python爬虫实战|京东商城评论
Posted 向阳-Y.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫实战|京东商城评论相关的知识,希望对你有一定的参考价值。
1.发现网址url规律
productid="100014438267"
def generate_urls(productid):
"""
获取每一页连接
productid:商品编号
sortType:排序方式,取值为5,6(默认排序和时间排序)
page:页码,由网页可知,从0开始
"""
urls=[]
template="https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={productid}&score=0&sortType={sortType}&page={page}&pageSize=10&isShadowSku=0&fold=1"
for sortType in [5,6]:
for page in range(0,100):
url=template.format(sortType=sortType,page=page,productid=productid)
urls.append(url)
return urls
urls=generate_urls(productid)
urls
输出部分截图:

2.拿到一个页面数据
import requests
def get_json(url):
headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400"}
resp=requests.get(url,headers=headers)
raw_json=resp.text
return raw_json
url="https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100014438267&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1"
raw_json=get_json(url)
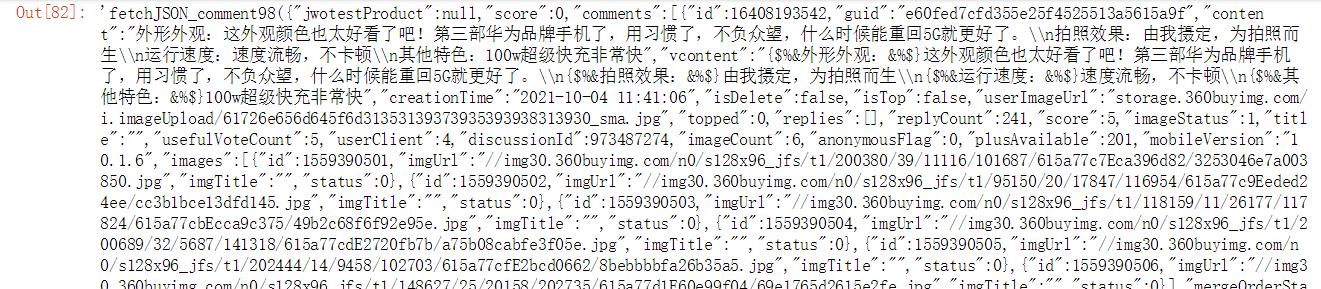
raw_json
输出部分截图:
3.数据解析
import json
def extract_comments(raw_json):
"""
从json数据(不规则,比较乱的json)清洗转换成comment数据列表(列表中每一个元素是一个字典)
raw_json:json原始数据
['comments']:筛选只来自comments的内容
[20:-2]:因为raw_json的开头和结尾包含了一些多余的数据
"""
comments=json.loads(raw_json[20:-2])['comments']
return comments
comments=extract_comments(raw_json)
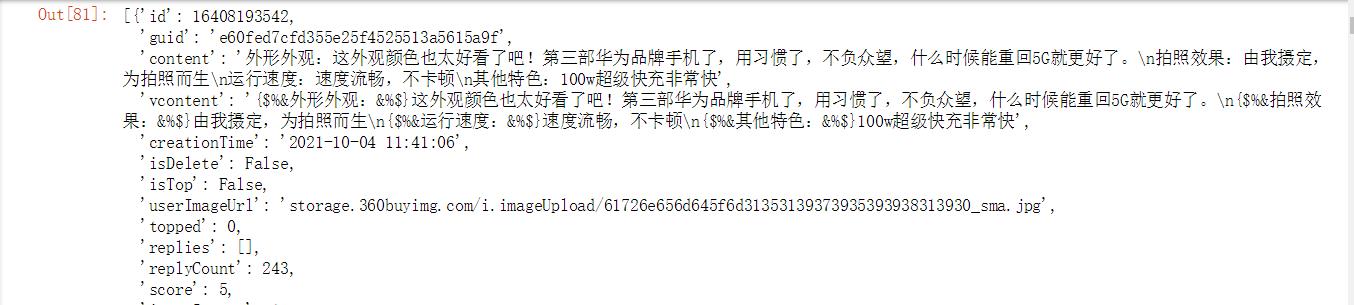
comments
输出部分截图:
4.存储数据
import csv
path="F:/papapa/data/jingdong.csv"
csvf=open(path,'a+',encoding='utf-8',newline='')
fieldnames=['content','referenceName']
writer=csv.DictWriter(csvf,fieldnames=fieldnames)
writer.writeheader()
#逐个写入csv
for comment in comments:
data={}
data['content']=comment.get('content')
data['referenceName']=comment.get('referenceName')
writer.writerow(data)
#关闭csv
csvf.close()
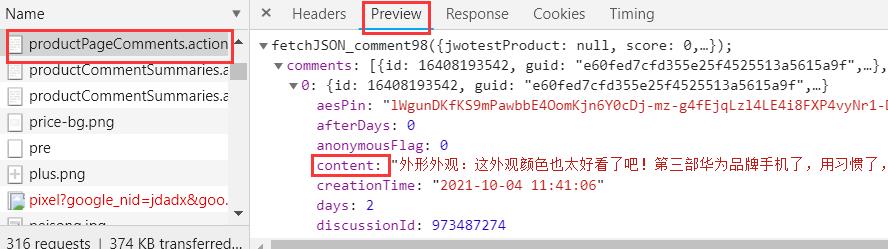
解析:
fieldnames中的字段为下图:
5.大功告成
from pyquery import PyQuery
import requests
import csv
import json
def generate_urls(productid):
"""
获取每一页连接
productid:商品编号
sortType:排序方式,取值为5,6(默认排序和时间排序)
page:页码,由网页可知,从0开始
"""
urls=[]
template="https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={productid}&score=0&sortType={sortType}&page={page}&pageSize=10&isShadowSku=0&fold=1"
for sortType in [5,6]:
for page in range(0,10):
url=template.format(sortType=sortType,page=page,productid=productid)
urls.append(url)
return urls
def get_json(url):
headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400"}
resp=requests.get(url,headers=headers)
raw_json=resp.text
return raw_json
def extract_comments(raw_json):
"""
从json数据(不规则,比较乱的json)清洗转换成comment数据列表(列表中每一个元素是一个字典)
raw_json:json原始数据
['comments']:筛选只来自comments的内容
[20:-2]:因为raw_json的开头和结尾包含了一些多余的数据
"""
comments=json.loads(raw_json[20:-2])['comments']
return comments
def clean_comment(comment):
data=dict()
data['content']=comment.get('content')
data['referenceName']=comment.get('referenceName')
return data
def main(productid,file):
print("开始采集")
#新建csv
csvf=open(file,'a+',encoding='utf-8',newline='')
fieldnames=['content','referenceName']
writer=csv.DictWriter(csvf,fieldnames=fieldnames)
writer.writeheader()
#生成productid产品所以评论urls
urls=generate_urls(productid)
for url in urls:
print('正在采集:{url}'.format(url=url))
#逐个访问拿到评论raw_json数据
raw_json=get_json(url)
#从row_json拿到评论字典
comments=extract_comments(raw_json)
for comment in comments:
data=clean_comment(comment)
writer.writerow(data)
#关闭csv
csvf.close()
print('采集完成!')
main(productid="100014438267",file="F:/papapa/data/jingdong.csv")
相关基础篇文章:
python爬虫实战一|大众点评网
csv存储数据代码步骤
快速入门Python爬虫|requests请求库|pyquery定位库
以上是关于python爬虫实战|京东商城评论的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(92):项目实战:抓取京东图书评价
Python爬虫编程思想(70): 项目实战--抓取京东商城手机销售排行榜