基于海量日志和时序数据的质量建设最佳实践
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于海量日志和时序数据的质量建设最佳实践相关的知识,希望对你有一定的参考价值。
简介: 在云原生和DevOps研发模式的挑战下,一个系统从开发、测试、到上线的整个过程中,会产生大量的日志、指标、事件以及告警等数据,这也给企业质量平台建设带来了很大的挑战。本议题主要通过可观测性的角度来讨论基于海量日志和时序数据的质量建设最佳实践。

作者 | 寂之
来源 | 阿里技术公众号
一 前言
在云原生和DevOps研发模式的挑战下,一个系统从开发、测试、到上线的整个过程中,会产生大量的日志、指标、事件以及告警等数据,这也给企业质量平台建设带来了很大的挑战。本议题主要通过可观测性的角度来讨论基于海量日志和时序数据的质量建设最佳实践。
二 质量建设痛点
众所周知,在云原生开发模式下,可观测性是非常重要的一部分,它通过日志、指标、Trace等数据,让我们可以深入了解系统的运行状态和健康程度。在 CNCF Landscape大图中,可观测性也占据了相当大的一块位置。
然而在实际使用过程中,许多人对可观测性的关注,主要集中在系统上线之后。这当然是没有问题的,但实际上,从一个系统开发开始,一直到线上运行,都是可以从可观测的角度来对系统的质量进行评估和衡量,我们可以称之为对质量的观测。
下图比较概括地描述了一个系统的质量观测完整生命周期,大体上可以分为如下四个阶段,并且在每个阶段都有需要特别关注的一些数据和指标:
- 开发阶段:重点需要关注代码的质量,例如静态代码扫描以及依赖检查会发现潜在的代码缺陷和安全风险,由此我们可以统计千行代码缺陷率或者严重缺陷比例,从而来衡量一个系统的代码质量是否符合要求
- 测试阶段:在此阶段需要重点关注测试的质量,例如测试覆盖率,以及测试用例的失败率等指标
- 灰度验证:需要关注系统的稳定性以及不同版本之间的差异,因此也会有一系列的业务指标,例如HTTP Error 比例,不同版本的延迟等指标的对比
- 线上运行:此时需要重点关注系统的稳定性以及业务的稳定性,因此各种线上的性能指标、业务指标、应用日志、Trace等各种数据都是非常重要的
在整个质量观测的生命周期中,除了各种各样的数据,我们也会涉及到各种各样的系统,例如 GitLab、sonarqube、Allure、JMeter、Jenkins、Travis CI、Argo CD 等等。这些不同的系统作用于不同的阶段,会产生大量的异构数据,如何对这些数据进行合理的管理和使用,从而可以比较方便地挖掘出其中的数据价值(不局限于软件质量方面),对我们来说是一个比较大的挑战。
基于上述的讨论,我们可以大体总结出质量观测的几个痛点:
- 海量的异构数据:在系统开发、测试、验证、上线等各个阶段产生了大量的日志、时序、Trace 等数据,这些数据产生的位置、数据格式、以及存储的位置,都有可能是不一样的。如何从这些数据中快速精准地挖掘出潜在的质量问题比较困难。
- 依赖规则,缺乏智能:质量监控比较依赖于人的经验,很大程度上受限于人为设定的规则和阈值,无法做到数据自适应,因此无法发挥出真正的数据价值。另一方面就是随着系统的发展和演进,需要大量的人工干涉和不断调整,才能够让监控比较有效。
- 告警风暴与告警误报:为了不错过细微的问题,我们可能会配置大量的监控,从而导致在完整的软件生命周期中可能产生大量的告警,难以从其中识别出有效信息。另外大量的告警也带了很大程度上的误报问题,从而导致“狼来了”效应,于是真正的问题反而很容易又被忽略掉。这就陷入了恶性循环。
三 数据统一接入和管理
1 海量数据管理痛点
首先我们来探讨第一个痛点,也就是如何对海量的异构数据进行管理。目前可观测性相关的系统五花八门。
例如日志可能会使用 ELK 或者 Splunk,指标会使用 Prometheus,Trace 使用 Skywalking、Jaeger 或者 zipkin。但太多的选择也不见得是好事,在这种情况下,可观测性数据的管理又给我们带来了如下几个痛点:
- 运维成本高:完整的质量系统需要数个甚至十多个软件的协同,从而也带了极高的运维成本。
- 学习成本高:每个软件都有自己的使用插件、插件系统,有些还会有自己的DSL语法,学习成本非常高,很难完全掌握使用。
- 扩展困难:随着数据规模的增长,软件的扩展能力、性能、稳定能力等方面都会有很大的挑战。
- 数据孤岛:不同的数据处于不同的系统中,协同困难。例如想要将 ES 中的日志和 Prometheus 中的指标进行一个 Join 查询就无法实现,除非做额外的二次开发。
2 数据统一接入和管理
基于上述几个痛点,我们的解决方案是将这些异构的数据进行统一的存储和管理,如下图所示:
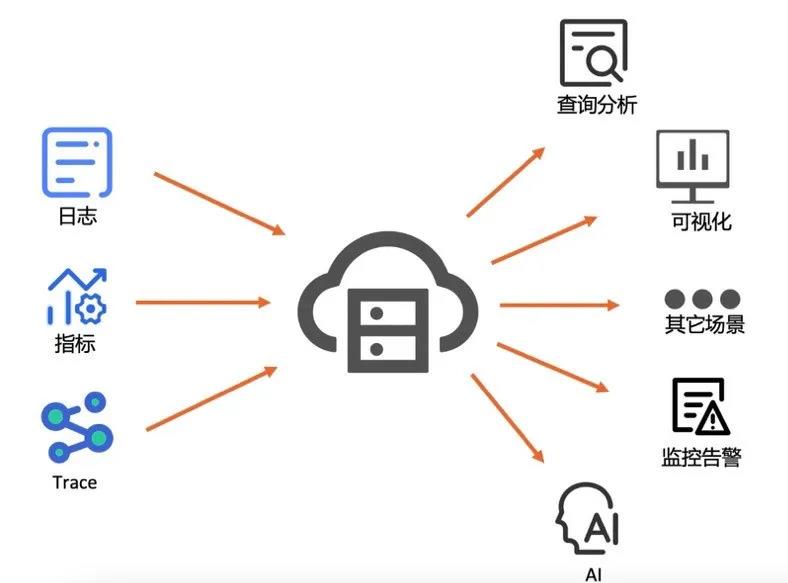
在这里,我们将日志、指标、Trace等数据全部接入到一个统一的可观测性存储中。然后基于这个统一的存储,进行后续的查询分析、可视化、监控告警、AI 等上层能力,甚至还可以进行数据的加工和规整,一站式地完成异构数据到同构数据的转换过程。
基于统一的存储,我们可以构建统一的查询和分析语法,从而一套语法适配不同的数据,并且让不同的数据之间进行联合查询也变成了可能。如下图所示,我们以标准 SQL 为基础,进行了部分 DSL 扩展和 SQL 函数扩展,并融合了 PromQL,从而让不同类型的数据查询和分析变得统一。
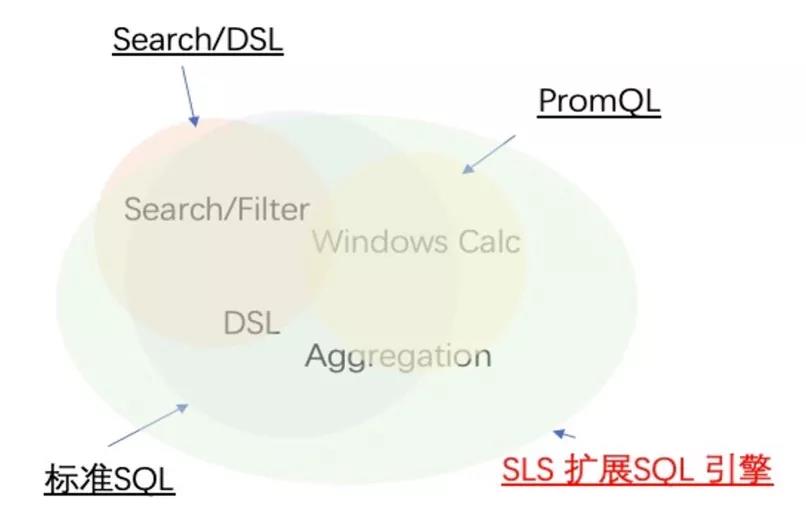
例如下面的例子:
- 我们可以通过标准 SQL 语句对日志进行分析
- 还可以通过 PromQL 扩展的 SQL 函数对指标数据进行分析
- 还可以通过嵌套查询,对指标数据的分析结果进行再聚合
- 此外还可以再通过机器学习函数,给查询和分析赋予 AI 的能力

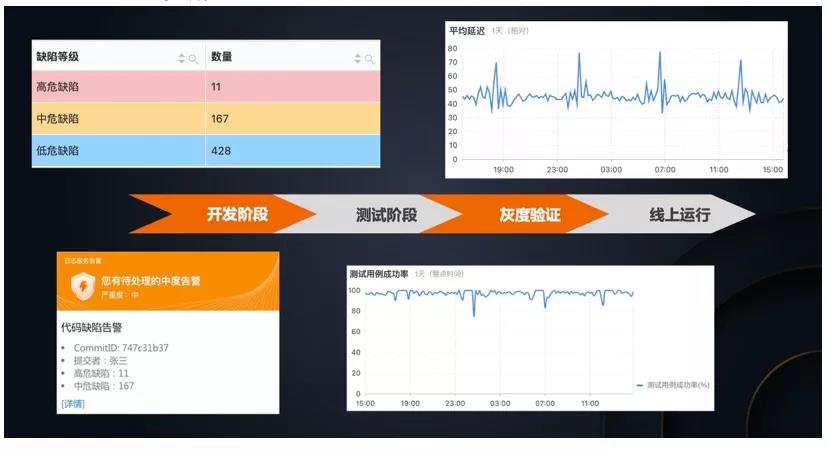
基于上述统一的数据存储和查询分析,我们可以非常轻松地实现统一的可视化和监控。如下图所示,虽然不同阶段的数据产生自不同的系统,也有着不同的格式,但是由于它们的存储和分析是一致的,因此我们可以构建出统一的报表来查看各个阶段的软件质量,以及统一进行监控的配置和告警的管理,而无需将这些分散到各个不同的系统中,脱离例如 ES + Kibana、Prometheus + Grafana 等组合。
四 智能巡检
1 传统监控的困难和挑战
接下来我们来看如何基于这些数据,让监控更加智能。传统的监控大多是基于一些固定的阈值,或者同环比。但是在很多场景下,这种模式存在着诸多问题。例如:
- 监控对象爆炸式增长:随着云原生的普及,服务部署越来越从以“主机”为中心向“容器化”方向转化,容器本身的轻量化以及短生命周期等特点,导致监控对象和监控指标急剧增加。如果要全方位的覆盖这些监控对象和指标,需要配置大量的监控规则,并且它们的阈值也可能是各不相同的,因此会有很大的工作量。

-
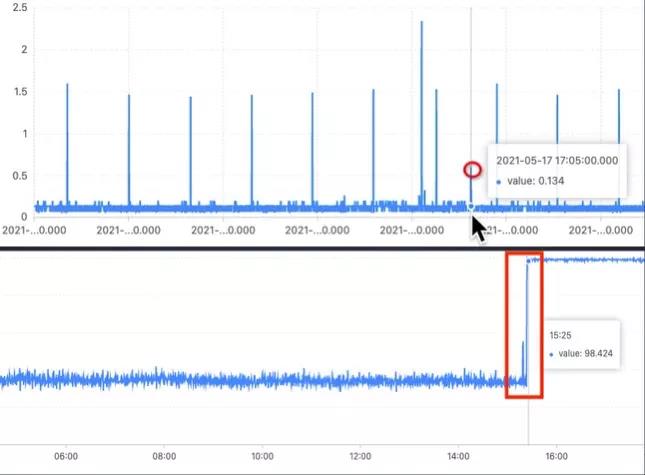
监控规则无法自适应:基于人为定义的阈值,很大程度上依赖于人的经验,随着系统的演化和业务的发展,这些规则往往不能很好地适应,由此不可避免地导致漏报、误报等问题。无法做到数据的自适应,因此需要人为介入,不断调整阈值。例如下图:
- 上面是一个指标,有规则性的毛刺。如果通过阈值来判断是否需要告警,当一个毛刺点异常的时候,可能由于不满足阈值,导致告警漏报。
- 下面是另一个指标,可能随着系统的进化,新版本发布之后,该指标的值会发生一个陡增。此时如果是固定阈值告警的话,会将陡增之后的所有数据都认为是异常点,导致告警频繁触发。此时需要人为介入去调整阈值。
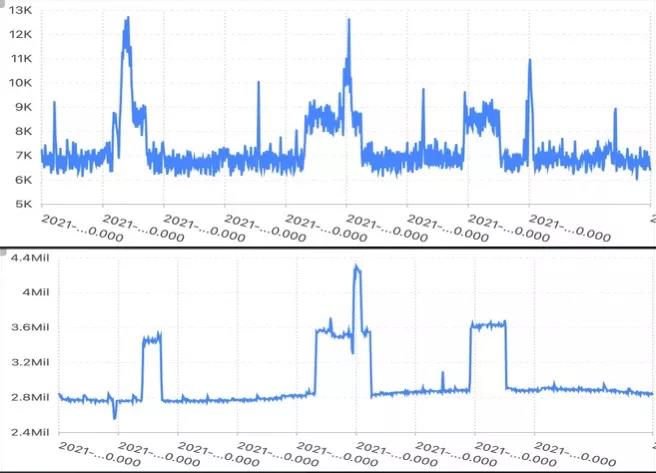
- 监控规则泛化能力弱:不同的业务、甚至同一业务的不同版本,指标的规律性、阈值都有可能是不同的。因此我们需要为不同的业务、不同的版本去做监控规则的适配。例如下图,虽然两个指标整体上有着比较相似的波动规律,但是由于它们的取值范围、以及局部的抖动情况会有差异,因此需要分别去做监控。
2 智能巡检
基于上述痛点,我们提出了智能巡检的方案。它具备以下几个优势:
- 智能前置:现在有很多系统是在告警触发后,进行智能的管理,但是这无法避免告警误报、漏报等问题。智能巡检可以将 AI 的能力前置到监控层,从而在源头上避免潜在的告警问题,挖掘出真正有效的数据价值。
- 监控自适应:可以基于历史数据自动学习和进化,进行动态的阈值判断,从而让告警更加精准。另外对数据的学习也是实时的,可以更加快速地发现异常问题。
- 动态反馈:除了自动学习之外,还可以通过用户的反馈,对告警进行确认或者误报标记,将 AI 能力与人的经验相结合,相辅相成,进一步完善模型,减少误报。
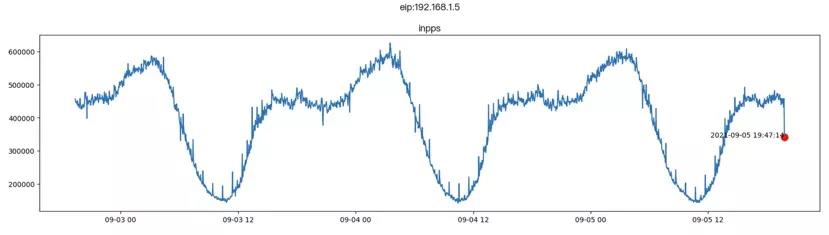
在一些数据波动比较大,指标没有固定阈值的场景下(例如用户访问量、外卖订单量等),智能巡检的优势可以得到很好的体现。例如下图,指标本身呈现出周期性的波动,假如一个新版本上线了之后,由于bug导致网络流量异常抖动。如果基于固定阈值来判断,此时处于指标值的上下界范围内,就很难发现问题;但是基于智能巡检,就可以很容易地判定这是一个异常点。
3 智能巡检实现思路
智能巡检的基本思路如下:
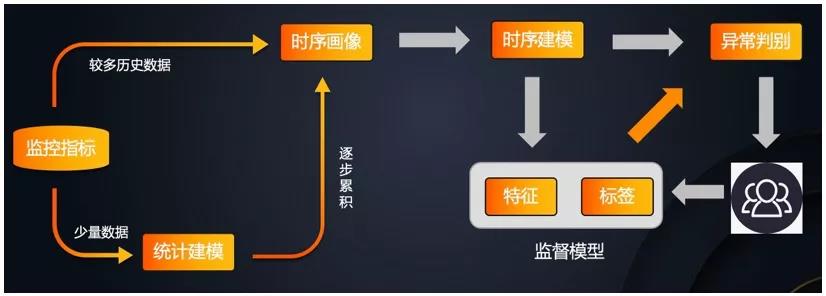
我们采用无监督学习算法,自动识别实体的数据特征,根据数据特征选取不同的算法组合,针对数据流实时建模,完成异常任务检测。并根据用户的打标信息(对告警进行确认或者误报反馈),训练监督模型,对算法进行不断优化,从而提高监控的准确率。
目前异常检测我们使用了两种算法,它们的比较如下:

五 告警智能管理
1 告警管理痛点
在质量观测的完整生命周期中,会产生大量的告警。如下图所示:

这导致的问题就是:
- 多套工具难维护:在不同的阶段可能使用了不同的工具,每个工具可能都提供了一部分的告警能力,最终导致难以维护。好在通过统一的数据接入和管理,我们可以统一去配置监控和管理告警。
- 海量告警无收敛:另一个问题就是,海量的告警难以收敛,尤其是当告警之间有相互依赖关系的时候。例如主机负载高,导致该主机上服务异常、接口延迟高、HTTP Error 报错多等多种问题并发,从而段时间内有大量的告警触发,以及大量的告警消息通知。缺乏合理的降噪机制。
- 通知管理能力弱:许多告警管理系统只是简单地将告警消息发送出去,存在着通知渠道不完善、通知内容不符合用户需求、无法支持值班需求等等问题。
2 告警智能管理
我们可以通过告警智能管理来解决上述问题,如下图所示:

告警智能降噪包含以下几种机制:
- 自动去重:每个告警会根据告警自身的关键特征计算出一个告警指纹,然后根据告警指纹自动去重。例如:某主机每一分钟触发CPU使用率过高告警,1小时触发60次,但对于告警管理系统来说,这只是一个告警的60个快照,而不是60个独立的告警;同时假如通知设置为30分钟重复,则一共只会发送两次通知,而不是每一分钟就发送一次通知。
- 路由合并:相关的告警合并起来,一并进行通知,而不是针对每个告警分别通知,从而减少通知的数量。例如:根据告警所在集群进行合并,假如某集群短时间内产生了10个告警,则只会发送一条通知,包含这10个事件。
- 告警抑制:主要用于处理告警之间的互相影响。例如:某一k8s集群发生OOM严重告警,可以暂时忽略同一集群的低级别告警。
- 告警静默:满足特定条件的告警无需通知。例如:测试集群在凌晨有计划内变更,期间服务会有短暂不可用,触发预期内告警,该告警可以忽略。
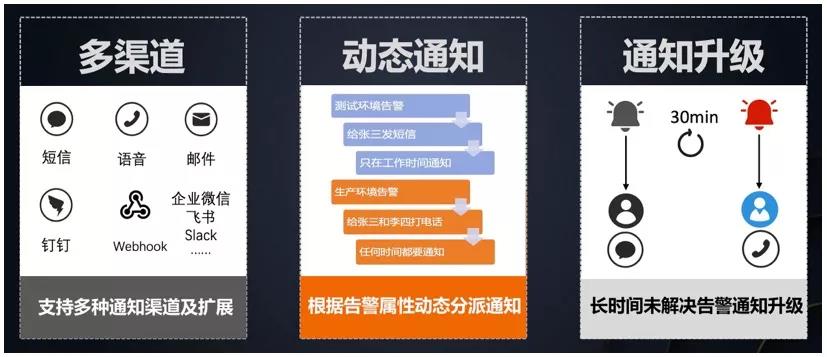
动态分派包含如下功能:
- 多渠道:支持短信、语音、邮件、钉钉、企业微信、飞书、Slack等多种通知渠道,同时还支持通过自定义 Webhook 进行扩展。同一个告警,支持同时通过多个渠道、每个渠道使用不同的通知内容进行发送。例如通过语音和钉钉来进行告警通知,既可以保证触达强度,又可以保证通知内容的丰富程度。
- 动态通知:可以根据告警属性动态分派通知。例如:测试环境的告警,通过短信通知到张三,并且只在工作时间通知;而生产环境的告警,通过电话通知到张三和李四,并且无论何时,都要进行通知。
- 通知升级:长时间未解决的告警要进行升级。例如某告警触发后,通过短信通知到了某员工,但是该问题长时间未被处理,导致告警一直没有恢复,此时需要通知升级,通过语音的方式通知到该员工的领导。
另外就是值班和代班机制。值班是非常常见的一个场景,通常情况下,告警不是发送给所有的负责人,而是通过轮转的方式进行分别值班。既然有了值班,也必须要考虑特殊的场景需要代班,例如某人值班的当天,由于有事,所以让另外一个人来代替他值班。例如下面的例子:2021年8月由张三和李四值班(每班一周,仅工作日值班),首个工作日交班;8月17日张三请假,由小明代值班。

六 总结和展望
综合上面的讨论,完整的架构大图如下:
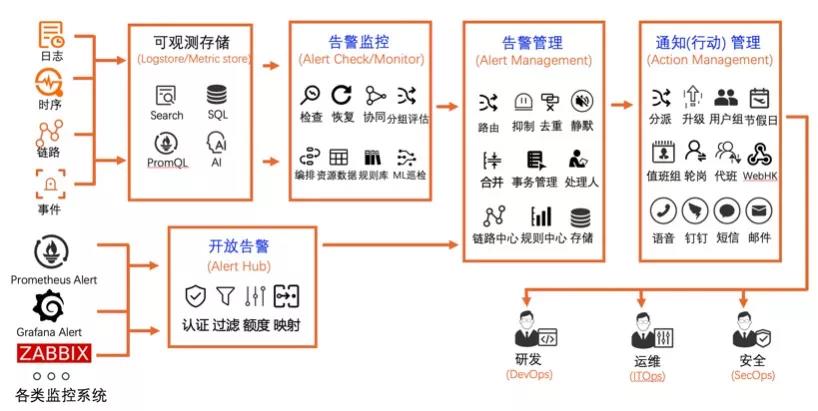
通过将日志、时序、Trace、事件等数据接入到统一的可观测存储,从而实现统一的查询分析、可视化等功能,基于此,可以实现统一的监控和告警管理,从而赋能研发、运维、安全等各个角色。除此之外,还支持通过开放告警的功能,将其它系统(例如 Prometheus、Grafana、Zabbix 等)的告警直接接入进行告警的统一管理。
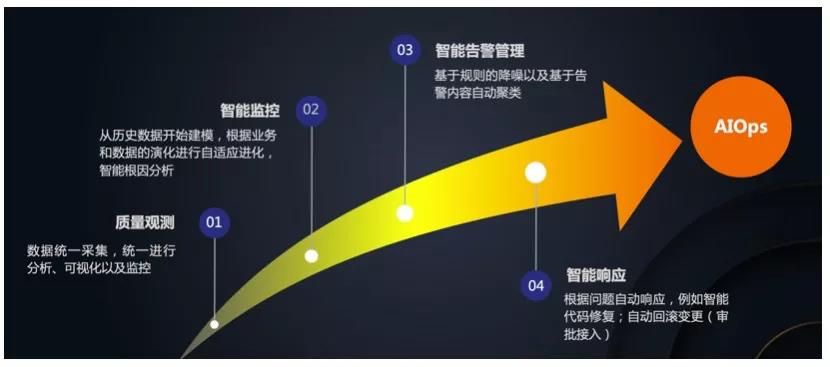
关于对未来的展望:
- 目前质量观测,数据的统一采集和管理,分析、可视化、监控等能力已经都相对完善
- 从监控角度来说,智能巡检已经可以比较好的自适应数据,另外就是进行智能根因分析,自动发现问题的根源,加快问题溯源,减轻排障困难
- 告警的智能管理,除了基于规则的降噪,还会加入更多的算法支持,根据告警内容自动进行聚类,减少告警通知风暴
- 最后一步是问题的后续响应,目前我们已经可以通过对接自定义的Webhook来进行一些简单的操作,后续还会加入更多自动化的能力,例如代码故障自动修复,自动回滚变更等。
随着以上几步的不断建设和完善,相信对于质量的观测和把控,会越来越朝着人性化、自动化、智能化的方向迈进。
链接:
1、CNCF Landscape地址:CNCF Cloud Native Interactive Landscape
2、Time-Series Event Prediction with Evolutionary State Graph:Time-Series Event Prediction with Evolutionary State Graph | Proceedings of the 14th ACM International Conference on Web Search and Data Mining
3、RobustSTL: A Robust Seasonal-Trend Decomposition Algorithm for Long Time Series:RobustSTL: A Robust Seasonal-Trend Decomposition Algorithm for Long Time Series| Proceedings of the AAAI Conference on Artificial Intelligence
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于基于海量日志和时序数据的质量建设最佳实践的主要内容,如果未能解决你的问题,请参考以下文章
底层基于Apache Hudi的DLA最佳实践 | 海量低成本日志分析
解读华为云GaussDB(for Influx):最佳实践之数据建模