集群安装搭建赛题解析
Posted 慕铭yikm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集群安装搭建赛题解析相关的知识,希望对你有一定的参考价值。
系列文章目录
目录
集群安装搭建赛题解析
前言
根据“红亚杯”-大数据环境搭建与数据采集技能线上专题赛以及鈴音.博主文章结合整理,附上资料链接。
在此鸣谢
资料链接
链接:https://pan.baidu.com/s/1ytGL3cLGQxGltl5bHrSBQQ
提取码:yikm
VMware虚拟机练习配置
创建三台虚拟机
配置如下

可以选择最小化安装
(最小化安装如果要使用vim和ifconfig命令需要进行安装)
yum -y install vim*
yum -y install net-tools.x86_64
开启ens33

配置静态ip

修改网络服务设置
vim /etc/sysconfig/network-scripts/ifcfg-ens33 
在此基础上修改
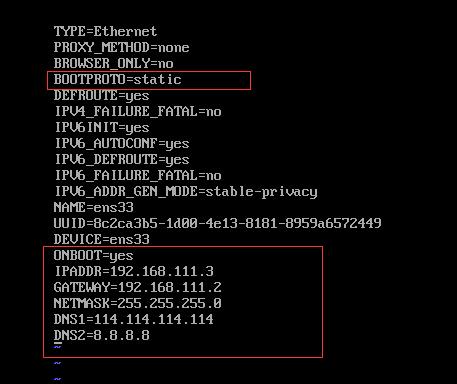
:wq保存退出
重启网卡
service network restart 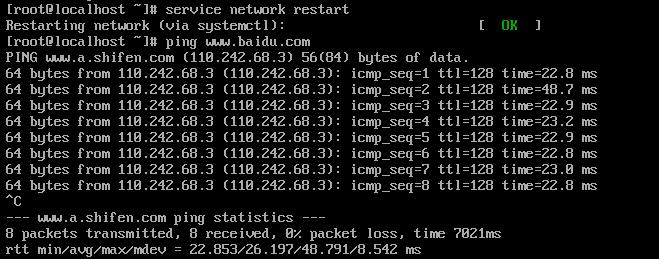
查看网络状态
ifconfig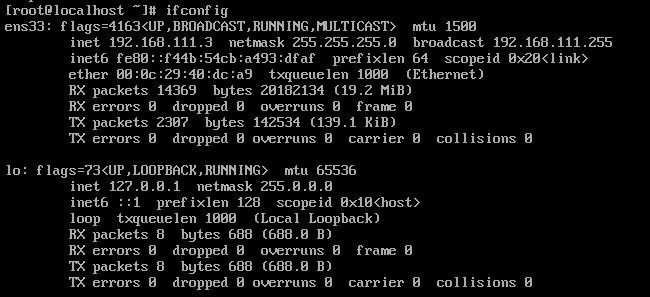
克隆出两台机器,并修改ip地址
192.168.111.4,192.168.111.5
用远程工具进行连接,博主用的是finalshell强烈安利
下载地址:SSH工具 客户端
将准备好的package传入虚拟机中,链接在文章最前面!
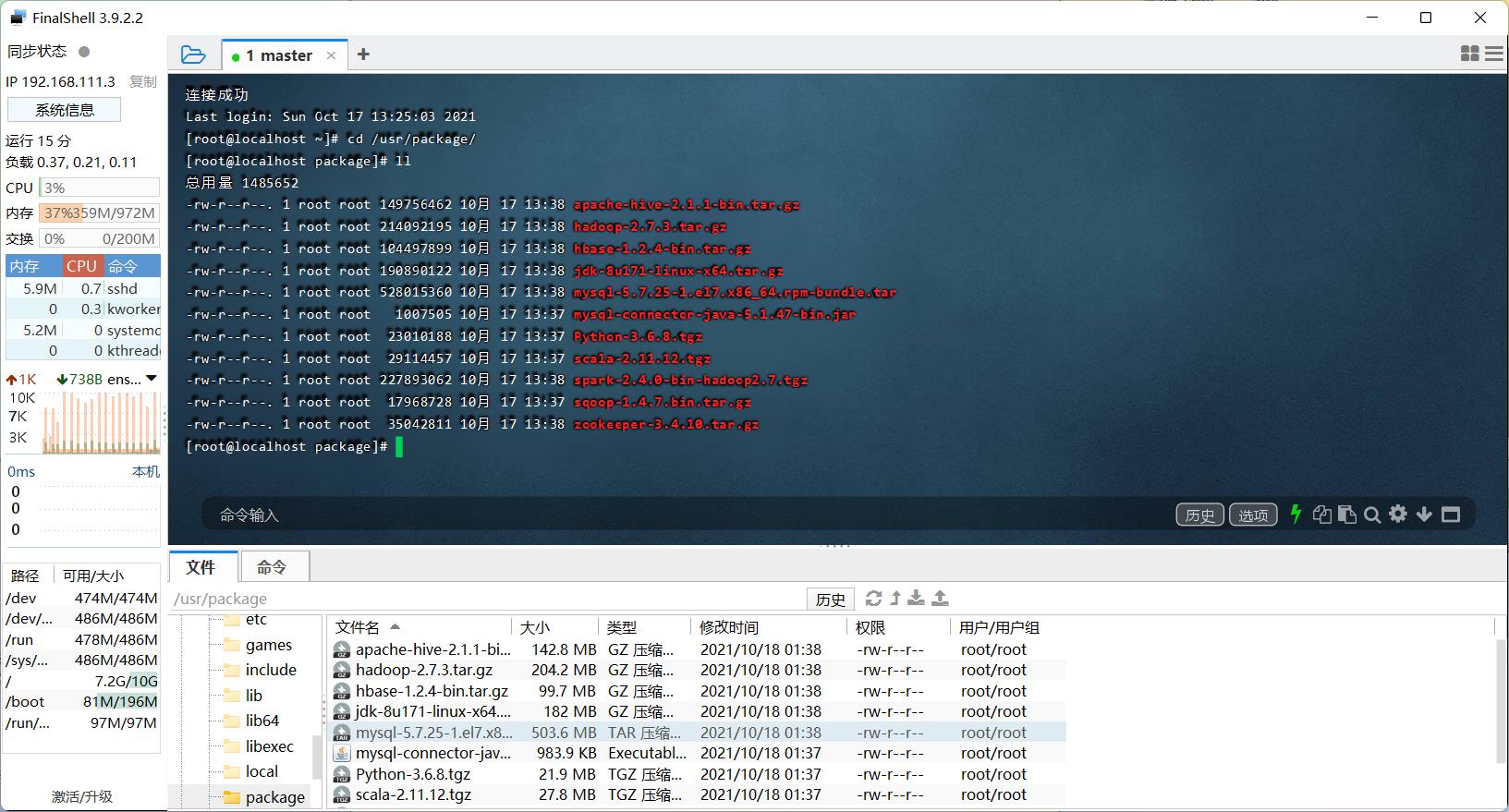
准备就绪,开搞开搞!
训练时一定要多拍快照防止出错!!!
配置本地YUM源
Centos自带的YUM源更新太慢,可以使用更改本地源的方法来安装软件。
我们通常使用 yum install 命令来在线安装 linux系统的软件, 这种方式可以自动处理依赖性关系,并且一次安装所有依赖的软体包。
yum的配置文件在 /etc/yum.repos.d 目录下, 其中有多个配置文件,每一个配置文件中都可以配置一个或多个 repository。
yum仓库就是使用yum命令下载软件的镜像地址。国内的仓库可以使用阿里源、163、清华大学等

配置本地源:通过比赛平台提供源文件下载路径,将本地源文件下载到/etc/yum.repos.d/目录下(三台机器都执行)。
-
发信号给yum进程:pkill -9 yum
-
进入yum源配置文件:cd /etc/yum.repos.d
-
删除所有文件:rm -rf *
-
下载yum源:wget http://xxxx/bigdata/repofile/bigdata.repo
-
清除YUM缓存:yum clean all

基础环境配置(20 / 20分)
1.修改主机名,便于识别节点;
2.工具包已保存在环境中;
3.修改hosts文件,添加集群节点映射,按照给出的节点IP和对应的主机名进行设置;
4.要求各节点时区修改为中国时区( 中国标准时间CST+8)
5.安装ntp服务,要求主节点master为本地时钟源,从节点设置定时任务同步本地时间;
6.集群中数据传输需要节点之间免密访问,要求设置主节点之间到从节点的免密访问;
7.Hadoop技术基于Java语言,要求本地源下载对应安装包进行安装配置,注意安装路径要求,无需更改文件名,注意添加环境变量。
考核条件如下:
主机名
1. 修改主机名(分别为master、slave1、slave2,临时生效即可,无需重启环境)(1.00 / 1分)
操作环境: master、slave1、slave2
hostnamectl set-hostname master
bash
防火墙
2. 判断是否关闭防火墙(1.00 / 1分)
操作环境: master、slave1、slave2
systemctl status firewalld
systemctl stop firewalld
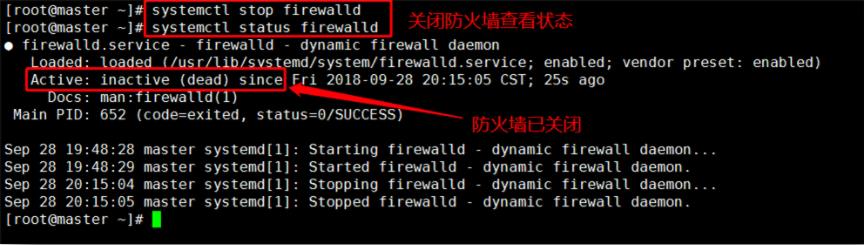
永久关闭防火墙和selinux
systemctl disable firewalld
vim /etc/sysconfig/selinux


IP映射
3. hosts文件添加映射(内网IP)(1.00 / 1分)
操作环境: master、slave1、slave2
vim /etc/hosts 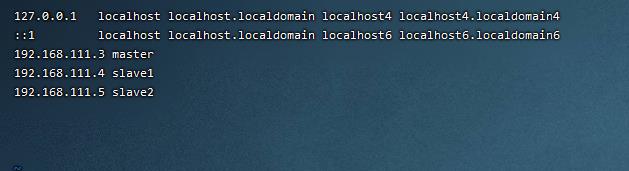
ping一下测试

时区同步
4. 时区更改(中国时区)(1.00 / 1分)
操作环境: master、slave1、slave2
tzselect 依次输入5911
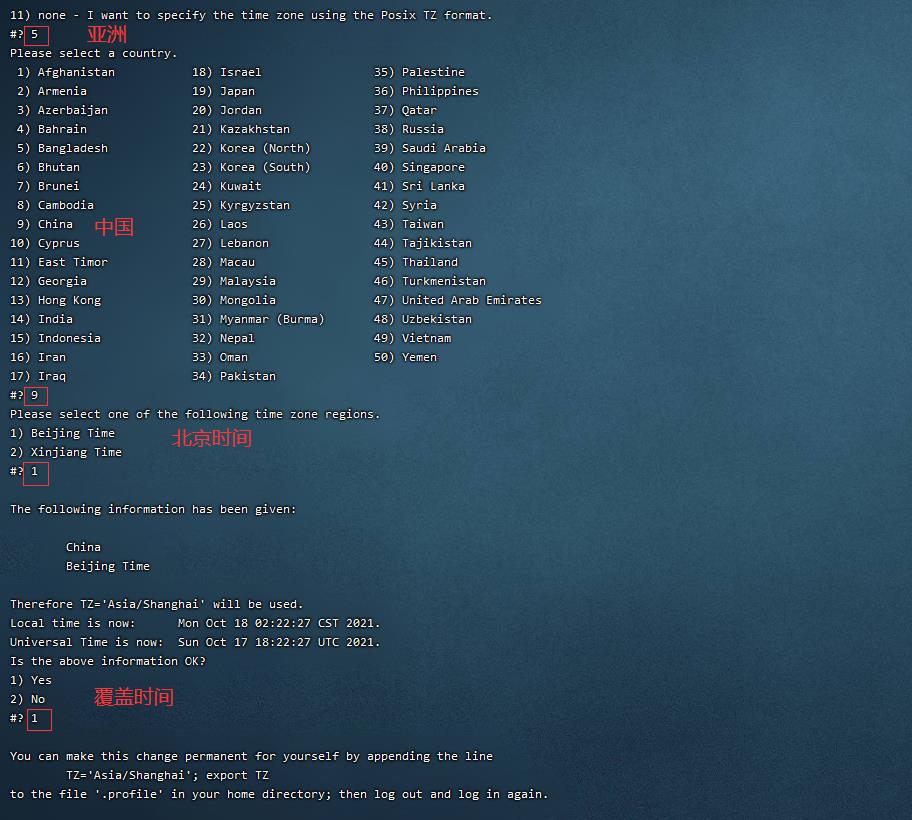
tzselect只是帮我们把选择的时区显示出来,并不会实际生效,也就是说它仅仅告诉我们怎么样去设置环境变量TZ。
如果要永久更改时区,按照tzselect命令提示的信息,在.profile或者/etc/profile中设置正确的TZ环境变量并生效。
设置TZ环境变量:TZ='Asia/Shanghai'; “export TZ
输入:
echo "TZ='Asia/Shanghai'; export TZ" >> /etc/profile && source /etc/profile
查看时间:
date 
NTP同步
NTP(Network Time Protocol,网络时间协议)是用来使网络中的各个计算机时间同步的一种协议。 NTP服务器就是利用NTP协议提供时间同步服务的。
ntp软件(支持ntp协议) CentOS6自带CentOS7需要安装的。图中,可以看到有一个服务器作为时钟源,其他主机去同步服务器上的时间。
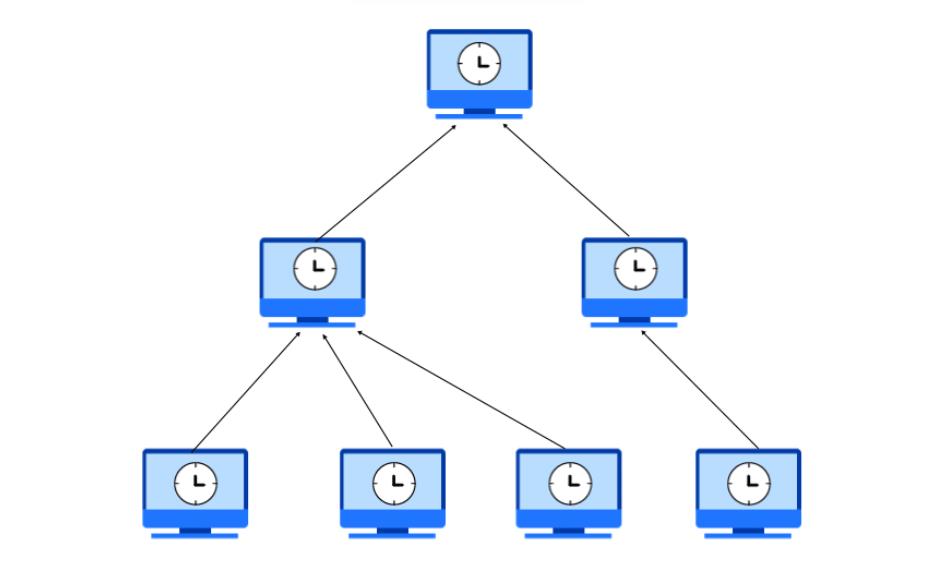
5. 确认NTP服务(1.00 / 1分)
操作环境: master、slave1、slave2
下载ntp服务:
yum -y install ntp 
6. 屏蔽默认server,设置master为本地时钟源,服务器层级设为10(1.00 / 1分)
操作环境: master
vim /etc/ntp.conf 在最后一行加入
server 127.127.1.0
fudge 127.127.1.0 stratum 10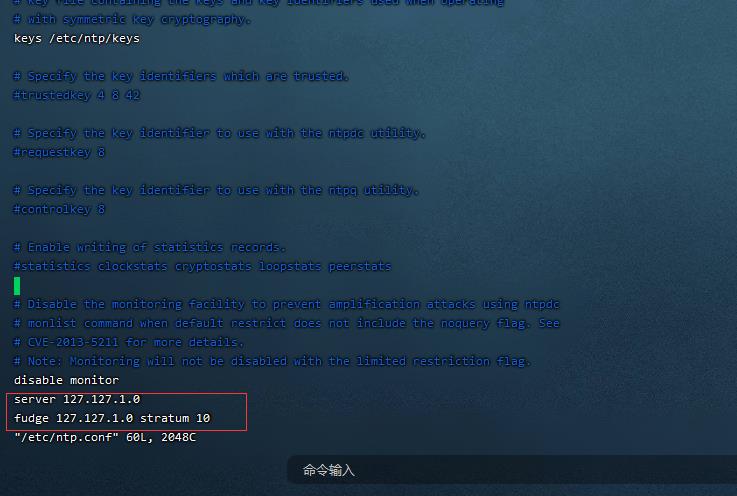
7. 主节点开启NTP服务(1.00 / 1分)
操作环境: master
/bin/systemctl restart ntpd.service

slaves手动同步时间(slave1,slave2上 ):
ntpdate master
定时任务
crontab是用来定期执行程序的命令
星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。
逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。

8. 从节点在早十-晚五时间段内每隔半个小时同步一次主节点时间(24小时制、用户root任务调度crontab)(1.00 / 1分)
操作环境: slave1、slave2
写一个定时任务:crontab -e
键入 i ,进入编辑模式
输入内容:
*/30 10-17 * * * usr/sbin/ntpdate master
查看定时任务列表:crontab -l

远程登录ssh
RSA 即可作为数字签名,也可以作为加密算法(未被完全攻破、暴力破解)。
DSA 只能用于数字签名,而无法用于加密(某些扩展可以支持加密);
RSA 与 DSA 都是非对称加密算法,相同密钥长度RSA算法和DSA算法安全性相当。
RSA or DSA, this is a question!
Master节点要把自身的公钥拷贝到自身的authorized_keys中。
目的:将 .ssh/id_rsa.pub放到其他机器上的authorized_keys中。
注意:如果是非root用户,需要修改文件权限 chmod 600 ~/.ssh/authorized_keys
ssh-keygen
一直回车即可
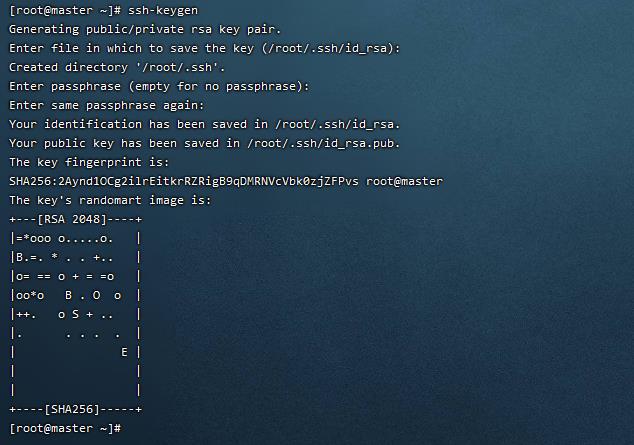
什么是authorized_keys : authorized_keys是linux操作系统下,专门用来存放公钥的地方,只要公钥放到了服务器的正确位置,并且拥有正确的权限,你才可以通过你的私钥,免密登录linux服务器。
将.ssh/id_rsa. pub中的公钥存到authorized_keys 中:
cd .ssh
ls
cat id_rsa.pub >> authorized_keys
ssh-copy-id localhost
9. 实现主机自身localhost免密访问(内回环)(2.00 / 2分)
操作环境: master
ssh localhost
10. 主节点生成公钥文件(数字签名RSA,用户root,主机名master)(1.00 / 1分)
操作环境: master
11. 实现master对slave1的免密登陆(2.00 / 2分)
操作环境: master
scp -r .ssh root@slave1:~/
ssh slave1
exit 

12. 实现master到slave2的免密访问(2.00 / 2分)
操作环境: master
scp -r .ssh root@slave2:~/
ssh slave2
exitJava环境配置
13. 将jdk安装包解压到/usr/java目录(安装包存放于/usr/package/,解压后路径不做修改,默认为/usr/java/jdk1.8.0_171,其他安装同理)(2.00 / 2分)
操作环境: master、slave1、slave2
mkdir -p /usr/java
tar -zxvf /usr/package/jdk-8u171-linux-x64.tar.gz -C /usr/java/

14. /etc/profile中配置JAVA系统环境变量($JAVA_HOME)(1.00 / 1分)
操作环境: master、slave1、slave2
vim /etc/profile在其中加入:
#java
export JAVA_HOME=/usr/java/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin

生效环境变量
source /etc/profile

15. 验证jdk是否安装成功(2.00 / 2分)
操作环境: master、slave1、slave2
scp -r /usr/java/ root@slave1:/usr/
scp -r /usr/java/ root@slave2:/usr/
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/
java -version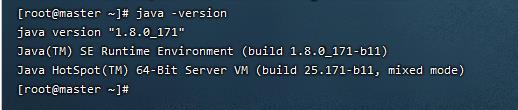
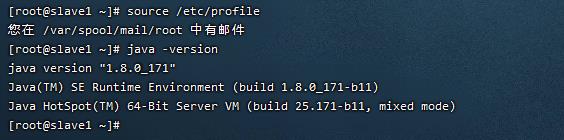
安装完jdk后jdk版本和自己安装的不一样
请看这篇博文,相信你能解决问题!
安装完jdk后jdk版本和自己安装的不一样怎么办?
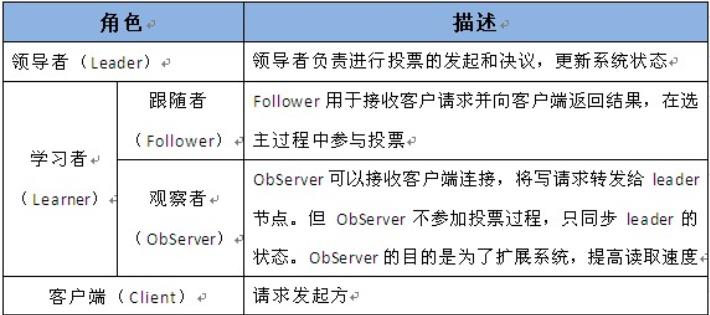
Zookeeper集群环境搭建(20 / 20分)
Zookeeper是一个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
网站架构逐渐从集中式转变成分布式,提供更强的计算、存储能力,避免单点故障等问题。
举例说明:当有一项任务分配到某个团队之后,团队内部的成员开始各司其职,然后把工作结果统一汇总给团队主管,由团队主管再整理团队的工作成果汇报给公司。
人遇到问题可以沟通,机器如何沟通?如何保证分布式系统中保证数据的一致性和可用性?
zookeeper就是各个服务或节点之间进行协调的服务或中间人,同步数据,同步信息
1.配置文件参考:
tickTime=2000
initLimit=10
syncLimit=5
clientPort=????
# 配置数据存储路径
????
# 配置日志文件路径
????
# 配置集群列表
server.1=????
server.2=????
server.3=????
2.Zookeeper一共有三个端口供使用:
2181:对clinet端提供服务
2888:集群内机器通讯使用(Leader监听此端口)
3888:选举leader
3.配置集群时,端口使用如下:
使用server.A=B:C:D
A:表示一个数字,这个数字表示第几个服务器,对应myid文件中的序号
B:服务器地址,也就是ip地址
C:本台服务器与集群中的leader服务器交换信息端口
D:如果leader挂了就需要这个端口重新选举
考核条件如下:
zookeeper基础配置
1. 将zoo安装包解压到指定路径/usr/zookeeper(安装包存放于/usr/package/)(1.00 / 1分)
操作环境: master、slave1、slave2
mkdir -p /usr/zookeeper
tar -zxvf /usr/package/zookeeper-3.4.10.tar.gz -C /usr/zookeeper/

2. 配置zookeeper系统环境变量($ZOOKEEPER_HOME)(1.00 / 1分)
操作环境: master、slave1、slave2
vim /etc/profile在其中加入:
#zookeeper
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
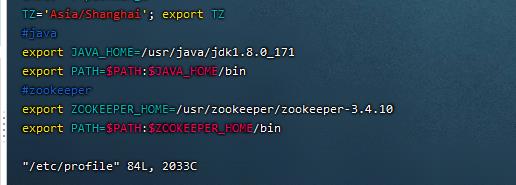
生效环境变量
source /etc/profile
zoo.cfg配置文件
3. 修改配置文件zoo.cfg(1.00 / 1分)
操作环境: master、slave1、slave2
cd /usr/zookeeper/zookeeper-3.4.10/conf
ll
mv zoo_sample.cfg zoo.cfg

4. 设置数据存储路径(dataDir)为/usr/zookeeper/zookeeper-3.4.10/zkda(1.00 / 1分)
操作环境: master、slave2、slave1
5. 设置日志文件路径(dataLogDir)为/usr/zookeeper/zookeeper-3.4.10/zkdatalog(1.00 / 1分)
操作环境: master、slave1、slave2
6. 设置集群列表(master为1号服务器,slave1为2号,slave2为3号)(2.00 / 2分)
操作环境: master、slave1、slave2
vim zoo.cfg
进行如下修改:
修改dataDir=/tmp/zookeeper
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata在文末插入:
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888 
zookeeper相关文件夹创建
7. 创建所需数据存储文件夹(2.00 / 2分)
操作环境: master、slave1、slave2
8. 创建所需日志存储文件夹(2.00 / 2分)
操作环境: master、slave1、slave2
cd /usr/zookeeper/zookeeper-3.4.10/
mkdir zkdata zkdatalog
ll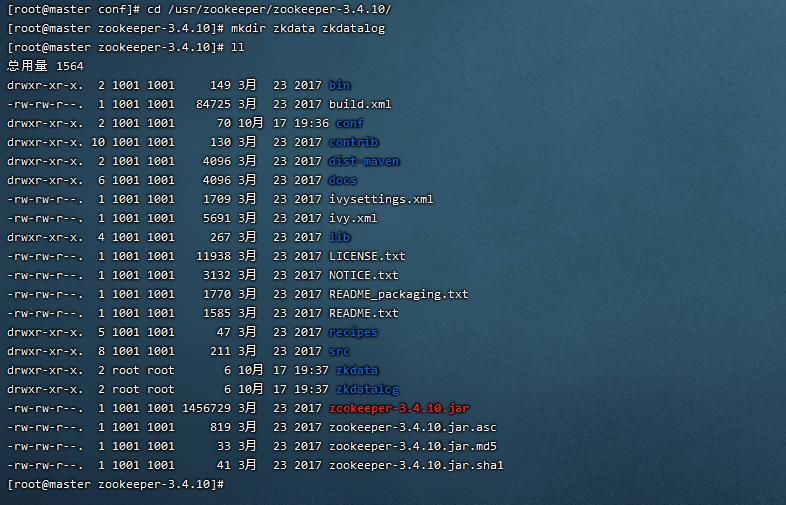
myid修改
9. 数据存储路径下创建myid,写入对应的标识主机服务器序号(2.00 / 2分)
操作环境: master、slave1、slave2
master主机中,设置服务器id为1
slave1设置为2,slave2设置为3
cd zkdata
vim myid 

scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/
scp -r /usr/zookeeper/ root@slave1:/usr/
scp -r /usr/zookeeper/ root@slave2:/usr/
source /etc/profile
vim /usr/zookeeper/zookeeper-3.4.10/zkdata/myid 

启动zookeeper服务
10. 启动zookeeper服务(2.00 / 2分)
操作环境: master、slave1、slave2
cd /usr/zookeeper/zookeeper-3.4.10/
bin/zkServer.sh start

zookeeper状态查询
11. 查看zoo集群状态(5.00 / 5分)
操作环境: master、slave1、slave2
bin/zkServer.sh status



Hadoop完全分布式集群搭建(30 / 30分)
Hadoop是由Java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
- HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
- MapReduce是一个计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
| 配置文件 | 配置对象 | 主要内容 |
|---|---|---|
| hadoop-env.sh | hadoop运行环境 | 用来定义Hadoop运行环境相关的配置信息; |
| core-site.xml | 集群全局参数 | 定义系统级别的参数,包括HDFS URL、Hadoop临时目录等; |
| hdfs-site.xml | HDFS参数 | 定义名称节点、数据节点的存放位置、文本副本的个数、文件读取权限等; |
| mapred-site.xml | MapReduce参数 | 包括JobHistory Server 和应用程序参数两部分,如reduce任务的默认个数、任务所能够使用内存的默认上下限等; |
| yarn-site.xml | 集群资源管理系统参数 | 配置ResourceManager ,nodeManager的通信端口,web监控端口等; |
Hadoop的配置类是由资源指定的,资源可以由一个String或Path来指定,资源以XML形式的数据表示,由一系列的键值对组成。资源可以用String或path命名(示例如下),
- String:指示hadoop在classpath中查找该资源;
- Path:指示hadoop在本地文件系统中查找该资源。
<configuration>
<property>
<name>fs.default.name</name>
<value>????</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>????</value>
</property>
</configuration>
考核条件如下:
hadoop基础配置
1. 将Hadoop安装包解压到指定路径/usr/hadoop(安装包存放于/usr/package/)(1 / 1分)
操作环境: master、slave1、slave2
mkdir -p /usr/hadoop
tar -zxvf /usr/package/hadoop-2.7.3.tar.gz -C /usr/hadoop/
2. 配置Hadoop环境变量,注意生效($HADOOP_HOME)(2 / 2分)
操作环境: master、slave1、slave2
vim /etc/profile
在其中加入:
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin
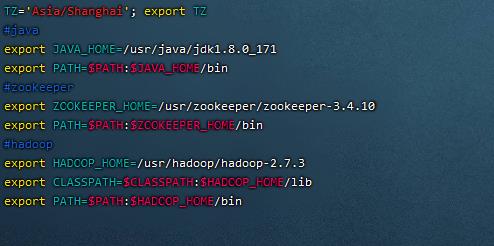
生效环境变量
source /etc/profile
hadoop-env.sh
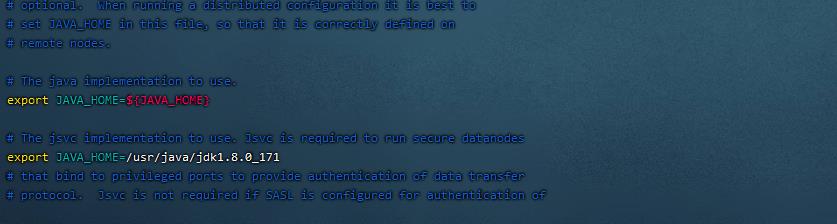
3. 配置Hadoop运行环境JAVA_HOME(1 / 1分)
操作环境: master、slave1、slave2
cd /usr/hadoop/hadoop-2.7.3/etc/hadoop/
ll
vim hadoop-env.sh在28行加入:
export JAVA_HOME=/usr/java/jdk1.8.0_171
core-site.xml
4. 设置全局参数,指定NN的IP为master(映射名),端口为9000(1 / 1分)
操作环境: master、slave1、slave2
5. 指定存放临时数据的目录为hadoop安装目录下/hdfs/tmp(绝对路径,下同)(2 / 2分)
操作环境: master、slave1、slave2
编辑core-site.xml
vim core-site.xml添加以下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>

hdfs-site.xml
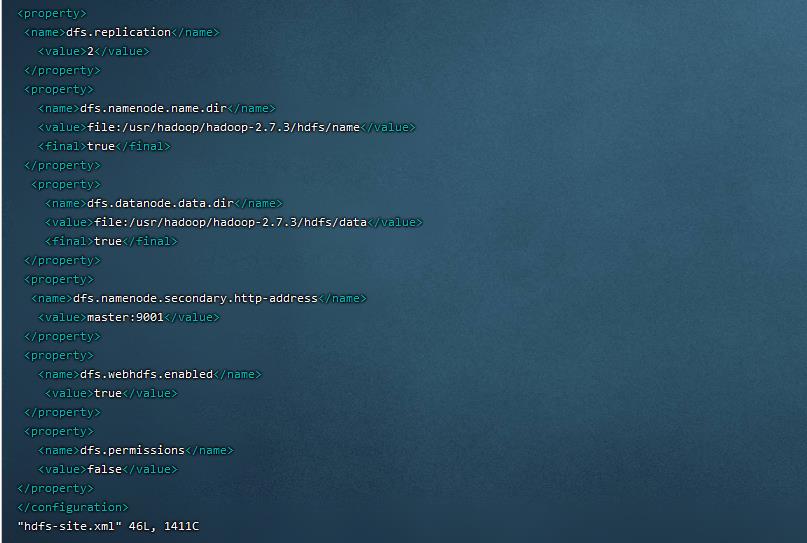
6. 设置HDFS参数,指定备份文本数量为2(2 / 2分)
操作环境: master、slave1、slave2
7. 设置HDFS参数,指定NN存放元数据信息路径为hadoop目录下/hdfs/name(2 / 2分)
操作环境: master、slave1、slave2
8. 设置HDFS参数,指定DN存放元数据信息路径为hadoop安装目录下/hdfs/data(2 / 2分)
操作环境: slave1、master、slave2
编辑hdfs-site.xml
vim hdfs-site.xml添加以下内容:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
yarn-env.sh
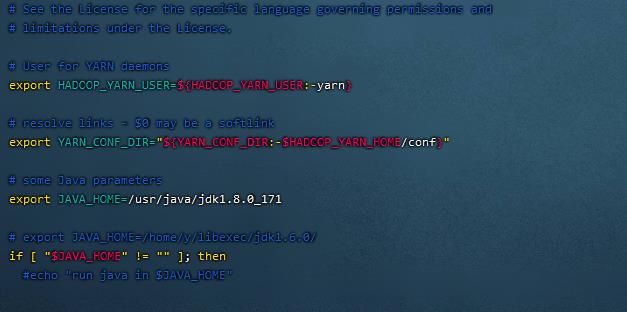
9. 设置YARN运行环境JAVA_HOME参数(2 / 2分)
操作环境: master、slave1、slave2
编辑yarn-env.sh
vim yarn-env.sh插入以下内容:
export JAVA_HOME=/usr/java/jdk1.8.0_171
yarn-site.xml
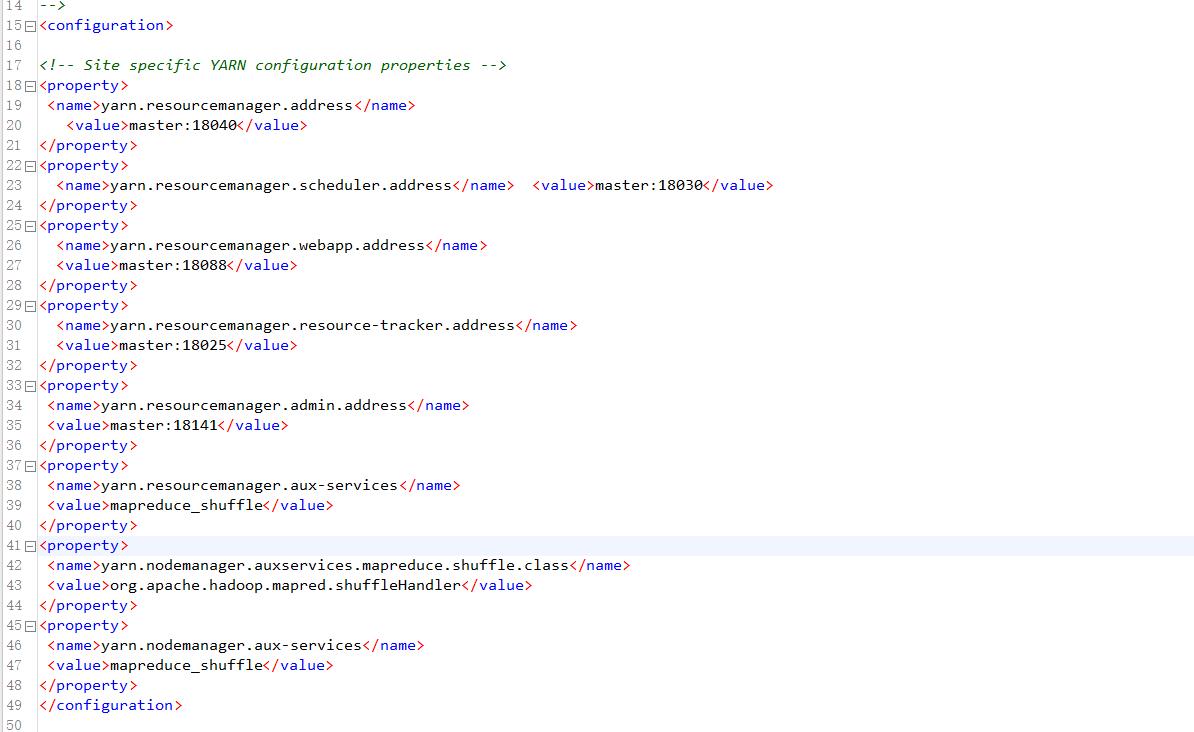
10. 设置YARN核心参数,指定ResourceManager进程所在主机为master,端口为18141(2 / 2分)
操作环境: master、slave1、slave2
11. 设置YARN核心参数,指定NodeManager上运行的附属服务为shuffle(2 / 2分)
操作环境: master、slave1、slave2
编辑yarn-site.xml
vim yarn-site.xml插入以下内容:
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name> <value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.shuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
mapred-site.xml
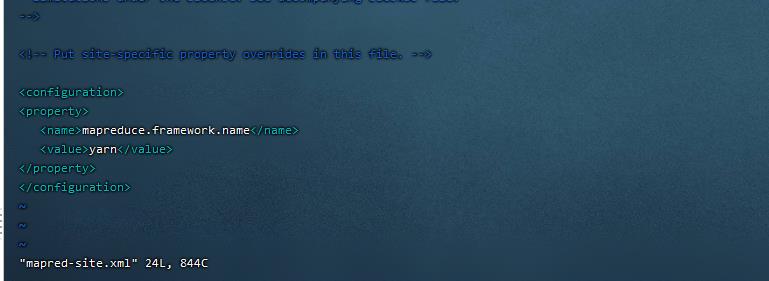
12. 设置计算框架参数,指定MR运行在yarn上(2 / 2分)
操作环境: master、slave1、slave2
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml 插入以下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
节点文件设置
13. 设置节点文件,要求master为主节点; slave1、slave2为子节点(2 / 2分)
操作环境: master、slave1、slave2
vim slaves
修改为:
slave1
slave2 
vim master插入以下内容:
master 
namenode格式化
14. 文件系统格式化(2 / 2分)
操作环境: master
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/
scp -r /usr/hadoop/ root@slave1:/usr/
scp -r /usr/hadoop/ root@slave2:/usr/
在slave1和slave2上生效环境变量
source /etc/profile在master下进行:
hadoop namenode -format

启动hadoop集群
15. 启动Hadoop集群(5 / 5分)
操作环境: master、slave1、slave2
仅在master下执行:
cd /usr/hadoop/hadoop-2.7.3/
sbin/start-all.sh 
jps检查状态:
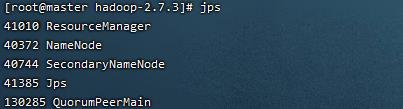
浏览器中输入:
192.168.111.3:50070
以上是关于集群安装搭建赛题解析的主要内容,如果未能解决你的问题,请参考以下文章
SpringCloud Alibaba系列一文全面解析Zookeeper安装常用命令JavaAPI操作Watch事件监听分布式锁集群搭建核心理论
天池赛题解析:零基础入门语义分割-地表建筑物识别-CV语义分割实战(附部分代码)
2021 亚太杯数学建模赛题A-Image Edge Analysis and application图像边缘分析与应用 赛题思路解析及实现
2021 亚太杯数学建模赛题A-Image Edge Analysis and application图像边缘分析与应用 赛题思路解析及实现