数据采集第二次实验
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据采集第二次实验相关的知识,希望对你有一定的参考价值。
目录
实验 1
1.1 题目
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
1.2 思路
1.2.1 发送请求
- 导入包
import urllib.request
- 构造请求头并发送请求
headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req)
1.2.2 解析网页
- 导入库(使用BeautifulSoup进行页面解析)
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
注意: 这里还有一个编码的转换,防止windows的gbk编码,而导致的中文乱码!
- 解析response内容
dammit=UnicodeDammit(data,["utf-8","gbk"]) # 编码
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml") # 解析网页
1.2.3 获取结点
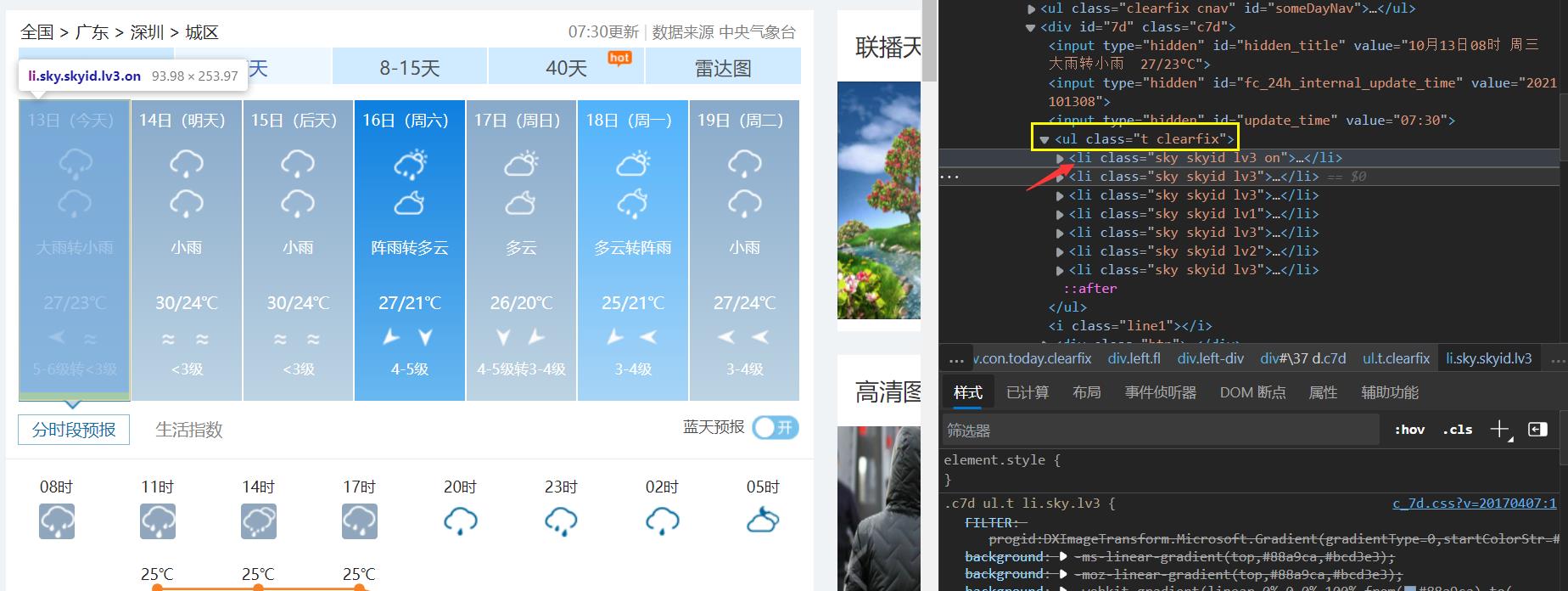
- 采用css选择进行节点的获取
举个例子,其他类比
lis=soup.select("ul[class='t clearfix'] li")
获取到这里的所有li就是
ul的属性class = t clearfix的所有的li
1.2.4 数据保存
-
保存到数据库中(保存到mysql数据库中)
-
导入库pymysql
import pymysql
- 数据库初始化连接
HOSTNAME = '127.0.0.1'
PORT = '3306'
DATABASE = 'spider_ex' # 数据库名
USERNAME = 'root'
PASSWORD = 'root'
# 打开数据库连接
conn = pymysql.connect(host=HOSTNAME, user=USERNAME,password=PASSWORD,database=DATABASE,charset='utf8')
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = conn.cursor()
- 插入数据
def InsertData(count,date,weather,temp):
a = temp.split(" ")
global conn
global cursor
sql = "INSERT INTO ex2_1(序号, 地区, 日期,天气信息,温度) VALUES (%s, %s, %s, %s, %s)"
number = count
area = "深圳"
try:
conn.commit()
cursor.execute(sql,[number,area,date,weather,temp])
print("插入成功")
except Exception as err:
print("插入失败",err)
- 使用原生sql语句进行插入保存,并没有使用orm。
实验 2
2.1 题目
要求:用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。
2.2 思路
- 观察页面的js包请求
可以先把多余的请求删去
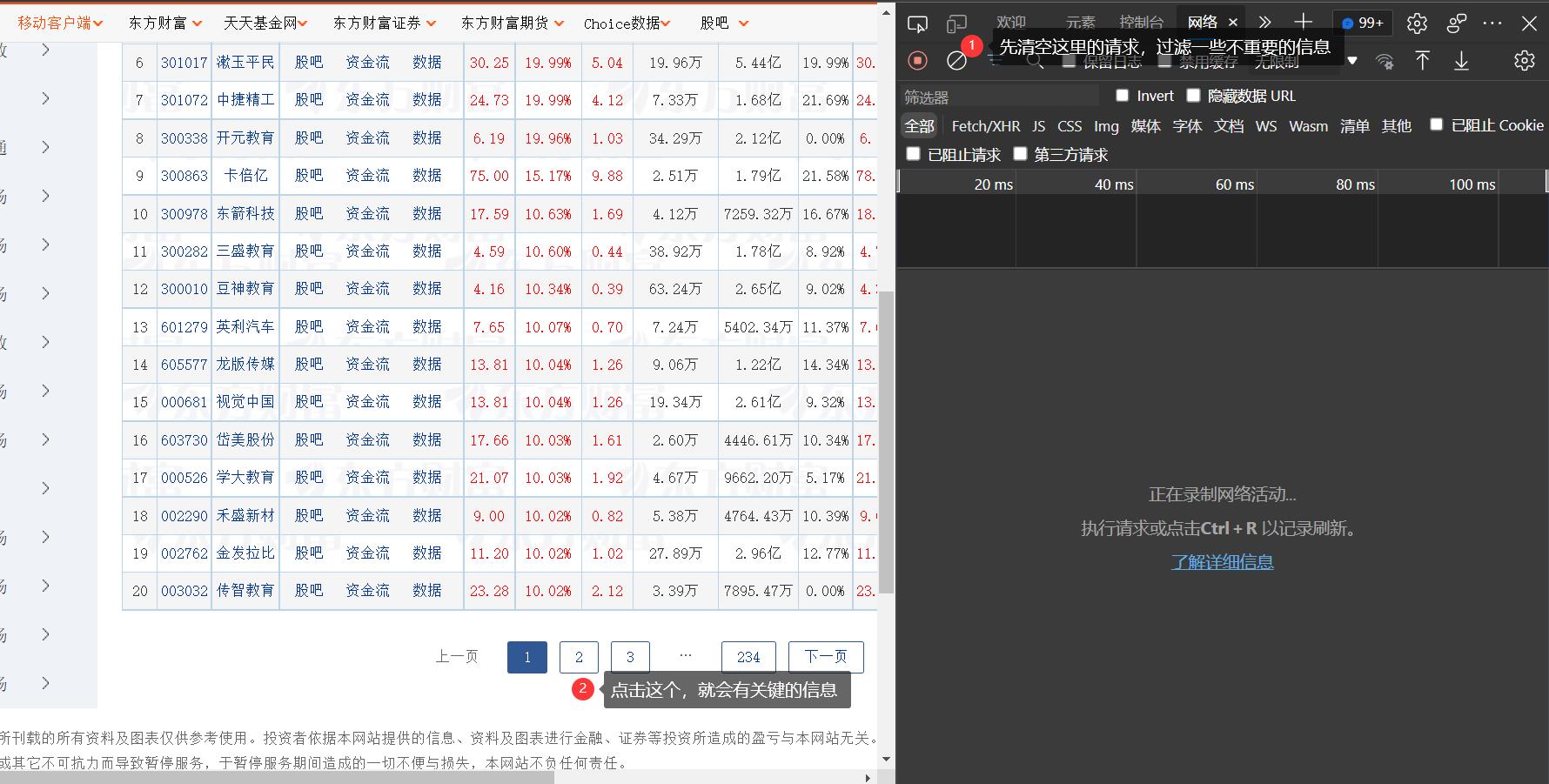
然后点击新的页面,就会出现这个关键的请求信息。
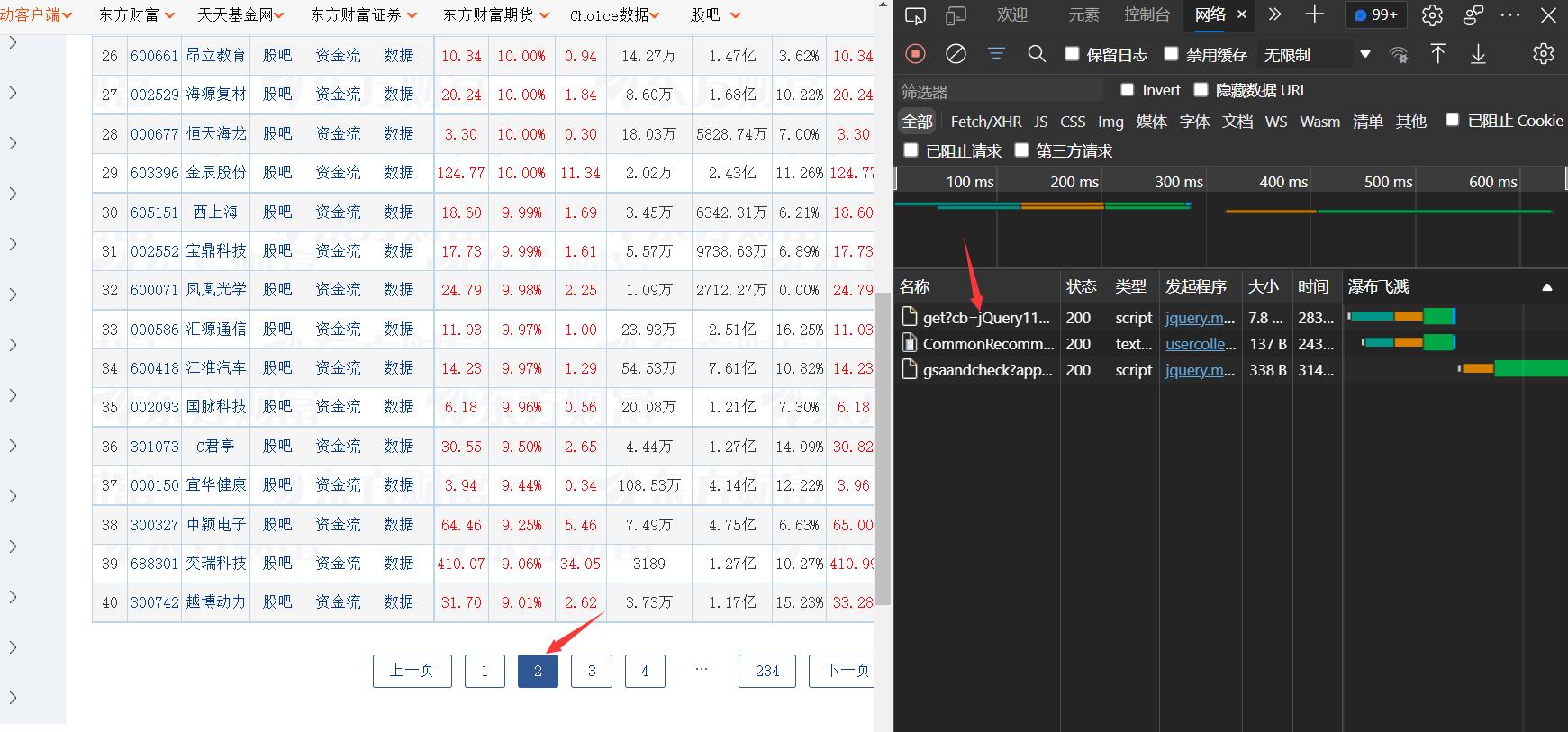
查看页数和页码(比较第一第二页的参数的区别)
- 第一页
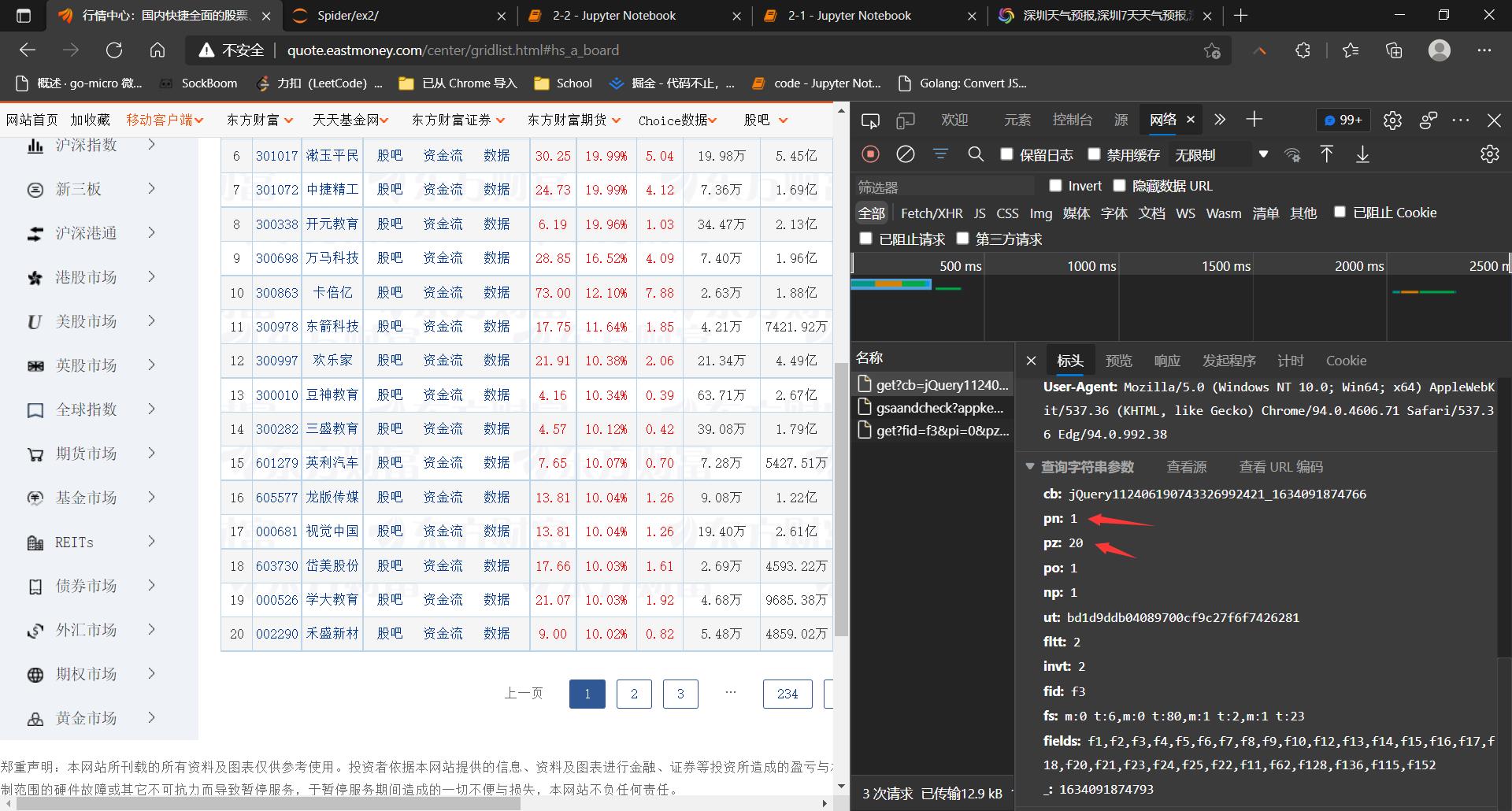
- 第二页

可以看到这里的参数pn会随着页数的增加而增加
所以可以知晓这个pn就是页面的页码。
2.2.1 发送请求
- 编写请求头,以及参数。
import requests,json
headers = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38',
'Accept': '*/*',
'Referer': 'http://quote.eastmoney.com/',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
params = (
('cb', 'jQuery1124049118572600550814_1634085098344'),
('pn', '2'), # 第几页
('pz', '20'), # 一页多少个
('po', '1'),
('np', '1'),
('ut', 'bd1d9ddb04089700cf9c27f6f7426281'),
('fltt', '2'),
('invt', '2'),
('fid', 'f3'),
('fs', 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23'),
('fields', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152'),
('_', '1634085098352'),
)
resp = requests.get('http://28.push2.eastmoney.com/api/qt/clist/get', headers=headers, params=params, verify=False)
# 发送请求
2.2.2 解析网页
- 由于返回的数据不是标准的
json格式,所以要进行去头去尾的操作。
建议把返回的格式复制到一些在线json的网站进行验证,这样才能保证json格式的正确。
res = resp.content[len("jQuery1124049118572600550814_1634085098344("):len(resp.content)-2]
res = str(res,'utf-8')
resp_json = json.loads(res)
2.2.3 获取结点
- json格式的处理方式非常简单,找到
key之后,直接遍历即可。不需要复杂的操作。
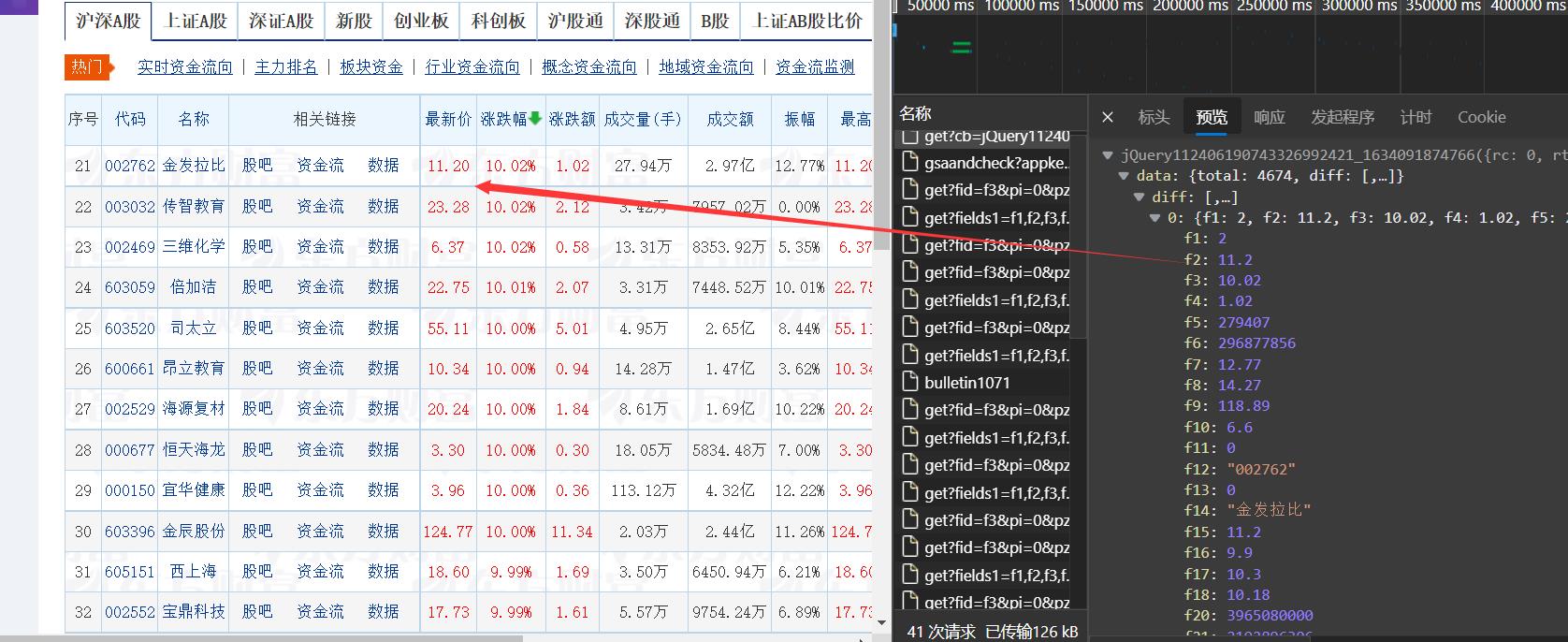
for k in resp_json['data']['diff']:
data["number"]=count,
data["f12"]=k['f12'],
data["f14"]=k['f14'],
data["f2"]=k['f2'],
data["f3"]=k['f3'],
data["f4"]=k['f4'],
data["f5"]=k['f5'],
data["f6"]=k['f6'],
data["f7"]=k['f7'],
data["f15"]=k['f15'],
data["f16"]=k['f16'],
data["f17"]=k['f17'],
data["f18"]=k['f18'],
注意: 一定要仔细看到每个参数对应的值,不然容易出错,或遗漏
2.2.4 数据保存
**注意:**这里要进行一个数据的处理!
因为这个我们抓取到的数据是和显示的是不一样的,要进行一个处理。比如百分号和单位。
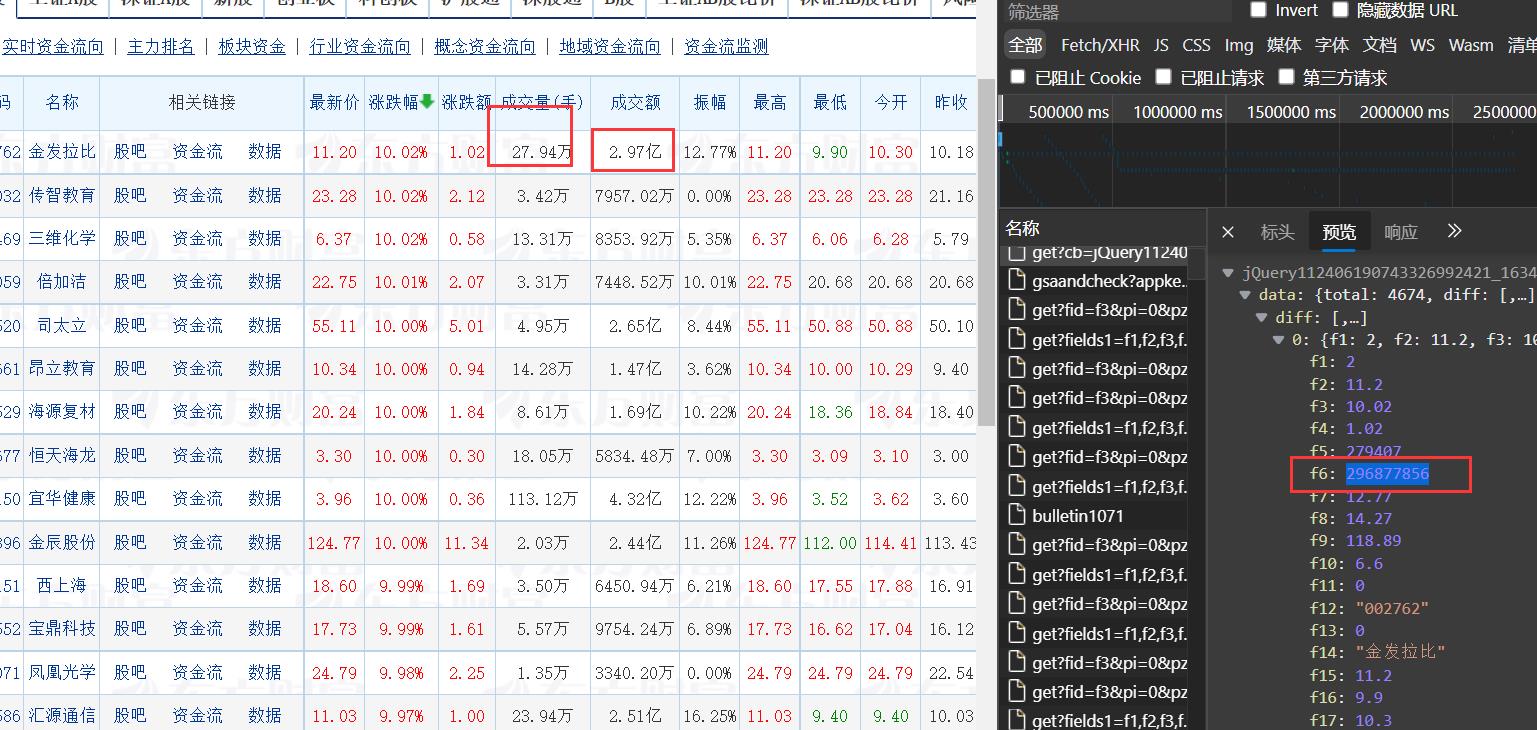
处理方法:
- 百分号可以转成字符串直接相加
- 如果是数字的话就直接像这样判断就好了
def formatDate(a):
if a > 100000000:
a = round(a/100000000,2)
a = str(a) + '亿'
elif a > 10000:
a = round(a/10000, 2)
a = str(a) + '万'
return a
同 1.2.4
- 贴结果
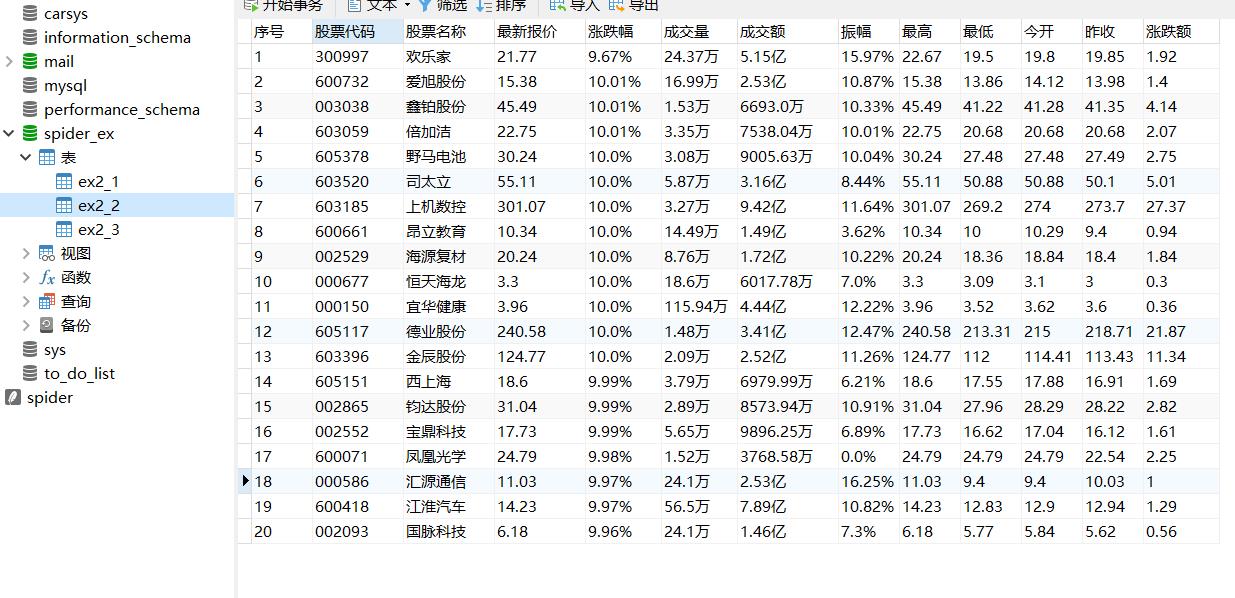
实验 3
3.1 题目
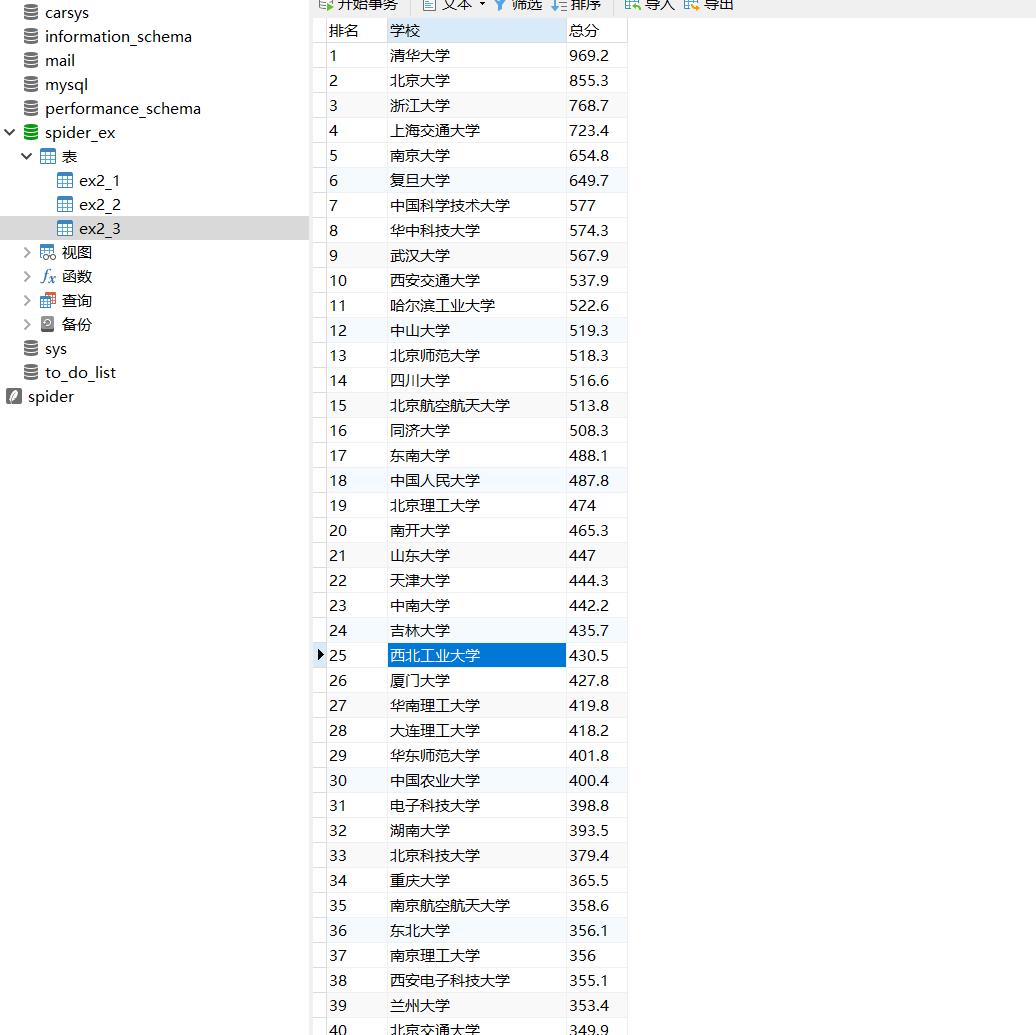
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所
有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
3.2 思路
3.2.1 发送请求
- 引入库并且编写请求头
请求头是为了把爬虫包装成浏览器的正常访问。
import request
import re
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
}
- 发送请求
resp = requests.get('https://www.shanghairanking.cn/_nuxt/static/1632381606/rankings/bcur/2021/payload.js', headers=headers)
3.2.2 解析网页
- 分析可以知道我们的节点信息在这个里面
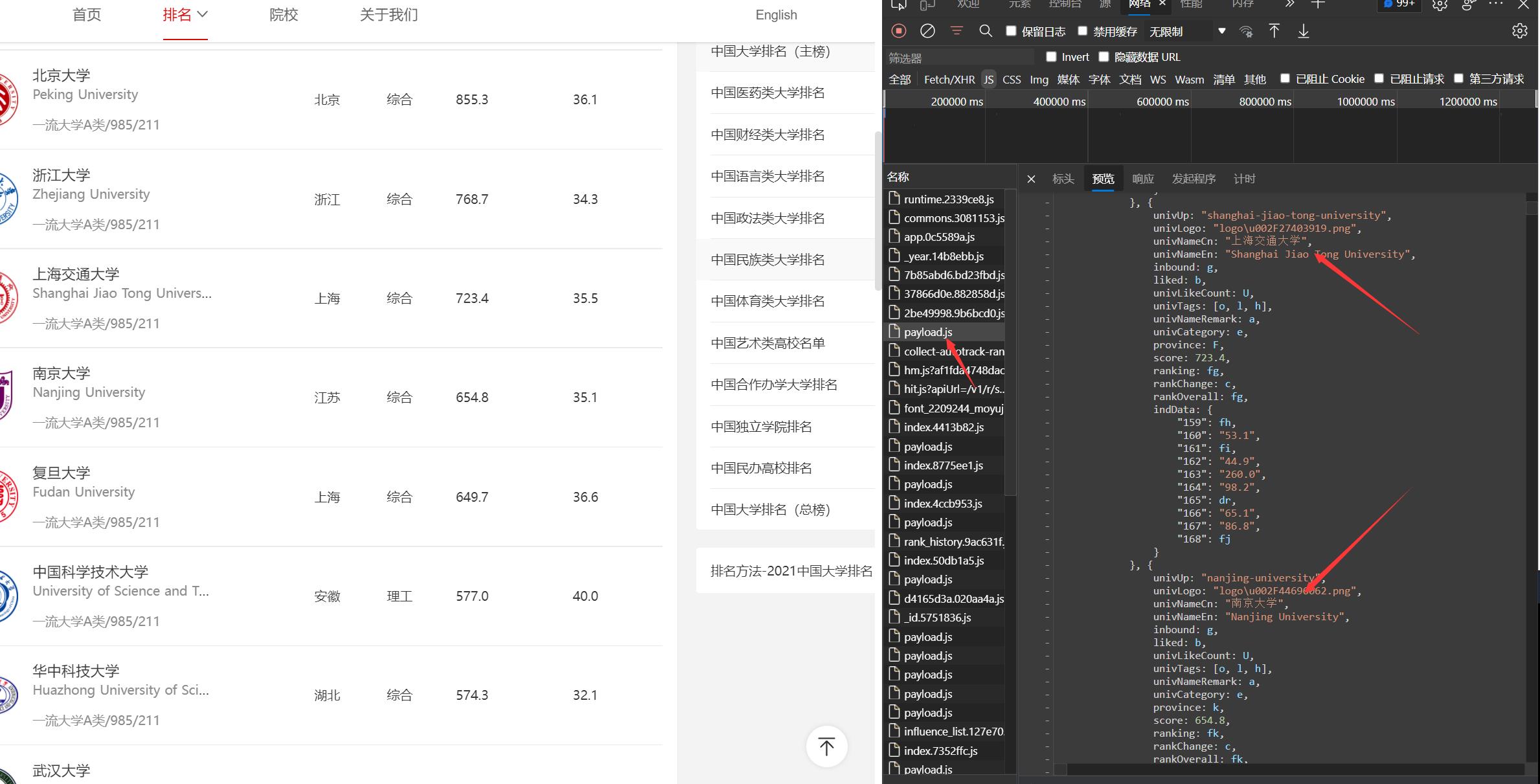
- 虽然这是可以转化成json格式,但是会麻烦很多,所以我们用正则进行匹配
res = resp.content
res = str(res,'utf-8')
3.2.3 获取结点
- 分析网页
学校信息
names = re.findall("univNameCn:(.*?),univNameEn:",res)
分数信息
scores = re.findall("score:(.*?),ranking",res)
排名信息
ranking = re.findall("ranking:(.*?),rankChange",res)
然后我们验证这三个数据是否一致
是一致的!

坑点来了!!!
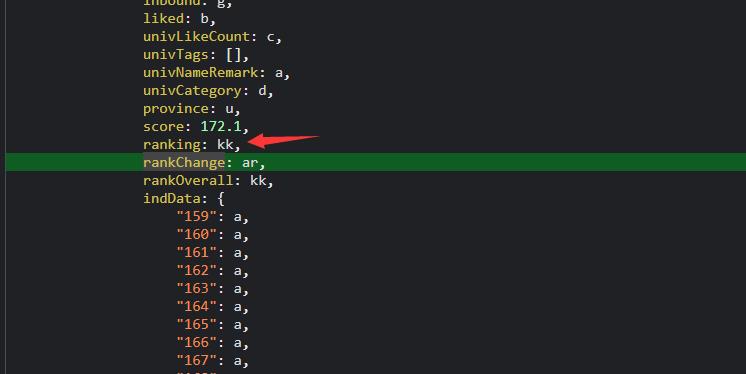
但是我们发现这里是有缺失值的!所以我们要观察网页的结构,我发现了这里就是头尾的键值对的对应,我也是第一次见这种页面结构!!!
然后我们抓取这里的信息!然后构造键值对!!


head = re.findall('"/rankings/bcur/2021", (.*?)\\)',res)
end = re.findall('mutations(.*)',res)
然后要进行数据的处理!就是要转化成元组或列表形式,方便我们构建键值对,所以我们可以通过以下方法进行转化!
keySet = head[0][len("(function"):]+")"
ValueSet = end[0][len(":void 0}}"):len(end[0])-len("));")]
keytemp=keySet.replace('(','').replace(')','')
keySet=tuple([i for i in keytemp.split(',')])
Valuetemp=ValueSet.replace('(','').replace(')','')
ValueSet=tuple([i for i in Valuetemp.split(',')])

但是发现没对上!我们打印发现是多了一个空值!就是这个箭头的空值!!

这样就可以了,就能让keySet和ValueSet一样的长度了!
ValueSet = ValueSet[1:]
然后我们构造键值对
- 初始化
data = {}
for key in keySet:
data[key]=""
- 赋值
for key,value in zip(keySet,ValueSet):
data[key]=value
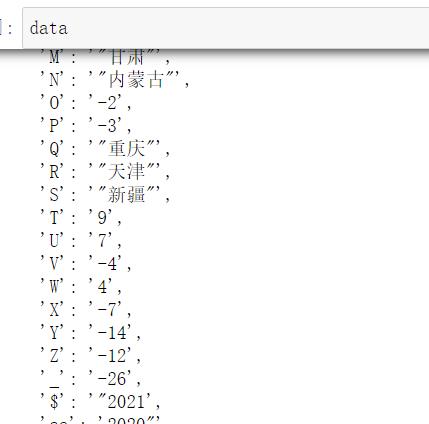
但是还有一个坑点!!
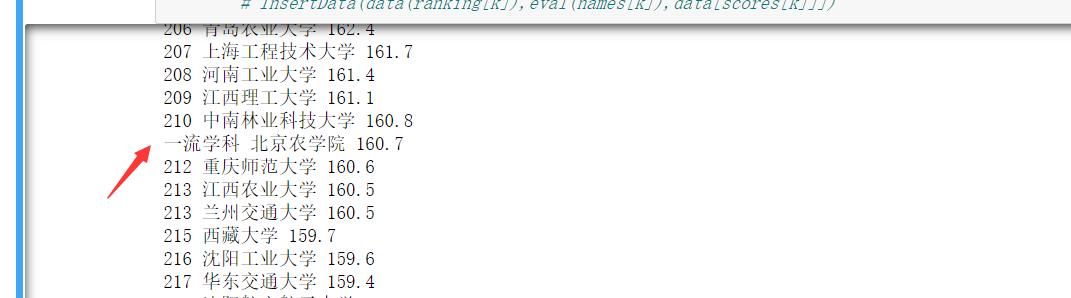
这里突然没对上,应该是211的,观察发现,原来是这里多了一位!写这个网站的程序员。。。

只能是手补上去了。
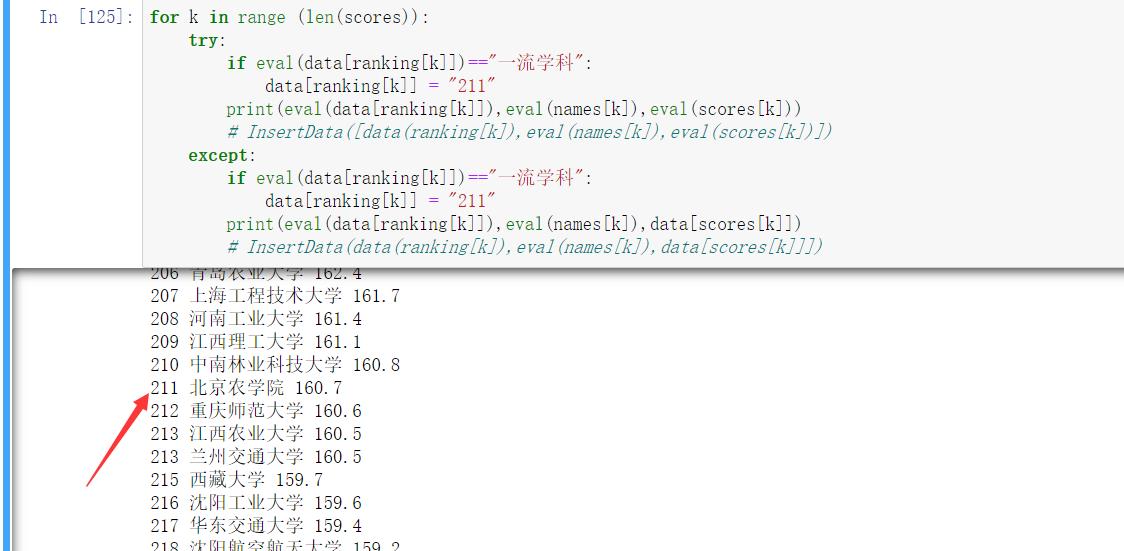
3.2.4 保存数据
同上 1.2.4
MP4 To GIF:
import moviepy.editor as mpy
# 视频文件的本地路径
content = mpy.VideoFileClip(r".\\ex3.mp4")
# 剪辑0分0秒到0分44秒的片段。resize为修改清晰度
c1 = content.subclip((0, 0), (0, 44)).resize((280, 200))
# 将片段保存为gif图到python的默认路径
c1.write_gif(r".\\ex2_3_1.gif")
最后
小生凡一,期待你的关注!
以上是关于数据采集第二次实验的主要内容,如果未能解决你的问题,请参考以下文章