TensorFlow 从入门到精通(10)—— GPU模型训练和卷积神经网络与应用
Posted aJupyter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow 从入门到精通(10)—— GPU模型训练和卷积神经网络与应用相关的知识,希望对你有一定的参考价值。
这节课,我们来学习如何用GPU训练模型,快的起飞
以及接触卷积神经网络并用keras搭建一个卷积神经网络做一个图片分类
下一节是一个卷积神经网络的项目,冲冲冲
import tensorflow as tf
tf.__version__,tf.config.list_physical_devices('GPU') # 查看能否使用gpu
('2.6.0', [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')])
使用Gpu训练模型,无需更改任何代码
!nvidia-smi # 查看gpu信息
Mon Oct 4 09:19:51 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.74 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 37C P8 28W / 149W | 3MiB / 11441MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
一、数据集
1.下载数据集
# 下载数据集
cifar10 = tf.keras.datasets.cifar10
(x_train,y_trian),(x_test,y_test) = cifar10.load_data()
x_train.shape,y_trian.shape,x_test.shape,y_test.shape
((50000, 32, 32, 3), (50000, 1), (10000, 32, 32, 3), (10000, 1))
2.归一化
x_train = x_train.astype(float) / 255.0
x_test = x_test.astype(float) / 255.0
- 这里并没有进行独热编码,后面解释,其实就是换了一个损失函数。
3.查看图片所属分类(更好了解数据集,并无其余作用)
import matplotlib.pyplot as plt
def show_label(img_ndarray,y_ndarray):
# 展示图片
plt.imshow(img_ndarray)
# 类别
classes=('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
plt.title(f'label:{classes[y_ndarray[0]]}')
plt.show()
show_label(x_train[0],y_trian[0])
二、模型
def create_model():
model = tf.keras.models.Sequential()
# 卷积层一 同时也充当输入层
model.add(tf.keras.layers.Conv2D(filters=32, # 输出通道数
kernel_size=(3,3), # 卷积核(权重矩阵大小,3*3/5*5)
input_shape=(32,32,3),# 卷积层作为输入层的时候可以接受三维数据,其余位置只能处理二维数据
activation='relu',
padding='same' # 输入和输出形状保持一致,卷积层不影响图片大小,但影响图片个数
))
# 防止过拟合
model.add(tf.keras.layers.Dropout(rate=0.3)) # 30%的参数不会参与优化
# 池化层一
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2,2))) # 池化窗口大小,会改变图像的大小,变为16*16
# 卷积层二
model.add(tf.keras.layers.Conv2D(filters=64, # 输出通道数
kernel_size=(3,3), # 卷积核(权重矩阵大小,3*3/5*5)
activation='relu',
padding='same' # 输入和输出形状保持一致,卷积层不影响图片大小,但影响图片个数
))
# 防止过拟合
model.add(tf.keras.layers.Dropout(rate=0.3)) # 30%的参数不会参与优化
# 池化层二
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2,2))) # 池化窗口大小,会改变图像的大小,变为8*8
# ————————————————图像最终是64*8*8————————————————
# 平坦层,因为全连接层只能接收一维数据
model.add(tf.keras.layers.Flatten())
# 全连接层
model.add(tf.keras.layers.Dense(units=128,activation='relu',kernel_initializer='normal'))
# 输出层
model.add(tf.keras.layers.Dense(units=10,activation='softmax',kernel_initializer='normal'))
return model
model = create_model()
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
dropout (Dropout) (None, 32, 32, 32) 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 16, 16, 64) 18496
_________________________________________________________________
dropout_1 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 4096) 0
_________________________________________________________________
dense (Dense) (None, 128) 524416
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 545,098
Trainable params: 545,098
Non-trainable params: 0
_________________________________________________________________
三、模型训练
1.训练
trian_epochs = 20
batch_size = 50
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',# 无序对标签进行独热编码的损失函数
metrics = ['accuracy'],
)
train_history = model.fit(x_train,y_trian,validation_split=0.2,epochs=trian_epochs,verbose=2,batch_size=batch_size)
Epoch 1/20
800/800 - 8s - loss: 1.5125 - accuracy: 0.4525 - val_loss: 1.3550 - val_accuracy: 0.5539
Epoch 2/20
800/800 - 6s - loss: 1.1463 - accuracy: 0.5940 - val_loss: 1.2083 - val_accuracy: 0.6048
Epoch 3/20
800/800 - 6s - loss: 0.9975 - accuracy: 0.6472 - val_loss: 1.0934 - val_accuracy: 0.6406
Epoch 4/20
800/800 - 6s - loss: 0.8972 - accuracy: 0.6850 - val_loss: 1.0181 - val_accuracy: 0.6730
Epoch 5/20
800/800 - 6s - loss: 0.8191 - accuracy: 0.7134 - val_loss: 0.9545 - val_accuracy: 0.6891
Epoch 6/20
800/800 - 6s - loss: 0.7512 - accuracy: 0.7358 - val_loss: 0.9383 - val_accuracy: 0.6938
Epoch 7/20
800/800 - 6s - loss: 0.6895 - accuracy: 0.7555 - val_loss: 0.9067 - val_accuracy: 0.6962
Epoch 8/20
800/800 - 6s - loss: 0.6358 - accuracy: 0.7755 - val_loss: 0.8834 - val_accuracy: 0.7043
Epoch 9/20
800/800 - 6s - loss: 0.5869 - accuracy: 0.7907 - val_loss: 0.8854 - val_accuracy: 0.6961
Epoch 10/20
800/800 - 6s - loss: 0.5375 - accuracy: 0.8096 - val_loss: 0.8673 - val_accuracy: 0.7052
Epoch 11/20
800/800 - 6s - loss: 0.4881 - accuracy: 0.8240 - val_loss: 0.8950 - val_accuracy: 0.6957
Epoch 12/20
800/800 - 6s - loss: 0.4540 - accuracy: 0.8375 - val_loss: 0.8588 - val_accuracy: 0.7065
Epoch 13/20
800/800 - 6s - loss: 0.4181 - accuracy: 0.8489 - val_loss: 0.8873 - val_accuracy: 0.6994
Epoch 14/20
800/800 - 6s - loss: 0.3888 - accuracy: 0.8598 - val_loss: 0.8799 - val_accuracy: 0.7038
Epoch 15/20
800/800 - 6s - loss: 0.3578 - accuracy: 0.8716 - val_loss: 0.8731 - val_accuracy: 0.7071
Epoch 16/20
800/800 - 6s - loss: 0.3334 - accuracy: 0.8801 - val_loss: 0.9532 - val_accuracy: 0.6874
Epoch 17/20
800/800 - 6s - loss: 0.3074 - accuracy: 0.8903 - val_loss: 0.9313 - val_accuracy: 0.6975
Epoch 18/20
800/800 - 6s - loss: 0.2800 - accuracy: 0.8999 - val_loss: 0.9566 - val_accuracy: 0.7015
Epoch 19/20
800/800 - 6s - loss: 0.2724 - accuracy: 0.9024 - val_loss: 0.9659 - val_accuracy: 0.6975
Epoch 20/20
800/800 - 6s - loss: 0.2618 - accuracy: 0.9052 - val_loss: 0.9652 - val_accuracy: 0.7044
train_history.history.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
2.可视化训练过程
def show_train_history(train_history,train_metrics,val_metrics):
plt.plot(train_history[train_metrics])
plt.plot(train_history[val_metrics])
plt.title('Trian History')
plt.ylabel(train_metrics)
plt.xlabel('epoch')
plt.legend(['trian','validation'],loc='upper left')
plt.show()
show_train_history(train_history.history,'loss','val_loss')
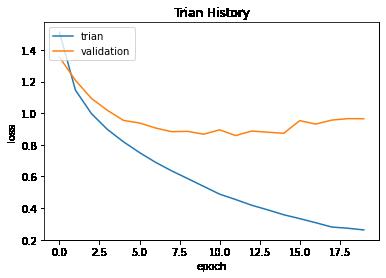
show_train_history(train_history.history,'accuracy','val_accuracy')
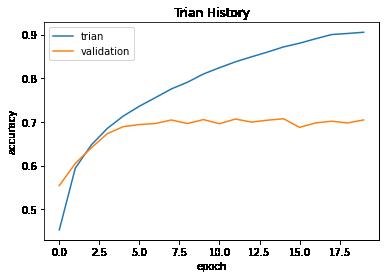
3.评估模型
test_loss,test_acc = model.evaluate(x_test,y_test,verbose=2)
test_loss,test_acc
313/313 - 1s - loss: 0.9629 - accuracy: 0.7017
(0.9629493951797485, 0.70169997215271)
四、预测
1.预测
prd = model.predict(x_test)
predict = tf.argmax(prd,axis=1).numpy()
int(y_test[0]),predict[0]
(3, 3)
2.可视化预测结果
# 定义可视化函数
import numpy as np
import matplotlib.pyplot as plt
classes=('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
def plot_image_labels_prediction(images, # 图像列表
labels, # 标签列表
preds, # 预测值列表
index=0, # 从第index个开始
num=10 # 缺省一次显示10幅
):
fig = plt.gcf() # 获取当前图表
fig.set_size_inches(12,6) # 1英寸等于2.54cm
if num > 10:
num = 10 # 最多显示10个子图
for i in range(0,num):
ax = plt.subplot(2,5,i+1)
ax.imshow(images[index]) # 显示第index个图像
title = str(i)+','+classes[labels[index][0]] # 构建该图上要显示的title信息
if len(preds) > 0:
title += ',predict='+str(classes[preds[index]])
ax.set_title(title,fontsize=10) # 显示图上的title信息
ax.set_xticks([]) # 不显示坐标轴
ax.set_yticks([])
index = index + 1
plt.show()
plot_image_labels_prediction(x_test,y_test,predict)

好好生活,好好coding。
以上是关于TensorFlow 从入门到精通(10)—— GPU模型训练和卷积神经网络与应用的主要内容,如果未能解决你的问题,请参考以下文章
TensorFlow 从入门到精通:tensorflow.nn 详解