spark安装
Posted 慕铭yikm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark安装相关的知识,希望对你有一定的参考价值。
目录
spark安装
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
前言
在部署完hadoop集群后,再安装scala与spark
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
资料链接
链接:https://pan.baidu.com/s/1ytGL3cLGQxGltl5bHrSBQQ
提取码:yikm
安装scala
创建scala工作目录
mkdir -p /usr/scala/
tar -xvf /usr/package/scala-2.11.12.tgz -C /usr/scala/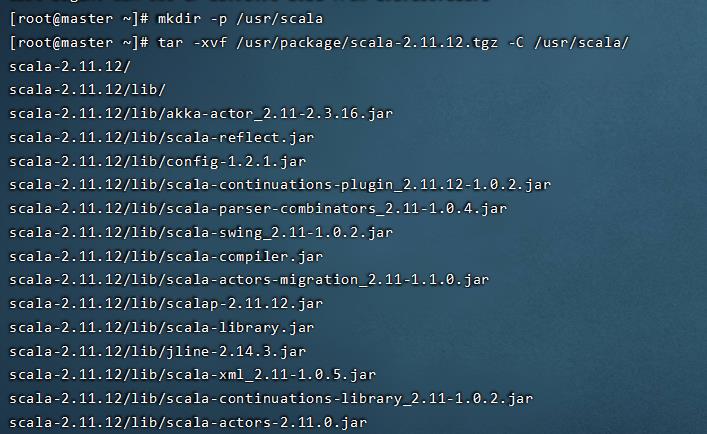
配置环境变量(三台机器)
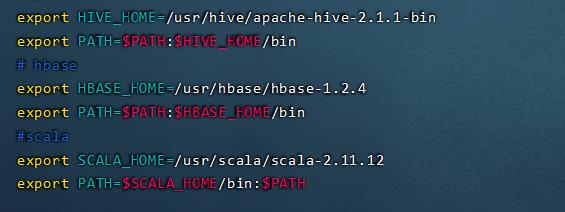
vim /etc/profile添加以下内容:
#scala
export SCALA_HOME=/usr/scala/scala-2.11.12
export PATH=$SCALA_HOME/bin:$PATH
生效环境变量
source /etc/profile

查看是否安装成功
scala -version
分发到节点
scp -r /usr/scala/ root@slave1:/usr/
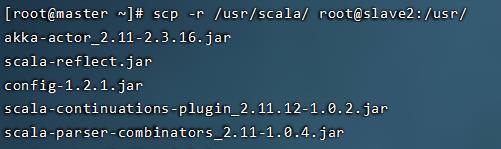
scp -r /usr/scala/ root@slave2:/usr/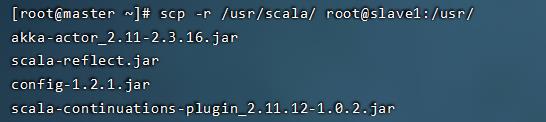
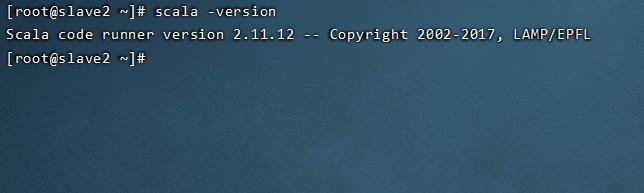
验证
scala -version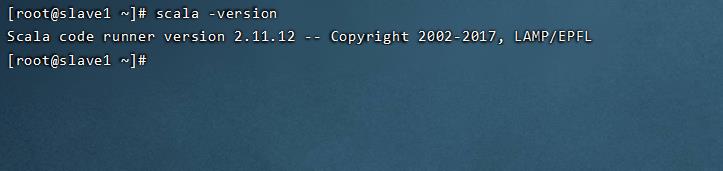
安装spark
创建spark工作目录
mkdir -p /usr/spark
tar -zxvf /usr/package/spark-2.4.0-bin-hadoop2.7.tgz -C /usr/spark/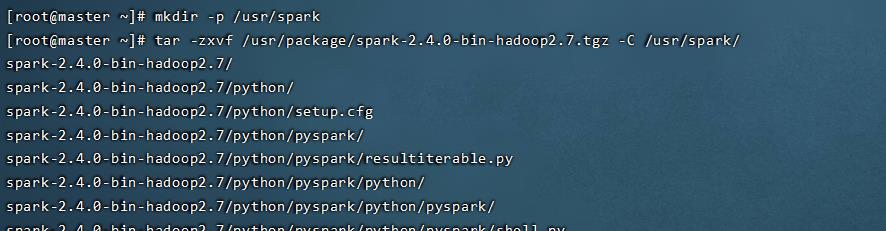
编辑spark-env.sh
cd /usr/spark/spark-2.4.0-bin-hadoop2.7/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh

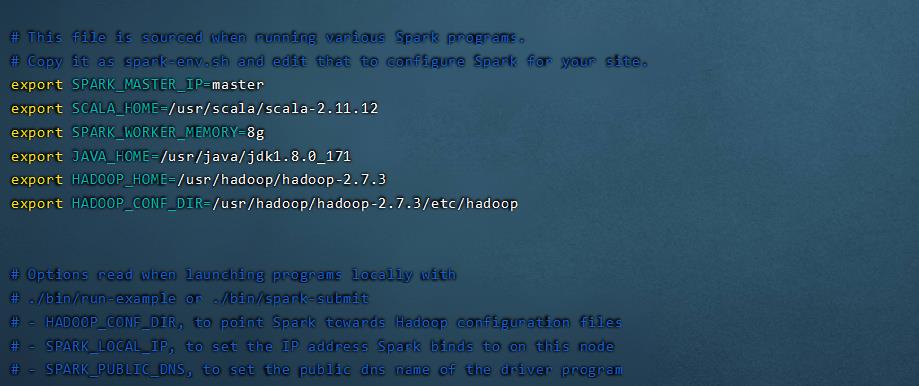
添加以下内容:
export SPARK_MASTER_IP=master
export SCALA_HOME=/usr/scala/scala-2.11.12
export SPARK_WORKER_MEMORY=8g
export JAVA_HOME=/usr/java/jdk1.8.0_171
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.3/etc/hadoop
配置spark从节点
mv slaves.template slaves
vim slaves

修改localhost:
slave1
slave2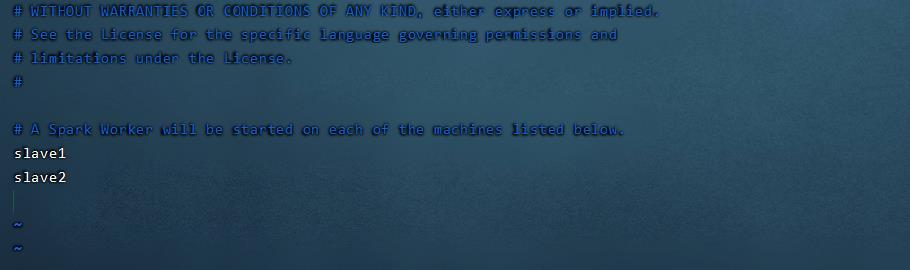
配置环境变量(三台机器)
vim /etc/profile
添加以下内容:
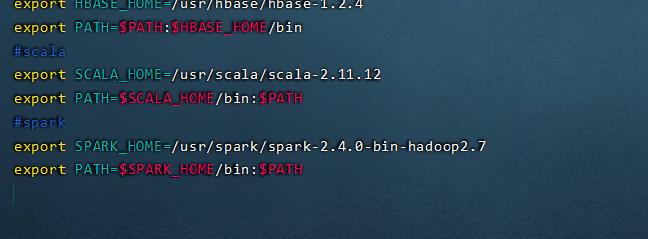
#spark
export SPARK_HOME=/usr/spark/spark-2.4.0-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
生效环境变量
source /etc/profile
分发到节点
scp -r /usr/spark/ root@slave1:/usr/
scp -r /usr/spark/ root@slave2:/usr/
测试运行环境(只在master节点执行)
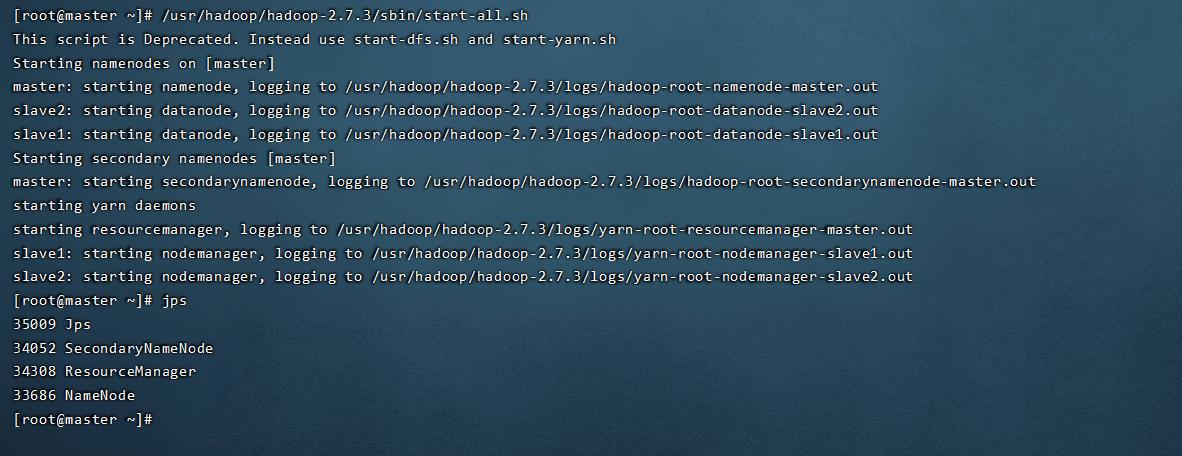
启动hadoop
/usr/hadoop/hadoop-2.7.3/sbin/start-all.sh
启动spark集群
/usr/spark/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh

jps查看进程



访问spark web界面
192.168.111.3:8080 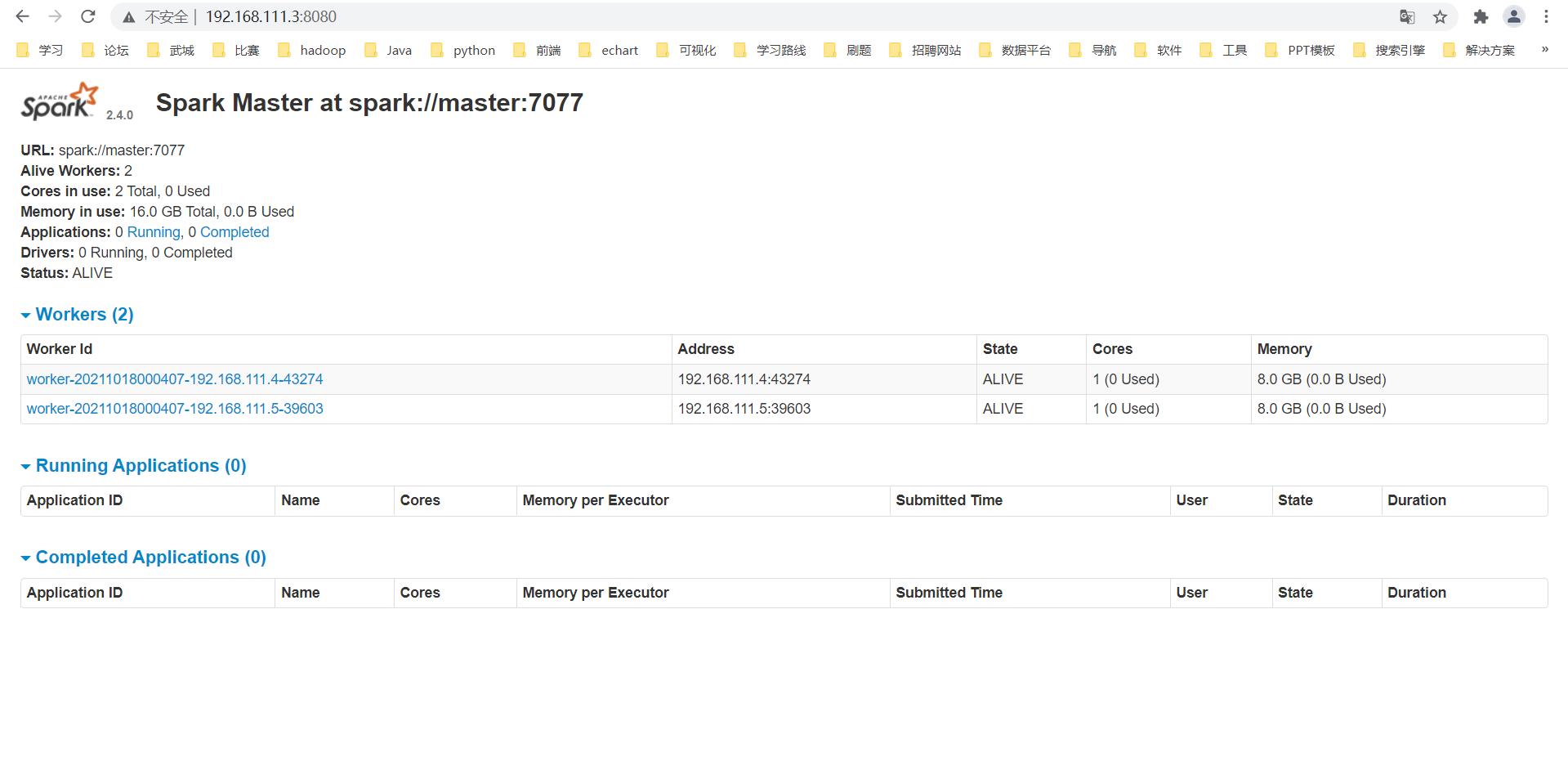
开启spark-shell
spark-shell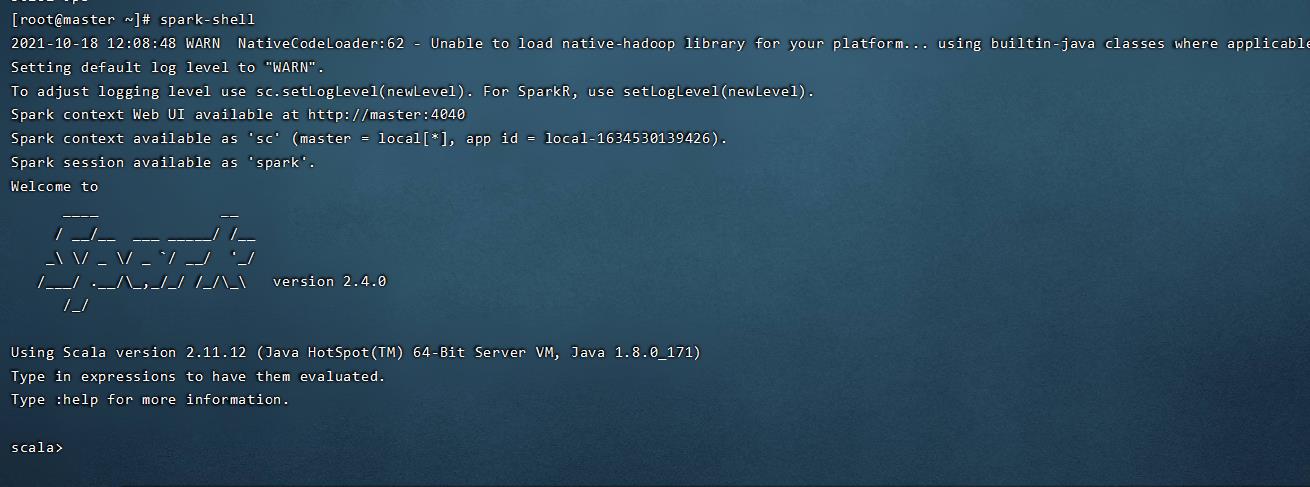
输入以下命令测试:
println("Hello world")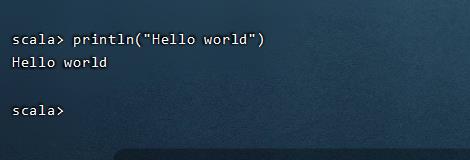
输入pyspark测试python环境spark交互模式
pyspark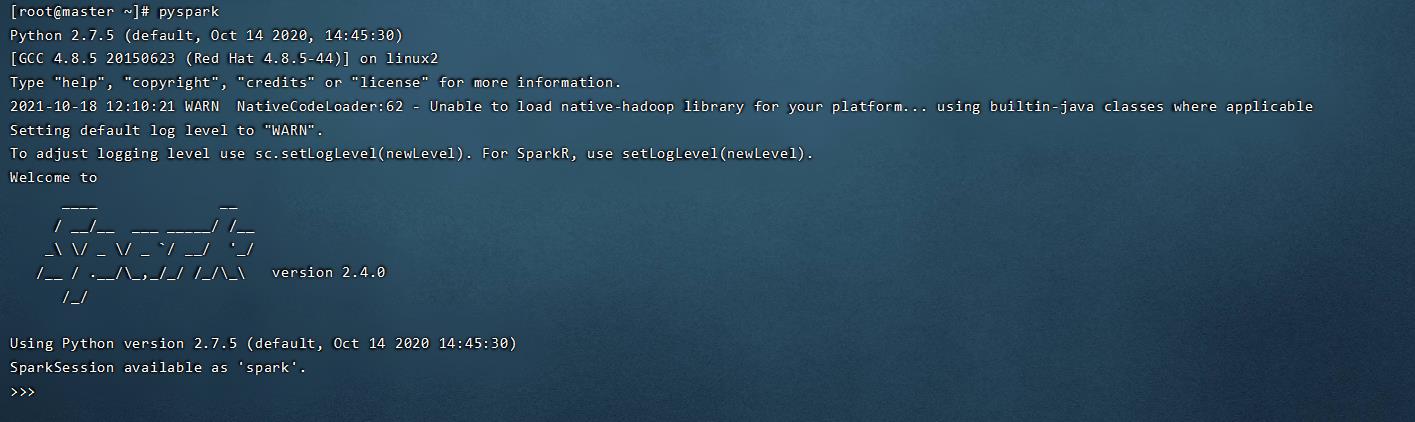
输入命令测试:
print("Hello world")
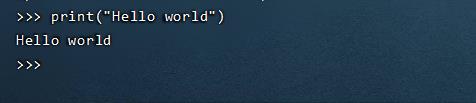
输入quit()可退出

以上是关于spark安装的主要内容,如果未能解决你的问题,请参考以下文章
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)(代码片段