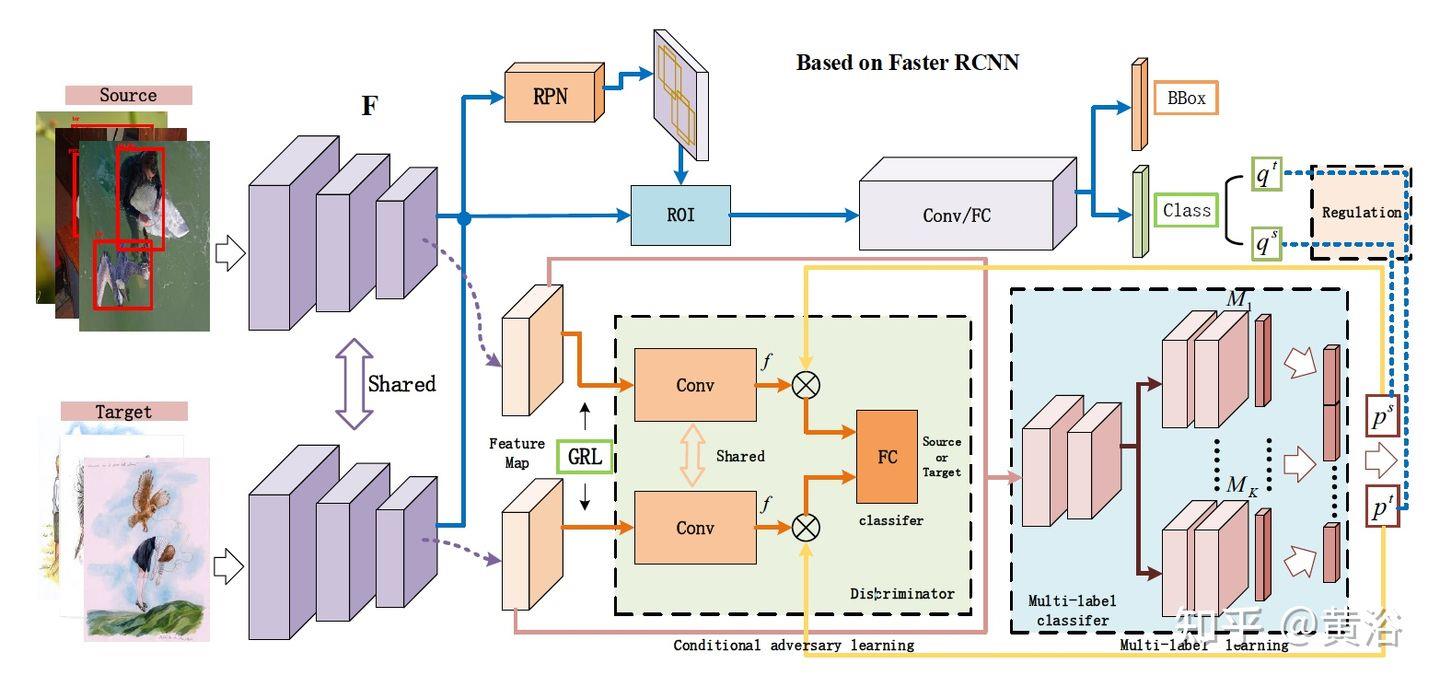
“Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation“
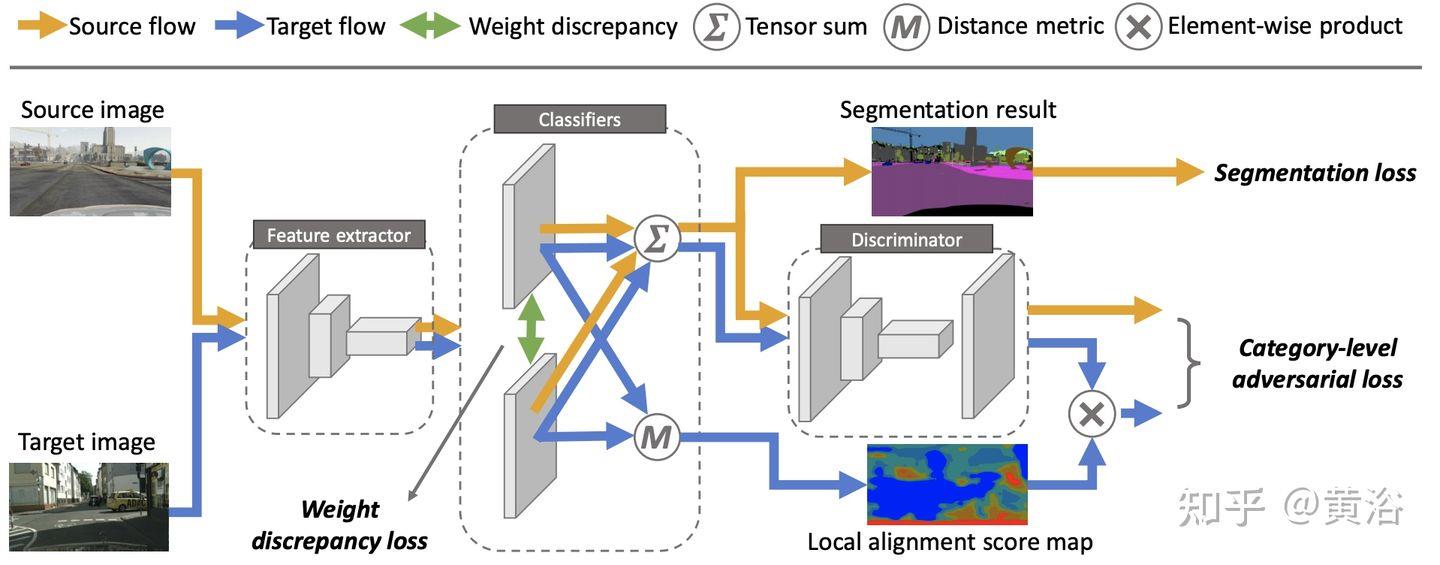
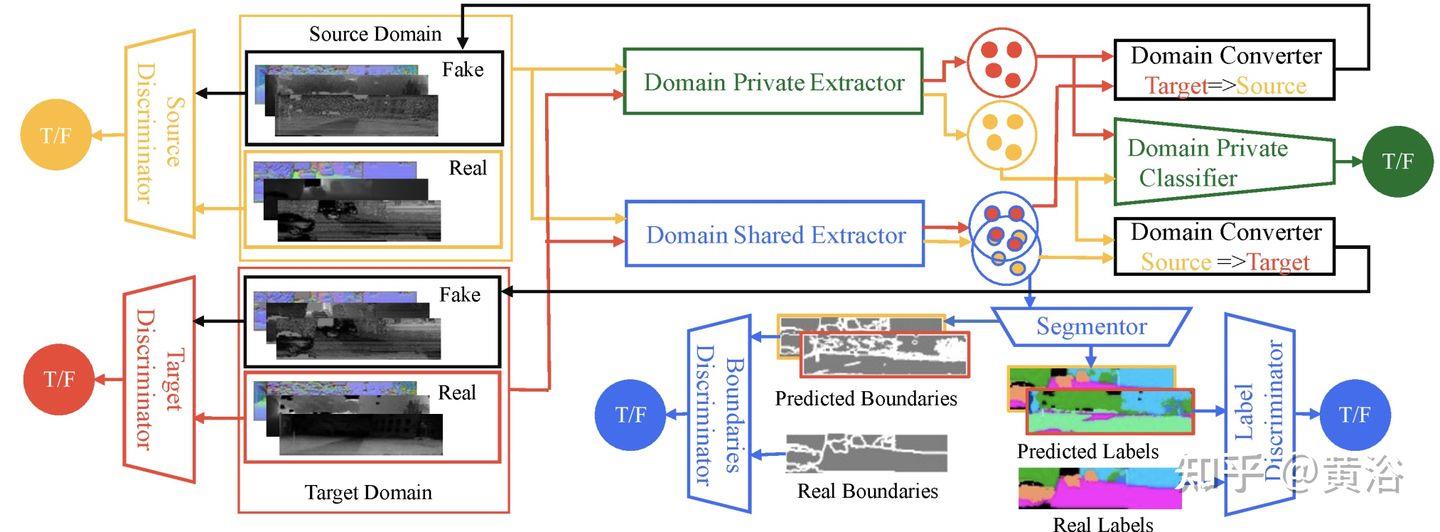
6.4)迁移学习/域适应
迁移学习(transfer learning,TL)不需要训练数据和测试数据是独立同分布(independent and identically distributed,i.i.d),目标域的模型不需要从头开始训练,可以减少目标域训练数据和时间的需求。
深度学习的迁移技术基本分为两种类型,即非对抗性的(传统)和对抗性的。
域适应 (domain adaptation,DA) 是TL的一种特殊情况,利用一个或多个相关源域(source domains)的标记数据在目标域(target domain)执行新任务。
DA方法分为两类:基于实例的和基于特征的。
最近出现的一些新实例方法:
“Multi-Target Domain Adaptation via Unsupervised Domain Classification for Weather Invariant Object Detection“

“Uncertainty-Aware Consistency Regularization for Cross-Domain Semantic Segmentation“
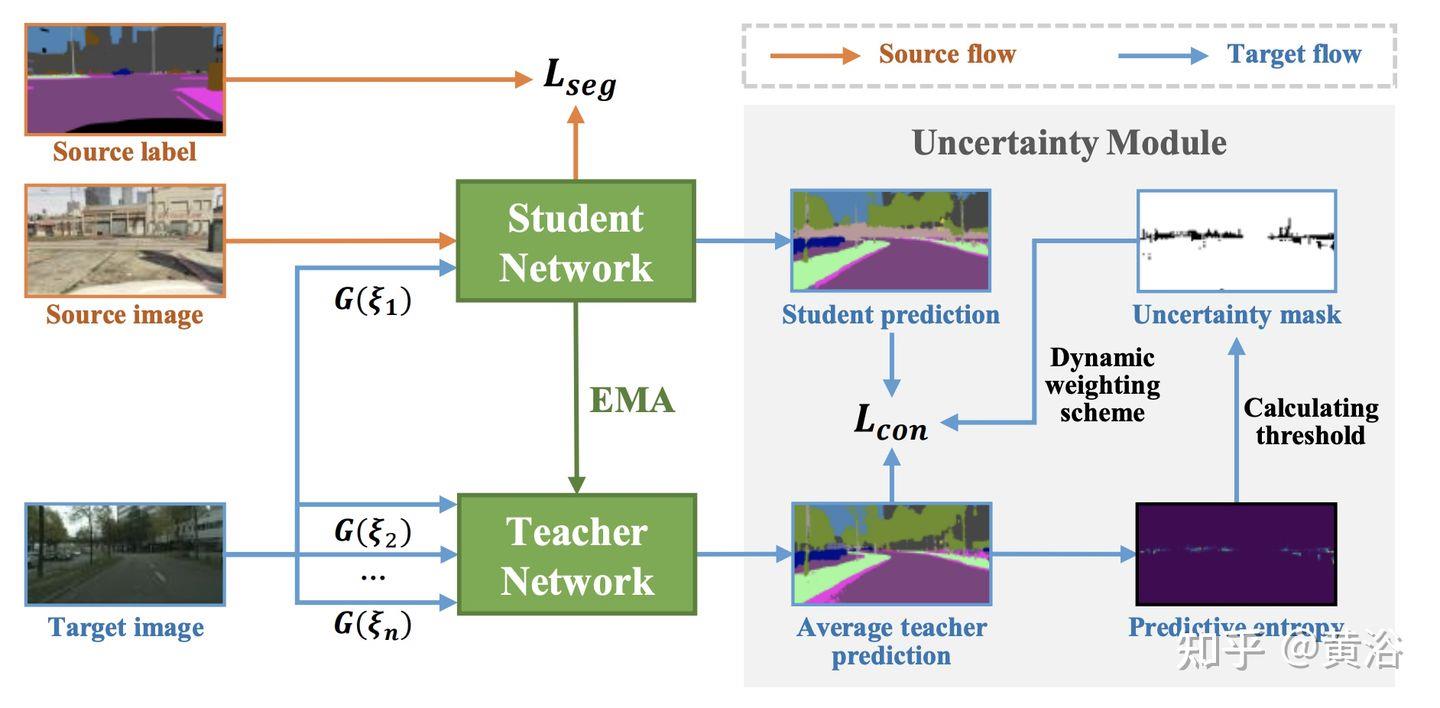
“SF-UDA3D: Source-Free Unsupervised Domain Adaptation for LiDAR-Based 3D Object Detection“
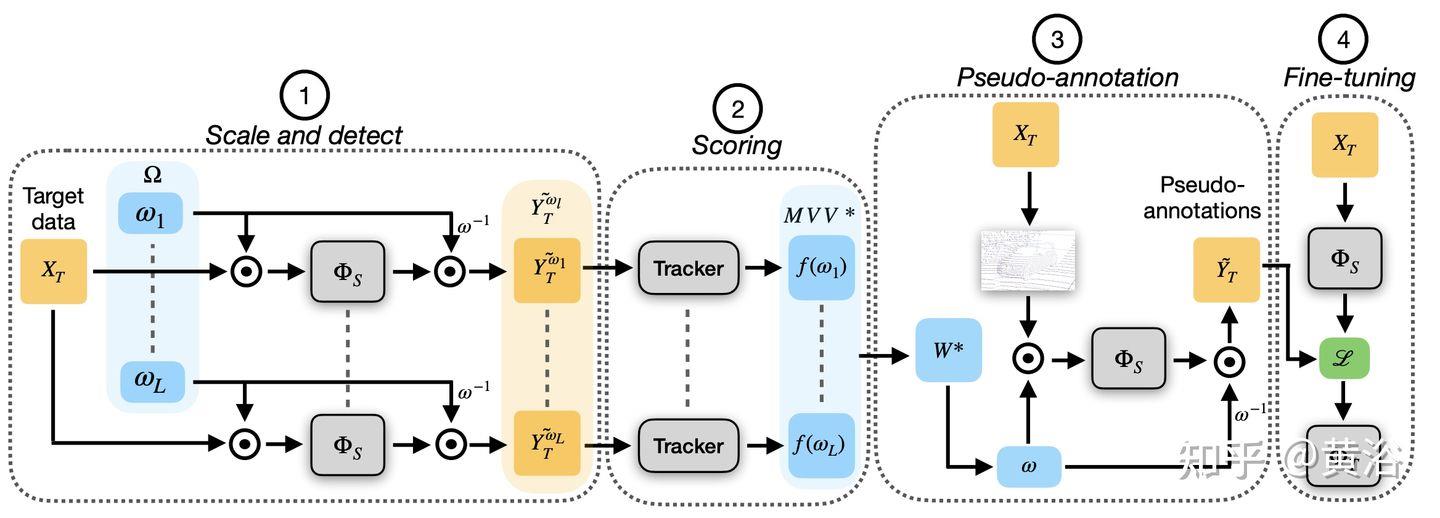
“LiDARNet: A Boundary-Aware Domain Adaptation Model for Point Cloud Semantic Segmentation“
6.5)自动机器学习(AutoML)/元学习(学习如何学习)
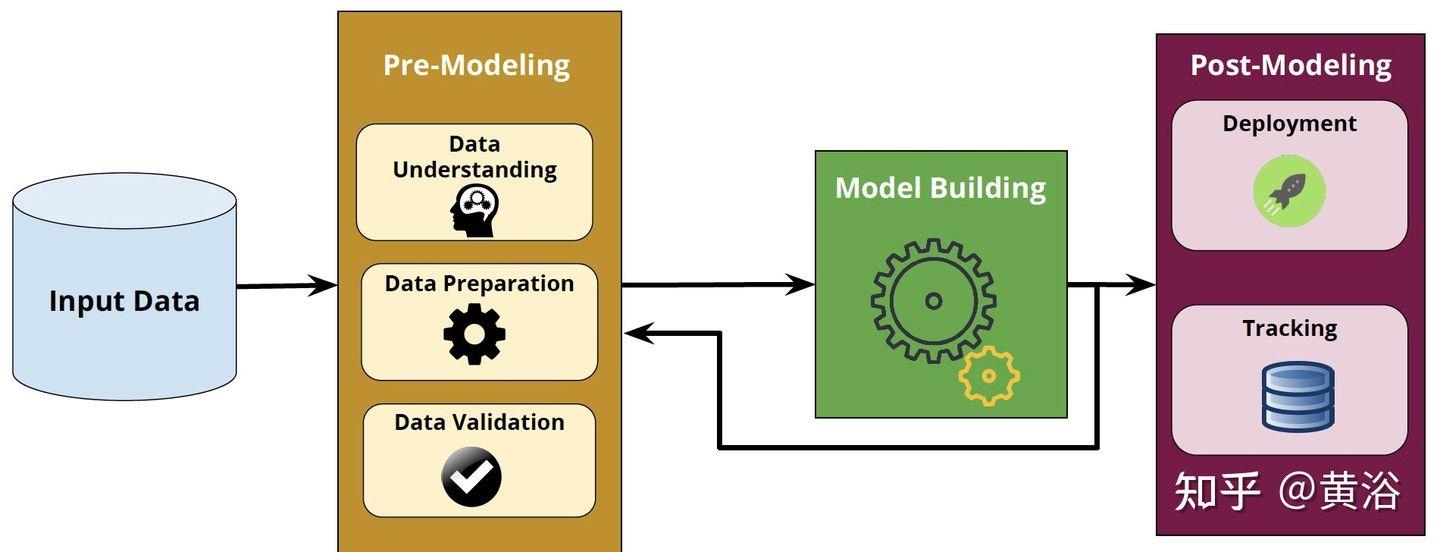
一个机器学习建模的工程还有几个方面需要人工干预和可解释性,即机器学习落地流水线的两个主要组件:预-建模和后-建模(如图)。
预-建模影响算法选择和超参数优化过程的结果。 预-建模步骤包括多个步骤,包括数据理解、数据准备和数据验证。
后-建模模块涵盖了其他重要方面,包括机器学习模型的管理和部署。
为了降低这些繁重的开发成本,出现了自动化整个机器学习流水线的新概念,即开发自动机器学习(automated machine learning,AutoML) 方法。AutoML 旨在减少对数据科学家的需求,并使领域专家能够自动构建机器学习应用程序,而无需太多统计和机器学习知识。
值得特别一提的是谷歌方法“神经架构搜索”(Neural Architecture Search,NAS),其目标是通过在预定义搜索空间中选择和组合不同的基本组件来生成稳健且性能良好的神经网络架构。
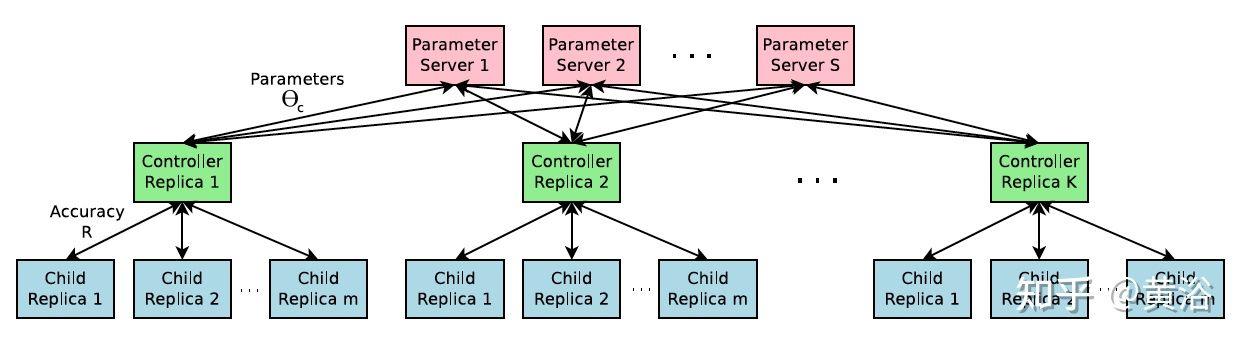
NAS的总结从两个角度了解:模型结构类型和采用超参数优化(hyperparameter optimization,HPO)的模型结构设计。最广泛使用的 HPO 方法利用强化学习 (RL)、基于进化的算法 (EA)、梯度下降 (GD) 和贝叶斯优化 (BO)方法。
如图是AutoML在机器学习平台的应用实例:
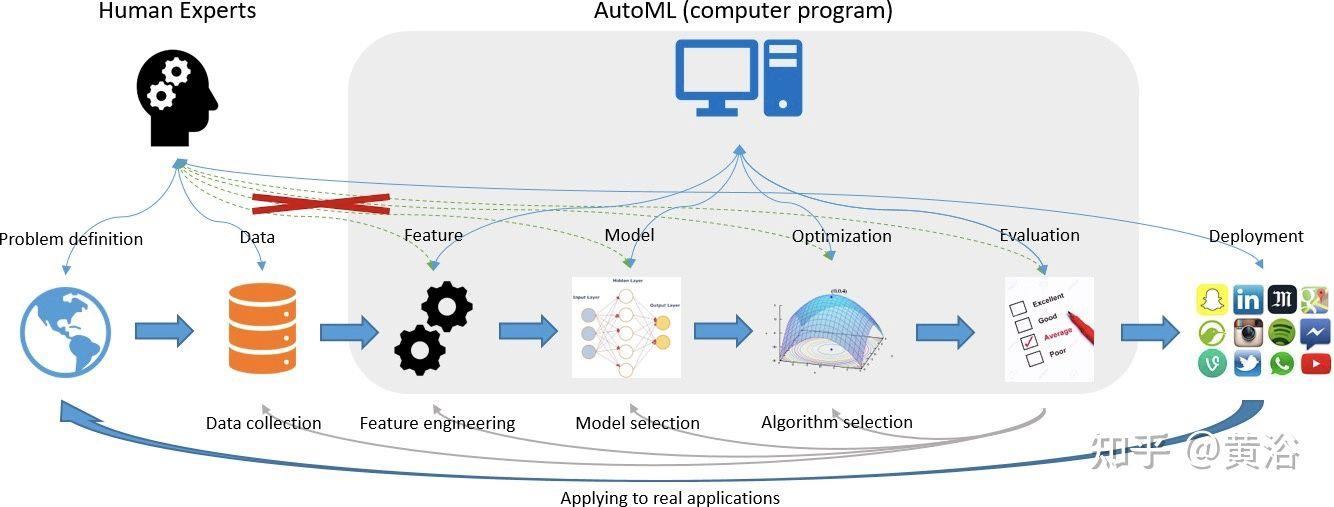
注:在谷歌云、微软云Azure和亚马逊云AWS都支持AutoML。
深度学习(DL)专注于样本内预测,元学习(meta learning)关注样本外预测的模型适应问题。元学习作为附加在原始 DL 模型的泛化部分。
元学习寻求模型适应与训练任务大不相同的未见过的任务(unseen tasks)。元强化学习 (meta-RL) 考虑代理与不断变化的环境之间的交互过程。元模仿学习 (Meta-IL) 将过去类似的经验应用于只有稀疏奖励的新任务。
元学习与 AutoML 密切相关,二者有相同的研究目标,即学习工具和学习问题。现有的元学习技术根据在 AutoML 的应用可分为三类:
1)用于配置评估(对于评估者);
2)用于配置生成(用于优化器);
3) 用于动态配置的自适应。
元学习促进配置生成,例如,针对特定学习问题的配置、生成或选择配置策略或细化搜索空间。元学习检测概念漂移(concept drift)并动态调整学习工具实现自动化机器学习(AutoML)过程。
6.6)半监督学习
半监督学习(semi-supervised learning)是利用未标记数据生成具有可训练模型参数的预测函数,目标是比用标记数据获得的预测函数更准确。由于混合监督和无监督方法,半监督学习的损失函数可以具有多种形状。 一种常见的方法是添加一个监督学习的损失项和一个无监督学习的损失项。
已经有一些经典的半监督学习方法:
- “Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks”
- “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results“
- “Self-training with Noisy Student improves ImageNet classification“
最近出现一些新实例方法:
“Unbiased Teacher for Semi-Supervised Object Detection“
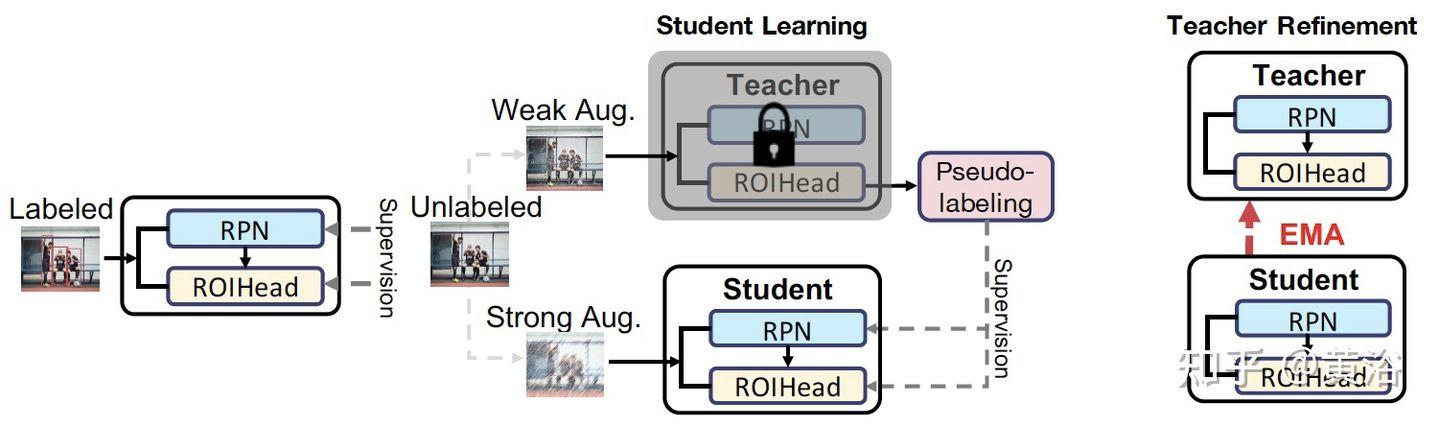
“Pseudoseg: Designing Pseudo Labels For Semantic Segmentation“
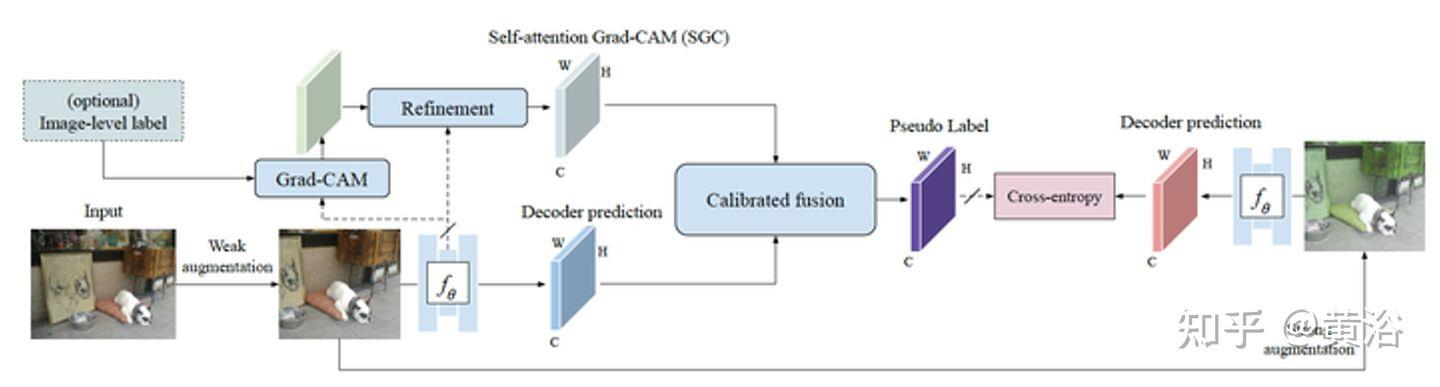
“Semantic Segmentation of 3D LiDAR Data in Dynamic Scene Using Semi-supervised Learning“
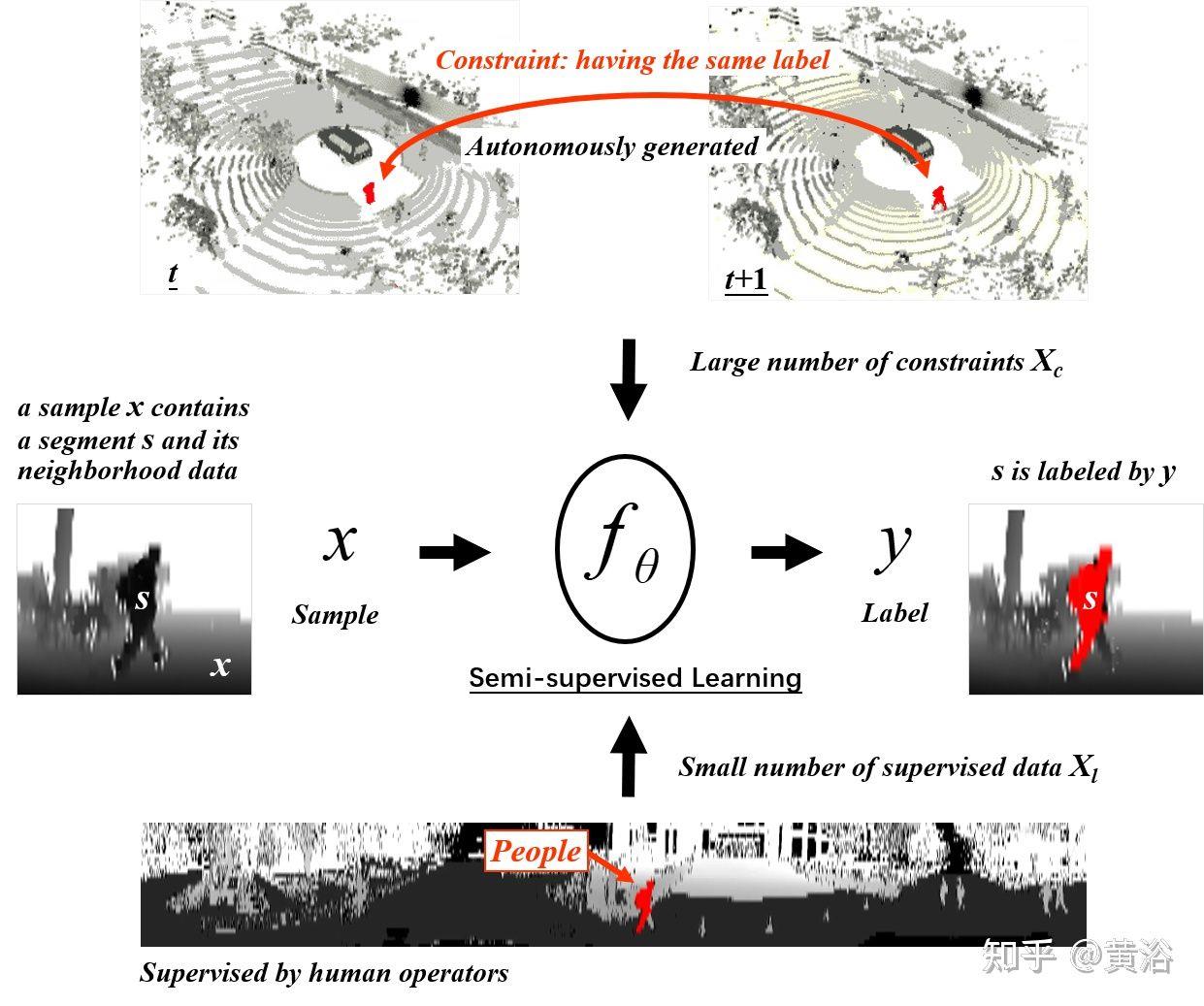
“ST3D: Self-training for Unsupervised Domain Adaptation on 3D Object Detection“

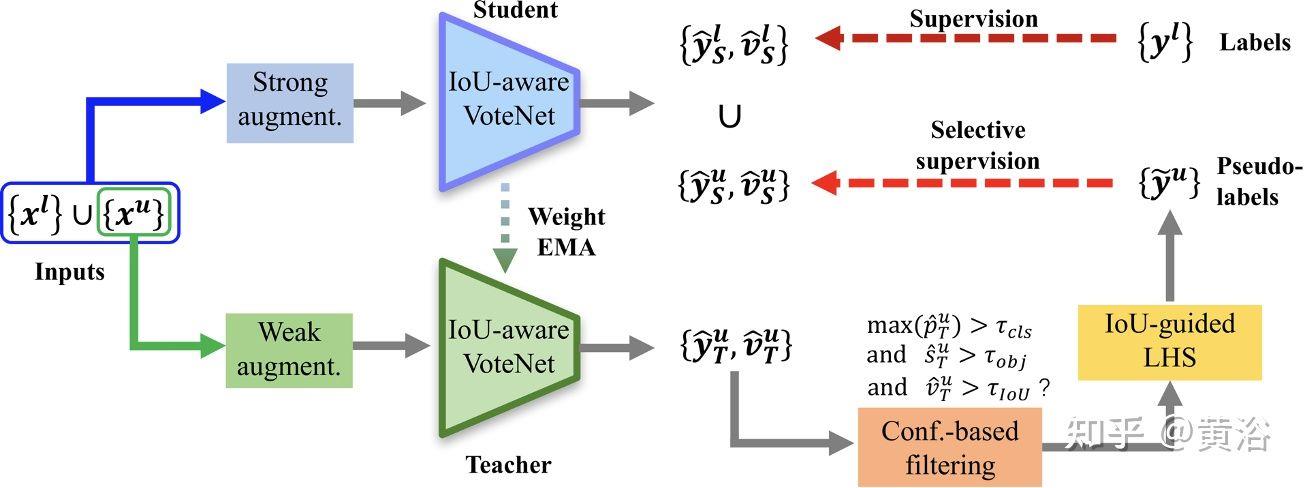
“3DIoUMatch: Leveraging IoU Prediction for Semi-Supervised 3D Object Detection“
7. 7)自监督学习
自监督学习(self supervised learning)算是无监督学习的一个分支,其目的是恢复,而不是发现。自监督学习基本分为:生成(generative)类, 对比(contrastive)类和生成-对比(generative-contrastive)混合类,即对抗(adversarial)类。
自监督使用借口任务(pretext task)来学习未标记数据的表示。借口任务是无监督的,但学习的表示通常不能直接给下游任务(downstream task),必须进行微调。因此,自监督学习可以被解释为一种无监督、半监督或自定义策略。下游任务的性能用于评估学习特征的质量。
一些著名的自监督学习方法有:
- “SimCLR-A Simple framework for contrastive learning of visual representations“
- “Momentum Contrast for Unsupervised Visual Representation Learning“
- “Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning“
- “Deep Clustering for Unsupervised Learning of Visual Features“
- “Unsupervised Learning of Visual Features by Contrasting Cluster Assignments“
注意最近的一些新方法:
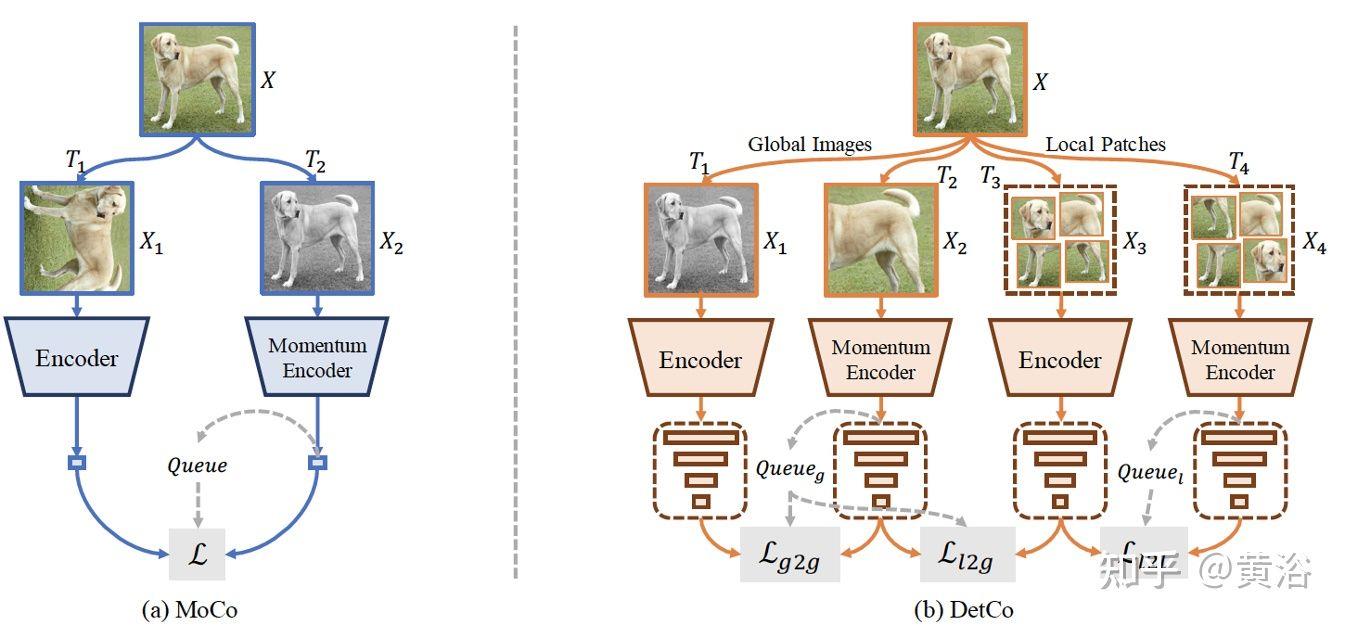
“DetCo: Unsupervised Contrastive Learning for Object Detection“
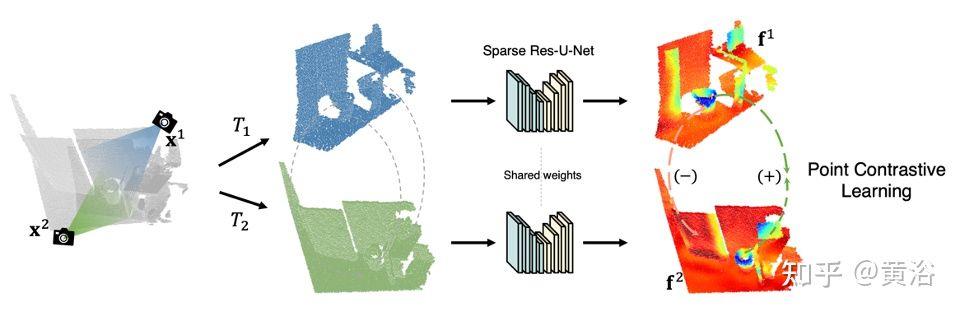
“PointContrast: Unsupervised Pre-training for 3D Point Cloud Understanding“
“MonoRUn: Monocular 3D Object Detection by Reconstruction and Uncertainty Propagation“

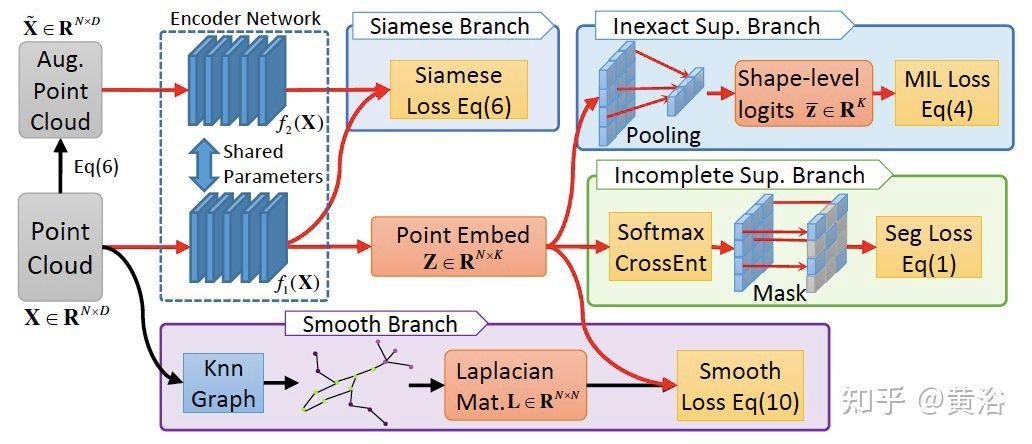
“Weakly Supervised Semantic Point Cloud Segmentation: Towards 10x Fewer Labels“
6.8)少样本/零样本学习
零样本学习(Zero-shot learning,ZSL)旨在识别在训练期间可能未见过实例的目标。虽然大多数ZSL方法都使用判别性损失(discriminative losses)进行学习,但少数生成模型(generative models)将每个类别表示为概率分布。
对于未见类(unseen classes),ZSL除了无法访问其视觉或辅助信息的inductive设置之外,transductive方法无需访问标签信息,直接用**已见类(seen classes)**和未见类一起的视觉或语义信息。
ZSL属于迁移学习(TL),源特征空间为训练实例,目标特征空间为测试实例,二者特征空间一样。 但对于已见类和未见类,标签空间是不同的。
为了从有限的监督信息中学习,一个新的机器学习方向称为少样本学习 (Few-Shot Learning ,FSL)。基于如何使用先验知识,FSL可分为三个类:1)用数据先验知识来增强监督经验,2)通过模型先验知识约束假设空间,和3)用算法先验知识改变假设空间中最佳参数的搜索方式。
FSL 可以是监督学习、半监督学习和强化学习(RL),取决于除了有限的监督信息之外还有哪些数据可用。许多 FSL 方法是元学习(meta learning)方法,以此作为先验知识。
最近的一些实例方法:
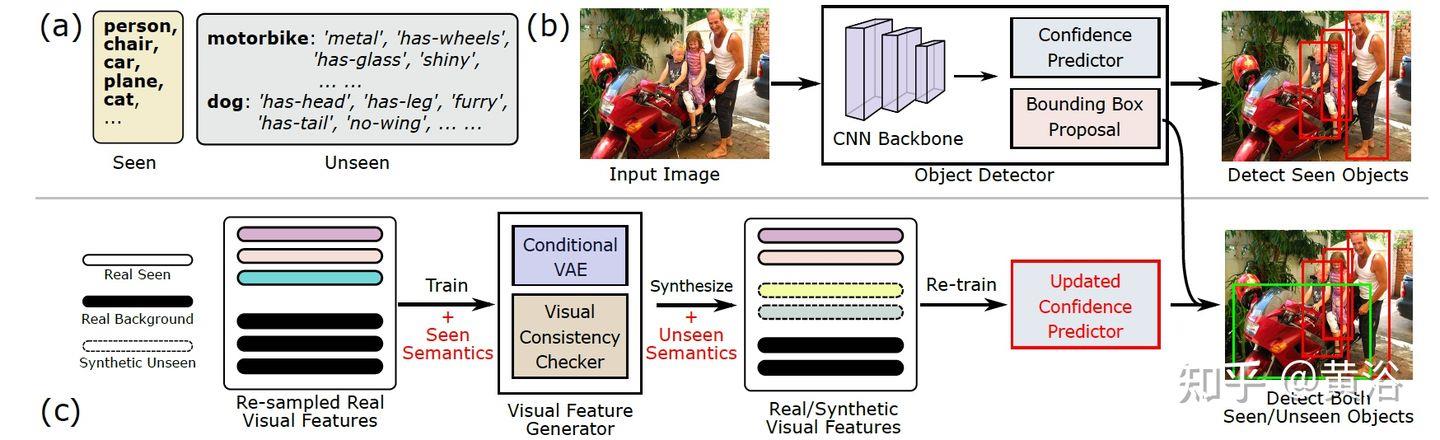
“Don’t Even Look Once: Synthesizing Features for Zero-Shot Detection“
“Zero-Shot Semantic Segmentation“
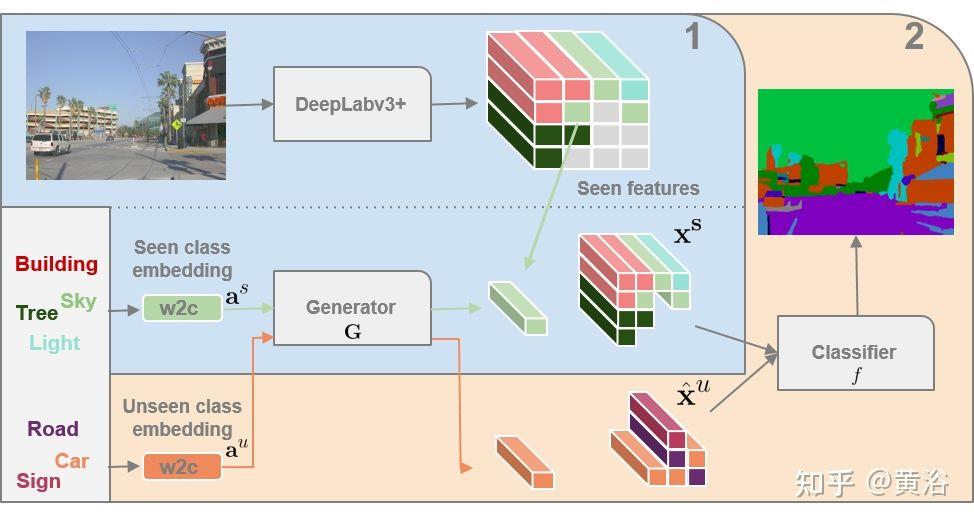
“Zero-Shot Learning on 3D Point Cloud Objects and Beyond“

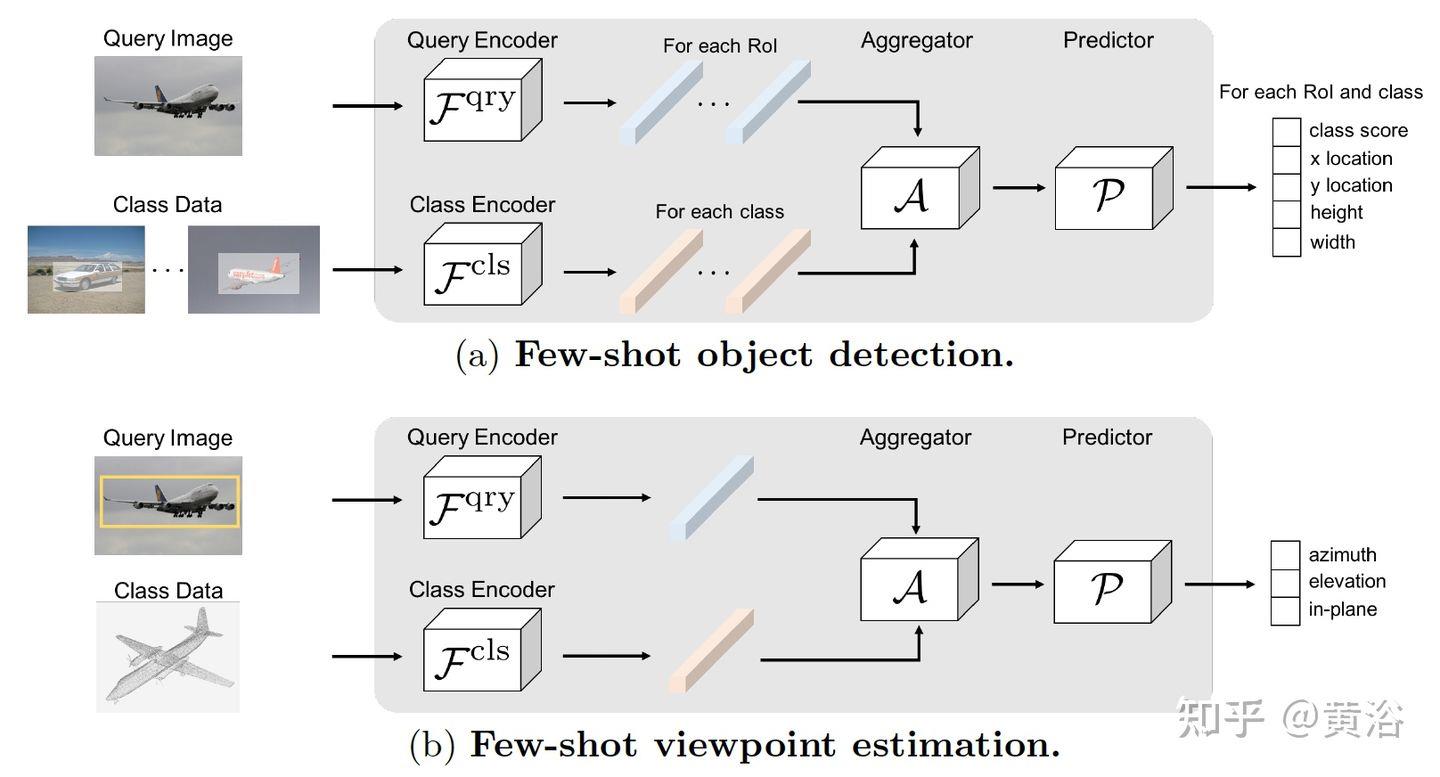
“Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild“
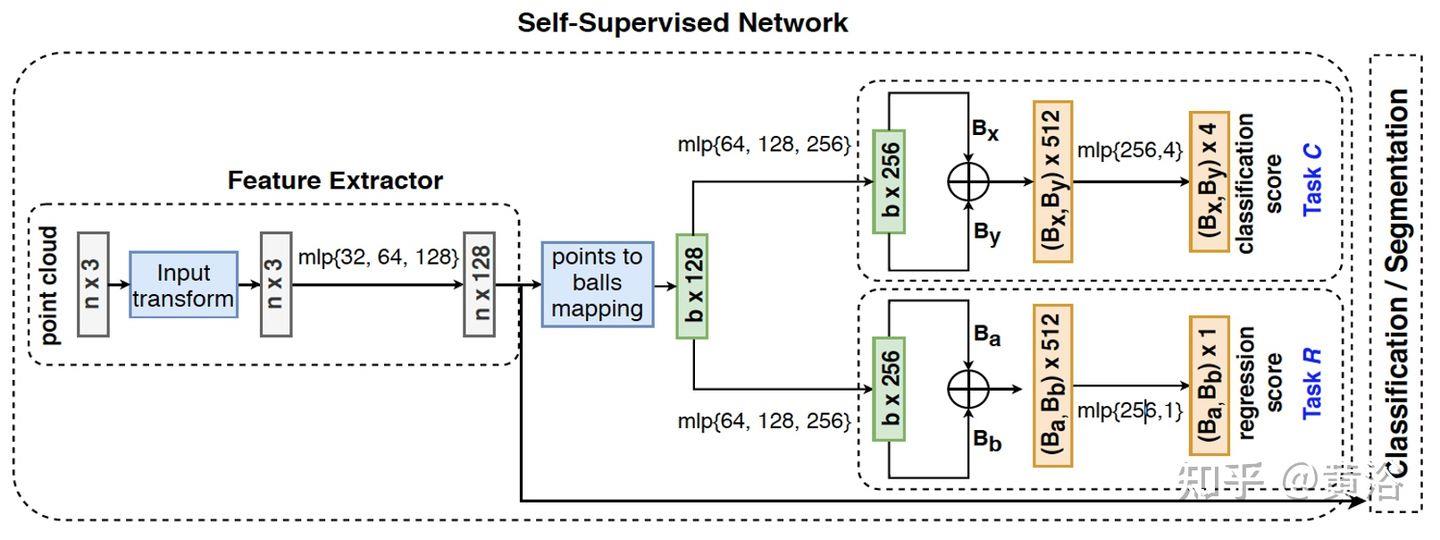
“Self-Supervised Few-Shot Learning on Point Clouds“
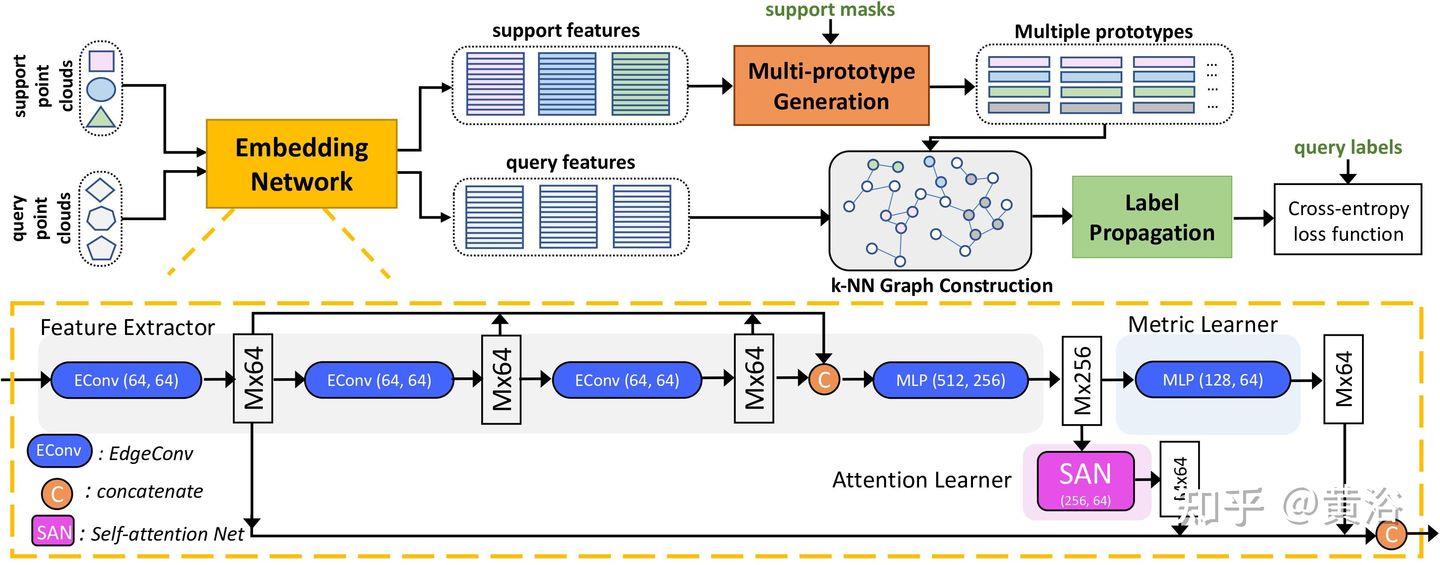
“Few-shot 3D Point Cloud Semantic Segmentation“
6.9)持续学习/开放世界
持续学习( continual learning)可以不断积累不同任务得到的知识,而无需从头开始重新训练。其困难是如何克服灾难遗忘(catastrophic forgetting)。
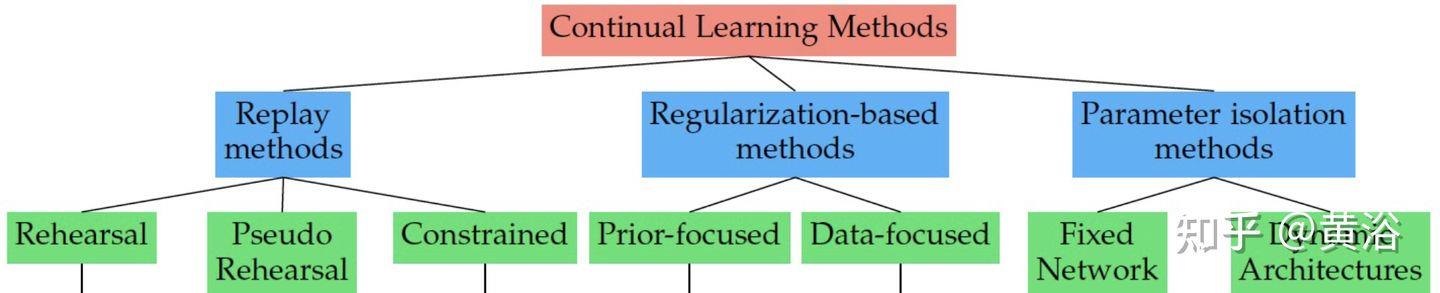
如图是持续学习的方法分类:经验重放(ER)、正则化和参数孤立三个方向。
开放集识别(Open set recognition,OSR),是在训练时存在不完整的世界知识,在测试中可以将未知类提交给算法,要求分类器不仅要准确地对所见类进行分类,还要有效处理未见类。开放世界学习(Open world learning)可以看作是持续学习的一个子任务。
以下给出最近的一些实例方法:
“Lifelong Object Detection“
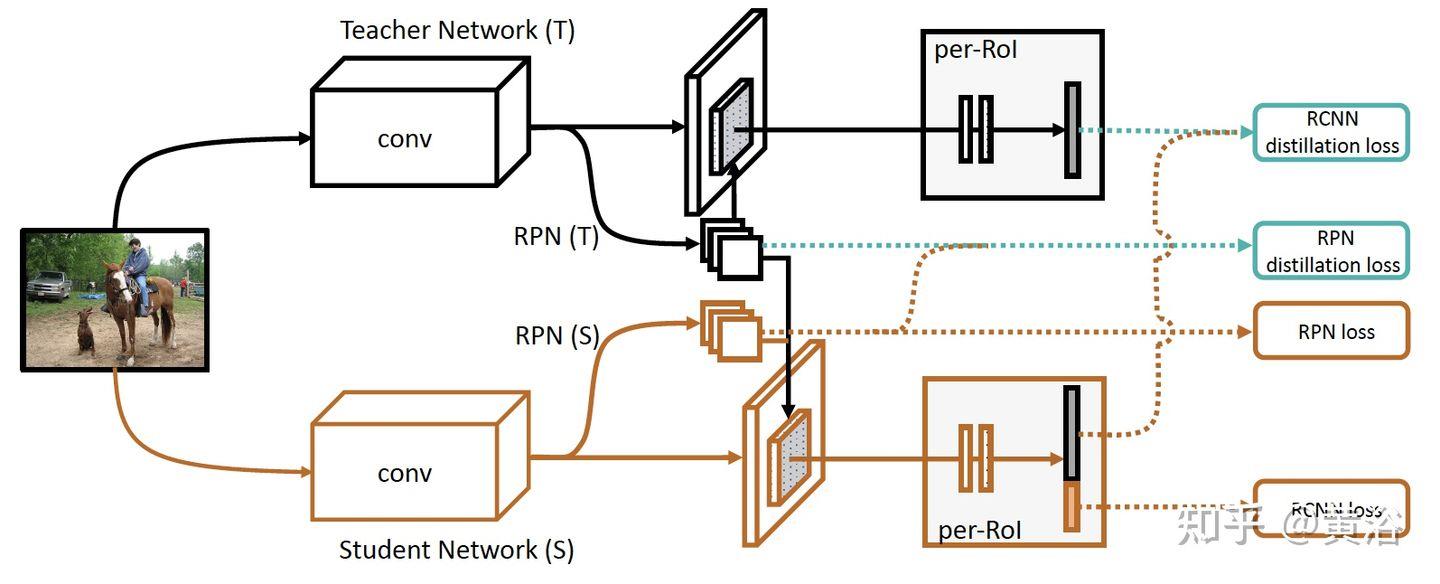
“Incremental Few-Shot Object Detection“
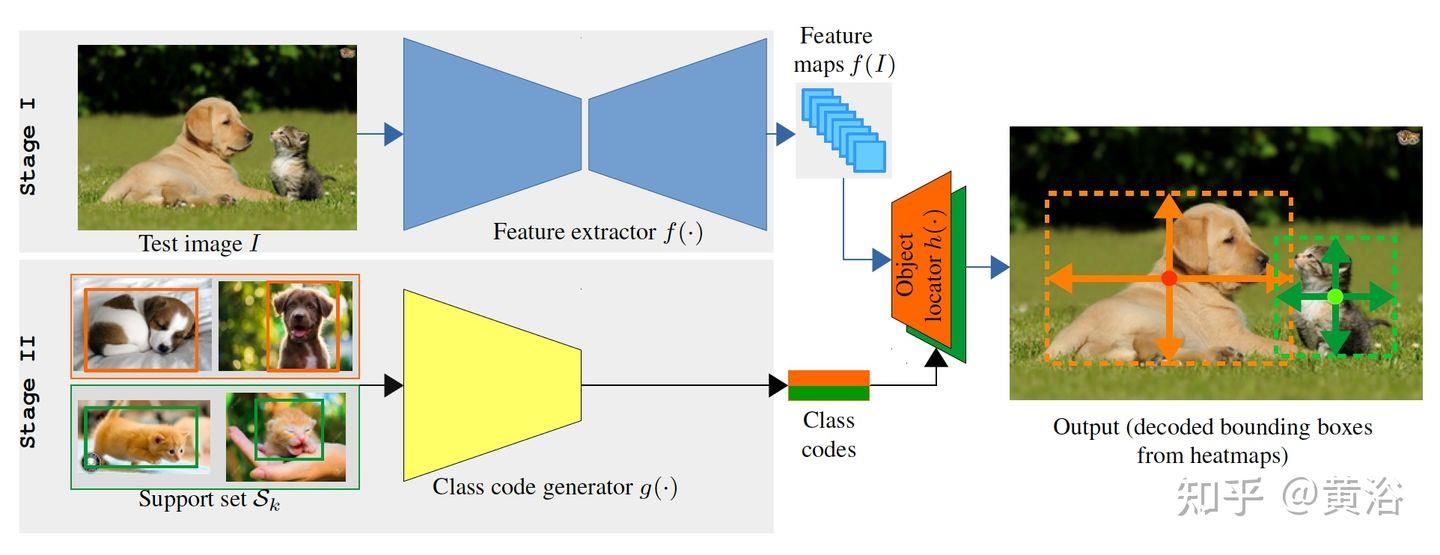
“Towards Open World Object Detection“
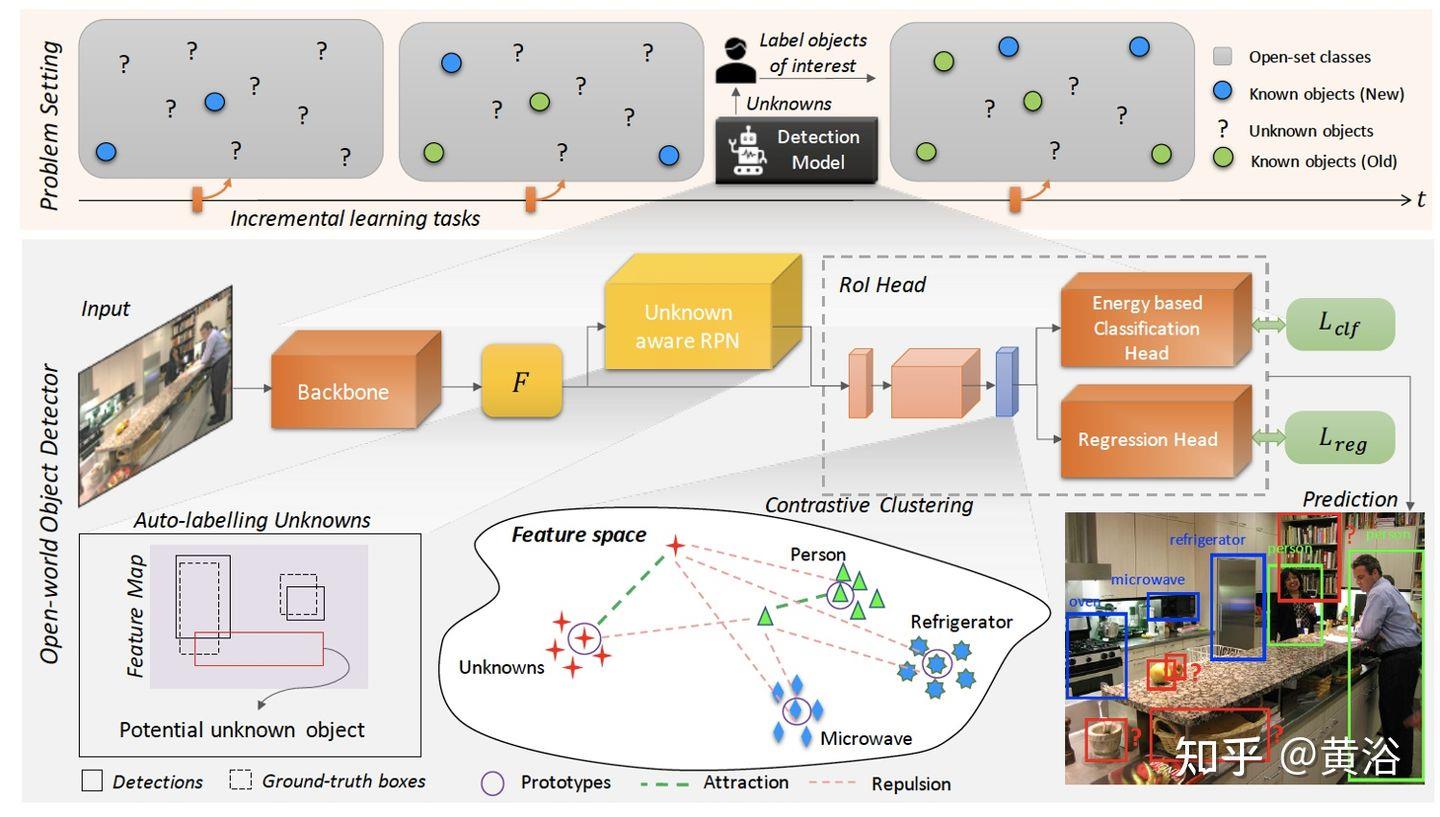
“OpenGAN: Open-Set Recognition via Open Data Generation”

“Large-Scale Long-Tailed Recognition in an Open World“
数据闭环的关键是数据,同时采用数据驱动的训练模型是基础。决定了整个自动驾驶迭代升级系统的走向是:
- 数据的模式(摄像头/激光雷达/雷达,无/导航/高清地图,姿态定位精度,时间同步标记);
- 数据驱动模型(模块/端到端);
- 模型的架构(AutoML);
- 模型训练的策略(数据选择)。
以上是关于自动驾驶的Pipline -- 如何打造自动驾驶的数据闭环?(下)的主要内容,如果未能解决你的问题,请参考以下文章