一只初学者级别的京东商城商品爬虫(爬取索尼微单的参数信息)
Posted reader-yu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一只初学者级别的京东商城商品爬虫(爬取索尼微单的参数信息)相关的知识,希望对你有一定的参考价值。
近期对摄影产生一些兴趣,所以就自己爬了一下京东商城上Canon微单的数据。爬虫爬取了商品价格以及详细参数信息。作为一个初学者,幸运或者不幸的是,由于爬虫性能较差,在以下的代码中我并没有用到反爬虫的问题,只熟悉Python下载与安装的朋友也可以放心食用这篇文章。
以下我记下了完整详细的爬虫制作过程,供新手朋友参考、高端玩家指正。
一、开发前的准备
开发环境:Python3.6+Jupyter notebook
爬取过程使用的库:requests+re+BeautifulSoup
数据存取以及清洗过程使用的库:pandas+matplotlib
对这些库不熟悉的可以查阅官方文档。搜索引擎搜一下就好。
另外,记得爬取前在浏览器输入https://www.jd.com/robots.txt查看爬虫协议。我们用的是requests库,这种爬虫很小,对网站很友好(一张网页一张网页的爬,效率低下),一般不会违法爬虫协议。
二、编写爬取某商品详细信息的函数
先附代码证明我不是在骗人。另外相信有经验的伙伴应该能感觉到这段代码的性能似乎有些问题。代码后是详细的分析过程。
1 import requests 2 from bs4 import BeautifulSoup 3 import re 4 5 def get_canon_details(uid): 6 ‘‘‘函数返回一个列表,各数据依次为[‘价格‘, ‘上市时间‘,‘商品产地‘, ‘类型‘, 7 ‘商品毛重(kg)‘, ‘画幅‘, ‘用途‘, ‘品牌‘, ‘型号‘, ‘机身重量(g)‘, ‘尺寸(mm)‘, 8 ‘有效像素‘, ‘传感器类型‘, ‘传感器尺寸‘, ‘对焦系统‘, ‘高清摄像‘, ‘语言‘, ‘液晶屏尺寸‘, 9 ‘液晶屏像素‘, ‘液晶屏类型‘, ‘取景器类型‘, ‘滤镜直径‘, ‘最大光圈‘, ‘白平衡模式‘, ‘ISO感光度‘, 10 ‘场景模式‘, ‘机身闪光灯‘, ‘外接闪光灯‘, ‘自拍‘, ‘连拍速度‘, ‘机身防抖‘, ‘延时拍摄‘, 11 ‘遥控拍摄‘, ‘存储介质‘, ‘机身内存‘, ‘WiFi连接‘, ‘NFC‘, ‘蓝牙传输‘, ‘HDMI接口‘, ‘其它接口‘, 12 ‘电池型号‘, ‘电池类型‘, ‘电池续航时间‘, ‘外接电源‘]:‘‘‘ 13 #根据网页URL获得对应商品的UID并尽可能抓取信息。此处仅得到商品的品牌信息 14 #测试用例为url = "https://item.jd.com/4691332.html?dist=jd" 15 16 #获取商品的价格 https://p.3.cn/prices/mgets?callback=jQuery8921309&type=1&area=1_72_2799_0&pdtk=&pduid=1532358136269191914663&pdpin=&pin=null&pdbp=0&skuIds=J_"+uid 18 price_text = requests.get(price_url) 19 PRICE = eval(re.compile(‘p":"(.*?)"‘).findall(price_text.text)[1]) 20 21 #获取商品参数信息 22 introduction_url = "https://item.jd.com/"+uid+".html?dist=jd" 23 introduction = requests.get(introduction_url) 24 introduction = BeautifulSoup(introduction.text,‘lxml‘) 25 parameter = [] 26 for k in range(0,len(introduction.find_all(‘dt‘,class_ = None))): 27 if introduction.find_all(‘dt‘,class_ = None)[k].i == None: 28 parameter.append(introduction.find_all(‘dt‘,class_=None)[k].text) 29 30 value = [] 31 for k in range(0,len(introduction.find_all(‘dd‘,class_ = None))): 32 if introduction.find_all(‘dd‘,class_=None)[k].a == None: 33 value.append(introduction.find_all(‘dd‘,class_=None)[k].text) 34 value = value[:len(parameter)-len(value)] 35 Para_Val = dict() 36 for i,j in zip(parameter,value): 37 Para_Val[i] = j 38 39 Para_Val[‘价格‘] = PRICE 40 ANSER = [] 41 for i in[‘价格‘, ‘上市时间‘,‘商品产地‘, ‘类型‘, ‘商品毛重(kg)‘, ‘画幅‘, ‘用途‘, ‘品牌‘, ‘型号‘, ‘机身重量(g)‘, ‘尺寸(mm)‘, ‘有效像素‘, ‘传感器类型‘, ‘传感器尺寸‘, ‘对焦系统‘, ‘高清摄像‘, ‘语言‘, ‘液晶屏尺寸‘, ‘液晶屏像素‘, ‘液晶屏类型‘, ‘取景器类型‘, ‘滤镜直径‘, ‘最大光圈‘, ‘白平衡模式‘, ‘ISO感光度‘, ‘场景模式‘, ‘机身闪光灯‘, ‘外接闪光灯‘, ‘自拍‘, ‘连拍速度‘, ‘机身防抖‘, ‘延时拍摄‘, ‘遥控拍摄‘, ‘存储介质‘, ‘机身内存‘, ‘WiFi连接‘, ‘NFC‘, ‘蓝牙传输‘, ‘HDMI接口‘, ‘其它接口‘, ‘电池型号‘, ‘电池类型‘, ‘电池续航时间‘, ‘外接电源‘]: 42 if i in Para_Val: 43 ANSER.append(Para_Val[i]) 44 else: 45 ANSER.append(None) 46 return ANSER
首先明确这一阶段的目标。我希望可以获取京东商城上某一个商品的详细信息,包括相机的价格以及详细参数(参见代码中三引号里的内容)。完成这个过程后,再将它包装成一个函数。
2.1、获取商品价格信息。
首先分析一下京东售卖页面的结构。在Chrome中打开京东,搜索微单,点进某一个具体商品的页面。按F12进入开发者模式。之后的操作见以下的GIF。
这是我们发现价格在网页源码中对应的部分后面有“== $ 0”,不祥的预感在我心头萦绕。果然,价格信息使用的方式是异步加载,也就是说,利用requests库获得的url为"https://item.jd.com/4691332.html?dist=jd"中,并不含有我们所需要的价格信息,价格信息隐藏在另外一个url里。如何找到这个url呢?看下面这个动图。
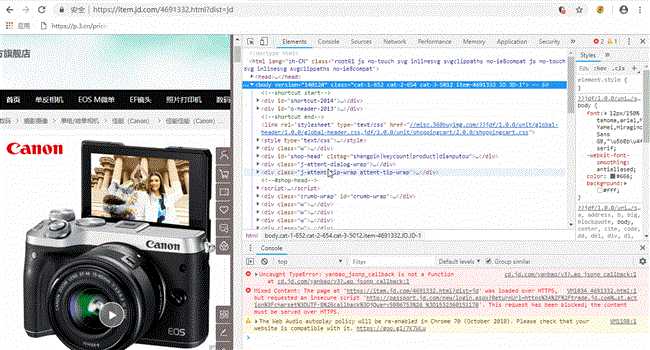
这时需要一点耐心,输入3399并搜索(动图中输入框里直接有3399,是因为我之前输入过),在结果中找到价格存放的真正位置。就是动图最后我要复制的部分。url为:https://p.3.cn/prices/mgets?callback=jQuery6781865&type=1&area=1&pdtk=&pduid=1532358136269191914663&pdpin=&pin=null&pdbp=0&skuIds=J_4691332%2CJ_1596435%2CJ_4843047%2CJ_4682641%2CJ_1070080%2CJ_7361135%2CJ_1225383%2CJ_3576104%2CJ_5268940%2CJ_2342146&ext=11100000&source=item-pc
有点长,可见应当是可以删去一部分修饰的。注意到商品网址里有一串数字“4691332”,可以猜测这段数字是和商品一一对应的,所以而上面这段代码也有“4691332”,那么这串字符后面的都删掉。得到url:"https://p.3.cn/prices/mgets?callback=jQuery8921309&type=1&area=1_72_2799_0&pdtk=&pduid=1532358136269191914663&pdpin=&pin=null&pdbp=0&skuIds=J_4691332"。输入浏览器里看一眼,确实有价格信息。怎么取出来呢?先用requests库的get方法获得这个url里的信息并且存入price_text中,再用.text取出price_text中的文本信息,最后用正则表达式匹配出价格,再用eval函数把价格数据类型由字符型改为数值型即可。对应代码在第16~19行。
2.2、获取商品的参数信息。
用上面第二张动图类似的方法,在输入框输入“基本参数”并搜索,找到商品详细参数对应的url:"https://item.jd.com/4691332.html?dist=jd"。用requests.get把它的信息读下来,再用BeautifulSoup把它整理一下并存入变量introduction中。在jupyter中看一看结果。看图:↓↓↓可以认为<dt>标签里存放参数名称,<dd>标签里存放参数值。
考验BeautifulSoup技能熟练度的时刻到了,不会的去查文档哈,好像中文版挺多的。
这里我们遇到的麻烦在于,<dt>标签包含的不仅只有参数名称,还有其它乱七八糟的东西。我的解决方法是加限制限制要找的信息必须满足没有class且不含<i>标签;对<dd>要麻烦一丢丢,限制不含class且不含<a>标签后,发现最后总是有一项多余数据在列表尾部,将最后一项去除。这时我们就可以得到两个列表,我把它们拼成字典。(“这样一来取用比较方便,只需要规定键的列表,就可以规定得到返回值的顺序”)
2.3把上面的内容整理成函数。
经过上面两个步骤,函数主体成型了。输入参数选择什么呢?我们回顾一下用到的两个url:
‘https://item.jd.com/4691332.html?dist=jd‘
‘https://p.3.cn/prices/mgets?callback=jQuery8921309&type=1&area=1_72_2799_0&pdtk=&pduid=1532358136269191914663&pdpin=&pin=null&pdbp=0&skuIds=J_4691332‘
稍微测试就可以发现,对于别的商品,只要将上面两个url中的数字串改成商品对应的数字串,就能得到对应结果。因此我们选择输入参数为该数字串,命名为uid。至此,我们就完成了根据商品uid获取商品价格及参数信息的函数。只需要再获取大量的商品url(或uid),就可以大量爬取商品详细信息。
三、批量获取商品url
在京东上搜索佳能微单,发现有47页的商品,用下面的代码批量爬下来~
1 import requests 2 import re 3 from bs4 import BeautifulSoup 4 from get_details import get_canon_details 5 def get_canon_url(k): 6 res = requests.get("https://list.jd.com/list.html?cat=652,654,5012&ev=exbrand_8983&page="+str(k)) 7 soup = BeautifulSoup(res.text,‘lxml‘) 8 url_set = set() 9 for i in range(1,len(soup.find_all("ul",class_ ="gl-warp clearfix")[0].select(‘a[target]‘))): 10 url_set.add(soup.find_all("ul",class_ ="gl-warp clearfix")[0].select(‘a[target]‘)[i].get(‘href‘)) 11 return list(url_set) 12 13 url_list = [] 14 for k in range(1,48): 15 url_list.extend(get_canon_url(k))
用这段代码,跑一会等结果。中间还可以打个小游戏啥的。不详细解释了,思路和用到的方法都跟上面差不多。(主要是博主写累了233)
四、爬取并存盘
全部怕下来之前,先看看效率。如下图,效率很低。两千多条数据全部下载大概需要两个小时。可以通过改读入的url_list长度改变下载数据的数目。
1 %%time 2 3 camera = [] 4 for item in url_list[1:10]: 5 uid = re.compile(".com/(.*?).html").findall(item) 6 if uid: 7 all_information = [item] 8 all_information.extend(get_canon_details(uid[0])) 9 camera.append(all_information) 10 else: 11 continue 12 13 #Wall time: 25.6 s
接下来要把文件下载到本地,不然每次都爬实在太麻烦。代码:
1 import pandas 2 df = pandas.DataFrame(camera,columns = [‘网址‘,‘价格‘, ‘上市时间‘,‘商品产地‘, ‘类型‘, ‘商品毛重(kg)‘, ‘画幅‘, ‘用途‘, ‘品牌‘, ‘型号‘, ‘机身重量(g)‘, ‘尺寸(mm)‘, ‘有效像素‘, ‘传感器类型‘, ‘传感器尺寸‘, ‘对焦系统‘, ‘高清摄像‘, ‘语言‘, ‘液晶屏尺寸‘, ‘液晶屏像素‘, ‘液晶屏类型‘, ‘取景器类型‘, ‘滤镜直径‘, ‘最大光圈‘, ‘白平衡模式‘, ‘ISO感光度‘, ‘场景模式‘, ‘机身闪光灯‘, ‘外接闪光灯‘, ‘自拍‘, ‘连拍速度‘, ‘机身防抖‘, ‘延时拍摄‘, ‘遥控拍摄‘, ‘存储介质‘, ‘机身内存‘, ‘WiFi连接‘, ‘NFC‘, ‘蓝牙传输‘, ‘HDMI接口‘, ‘其它接口‘, ‘电池型号‘, ‘电池类型‘, ‘电池续航时间‘, ‘外接电源‘]) 3 df["网址"]="https:"+df["网址"] 4 5 df = df[df["价格"]>1000] 6 #之所以加这一条,是因为京东页面里会有大量的配件(价格一般小于1000)我们把它去掉 7 8 df.to_excel("camera.xlsx", merge_cells=False)
五、基本的数据整理
现在我们从下载的本地文件里读入数据:
# -*- coding=gbk -*- import matplotlib.pyplot as plt import numpy as np import pandas as pd data = pd.read_csv("camera.csv",engine=‘python‘) del data["Unnamed: 0"]
画价格分布图:
1 %matplotlib inline 2 import matplotlib.pyplot as plt 3 from pylab import * 4 mpl.rcParams[‘font.sans-serif‘] = [‘SimHei‘] 5 fig = plt.figure() 6 price = fig.add_subplot(111) 7 price.hist(data[data["价格"]<10000]["价格"]) 8 plt.xlabel("价格") 9 plt.ylabel("数目") 10 plt.title("CANON万元以下微单价格分布图(数据来源:京东)")
将像素数据改为数值型并处理缺失值:(这里弹出一个警告,博主没有能够解决)
1 import re 2 for i in range(0,len(data["有效像素"])): 3 if type(data["有效像素"][i]) == str: 4 if len(re.findall("d+",data["有效像素"][i])): 5 data["有效像素"][i] = eval(re.findall("d+",data["有效像素"][i])[0]) 6 else: 7 data["有效像素"][i] = 0
好啦,我我爬取京东微单的经历和经验就分享到这里,希望一起入坑Python的朋友能看的顺利,一起加油吧!
以上是关于一只初学者级别的京东商城商品爬虫(爬取索尼微单的参数信息)的主要内容,如果未能解决你的问题,请参考以下文章