一篇博客,拿下7个爬虫案例,够几天的学习量啦,《爬虫100例》第4篇复盘文章
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一篇博客,拿下7个爬虫案例,够几天的学习量啦,《爬虫100例》第4篇复盘文章相关的知识,希望对你有一定的参考价值。
文章目录
案例 13:斗图啦表情包爬取
原文参考链接:https://dream.blog.csdn.net/article/details/83020175
没想到在 2018 年,我就爬取了这个站点,现在打开这个网址竟然依旧可以访问。
测试代码,发现无问题,正常可用。不过我还是上传了一份到 codechina 中
案例 14:PDF 电子书下载
原文参考链接:https://dream.blog.csdn.net/article/details/83151879
当前爬取这个网站的时候,橡皮擦还在吐槽这是一个小清新网站,一点广告都没有,但在 3 年后的今天,这个网站消失了,果然盈利才是硬道理。
没办法,我怀着无比心动的心情,又找到了一个新的小清新站点。
免费技术书籍,这个就更加有趣了,都是技术人员阅读的书籍。
https://www.freetechbooks.com/topics,在爬取该网站的时候,由于对方服务器在国外,顾下载 PDF 时,存在部分问题,本复盘阶段,就不在进行扩展。

案例 15:政民互动数据采集
在复盘这个案例的时候,心里一抖,幸亏当年没现在这么的,网站已经变成很红的颜色了。
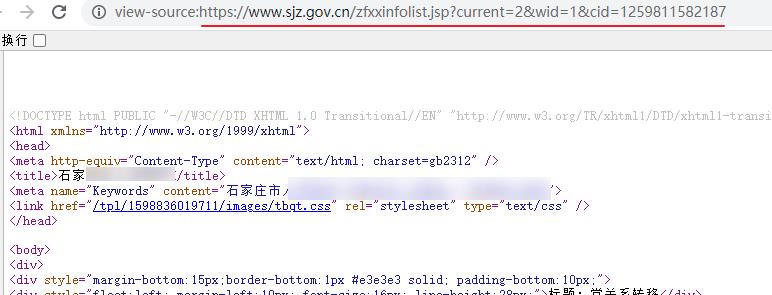
打开网站地址:https://www.sjz.gov.cn/col/1597714516660/index.html ,核心数据是使用的 iframe 进行的嵌套。
选择查看框架内源码,进入真实页面。

在框架源码中检索真实的地址,进行采集即可,可替换到原案例中的 selenium,使用普通的请求采集即可。
案例 16:500px 摄影师社区
一句话,接口都在,它还很好。
案例 17:CSDN 博客抓取数据
这个案例竟然是爬取 CSDN,大水冲了龙王庙呀。
看了一下,最后竟然是因为那一天是 1024。

检测接口发现,shown_offset 参数已经被取消,现在的接口格式如下:
https://blog.csdn.net/api/articles?type=more&category=python&shown_offset=0
数据的核心请求参数,经测试在 cookie 中只有 uuid_tt_dd 会对结果产生影响,顾获取数据时,动态从 cookie 获取该值,或手动输入即可。
import requests
import time
import requests
START_URL = "https://blog.csdn.net/api/articles?type=more&category=home&shown_offset=0"
HEADERS = {
"Accept":"application/json",
"Host":"www.csdn.net",
"Referer":"https://www.csdn.net/",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"X-Requested-With":"XMLHttpRequest",
"cookie":'uuid_tt_dd=10_从 cookie 自行获取;'
}
def get_url(url):
try:
res = requests.get(url,headers=HEADERS,timeout=3)
articles = res.json()
if articles["status"]:
need_data = articles["articles"]
if need_data:
# 输出第一条 title
print(need_data[0]["title"])
print("成功获取到{}条数据".format(len(need_data)))
# last_shown_offset = articles["shown_offset"] # 获取最后一条数据的时间戳
# if last_shown_offset:
time.sleep(1)
get_url(START_URL)
except Exception as e:
print(e)
print("系统暂停60s,当前出问题的是{}".format(url))
time.sleep(60) # 出问题之后,停止60s,继续抓取
get_url(url)
if __name__ == "__main__":
get_url(START_URL)
案例 18:煎蛋网 XXOO
这个网站已经改名为 随手拍,变化真大,案例使用的依旧是 selenium,学习它可以参考 《滚雪球学 Python 番外篇(完结)》。
所以本案例就不在进行复盘更新,网站依旧可访问,顾核心技术点基本一致。
案例 19:51CTO 学堂课程数据抓取
打开原案例中的地址,界面 UI 已经发生变化,但是数据还在。
https://edu.51cto.com/courselist/index-p1.html?edunav=
https://edu.51cto.com/courselist/index-p2.html?edunav=
https://edu.51cto.com/courselist/index-p3.html?edunav=
不得不说,当前爬取的时候,51CTO 只有 1W+课程数据,3 年过去了,翻了一倍。
简单的修改一下代码逻辑,该案例依旧可用,为了便于测试,只展示核心部分代码
from requests_html import AsyncHTMLSession # 导入异步模块
asession = AsyncHTMLSession()
BASE_URL = "https://edu.51cto.com/courselist/index-p{}.html?edunav="
async def get_html():
for i in range(1,3):
r = await asession.get(BASE_URL.format(i)) # 异步等待
get_item(r.html)
def get_item(html):
c_list = html.find('.Content-left',first=True)
if c_list:
items = c_list.find('li[class^=li_4n]')
print(items)
for item in items:
title = item.find("div[class='title']",first=True).text # 课程名称
href = item.find('a',first=True).attrs["href"] # 课程的链接地址
# class_time = item.find("div.course_infos>p:eq(0)",first=True).text
# study_nums = item.find("div.course_infos>p:eq(1)", first=True).text
# stars = item.find("div.course_infos>div", first=True).text
# course_target = item.find(".main>.course_target", first=True).text
# price = item.find(".main>.course_payinfo h4", first=True).text
# dict = {
# "title":title,
# "href":href,
# "class_time":class_time,
# "study_nums":study_nums,
# "stars":stars,
# "course_target":course_target,
# "price":price
# }
# print(dict)
print(title,href)
else:
print("数据解析失败")
if __name__ == '__main__':
result = asession.run(get_html)

今日复盘结论
今日复盘了 7 个案例,其中大多数网站依旧在线,散发活力,当然爬虫也依旧在工作,加油学习吧。
良心博主,竟然 3 年不掉线。
收藏时间
本期博客收藏过 400,立刻更新下一篇
今天是持续写作的第 193 / 200 天。
可以关注我,点赞我、评论我、收藏我啦。
更多精彩
以上是关于一篇博客,拿下7个爬虫案例,够几天的学习量啦,《爬虫100例》第4篇复盘文章的主要内容,如果未能解决你的问题,请参考以下文章