Hinton团队CV新作:用语言建模做目标检测,性能媲美DETR
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hinton团队CV新作:用语言建模做目标检测,性能媲美DETR相关的知识,希望对你有一定的参考价值。
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
选自丨机器之心 Ting Chen等
目标检测的「尽头」是语言建模?近日,Hinton 团队提出了全新目标检测通用框架 Pix2Seq,将目标检测视作基于像素的语言建模任务,实现了媲美 Faster R-CNN 和 DETR 的性能表现。
视觉目标检测系统旨在在图像中识别和定位所有预定义类别的目标。检测到的目标通常由一组边界框和相关的类标签来描述。鉴于任务的难度,大多数现有方法都是经过精心设计和高度定制的,在架构和损失函数的选择方面用到了大量的先验知识。
图灵奖得主 Geoffrey Hinton 和谷歌研究院的几位研究者近日提出了一个用于目标检测的简单通用框架 Pix2Seq。与显式集成相关任务先验知识的现有方法不同,该框架简单地将目标检测转换为以观察到的像素输入为条件的语言建模任务。其中,将对目标的描述(例如边界框和类标签)表示为离散 token 的序列,并且该研究还训练神经网络来感知图像并生成所需的序列。

论文地址:https://arxiv.org/abs/2109.10852
该方法主要基于一种直觉,即如果神经网络知道目标的位置和内容,那么就只需要教它如何读取目标。除了使用特定于任务的数据增强之外,该方法对任务做出了最少的假设。但在 COCO 数据集上的测试结果表明,新方法完全可以媲美高度专业化和优化过的检测算法。
Pix2Seq 框架

该研究提出的 Pix2Seq 框架将目标检测作为语言建模任务,其中以像素输入为条件。上图所描述的 Pix2Seq 架构和学习过程有四个主要组成部分,如下图 2 所示,包括:
图像增强:在训练计算机视觉模型中很常见,该研究使用图像增强来丰富一组固定的训练样例(例如,随机缩放和剪裁)。
序列构建和增强:由于图像的目标注释通常表征为一组边界框和类标签,该研究将它们转换为离散 token 的序列。
架构:该研究使用编码器 - 解码器的模型架构,其中编码器感知像素输入,解码器生成目标序列(一次一个 token)。
目标 / 损失函数:该模型经过训练以最大化 token 的对数似然。

基于目标描述的序列构建
在常见的目标检测数据集中,例如 Pascal VOC、COCO 等,图像中往往具有数量不一的目标,这些目标被表征一组边界框和类标签,Pix2Seq 将它们表示为离散 token 的序列。
类标签自然地被表示为离散 token,但边界框不是。边界框由其两个角点(即左上角和右下角)或其中心点加上高度和宽度确定。该研究提出离散化用于指定角点的 x、y 坐标的连续数字。具体来说,一个目标被表征为一个由 5 个离散的 token 组成的序列,即 [y_min, x_min, y_max, x_max, c],其中每个连续的角坐标被均匀地离散为[1, n_bins] 之间的一个整数,c 为类索引。该研究对所有 token 使用共享词表,因此词汇量大小等于 bin 的数量 + 类(class)的数量。边界框的这种量化方案使得在实现高精度的同时仅使用较小的词汇量。例如,一张 600×600 的图像只需要 600 个 bin 即可实现零量化误差。这比具有 32K 或更大词汇量的现代语言模型小得多。不同级别的量化对边界框的影响如下图 3 所示。

鉴于每个目标的描述表达为一个短的离散序列,接下来需要将多个目标的描述序列化,以构建一个给定图像的单一序列。因为目标的顺序对于检测任务本身并不重要,因此研究者使用了一种随机排序策略(每次显示图像时目标的顺序是随机化的)。此外,他们也探索了其他确定性排序策略,但是假设随机排序策略和任何确定性排序是一样有效的,给定一个可用的神经网络和自回归模型(在这里,网络可以学习根据观察到的目标来为剩余目标的分布建模)。
最后,因为不同的图像通常有不同的目标数量,所生成的序列会有不同的长度。为了表示序列的结束,研究者合并了一个 EOS token。
下图 4 展示了使用不同排序策略的序列构建过程。

架构、目标和推理
此处把从目标描述构建的序列作为一种「方言」来处理,转向在语言建模中行之有效的通用体系架构和目标函数。
这里使用了一种编解码器架构。编码器可以是通用的感知像素图像编码器,并将它们编码成隐藏的表征形式,比如 ConvNet (LeCun et al. ,1989; Krizhevsky et al. ,2012; He et al. ,2016) ,Transformer (Vaswani et al. ,2017; Dosovitskiy et al. ,2020) ,或者它们的组合(Carion et al. ,2020)。
在生成上,研究者使用了广泛用于现代语言建模 (Radford 等人,2018; Raffel 等人,2019) 的 Transformer 解码器。它每次生成一个 token,取决于前面的 token 和编码的图像表征。这消除了目标检测器结构中的复杂性和自定义,例如边界框提名(bounding box proposal)和边界框回归(bounding box regression),因为 token 是由一个带 softmax 的单词表生成的。
与语言建模类似,给定一个图像和前面的 token,Pix2Seq 被训练用来预测 token,其具有最大似然损失,即

其中 x 是给定的图像,y 和 y^~ 分别是相关的输入序列和目标序列,l 是目标序列长度。在标准语言建模中,y 和 y^~ 是相同的。此外,wj 是序列中为 j-th token 预先分配的权重。我们设置 wj = 1,something j,但是可以根据 token 的类型 (如坐标 vs 类 token) 或相应目标的大小来权重 token。
在推理过程中,研究者从模型似然中进行了 token 采样,即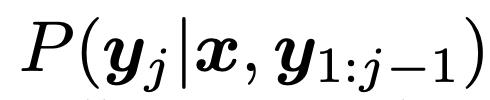 。也可以通过使用最大似然性 (arg max 采样) 的 token,或者使用其他随机采样技术来实现。研究者发现使用核采样 (Holtzman et al., 2019) 比 arg max 采样 (附录 b) 更能提高召回率。在生成 EOS token 时,序列结束。一旦序列生成,它直接提取和反量化了目标描述(即获得预测边界框和类标签)。
。也可以通过使用最大似然性 (arg max 采样) 的 token,或者使用其他随机采样技术来实现。研究者发现使用核采样 (Holtzman et al., 2019) 比 arg max 采样 (附录 b) 更能提高召回率。在生成 EOS token 时,序列结束。一旦序列生成,它直接提取和反量化了目标描述(即获得预测边界框和类标签)。
序列增强
EOS token 会允许模型决定何时终止,但在实践中,发现模型往往在没预测所有目标的情况下终止。这可能是由于:
注释噪音(例如,注释者没有标识所有的目标) ;
识别或本地化某些目标时的不确定性。因为召回率和准确率对于目标检测来说都很重要,一个模型如果没有很好的召回率就不可能获得很好的整体性能(例如,平均准确率)。
获得更高召回率的一个技巧是通过人为地降低其可能性来延迟 EOS token 的采样。然而,这往往会导致噪声和重复预测。
序列增强引入的修改如下图 5 所示,详细情况如下:

研究者首先通过以下两种方式创建合成噪声目标来增加输入序列:
向现有的地面真值目标添加噪声(例如,随机缩放或移动它们的包围盒) ;
生成完全随机的边框(带有随机相关的类标签)。值得注意的是,其中一些噪声目标可能与一些 ground-truth 目标相同或重叠,模拟噪声和重复预测,如下图 6 所示。

变化推理。使用序列增强,研究者能够大幅度地延迟 EOS token,提升召回率,并且不会增加噪声和重复预测的频率,因此,他们令模型预测到最大长度,产生一个固定大小的目标列表。当从生成的序列中提取边界框和类标签时,研究者用在所有真实类标签中具有最高似然的真实类标签替换噪声类标签。他们还使用选定类标签的似然作为目标的排名分数。
实验结果
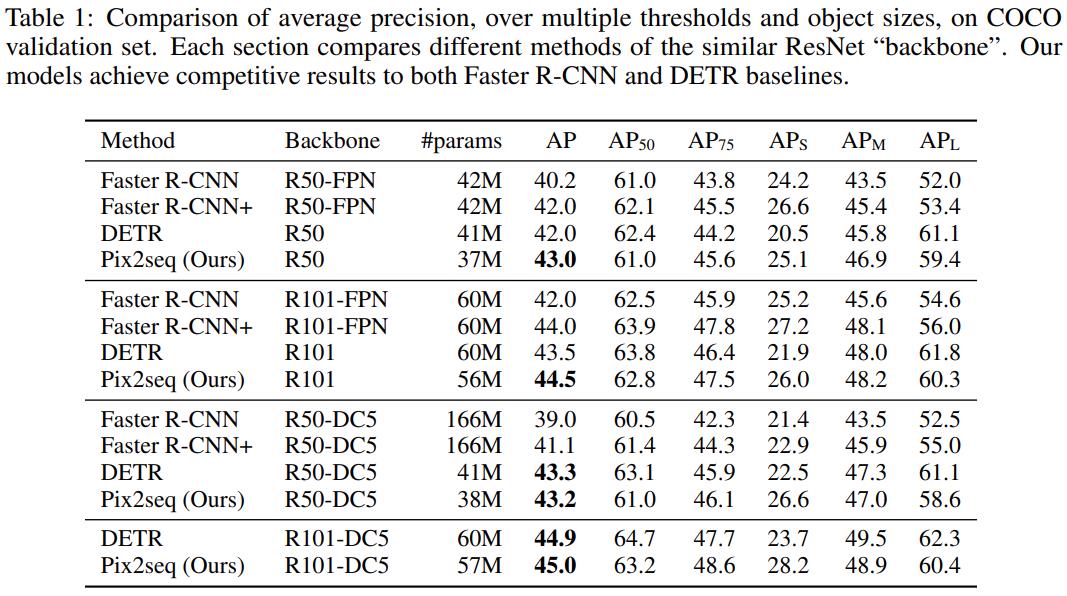
研究者主要与两个被广泛认可的基线方法进行比较,分别是 Facebook AI 于 2020 年提出的 DETR 和更早期的 Faster R-CNN。
结果如下表 1 所示,Pix2Seq 实现了媲美这两个基线方法的性能,其中在小型和中型目标上的表现与 R-CNN 相当,但在大型目标上表现更好。与 DETR 相比,Pix2Seq 在中型和大型目标上表现相当或略差,但在小型目标上表现明显更好(4-5 AP)。
序列构成的消融实验
下图 7a 探索了坐标量化对性能的影响。在这一消融实验中,研究者考虑使用了 640 像素的图像。该图表表明量化至 500 或以上 bin 就足够了,500 个 bin(每个 bin 大约 1.3 个像素)时不会引入显著的近似误差。事实上,只要 bin 的数量与像素数(沿着图像的最长边)一样多,就不会出现由边界框坐标量化导致的显著误差。
训练期间,研究者还考虑了序列构成中的不同目标排序策略。这些包括 1)随机、2)区域(即目标大小递减)、3)dist2ori(即边界框左上角到原点的距离)、4)类(名称)、5)类+区域(即目标先按类排序,如果同类有多个目标,则按区域排序)、6)类+dist2ori。
下图 7b 展示了平均精度(AP),7c 展示了 top-100 预测的平均召回率(AR)。在精度和召回率这两方面,随机排序均实现了最佳性能。研究者推测,使用确定性排序,模型可能难以从先前流失目标的错误中恢复过来,而使用随机排序,则可以在之后检索到它们。

增强的消融实验
研究者主要使用的图像增强方法是尺度抖动(scale jittering),因此比较了不同的尺度抖动强度(1:1 表示无尺度抖动)。下图 8a 展示了模型在没有合适尺度抖动时会出现过拟合(即验证 AP 低但训练 AP 高)。研究者预计,强大的图像增强在这项研究中非常有用,这是因为 Pix2Seq 框架对任务做了最小假设。
研究者还探究了「使用和不使用序列增强训练」的模型性能变化。对于未使用序列增强训练的模型,他们在推理过程中调整 EOS token 似然的偏移量,以运行模型做更多预测,从而产生一系列召回率。如下图 8b 所示,在无序列增强时,当 AR 增加时,模型会出现显著的 AP 下降。使用序列增强时,模型能够避免噪声和重复预测,实现高召回率和高精度。

解码器交叉注意力地图的可视化
在生成一个新的 token 时,基于 Transformer 的解码器在前面的 token 上使用自注意力,在编码的视觉特征图上使用交叉注意力。研究者希望在模型预测新的 token 时可视化交叉注意力(层和头的平均值)。
下图 9 展示了生成前几个 token 时的交叉注意力图,可以看到,在预测首个坐标 token(即 y_min)时,注意力呈现出了非常强的多样性,但随后很快集中并固定在目标上。

研究者进一步探索了模型「通过坐标关注指定区域」的能力。他们将图像均匀地划分为 N×N 的矩形区域网格,每个区域由边界框的序列坐标制定。然后在读取每个区域的坐标序列之后,他们将解码器的注意力在视觉特征图上实现可视化。最后,他们打乱图像的像素以消除对现有目标的干扰,并为了清晰起见消除了 2%的 top 注意力。
有趣的是,如下图 10 所示,模型似乎可以在不同的尺度上关注制定区域。

更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!
© THE END
投稿或寻求报道微信:MaiweiE_com
GitHub中文开源项目《计算机视觉实战演练:算法与应用》,“免费”“全面“”前沿”,以实战为主,编写详细的文档、可在线运行的notebook和源代码。

项目地址 https://github.com/Charmve/computer-vision-in-action
项目主页 https://charmve.github.io/L0CV-web/
推荐阅读
(更多“抠图”最新成果)
迈微AI研习社
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve

如果觉得有用,就请点赞、转发吧!
以上是关于Hinton团队CV新作:用语言建模做目标检测,性能媲美DETR的主要内容,如果未能解决你的问题,请参考以下文章
何恺明团队新作:只用普通ViT,不做分层设计也能搞定目标检测