TensorFlow 从入门到精通(14)—— 初识循环神经网络
Posted aJupyter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow 从入门到精通(14)—— 初识循环神经网络相关的知识,希望对你有一定的参考价值。
hello,大家好,我又回来了,如约,更新循环神经网络。
最近好像事情变少了,但是状态还是很差。新生班级要展示了,希望51班大哥们能拿个好名次。这篇博客,是用LSTM/RNN来对影评进行分析,这个网络挺复杂,训练了好久,能感觉出来GPU的作用了。
另外,我还打算开辟一个机器学习专栏,不知道大家怎么看。后面有投票,希望大家能投一下!!谢谢!!!!
下一次更新迁移学习,这个已经在准备啦,很快啦!!
import tensorflow as tf
tf.__version__
'2.6.0'
tf.test.is_gpu_available()
WARNING:tensorflow:From <ipython-input-2-17bb7203622b>:1: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
True
循环神经网络(RNN)介绍
很多问题具有时序性,自然语言处理、视频图像处理、股票交易信息等等
比如:
- jupyter 2021年成功入党了,2021年成功拿到国奖了,2022年成功保研了。哈哈哈哈,先做个梦。
大家就会发现,其实只有成功入党有主语jupyter,但是人类的阅读习惯,后面都是jupyter做的。这就是时序性。
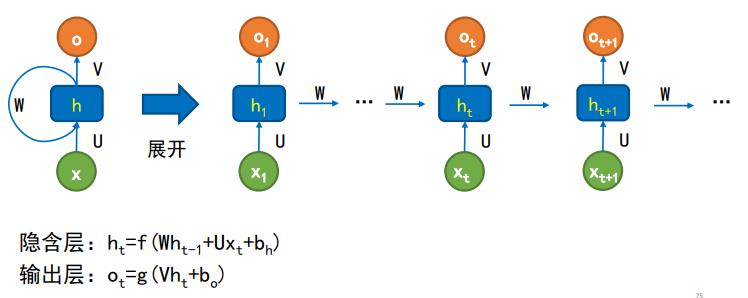
多层全连接的神经网络或者卷积神经网络都只能根据当前的状态进行处理,不能很好地处理时序问题。
(题外话,我们已经接触了全连接和卷积神经网络了)
循环神经网络(RNN)的结构比较特殊,它后一层网络的输入和前一层网络的输出有关系,这样就能把上一层的信息传递给下一层。
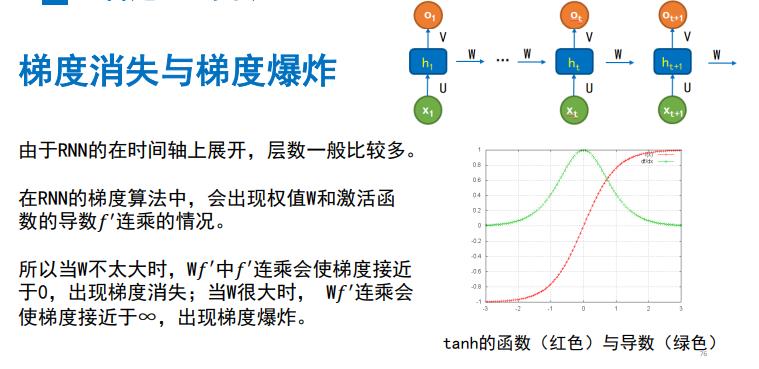
但是普通RNN,会存在梯度消失与梯度爆炸(因为他的激活函数是tanh函数)
- 当序列过长时,由于梯度消失和梯度爆炸问题,对于t时刻来说,它产生的梯度在时间轴上向历史传播几层后就消失了,根本就无法影响太遥远的过去
RNN会忘记很久之前的信息,而只能记住近期出现的信息,所以RNN很难有效处理长文本
长短时记忆网络(LSTM)介绍
RNN的问题:
- 梯度爆炸
- 梯度消失
解决之道:
对于梯度爆炸,一般靠裁剪后的优化算法即可解决,比如gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩)
通过LSTM改进RNN结构,消除梯度消失
传统的RNN每一步的隐藏单元只是执行了一个简单的tanh或RELU操作
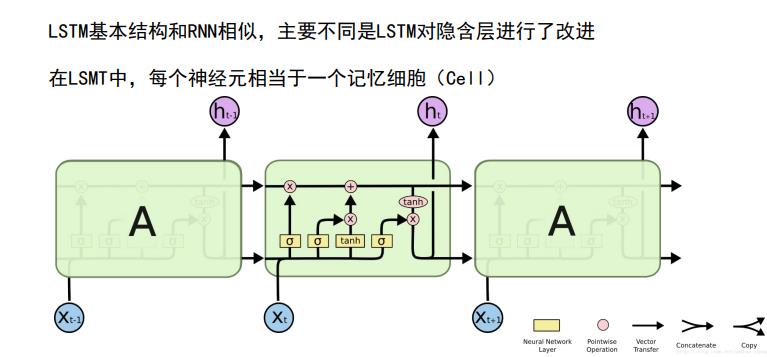
LSTM基本结构和RNN相似,主要不同LSTM对隐含层进行了改进,LSTM中每一个神经元相当于一个记忆细胞
LSTM较于RNN的优点:
- 缓解梯度消失问题
- 使用门结构,解决了长距离依赖的问题
一、自制数据集
- 这种方法更加现实
- 基本思路:
- 获取数据,确定数据格式规范
- 文字分词,英文分词可以按照空格分词,中文分词可以参考jieba
- 建立词索引表,给每个词一个数字索引编号
- 段落文字转为词索引向量
- 段落文字转为词嵌入矩阵
import os
import tarfile
import urllib.request
import numpy as np
import re
from random import randint
# 数据地址
url = 'http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
# 数据存放路径
file_path = 'data/aclImdb_v1.tar.gz'
if not os.path.exists('data'):
os.mkdir('data')
if not os.path.isfile(file_path):
print('downloading')
result = urllib.request.urlretrieve(url,filename=file_path)
print('ok',result)
else:
print(file_path,'is existed!')
downloading
ok ('data/aclImdb_v1.tar.gz', <http.client.HTTPMessage object at 0x7f1599fc17d0>)
# 解压数据
if not os.path.exists('data/aclImdb'):
tfile = tarfile.open(file_path,'r:gz')
print('extracting…')
result = tfile.extractall('data/') # tfile.extractall('data/')将文件解压到data目录下
print('ok',result)
else:
print('data/aclImdb is existed')
extracting…
ok None
# 读取数据集,题外话,对re不熟,需要补
# 将文本中不需要的字符清除,如html标签<br/>
def remove_tags(text):
re_tag = re.compile(r'<[>]+>') # compile 函数用于编译正则表达式,生成一个 Pattern 对象
return re_tag.sub('',text) # re_tag.sub('',text)将匹配到的字符换成空
# 读取数据集封装成函数
def read_files(file_type):
# 1)将所有的文件的路径存入file_list,并统计正样本和负样本的个数
path = 'data/aclImdb/'
file_list = []
positive_file_path = path+file_type+'/pos/'
for f in os.listdir(positive_file_path):
file_list.append(positive_file_path+f)
positive_num = len(file_list)
negitave_file_path = path+file_type+'/neg/'
for f in os.listdir(negitave_file_path):
file_list.append(negitave_file_path+f)
negitave_num = len(file_list) - positive_num
print('read',file_type,':',len(file_list))
print('positive_num',positive_num)
print('negitave_num',negitave_num)
# 2)自己制作标签,因为这个数据集的文件夹名就是特征的标签
labels = [[1,0]]*positive_num + [[0,1]]*negitave_num # 列表相加会拼接列表,列表×一个数字会重复里面的内容
# 3)得到所有文本
features = []
for fi in file_list:
with open(fi,'rt',encoding='utf8') as f:
features+=[remove_tags(''.join(f.readlines()))]
return features,labels
train_x,train_y = read_files('train')
test_x,test_y = read_files('test')
test_y = np.array(test_y)
train_y = np.array(train_y)
read train : 25000
positive_num 12500
negitave_num 12500
read test : 25000
positive_num 12500
negitave_num 12500
train_x[0] # 特征
'It started out slow after an excellent animated intro, as the director had a bunch of characters and school setting to develop. Once the bet is on, though, the movie picks up the pace as it\\'s a race against time to see if a certain number of worms can be eaten by 7 pm. We had a good opportunity on the way home to discuss some things with our son: bullies, helping others, mind over matter when you don\\'t want to do something.<br /><br />Of special note is the girl who played Erica (Erk): Hallie Kate Eisenberg. The director kinda sneaks her in unexpectedly, and when she is on-screen she is captivating. She\\'s one of those "Hey, she looks familiar" faces, and then I remembered that she was the little girl that Pepsi featured about 8 years ago. She was also in "Paulie", that movie about the parrot who tries to find his way home.<br /><br />Ms. Eisenberg made many TV and movie appearances in \\'99-00, but then was not seen much for the next few years. She\\'s now 14 and is growing up to be a beautiful woman. Her smile really warms up the screen. If she can get some more good roles she could have as good a career (or better?) than Haley Joel Osment, another three named kid actor, but hopefully without some of the problems that Osment has been in lately.<br /><br />Anywhozitz, according to my 8 y.o. son, who just finished reading the story, the film did not seem to follow the book all that well, but was entertaining none the less. The ending of the film seemed like a big setup for some sequels (How to Eat Boiled Slugs? Escargot Kid\\'s Style?), which might not be such a bad thing. It was nice to take the family to a movie and not have to worry about language, violence or sex scenes.<br /><br />One other good aspect of the movie was the respect/fear engendered by the principal Mr. Burdock (Boilerplate). Movies nowadays tend to show adult authority figures as buffoons. While he has one particular goofy scene, he ruled the school with a firm hand. It was also nice to see Andrea Martin getting some work.'
train_y[0] # 正评论
array([1, 0])
二、数据处理
1.建立字典
token = tf.keras.preprocessing.text.Tokenizer(num_words=4000) # 4000是只统计4000个词汇
token.fit_on_texts(train_x) # 从train_x中建立字典
2.文字转数字列表(词向量)
train_sequences = token.texts_to_sequences(train_x) # 将文本映射成词向量中的数字,也就是词出现的排名
test_sequences = token.texts_to_sequences(test_x)
train_x[0]
'It started out slow after an excellent animated intro, as the director had a bunch of characters and school setting to develop. Once the bet is on, though, the movie picks up the pace as it\\'s a race against time to see if a certain number of worms can be eaten by 7 pm. We had a good opportunity on the way home to discuss some things with our son: bullies, helping others, mind over matter when you don\\'t want to do something.<br /><br />Of special note is the girl who played Erica (Erk): Hallie Kate Eisenberg. The director kinda sneaks her in unexpectedly, and when she is on-screen she is captivating. She\\'s one of those "Hey, she looks familiar" faces, and then I remembered that she was the little girl that Pepsi featured about 8 years ago. She was also in "Paulie", that movie about the parrot who tries to find his way home.<br /><br />Ms. Eisenberg made many TV and movie appearances in \\'99-00, but then was not seen much for the next few years. She\\'s now 14 and is growing up to be a beautiful woman. Her smile really warms up the screen. If she can get some more good roles she could have as good a career (or better?) than Haley Joel Osment, another three named kid actor, but hopefully without some of the problems that Osment has been in lately.<br /><br />Anywhozitz, according to my 8 y.o. son, who just finished reading the story, the film did not seem to follow the book all that well, but was entertaining none the less. The ending of the film seemed like a big setup for some sequels (How to Eat Boiled Slugs? Escargot Kid\\'s Style?), which might not be such a bad thing. It was nice to take the family to a movie and not have to worry about language, violence or sex scenes.<br /><br />One other good aspect of the movie was the respect/fear engendered by the principal Mr. Burdock (Boilerplate). Movies nowadays tend to show adult authority figures as buffoons. While he has one particular goofy scene, he ruled the school with a firm hand. It was also nice to see Andrea Martin getting some work.'
type(train_sequences[0])
list
3.让转换后的数字列表长度相同
'''
tf.keras.preprocessing.sequence.pad_sequences(train_sequences, 浮点数或整数构成的两层嵌套列表
padding='post',‘pre’或‘post’,确定当需要补0时,在序列的起始还是结尾补0
truncating='post',‘pre’或‘post’,确定当截断序列时,从起始还是结尾截断
maxlen=400),’None或整数,为序列的最大长度。大于此长度的序列将会被截断,小于此长度’会填0
'''
train_x = tf.keras.preprocessing.sequence.pad_sequences(train_sequences,
padding='post',
truncating='post',
maxlen=400)
test_x = tf.keras.preprocessing.sequence.pad_sequences(test_sequences,
padding='post',
truncating='post',
maxlen=400)
train_x[0]
array([ 9, 642, 43, 547, 100, 32, 318, 1121, 14, 1, 164,
66, 3, 758, 4, 102, 2, 392, 953, 5, 2058, 277,
1, 2130, 6, 20, 148, 1, 17, 2847, 53, 1, 1059,
14, 42, 3, 1519, 426, 55, 5, 64, 44, 3, 810,
608, 4, 67, 27, 31, 690, 72, 66, 3, 49, 1429,
20, 1, 93, 341, 5, 46, 180, 16, 260, 489, 2753,
405, 327, 117, 548, 51, 22, 89, 178, 5, 78, 139,
7, 7, 4, 315, 851, 6, 1, 247, 34, 253, 1861,
1, 164, 1927, 38, 8, 2, 51, 56, 6, 20, 265,
56, 6, 3712, 438, 28, 4, 145, 1395, 56, 269, 1076,
1586, 2, 92, 10, 2024, 12, 56, 13, 1, 114, 247,
12, 2553, 41, 705, 150, 593, 56, 13, 79, 8, 12,
17, 41, 1, 34, 494, 5, 166, 24, 93, 341, 7,
7, 1559, 90, 108, 245, 2, 17, 3309, 8, 18, 92,
13, 21, 107, 73, 15, 1, 372, 168, 150, 438, 147,
2425, 2, 6, 1784, 53, 5, 27, 3, 304, 252, 38,
1822, 63, 53, 1, 265, 44, 56, 67, 76, 46, 50,
49, 552, 56, 97, 25, 14, 49, 3, 609, 39, 125,
71, 157, 286, 769, 550, 281, 18, 2353, 206, 46, 4,
1, 709, 12, 45, 74, 8, 7, 7, 1789, 5, 58,
705, 1600, 489, 34, 40, 1763, 883, 1, 62, 1, 19,
119, 21, 303, 5, 790, 1, 271, 29, 12, 70, 18,
13, 439, 597, 1, 326, 1, 274, 4, 1, 19, 465,
37, 3, 191, 15, 46, 2278, 86, 5, 1893, 402, 60,
235, 21, 27, 138, 3, 75, 151, 9, 13, 324, 5,
190, 1, 220, 5, 3, 17, 2, 21, 25, 5, 3230,
41, 1098, 564, 39, 380, 136, 7, 7, 28, 82, 49,
1247, 4, 1, 17, 13, 1, 1158, 1088, 31, 1, 440,
99, 2876, 2345, 5, 120, 1155, 2576, 14, 134, 26, 45,
28, 840, 2962, 133, 26, 1, 392, 16, 3, 505, 9,
13, 79, 324, 5, 64, 1588, 394, 46, 154, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0], dtype=int32)
三、基于LSTM结构的构建模型
model = tf.keras.models.Sequential()
# 词嵌入层,这里充当输入层
'''
model.add(tf.keras.layers.Embedding(output_dim=32,输出词向量的维度
input_dim=4000,#输入词汇表的长度,最大词汇数+1
input_length=400)) # 输入Tensor的长度
'''
model.add(tf.keras.layers.Embedding(output_dim=32,
input_dim=4000,
input_length=400))
# 平坦层
# model.add(tf.keras.layers.SimpleRNN(units=16)) # RNN
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(units=32))) # LSTM
# model.add(tf.keras.layers.GlobalAveragePooling1D())
# model.add(tf.keras.layers.Flatten())
# 全连接层
model.add(tf.keras.layers.Dense(units=256,activation='relu'))
# 丢弃层,防止过拟合
model.add(tf.keras.layers.Dropout(0.3))
# 输出层
model.add(tf.keras.layers.Dense(units=2,activation='softmax'))
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 400, 32) 128000
_________________________________________________________________
bidirectional (Bidirectional (None, 64) 16640
_________________________________________________________________
dense (Dense) (None, 256) 16640
_________________________________________________________________
dropout (Dropout) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 2) 514
=================================================================
Total params: 161,794
Trainable params: 161,794
Non-trainable params: 0
_________________________________________________________________
四、训练
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
history = model.fit(train_x,train_y,validation_split=0.2,epochs=10,batch_size=128,verbose=1)
Epoch 1/10
157/157 [==============================] - 32s 154ms/step - loss: 0.5359 - accuracy: 0.7192 - val_loss: 0.5319 - val_accuracy: 0.7444
Epoch 2/10
157/157 [==============================] - 23s 149ms/step - loss: 0.2882 - accuracy: 0.8847 - val_loss: 0.5372 - val_accuracy: 0.7904
Epoch 3/10
157/157 [==============================] - 23s 149ms/step - loss: 0.2302 - accuracy: 0.9119 - val_loss: 0.3840 - val_accuracy: 0.8646
Epoch 4/10
157/157 [==============================] - 23s 149ms/step - loss: 0.2008 - accuracy: 0.9280 - val_loss: 0.4596 - val_accuracy: 0.8344
Epoch 5/10
157/157 [==============================] - 23s 149ms/step - loss: 0.1862 - accuracy: 0.9327 - val_loss: 0.5627 - val_accuracy: 0.7946
Epoch 6/10
157/157 [==============================] - 23s 149ms/step - loss: 0.1749 - accuracy: 0.9380 - val_loss: 0.5431 - val_accuracy: 0.8148
Epoch 7/10
157/157 [==============================] - 23s 149ms/step - loss: 0.1443 - accuracy: 0.9491 - val_loss: 0.4799 - val_accuracy: 0.8632
Epoch 8/10
157/157 [==============================] - 23s 149ms/step - loss: 0.1283 - accuracy: 0.9553 - val_loss: 0.6568 - val_accuracy: 0.8078
Epoch 9/10
157/157 [==============================] - 23s 149ms/step - loss: 0.1087 - accuracy: 0.9632 - val_loss: 0.6196 - val_accuracy: 0.8314
Epoch 10/10
157/157 [==============================] - 23s 149ms/step - loss: 0.0960 - accuracy: 0.9688 - val_loss: 0.4496 - val_accuracy: 0.8698
import matplotlib.pyplot as plt
def show_train_history(train_history,train_metrics,val_metrics):
plt.plot(train_history[train_metrics])
plt.plot(train_history[val_metrics])
plt.title('Trian History')
plt.ylabel(train_metrics)
plt.xlabel('epoch')
plt.legend(['trian','validation'],loc='upper left')
plt.show()
show_train_history(history.history,'loss','val_loss')
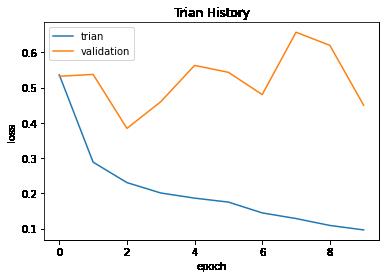
show_train_history(history.history,'accuracy','val_accuracy')

看这个验证集的准确率和损失一直在波动,而训练集一直在上升,其实就可以大概估计出是有点过拟合的意思了
五、评估和预测
model.evaluate(test_x,test_y,verbose=1) # 0是无,1是进度条,2是一个epoch一个
782/782 [==============================] - 40s 51ms/step - loss: 0.5644 - accuracy: 0.8374
[0.5644006133079529, 0.8374000191688538]
pre = model.predict(test_x)
pre[0],test_y[0]
(array([9.996530e-01, 3.470438e-04], dtype=float32), array([1, 0]))
# 模型应用,我自己写的
x = ["This is really a junk movie. Jupyter doesn't like it. Thank you! It's really bad"]
x = token.texts_to_sequences(x)
x = tf.keras.preprocessing.sequence.pad_sequences(x,
padding='post',
truncating='post',
maxlen=400)
x
array([[ 11, 6, 63, 3, 2579, 17, 149, 37, 9, 1289, 22,
42, 63, 75, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]], dtype=int32)
y = model.predict(x)
y
array([[0.12796064, 0.8720394 ]], dtype=float32)
state = {0:'pos',1:'neg'}
state[np.argmax(y)]
'neg'
以上是关于TensorFlow 从入门到精通(14)—— 初识循环神经网络的主要内容,如果未能解决你的问题,请参考以下文章
TensorFlow 从入门到精通:tensorflow.nn 详解
TensorFlow 从入门到精通(10)—— GPU模型训练和卷积神经网络与应用