CV:阿里在CV数据增强领域带来SOTA新范式(已被NeurIPS2022接收)—基于离散化对抗训练的鲁棒视觉新基准!
Posted 一个处女座的程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CV:阿里在CV数据增强领域带来SOTA新范式(已被NeurIPS2022接收)—基于离散化对抗训练的鲁棒视觉新基准!相关的知识,希望对你有一定的参考价值。
CV:阿里在CV数据增强领域带来SOTA新范式(已被NeurIPS2022接收)—基于离散化对抗训练的鲁棒视觉新基准!
导读:本文中,来自阿里巴巴AAIG的研究团队在模型鲁棒性问题上进行了研究,包括对抗鲁棒、分布外泛化性等。他们提出了一种即插即用的离散化对抗训练的方法来增强视觉表征。该方法在图像分类、目标检测和自监督学习等多个任务上都进行了验证,并且都有显著提升。 特别地,当DAT与Masked Auto-Encoding (MAE) 预训练模型结合进行微调,在无需额外数据等情况下,在ImageNet-C上获得31.40 mCE,在Stylized-ImageNet 上获得 32.77% 的 top-1准确率,构建了新的SOTA。 该工作“Enhance the Visual Representation via Discrete Adversarial Training” 目前已被NeurIPS接收,本文将详细介绍该相应技术。
目录
《Enhance the Visual Representation via Discrete Adversarial Training》
《Enhance the Visual Representation via Discrete Adversarial Training》

| 作者 | 毛潇锋,陈岳峰,薛晖等 |
| 论文地址论文地址 | |
| GitHub开源地址 |
1、背景介绍
当前计算机视觉任务的解决方案可抽象为以下两个阶段:
1)视觉表征提取;
2)下游任务训练/微调,
其中,视觉表征的提取是至关重要的,他决定了模型在下游任务上效果的上限。视觉表征的效果常常受限于迁移性和鲁棒性,迁移性指在某一任务上训练的视觉表征,应用于其他任务上的效果,而鲁棒性指在同一任务上,模型应对不同的测试数据域分布时的效果。学界和工业界一直致力于改进这两个局限,探索多个下游任务,多个测试域上通用的视觉表征。
提升视觉表征的通常做法是使用表达能力更强的模型,或者丰富的数据增强,降低模型过拟合的风险。然而传统的随机数据增强,只使用随机的图像变换,这种低效的方案难以保证每次增强都产生对模型有用的训练数据。对抗训练是一种对抗性的数据增强方案,在每次都通过对抗攻击的方式产生使得当前模型分类错误的“弱点”数据,通过逐渐修补模型的“bugs”,对抗训练可显著提升视觉表征的迁移性和鲁棒性。
2、难点
在工业化应用中,目前对抗训练还难以大规模应用,主要原因在于两点:
(1)、对抗训练会成倍数的增加模型的训练代价
(2)、对抗训练在提升鲁棒性的同时,也显著降低了模型在正常数据上的准确率。这个现象,被称作“Accuracy vs. Robustness Trade-Off”
真正在实际应用中,第一点通常是可忍受的,而第二点是致命缺陷,是造成对抗训练技术难以落地应用的根本因素。
3、我们的方法
本文旨在解决对抗训练中的“Accuracy vs. Robustness Trade-off”问题,并致力于将对抗训练技术落地于实际业务中以提升业务模型学到的视觉表征。
为了解决该问题,我们首先从“自然对抗样本”的角度解释图像对抗训练中的“Accuracy vs. Robustness Trade-Off”,我们认为实际让模型分类错误的样本分布,和对抗训练中产生的样本分布是有差异的。对抗样本通常通过像素上的改动产生难数据,而实际中遇到的难数据不会是改动像素导致的,更多反而是物体级别的旋转形变,外部环境光照等因素。这个bias导致像素级别鲁棒性的提升并不意味着高准确率。因此,我们需要产生更加“贴近自然”的对抗样本,作为数据增强。
计算机视觉领域中产生更“自然的对抗样本”是个难问题,因为无法准确判断一张生成图像的自然性。然而在NLP领域中“自然的对抗样本”这个问题却很简单,文本是离散化的,每个词具备各自的语义,产生自然对抗样本的过程只需要将关键词替换成某些语义相近的词,并使得模型分类出错,这样的样本就可以让人看来很自然。因此,我们的动机在于能否可将离散的符号化表示这一特性利用到图像中,并使用符号间语义相关性的特点,构造“自然对抗样本”。
为此,我们提出了Discrete Adversarial Training (DAT),也称离散对抗训练。如图1,我们首先利用VQGAN的码本将输入图像转化为一串离散的编码(类似文本的输入)并解码成离散图,这个离散化过程我们用表示。在编码上,我们采用对抗的思想,选择容易让图像分类出错的编码并替换,最终产生离散对抗样本。这里需要解决一个问题,因离散空间无法求解梯度,我们难以直接将对抗梯度回传到离散编码上。所以,我们使用了Straight-Through Estimator,把离散步骤看成identity映射。在该假设下,我们可以跳过中间的所有复杂步骤,直接将上的梯度作为对抗扰动。这一步简化同时避免了梯度在VQGAN中回传,大大降低了显存和计算代价开销(具体说明见论文)。扰动后的图像经过再一次离散化即可得到离散对抗样本。将作为“自然对抗样本”数据增强训练不同的CV任务,我们可以实现尽可能不影响模型准确率的情况下,显著提升视觉表征的迁移性和鲁棒性。
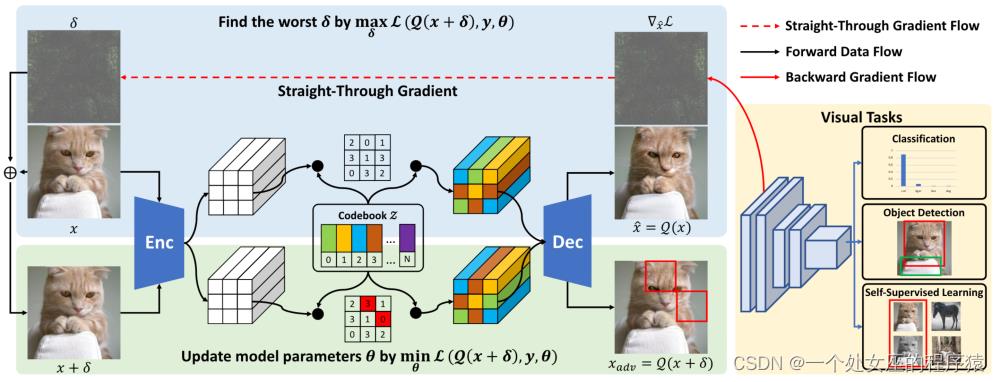
图1. 离散对抗训练(DAT)的整体流程
我们通过简单的可视化来判断是否确实符合上述的“自然对抗样本”,我们在ImageNet中采样了1000个样本,并基于预训练的ResNet50产生像素级别的普通对抗样本和离散对抗样本,并将他们输入模型得到BatchNorm层的均值方差统计,并计算和正常样本BN层统计的皮尔逊相关系数(PCC)来可视化对抗样本和自然样本间的分布差异。从图2可知,DAT产生的离散对抗样本和自然样本分布的相似度更高,更符合认知上的“自然对抗样本”。
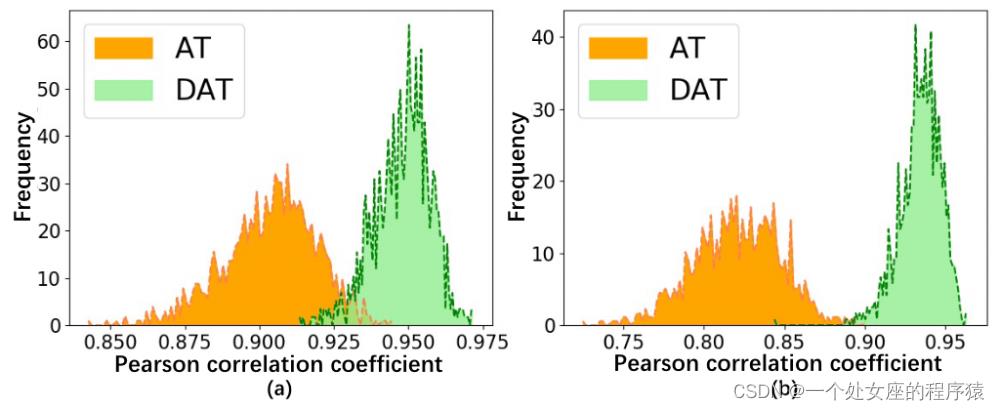
图2. 正常图像和对抗样本的BatchNorm统计间的皮尔逊相关系数(a均值,b方差)
离散对抗训练的算法流程图如下:
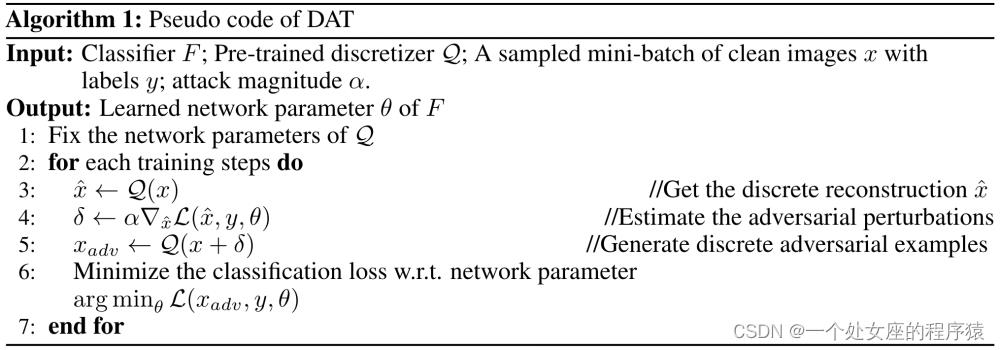
图3. 离散对抗训练(DAT)的算法流程图
4、实验结果
我们将DAT在分类,自监督,目标检测3个任务上进行了效果验证。
4.1、分类
我们采用ImageNet-A,ImageNet-C,ImageNet-R,ImageNet-Sketch等分布外性能测试集,和FGSM,DamageNet对抗下性能测试集来评估DAT分类视觉表征的鲁棒性。我们采用基于CNN架构的ResNet50和基于Transformer架构的ViT-B作为基础模型,和当前先进的鲁棒训练方法进行了对比,从结果上,DAT在所有实验setting下都提升了分类的鲁棒性,并可以和AugMix以及DeepAugment等技术有效结合。其中MAE+DAT (ViT-H)模型在ImageNet-C和ImageNet-Stylized两个benchmark上同时取得第一,创造了新的SOTA结果。
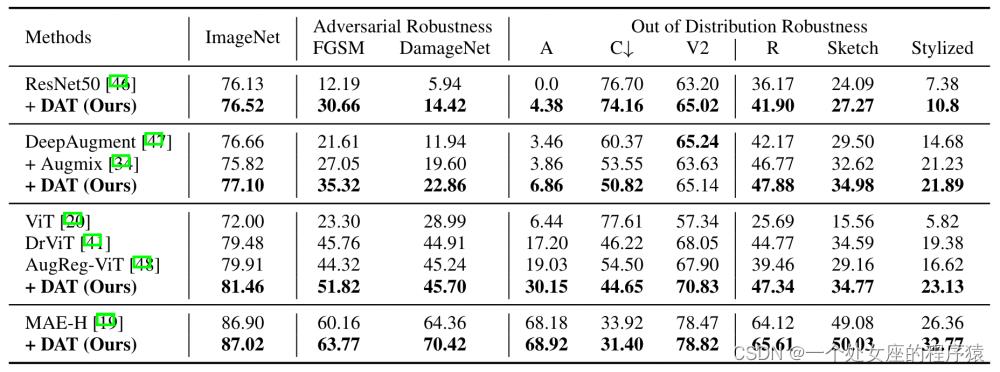
图4. 离散对抗训练(DAT)在分类任务上的实验对比
4.2、自监督
自监督任务要求通过无标签数据的预训练,获得迁移到多个下游任务上均有效的视觉表征。因此在该任务上,我们可以更直接的看出DAT对视觉表征迁移性的影响。我们选用了MoCov3,SimCLR,SimSiam三个自监督方法,并将DAT用于预训练过程。由于预训练的目标函数不再是分类损失而是对比损失,我们使用了和RoCL类似的对抗梯度回传方法,即最大化模型在预训练过程中的对比误差。图5显示DAT同样在自监督预训练任务中,能提升视觉表征的下游迁移性,这个实验结果也和以往使用对抗训练提升迁移性的工作的结果不谋而合了。
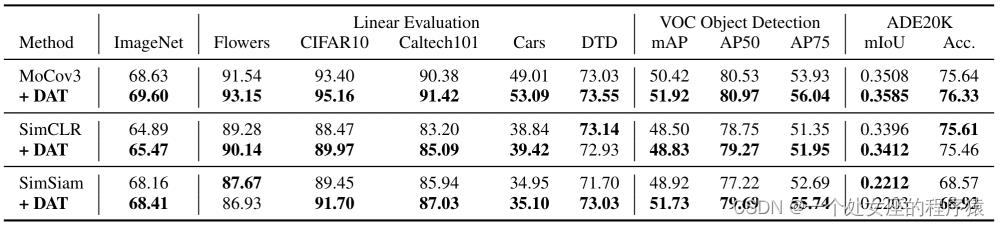
图5. 离散对抗训练(DAT)在自监督任务上的实验对比
4.3、目标检测
除此之外,我们还在目标检测任务上进行了测试,为避免过高的训练代价,我们在COCO上训练512输入以下的两个基础detector:efficientdet,COCO-C的mAP和rPC指标用于评估目标检测的鲁棒性,同时对比了另一个鲁棒目标检测训练方法Det-Advprop,图6结果显示DAT在小分辨率模型上可以同时提升COCO和COCO-C的mAP,并增强了模型的相对鲁棒性。
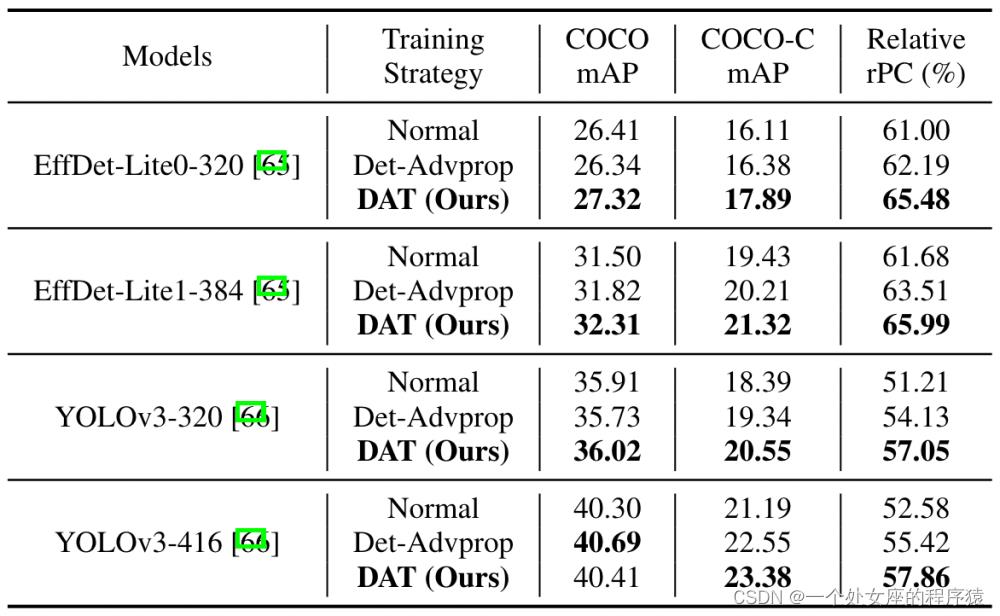
图6. 离散对抗训练(DAT)在目标检测任务上的实验对比
4.4、Ablation
我们在ablation实验中可视化了DAT的扰动,更直观的显示离散对抗样本相比于传统像素级对抗样本的优良特性:
(1)、离散对抗样本具有更高的图像质量。从图7第一行,通过计算区域内的color numbers,可看出传统的像素级对抗样本的像素值更丰富,但其中大多数是无效的,因此他比离散对抗样本有更多的噪点区域。通过计算真实性指标,我们发现离散对抗样本的FID只有14.65,远远低于传统对抗样本的65.18。
(2)、离散对抗样本更聚焦于低频的扰动。通过绘制频谱图,我们发现离散对抗样本在四个角上的值更低,这表示他有更多的低频成分,更接近于真实图像。反之,传统像素级的对抗扰动引入了非常多的高频成分。
(3)、离散对抗扰动更加结构化。结构化的特性会让对抗扰动更关注于重要的目标区域,这些区域对于分类等任务更关键,相比之下,传统的像素级对抗扰动则完全是杂乱无结构的噪声。
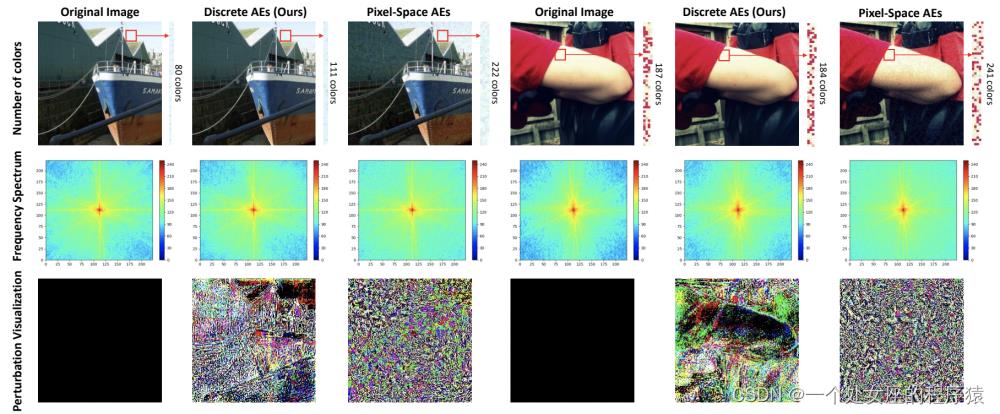
图7. 离散对抗样本和像素级对抗样本的可视化对比
5、关于我们【RCRT研究型实习生】
AAIG安全实验室致力于人工智能特别是深度学习的前沿技术研究与应用实践,实现可靠、可信、可用的人工智能系统,在TPAMI、NeurIPS、ICLR、CVPR、TIP、ICCV、ECCV、EMNLP、IEEE S&P、USENIX Security、CCS等学术会议上和期刊上发表多篇高水平论文,累计申请专利多项,参与多项国际国内技术标准制定,荣获中国人工智能大赛深度伪造视频检测A级证书。
主要研究方向包括:人工智能安全性、鲁棒性、可解释性、公平性、迁移性、隐私保护和因果推理等,从基础理论研究和技术创新两方面。与清华、中科院、浙大、上交、中科大等国内知名高校建立学术合作关系。
实验室目前正在RCRT研究型实习生,对人工智能安全方向有兴趣的可以发resume到:yuefeng.chenyf@alibaba-inc.com。
以上是关于CV:阿里在CV数据增强领域带来SOTA新范式(已被NeurIPS2022接收)—基于离散化对抗训练的鲁棒视觉新基准!的主要内容,如果未能解决你的问题,请参考以下文章