Python爬虫案例50篇-第1篇-csdn开源广场的cookie登录
Posted 不愿透露姓名の网友
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫案例50篇-第1篇-csdn开源广场的cookie登录相关的知识,希望对你有一定的参考价值。
提前声明:该专栏涉及的所有案例均为学习使用,如有侵权,请联系本人删帖!
一、请求头中的cookie
对于一些网站,我们在抓取时候需要补充请求头requests headers
Host: www.renren.com
Proxy-Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400
Accept: text/html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: ***
但是对于一些网站,我们如果不登录,那么我们就无法进入网站内部,因此就需要登录,那么登录后,我们就可以获取到cookie值,而有了cookie值,我们就可以进入网站,抓取想要的信息。
二、准备工作
- 环境:python3.6
- 开发工具:pycharm
- 模块:requests
三、分析
网站:https://codechina.csdn.net/explore/welcome
进入网址,需要登录

因此我们需要手动登录后,然后看到已经有了cookie
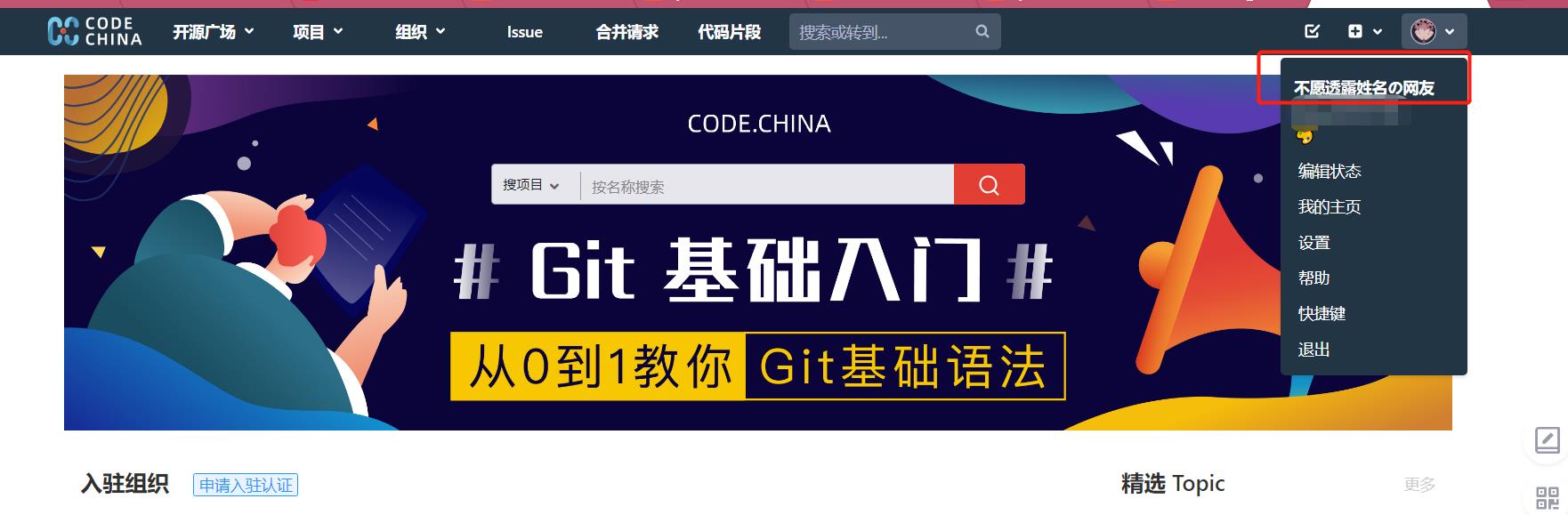

因此我们直接在请求的时候携带自己的cookie,如果我们登陆后,可以看到自己的用户名

四、代码编写
# -*- coding: utf-8 -*-
import requests
url = 'https://codechina.csdn.net/explore/welcome'
headers = {
'Cookie': '...',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36'
}
# 请求,verify=False 跳过ssl验证
response = requests.get(url, headers=headers, verify=False)
response.encoding = 'utf-8'
if '不愿透露姓名の网友' in response.text:
print('cookie有效')
else:
print('cookie无效')

成功!
以上是关于Python爬虫案例50篇-第1篇-csdn开源广场的cookie登录的主要内容,如果未能解决你的问题,请参考以下文章
时隔3年,摄影网站依旧可用,果然靠谱,Python爬虫100例,第2篇复盘文章
一篇博客,拿下7个爬虫案例,够几天的学习量啦,《爬虫100例》第4篇复盘文章
时隔3年,摄影网站依旧可用,果然靠谱,Python爬虫100例,第2篇复盘文章
值!一篇博客,容纳11个Python爬虫案例总结,《爬虫100例》专栏第6篇复盘文章