智能日志系统建设最佳实践
Posted 胜山的反思日记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了智能日志系统建设最佳实践相关的知识,希望对你有一定的参考价值。
一、监控系统拓扑结构
图1
上图是监控系统大致的整体结构,接下来通过以下7个方面来进行讲述:
1、日志打印
2、日志切分
3、日志采集
4、日志过滤
5、日志存储
6、数据展示
7、异常报警
一、日志打印
完善的日志是实现监控的基础,如何打印日志关系到之后的日志过滤、存储以及分析。除了选择合适的日志库,还要满足一些日志打印的要求:
- 日志风格:以key-value的field形式输出结构化的日志。
- 输出时机: error日志一定都需要打印,info日志结合业务需求适当打印,日志只需要在业务层关注,model和util等不需要打印。
- 输出格式:线上以json的格式打印日志,方便解析日志。线下为了方便查看,可以用自定义的format打印日志,线上和线下的日志格式通过etcd来控制。
- 输出内容:每一条日志都要携带logid、method、host和level,并且根据不同业务场景,需要携带不同业务的标识field,例如projectType、platform、payType等。
- 用context来传递不同goroutine之间的共享信息。
二、日志切分
日志切分是运维层面的东西,不应该由日志库来承担日志切分的事情,因为Linux在日志切分上有很成熟的工具,不需要自己写码去重复实现。
目前对日志切分的需求只有2个:按天切分和删除切出来的多余日志。logrotate就能很好的满足这些需求,logrotate是基于cron来运行的,其脚本是/etc/cron.daily/logrotate,默认放在/etc/cron.daily下,每天执行一次。
有的时候程序异常或者请求激增会导致日志量暴增,有可能在短时间内打满整个磁盘。可以在logrotate的配置文件里加上maxsize来限制日志文件的大小,并且将logrotate的执行频率调高至每小时甚至每分钟,及时切分并删除超过rotate数量的日志,来防止异常情况下磁盘被打满的情况发生。样例配置如下所示:

图2
三、日志采集
从监控系统的角度来说,日志收集有2种方式:主动采集和被动接收,两种方式各有利弊。
a.主动采集
- 优点:日志收集和业务程序分开,互不影响。
- 缺点:日志收集需要依赖额外的采集服务,过滤和存储可能还需要额外配置。
b.被动接收
- 优点:业务程序直接将日志发送至存储,灵活性强,存储内容可在业务代码里控制。
- 缺点:日志存储不稳定的话会影响业务程序的正常运行;反之,日志量大的话也会压垮日志存储。
但是在建设监控系统初期,日志存储还不是很稳定的情况下,还是用主动采集的方式比较稳妥,不影响服务稳定性为主。

图3
Collectd功能确实很强大,它的tail插件也能满足从文件收集日志,但是tail插件配置比较复杂而且说明文档相较于Filebeat来说不是很详细。
Collectd的其他插件可以采集的数据确实很多,而且也有插件支持将数据发送到Logstash和InfluxDB,但是多数插件的功能我们用不到,而且Elastic Stack中的Beats也能够很好的收集系统参数等数据,而且跟ELK能很好的兼容。
所以在分别试用了Filebeat和Collectd这2个采集服务后,综合上述分析决定采用Filebeat来负责从日志文件中采集日志。如图所示,Filebeat的配置简单易懂:

图4
Filebeat 发送的日志,会包含以下字段:
- beat.hostname beat 运行的主机名
- beat.name shipper 配置段设置的 name,如果没设置,等于 beat.hostname
- @timestamp 读取到该行内容的时间
- type 通过 document_type 设定的内容
- input_type 来自 "log" 还是 "stdin"
- source 具体的文件名全路径
- offset 该行日志的起始偏移量
- message 日志内容
- fields 添加的其他固定字段都存在这个对象里面
图5
四、日志过滤
Logstash 自2009年诞生经过多年发展,已经是很成熟并且流行的日志处理框架。
Logstash使用管道方式进行日志的搜集处理和输出。有点类似*NIX系统的管道命令 input | filter | output,input 执行完了会执行 filter,然后执行 output。
在 Logstash 中,包括了三个阶段:输入input → 处理filter(不是必须的)→ 输出output。
每个阶段都由很多的插件配合工作,比如 file、elasticsearch、redis 等等。
每个阶段也可以指定多种方式,比如输出既可以输出到elasticsearch中,也可以指定到stdout在控制台打印。
Codec 是 Logstash 从 1.3.0 版开始新引入的概念(Codec 来自 Coder/decoder两个单词的首字母缩写)。
在此之前,Logstash 只支持纯文本形式输入,然后以过滤器处理它。但现在,我们可以在输入期处理不同类型的数据,这全是因为有 Codec 设置。
所以,这里需要纠正之前的一个概念。Logstash 不只是一个 input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!Codec 就是用来 decode、encode 事件的。
Codec 的引入,使得 Logstash 可以更好更方便的与其他有自定义数据格式的运维产品共存,比如 graphite、fluent、netflow、collectd,以及使用msgpack、json、edn 等通用数据格式的其他产品等。
Logstash 提供了非常多的插件(Input plugins、Output plugins、Filter plugins、Codec plugins),可以根据需求自行组合。其中 Filter 插件 Grok 是 Logstash 最重要的插件。
Grok 通过正则表达式匹配日志内容,并将日志结构化,所以理论上只要正则掌握的够娴熟,就能解析任何形式的日志,非常适合用来解析第三方服务产生的非结构化日志。
但是如果是自己写的服务,就没必要将日志输出成非结构的,增加写正则的负担,所以在上述日志打印一节中才规定线上的日志输出成json形式,方便 Logstash 解析,Logstash 提供 json 的 Filter 插件。

图6
上图所示的配置示例是对一个sample服务产生的json日志,通过Filebeat采集,用json的Filter插件进行解析,并将结果输出到标准输出。
五、日志存储
InfluxDB vs. Elasticsearch
根据DB-ENGINES(https://db-engines.com/en/ranking)的排名,InfluxDB 和 Elasticsearch 在各自专攻的领域都是NO.1,InfluxDB 统治 Time Series DBMS,Elasticsearch 制霸 Search engine,关于它们的原理和使用,各自都有非常详细的文档和资料,这里就不再赘述。
在时序数据方面,InfluxDB表现强劲,Elasticsearch在主要的指标上均远落于下风:
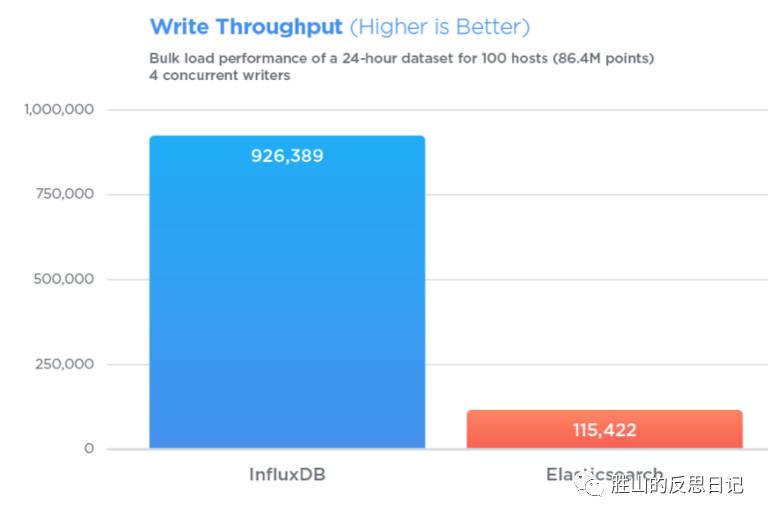
图7
- 数据写入
同时起4个进程写入8百64万条数据,Elasticsearch平均为 115,422 条/秒,InfluxDB平均 926,389 条/秒,写入速度是Elasticsearch的8倍。这种写入速度的差距随着数据量的增大保持相对一致。
- 磁盘存储
存储相同的8百64万条数据,使用默认配置的Elasticsearch需要2.1G,使用针对时序数据配置的Elasticsearch需要517MB,而InfluxDB只需要127MB,压缩率分别是前两者的16倍和4倍。
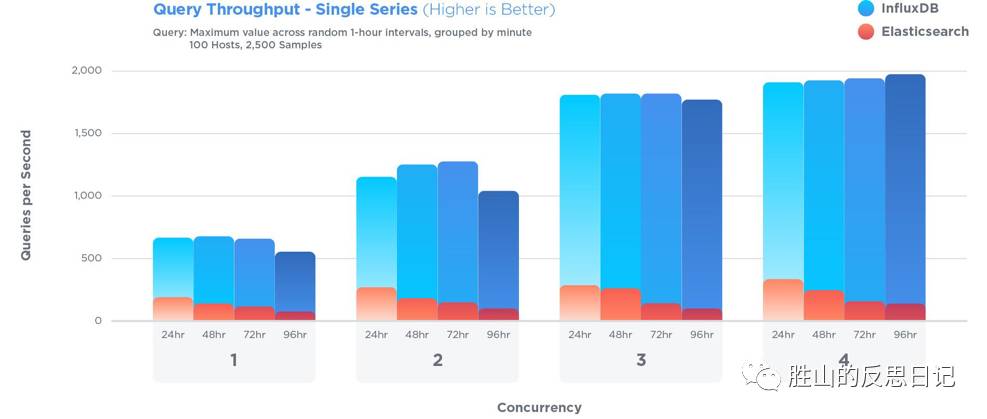
图8
图9
- 数据查询
在24h的数据集(8百64万条数据)里随机查询1个小时内的数据,按1分钟的时间间隔聚合,Elasticsearch和InfluxDB分别单进程执行1000次这种查询,算耗时的平均值。Elasticsearch耗时4.98ms(201次查询/秒),InfluxDB耗时1.26ms(794次查询/秒),查询速度是Elasticsearch的4倍。
随着数据集的增大,查询速度之间的差距逐渐拉大,最大相差10倍之多。而且随着执行查询的进程数增加,InfluxDB的查询速度增幅显著,而且在不同数据集之间的查询速度基本一致,但是Elasticsearch增幅就不大,而且随着数据集的增大查询速度是递减的。
详细的比较说明参见
InfluxDB Markedly Outperforms Elasticsearch in Time-Series Data & Metrics Benchmark:
https://www.influxdata.com/influxdb-markedly-elasticsearch-in-time-series-data-metrics-benchmark/
Elasticsearch强在全文搜索,InfluxDB擅长时序数据,所以还是具体需求具体分析。如果需要保存日 志并经常查询的,Elasticsearch比较合适;如果只依赖日志做状态展示,偶尔查询,InfluxDB比较合适。
业务各有特点,单一选择Elasticsearch或者InfluxDB都不能很好的查询日志和指标展示,所以有必要InfluxDB和Elasticsearch共存。
在 Logstash 里配置2个输出,同一条日志输出2份,一份保留全部字段输出至 Elasticsearch;另一份过滤文本性的字段保留指标性的字段,然后输出至 InfluxDB。
InfluxDB如果作为Logstash的输出,有个坑需要注意,就是Logstash的InfluxDB插件支持的时间戳精度太粗,不能精确到纳秒,会导致同一个值的时间戳在插入InfluxDB的时候出现异常。
因为InfluxDB用measurement名、tag集和时间戳来唯一标识一条记录。如果插入InfluxDB的一条记录与已经存在的一条记录 measurement名、tag集和时间戳都相同,那么filed会是新老两条记录的集合,相同field的值会被新记录覆盖。
解决方式有2种,一种是增加一个tag来标识新记录。另一种是手动提升时间戳的精度,提升至微秒,理论上每天可以支持86,400,000,000条不重复的日志,可以很大程度避免时间戳的重叠,配置如下图所示:
图10
六、数据展示
比较Kibana和Grafana,Kibana在图表展示上没有Grafana美观,而且Grafana的配置更加简单灵活。既然在日志存储中决定InfluxDB和Elasticsearch共存,展示上就也需要Kibana和Grafana共同协作,Kibana从Elasticsearch中检索日志,Grafana从InfluxDB和Elasticsearch中获取展示数据。
七、异常报警
即使上述6个环节都建立了,如果没有报警一切都是没有意义的,因为不可能每时每刻都盯着曲线看,所以需要设置异常阈值,让监控系统定时检查,发现异常立即发送报警通知。
报警的服务有很多,但是数据展示的Grafana自带报警功能,功能也能满足我们的报警需求,而且配置简单,所以规则简单的报警可以采用Grafana的报警服务。不过Grafana的报警只支持部分数据库,分别是Graphite, Prometheus, InfluxDB 和 OpenTSDB,所以在Elasticsearch中的日志报警还需要Elastic Stack的X-Pack。
Condition
如上图所示,可以设置报警检查的频率,报警条件是最近的5分钟内指定指标的平均值是否大于70,如果这个条件为True则触发报警。
这种报警条件还比较单一,像错误数在十分钟内超过几次才报警,当前订单数与昨天同一时间的订单数比较跌了超过百分之几就报警,控制报警通知发送的频率,等等,Grafana就不能满足了,针对这种报警规则我们自己实现了一个报警引擎,用来满足这些比较复杂的报警规则。
Notification
Grafana的报警通知只有在状态转换时才会触发,即报警状态的时候会发送告警通知,如果到恢复之前的一段时间里条件一直是满足报警条件的,Grafana不会一直发送通知,直到恢复的时候再发送一次恢复的通知。
Grafana的邮件配置很简单,可以利用QQ企业邮箱的smtp服务来发送报警邮件,邮件内容是配置的报警,配置比较简单:
[smtp]
enabled = true
host = smtp.exmail.qq.com:465
user = example@alert.com
password = ********
from_address = example@alert.com
from_user = Grafana
Webhook
Reception
配置了报警通知,不接收不去看也是白搭。一方面我们尽量实现多种通知途径,比如邮件、微信和短信。另一方面需要项目负责人接到报警及时响应,查看问题。
以上是关于智能日志系统建设最佳实践的主要内容,如果未能解决你的问题,请参考以下文章