大规模环境下基于语义直方图的多机器人实时全局定位图匹配
Posted Being_young
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大规模环境下基于语义直方图的多机器人实时全局定位图匹配相关的知识,希望对你有一定的参考价值。
文章:Semantic Histogram Based Graph Matching for Real-Time Multi-Robot Global Localization in Large Scale Environment
作者:Xiyue Guo, Junjie Hu, Junfeng Chen, Fuqin Deng, Tin Lun Lam.
编译:点云PCL
代码:https://github.com/JunjH/Semantic-Graph-based--global-Localization
本文仅做学术分享,如有侵权,请联系删除。欢迎各位加入免费知识星球,获取PDF论文,欢迎转发朋友圈。内容如有错误欢迎评论留言,未经允许请勿转载!
公众号致力于分享点云处理,SLAM,三维视觉,高精地图相关的文章与技术,欢迎各位加入我们,一起每交流一起进步,有兴趣的可联系微信:920177957。本文来自点云PCL博主的分享,未经作者允许请勿转载,欢迎各位同学积极分享和交流。
摘要
基于视觉的多机器人同时定位与建图(MR-SLAM)的核心问题是如何高效、准确地进行多机器人全局定位(MR-GL),第一个问题是,由于存在明显的视点差异,因此难以进行全局定位,基于外观的定位方法在视点变化较大的情况下往往会定位失败,最近,语义地图可以被用来克服视点变化带来的定位失败的问题。然而,这些方法非常耗时,尤其是在大规模环境中,第二个困难,即如何进行实时全局定位,本文提出了一种基于语义直方图的图像匹配方法,该方法对视点变化具有鲁棒性,能够实现实时全局定位,在此基础上,我们开发了一个系统,可以准确有效地执行MR-GL的同质和异构机器人,实验结果表明,我们的方法比基于随机游走的语义描述子快30倍左右,此外,全局定位的准确率为95%,而最先进的方法的准确率为85%。
主要贡献
该方法用于大规模环境下的全局定位,两个机器人(无人机和车辆)之间的视角非常大。我们利用语义地图为两个机器人构建语义图,然后,可以简单地估计它们之间的变换矩阵。
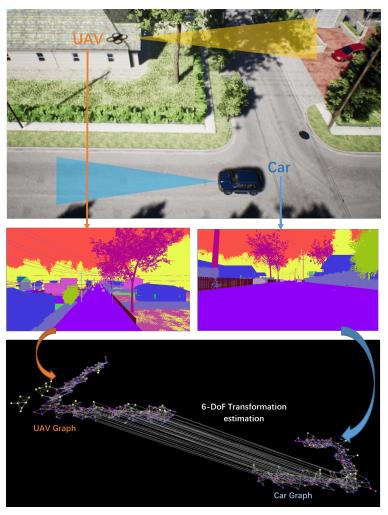
图1,基于语义的图匹配方法的一个实例
在本文中,我们提出了一种更精确和计算效率更高的方法,该方法是基于语义的图匹配方法,是一种新的基于语义直方图的描述子,能够在视点变化较大的情况下进行实时匹配,描述子以预先安排的直方图的形式存储周围路径的信息,图2示出了描述子的图示。基于新的描述子,我们进一步开发了一个基于语义图的全局定位系统来合并MRSLAM的地图。
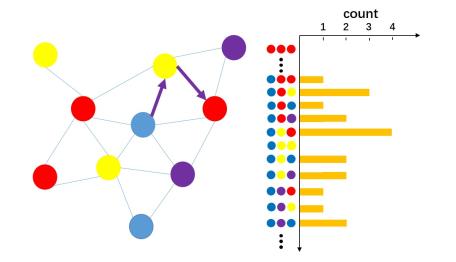
图2。基于语义直方图的描述子的图示。左边是语义图,搜索的路径从起点(蓝色)开始,路径信息记录为右侧预先安排的柱状图,两个描述子之间的相似性得分可以通过归一化点积得到
我们的方法在三个数据集上进行了测试,包括两个合成数据集和一个公开的真实数据集。因此,我们通过实验表明:
我们的方法在很大程度上优于基于外观和语义的方法。它在大规模环境中稳定而准确地处理较大的视点差异。
我们的方法比最先进的基于语义的方法快得多,它为同质和异构机器人系统提供了令人满意的性能。
该方法仅以RGB图像为输入,深度图和语义图通过深度卷积网络进行预测,在大规模真实KITTI数据集上具有良好的融合性能。
主要内容
本文介绍基于语义直方图的全局定位图匹配系统,整体的框架部分受到X-view的启发,首先,给出了两种里程计、相关深度图和语义图,首先生成语义图,然后提取基于语义直方图的描述子,这两个图与提取的描述子匹配,最后,计算了六自由度变换矩阵,该系统的框架如图3所示。
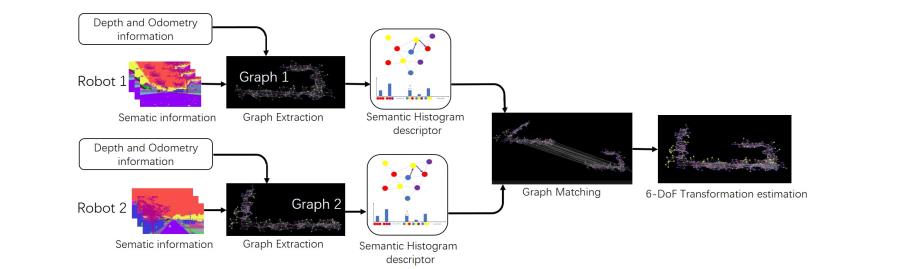
图3,全局定位系统的示意图,该系统采用语义图、深度图和里程计作为输入,首先根据输入构建每个机器人的3D语义图,然后,利用语义直方图方法提取每个节点的描述子。接下来,通过比较两个图中的描述符来匹配这两个图,最后,利用匹配对应关系估计两机器人坐标系之间的6自由度变换。
A . 图提取
类似于论文[3],为了构建图,我们需要从图像中提取节点,为此,我们采用种子填充方法从图像中分割对象,为了避免语义相同的两个相邻对象之间的分割失败,在分割过程中使用了像素的三维坐标,然后,提取每个对象的三维几何中心作为节点。需要注意的是,如果具有相同语义标签的节点彼此非常接近,则应合并它们,因此,每个节点包含两类信息:
1)节点的三维坐标值;
2) 语义标签。
如果节点之间的距离小于设定的阈值(连通性阈值),则形成节点之间的无向边。最后,节点和边一起形成基于语义的图。
B.基于语义直方图的描述子
为了描述图中的每个节点,需要通过提取节点的描述子来记录节点的周围信息,对于语义图,基于直方图的描述方法简单可行;此外,这类描述子的匹配过程非常快,直观地说,最简单的基于直方图的描述符是邻域向量描述子,它通过计算所有相邻节点的标签来描述节点,然而,由于缺乏拓扑信息,邻域向量的匹配性能很低,因此,提出了为所有节点包含更多的周围信息,具体来说,对于每个节点,描述子存储从它开始的所有可能路径,将路径的长度设置为3,因此,每个路径都可以看作一个三维向量,记录这三个步骤的语义标签,对于单个描述子,所有可能的路径都以预先安排的直方图的形式进行计数,因此,对象及其邻居的拓扑信息存储在描述子中。算法1中显示了描述符的图示,该描述符使得图匹配在计算上更加高效。

C. 图匹配
与图像匹配类似,通过计算相似度得分,在图中比较节点的描述子,在匹配过程中,仅比较具有相同标签的节点,相似性得分是通过取两个描述子之间的标准化点积得到的。其规定如下:
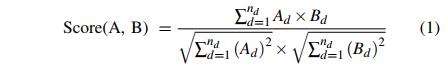
两个节点之间的相似度得分在0到1之间,得分越高表示相似度越高。将相似度得分高于阈值Ts的对应关系存储为匹配候选。为了保证这些对应关系的一致性,使用ICP-RANSAC算法来剔除异常值,最后,在姿态估计方法中保留了剩余的内联对应,此外,从ICP-RANSAC方法获得的旋转矩阵R和平移向量t存储为姿势估计方法的初始值。算法2中显示了图形匹配的图示

D.姿势估计
在这一步中,使用ICP算法计算最终的变换矩阵,在该方法中,使用RANSAC方法获得的内部对应进行配准,因此,旋转矩阵R和平移向量t通过最小化平方误差之和获得:
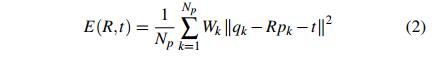
实验
为了公平和充分地验证我们的方法的有效性,我们在多个数据集上进行了三个实验。首先,我们在SYNTHIA数据集上展示了我们的方法与以前方法之间的定量比较。其次,我们展示了我们的多机器人全局定位方法的性能,我们将我们的方法应用于同质和异构多机器人系统。第三,为了验证我们的方法的通用性,我们在真实的KITTI数据集上进行了另一个实验,其中我们只使用RGB图像作为输入。最后,我们研究了不同参数设置和输入质量的影响,所有的实验都是在1.80GHz的Intel Core i7-8565U CPU上进行计算的。
A.性能比较
数据集和具体细节:SYNTHIA数据集从动态城市环境中安装在模拟汽车上的传感器收集数据。在我们的实验中,我们使用序列04 spring作为我们的测试序列。它包含三种类型的数据,包括RGB图像、深度图和语义图,如图4所示。

图4。SYNTHIA数据集示例,顶行中的图像是前向视图图像,包括语义、深度和RGB图像,下一行中的图像是同时采集的后向视图图像。
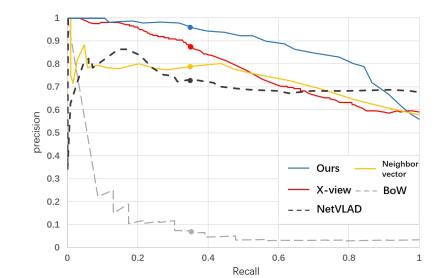
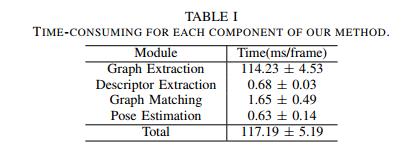
结果如图5所示,很明显,当视点变化显著时,基于语义图的方法比基于外观的方法更精确,结果表明,我们的方法获得了95%的成功率,而BoW、X-view、NetVLAD和邻居向量的成功率分别为8%、85%、73%和79%,此外,我们方法的每个组成部分的时间复杂度如表1所示。
B.全局定位的多机器人
数据集和具体细节:我们考虑的另一个问题全局定位的多个大规模的测距由多个机器人产生的,这是多机器人SLAM地图融合的关键步骤,评估了我们的方法在异构和同质机器人系统中的性能。

图6。AirSim生成的三条模拟轨迹的图示,我们使用它们来评估我们的全局定位方法在同质和异构机器人系统中的性能。
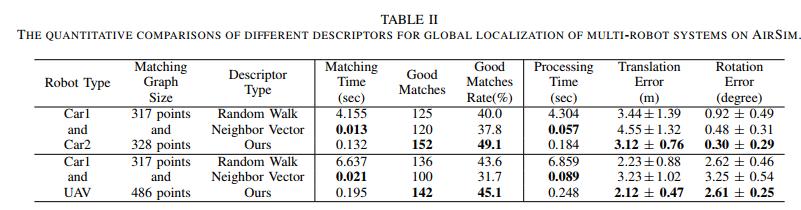
实验结果:定量比较如表二所示,其中100次实验的平均结果,很明显该方法实现了最低的平移和旋转误差的全局定位。
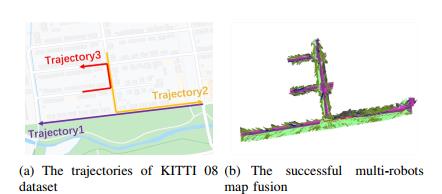
图7。KITTI数据集中序列08的轨迹和重建图。a) 显示轨迹,其中每条线表示轨迹。b) 显示从这三条轨迹重建和合并的地图。
C.真实场景的可泛化性
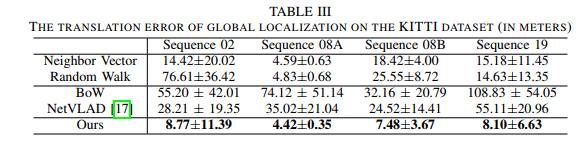
数据集和具体细节:为了评估我们的方法在真实环境中的可泛化性,我们在KITTI数据集上进行了另一个实验,具体来说,我们在序列02、08和19三个序列上评估我们的方法,在实验中,从序列08中分割出三条轨迹,条轨迹的图示如图7(a)所示。为简单起见,我们使用08A和08B表示轨迹1和轨迹2、轨迹2和轨迹3之间的对齐。对于序列02和19,有两条轨迹在相反方向上共享重叠。序列02、08和19的总行程长度分别为260米、850米和1000米。此外,序列02、08A、08B和19的重叠分别为30米、200米、50米和300米,与AirSim一样,我们使用整个图来执行定位。实验结果:表三显示了KITTI数据集的平均平移错误及其标准偏差。
总结
本文研究了基于视觉的多机器人SLAM的全局定位问题。主要解决两个难点问题。第一个是大视角差异,这在多机器人系统中普遍存在,第二个困难是需要实时进行全局定位,这些困难促使我们开发一种更有效的方法,本文提出了一种基于语义直方图的描述子,正因为如此,图匹配被表示为两个描述子集之间的点积,可以实时进行,基于所提出的描述子,我们提出了一个更准确、更高效的全局定位系统,该系统在合成SYNTHIA、AirSim数据集以及真实KITTI数据集上进行了测试,实验结果表明,我们的方法比其他方法有很好的优势,并且比以前基于随机游动的基于语义的方法要快得多。
资源
三维点云论文及相关应用分享
【点云论文速读】基于激光雷达的里程计及3D点云地图中的定位方法
3D-MiniNet: 从点云中学习2D表示以实现快速有效的3D LIDAR语义分割(2020)
PCL中outofcore模块---基于核外八叉树的大规模点云的显示
更多文章可查看:点云学习历史文章大汇总
SLAM及AR相关分享
扫描下方微信视频号二维码可查看最新研究成果及相关开源方案的演示:
如果你对本文感兴趣,请后台发送“知识星球”获取二维码,务必按照“姓名+学校/公司+研究方向”备注加入免费知识星球,免费下载pdf文档,和更多热爱分享的小伙伴一起交流吧!
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
扫描二维码
关注我们
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入免费星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享及合作方式:微信“920177957”(需要按要求备注) 联系邮箱:dianyunpcl@163.com,欢迎企业来联系公众号展开合作。
点一下“在看”你会更好看耶

以上是关于大规模环境下基于语义直方图的多机器人实时全局定位图匹配的主要内容,如果未能解决你的问题,请参考以下文章