C语言重点难点精讲关键字精讲
Posted 快乐江湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C语言重点难点精讲关键字精讲相关的知识,希望对你有一定的参考价值。
必读:
- C语言关键字是一个非常重要的话题,因为它能在相当的程度上将C语言的核心内容串联起来,起到一种提纲挈领的效果
- 下面的内容重点提及的是相应关键字特别值得注意的地方,这些地方是我们经常忽略的,而且考试也会经常涉及到
- 讲解这些关键字时默认大家都有C语言的基础,因此不会从0开始谈起
文章目录
一般来讲,C语言一共有32个关键字(C90标准),当然C99后又新增了5个关键字,不过我们还是重点讨论这32个关键字
| 关键字 | 说明 |
|---|---|
auto | 声明自动变量 |
short | 声明短整型变量或函数 |
int | 声明整形变量或函数 |
long | 声明长整形变量或函数 |
float | 声明浮点型变量或函数 |
double | 声明双精度变量或函数 |
char | 声明字符型变量或函数 |
struct | 声明结构体变量或函数 |
union | 声明共用数据类型 |
enum | 声明枚举类型 |
typedef | 用以给数据类型取别名 |
const | 声明只读变量 |
unsigned | 声明无符号类型变量或函数 |
signed | 声明有符号类型变量或函数 |
extern | 声明变量是在其它文件中正声明 |
register | 声明寄存器变量 |
static | 声明静态变量 |
volatile | 说明变量在程序执行过程中可以被隐含地改变 |
void | 声明函数无返回值或无参数,声明无类型指针 |
if | 条件语句 |
else | 条件语句否定分支(与if连用) |
switch | 用于开关语句 |
case | 开关语句分支 |
for | 一种循环语句 |
do | 循环语句的循环体 |
while | 循环语句的循环条件 |
goto | 无条件跳转语句 |
continue | 结束当前循环,开始下一轮循环 |
break | 跳出当前循环 |
default | 开关语句中的“其它”分支 |
sizeof | 计算数据类型长度 |
return | 子程序返回语句,循环条件 |
一:auto关键字
一般来说,在代码块中定义的变量(也即局部变量),默认都是auto修饰的,不过会省略。但是一定要注意:不是说默认的所有变量都是auto的,它只是一般用来修饰局部变量
当然在C语言中,我们已经不再使用auto了,或者称其为过时了,但是在C++中却赋予了auto新的功能,它变得更加强大了。有兴趣请点击2-6:C++快速入门之内联函数,auto关键字,C++11基于范围的for循环和nullptr
二:register关键字
register意味寄存器
(1)存储器分级
这个概念我们在计算机组成原理中讲得已经非常详细了,请点击:(计算机组成原理)第三章存储系统-第一节:存储器分类、多级存储系统和存储器性能指标
(2)register修饰变量
可以看出,如果将变量放到寄存器中,那么效率就会提高。可以用register修饰的变量有以下几种
- 局部的(全局变量会导致CPU寄存器长时间被占用)
- 不会被写入的(写入的话就需要被写回内存,要是这样的话register就没有意义的)
- 高频需要被读取的
如果要使用,不要大量使用,因为寄存器的数量有限。
另外还需要注意的一点是:被register修饰的变量,是不能取地址的,因为它已经放在了寄存器中,地址会涉及到内存,但是可以被写入
当然这个register关键字现在也基本不会用了,因为如今的编译器优化已经很智能了,不需要你自己手动优化
三:static关键字
(1)修饰全局变量和函数
我们知道全局变量(加入关键字extern声明)和函数都可以跨文件使用的
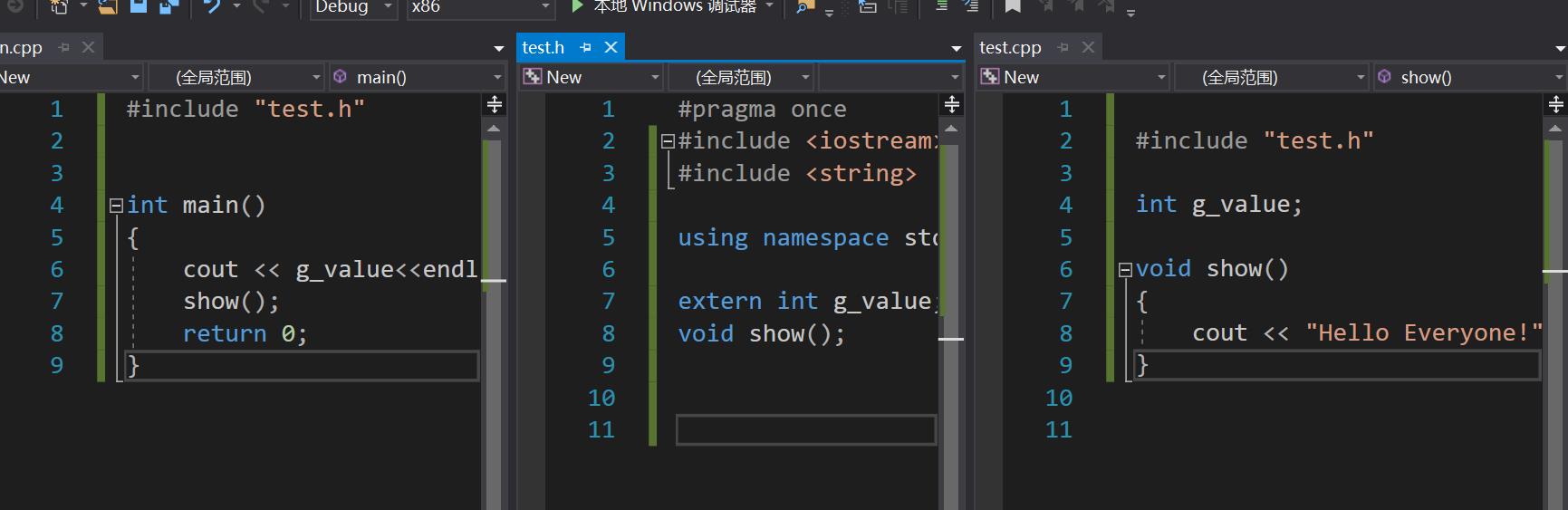

但是有一些应用场景中,我们不想让全局变量或函数跨文件访问应该怎么办呢?那么就可以使用static关键字
static int g_value=100;//修饰staic后全局变量将不能跨文件使用

可以看出被static修饰的全局变量是不能被外部其他文件直接访问的,而只能在本文件内使用
- 需要注意这里说的是直接访问,那意味着可以间接访问,比如通过函数的方式实现
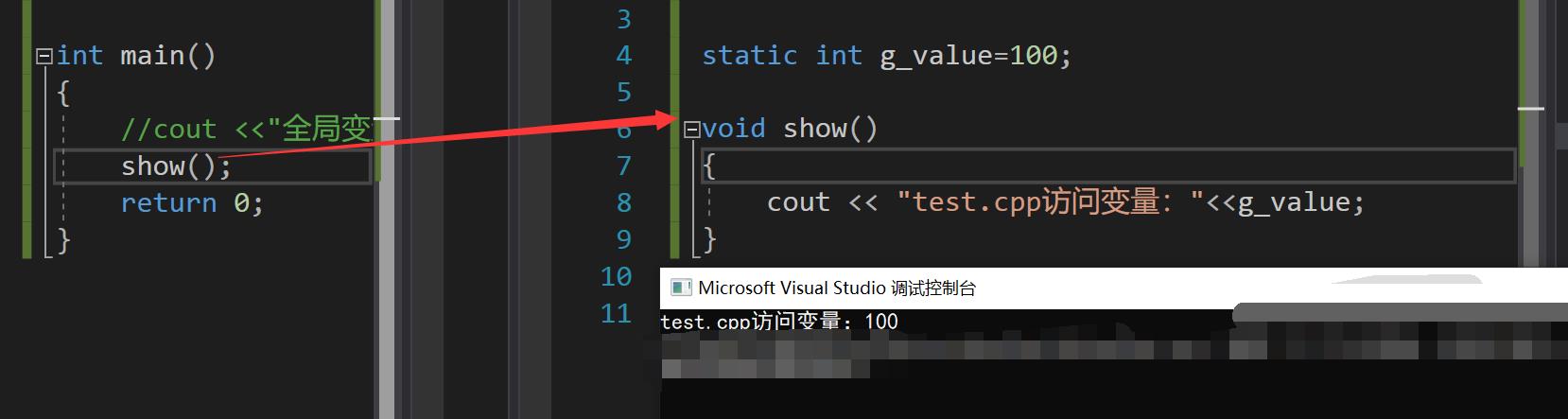
同样,被static修饰的函数只能在本文件内访问,而不能在外部其它文件中直接访问
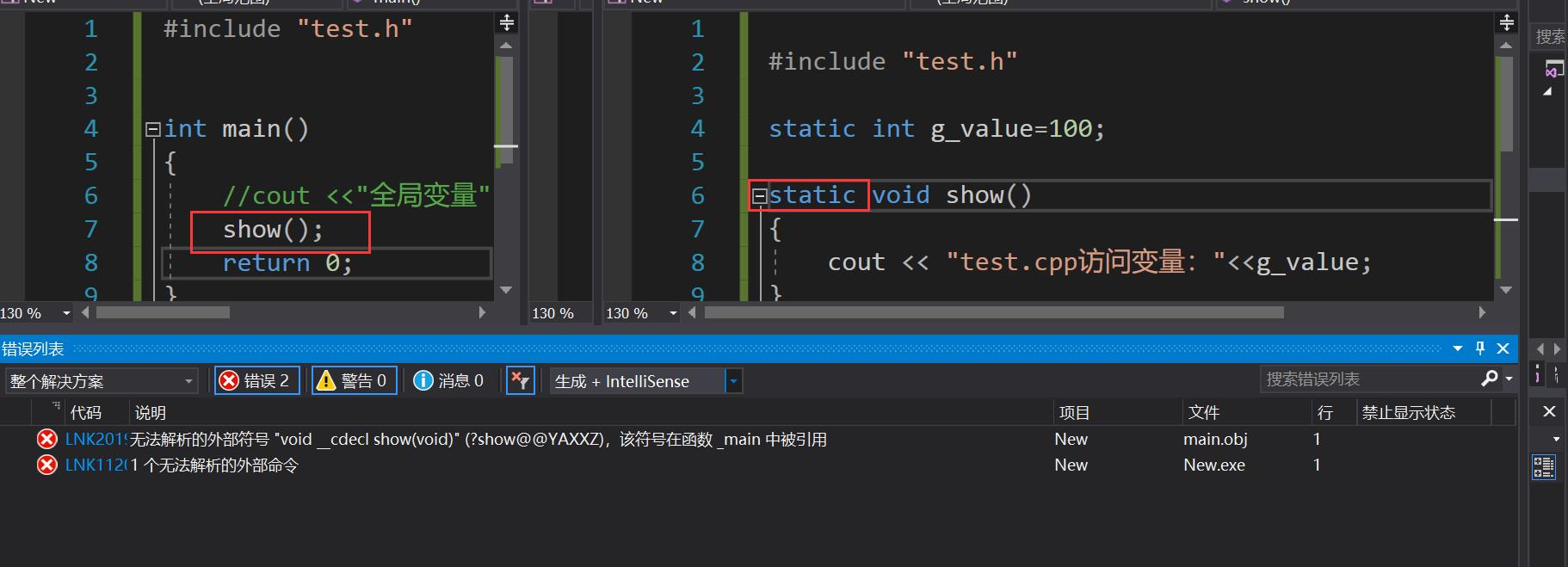
- 还是需要注意,这里是不能直接访问,并不是不能访问,比如可以通过函数嵌套的方式
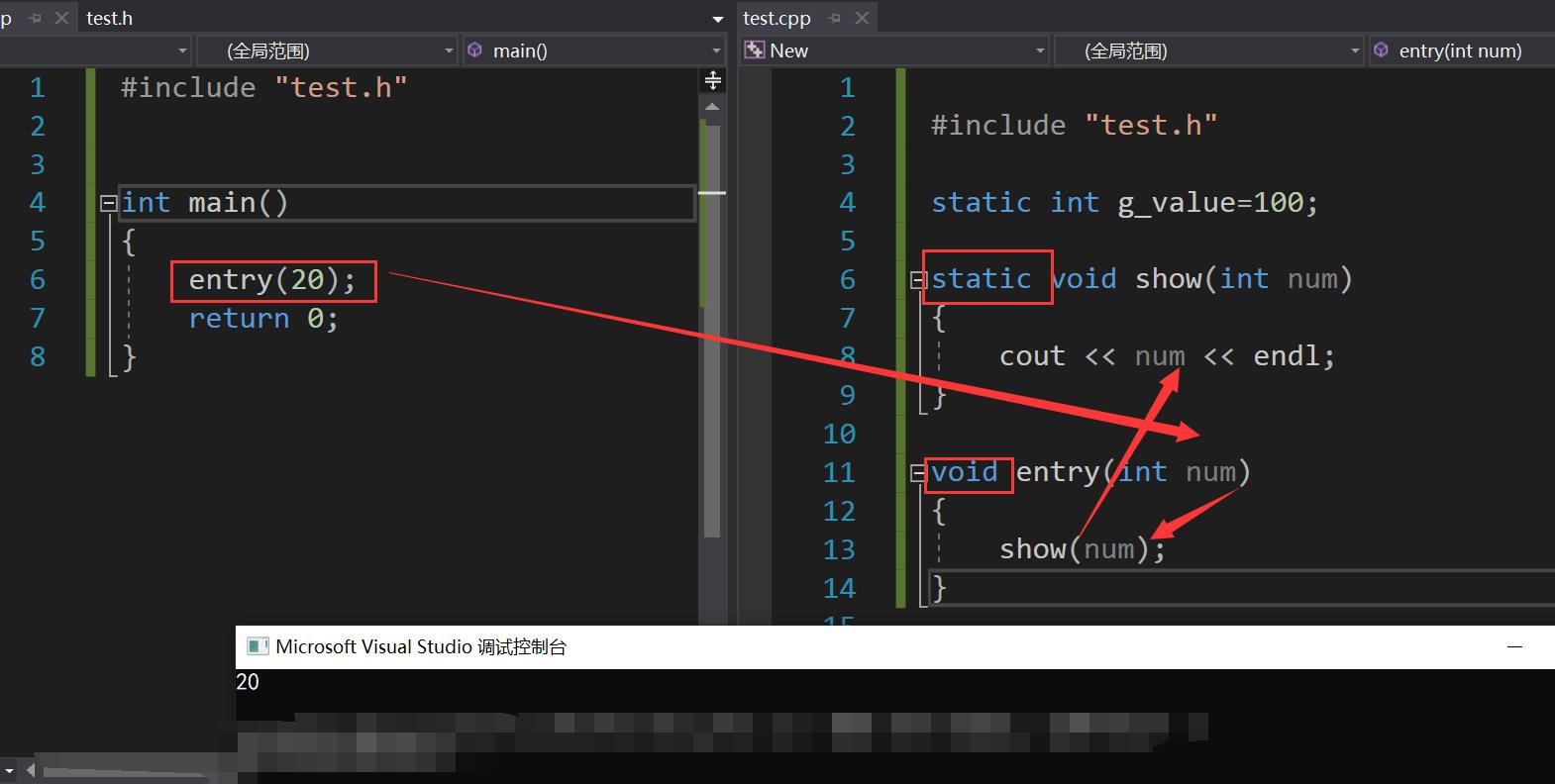
static这种功能本质为了封装,因为我们可以把一些不需要或者不想要暴露的细节保护起来了,只提供一个功能函数个,该函数在内部调用它们即可,这样的话代码安全性也比较高
(2)修饰局部变量
我们知道全局变量仅在当前代码块内有效,代码块结束之后局部变量会自动释放空间,因此下面代码的结果就会是这样
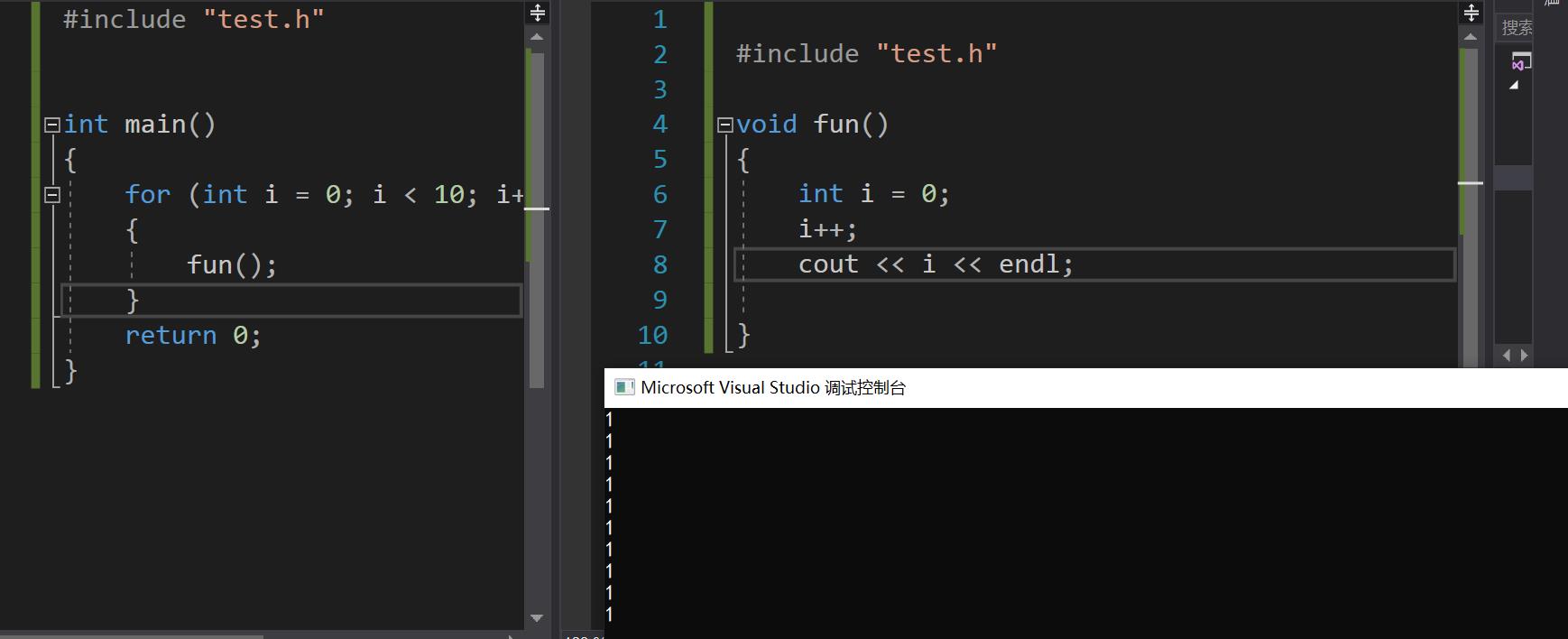
如果使用static修饰局部变量,会更改其生命周期,但其作用域不变,如下当用static修饰后,变量i地址不变,且结果累加
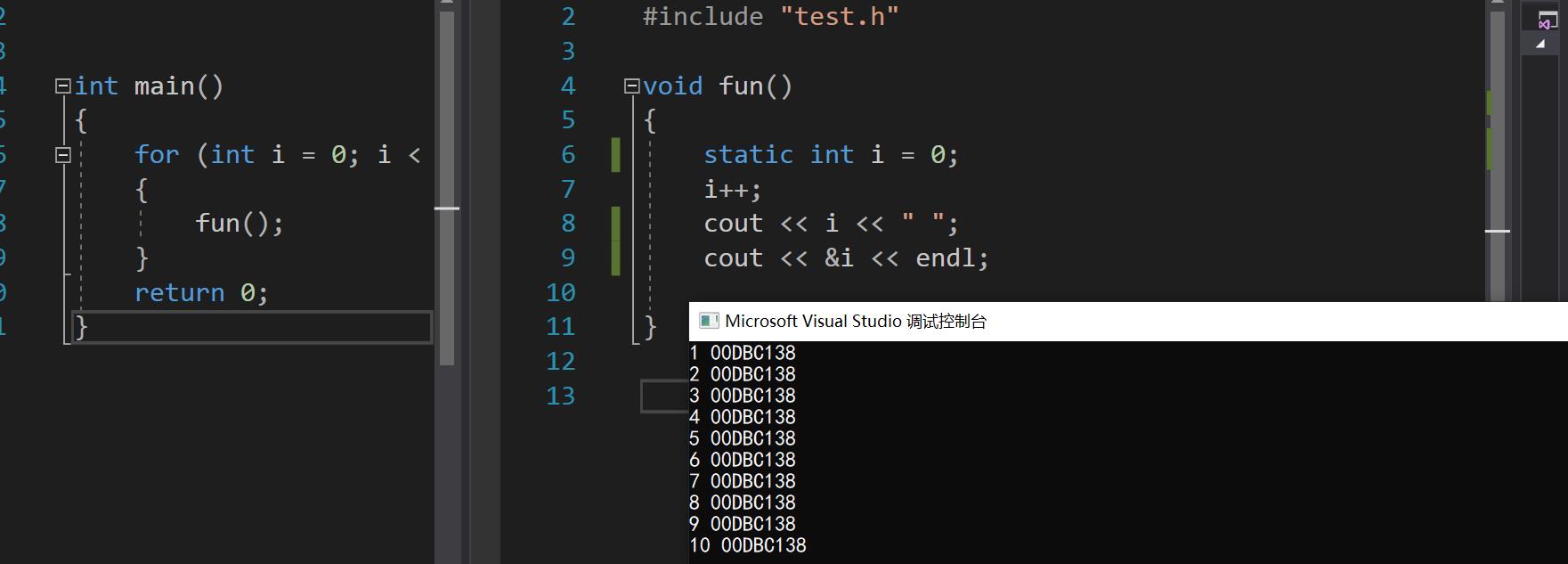
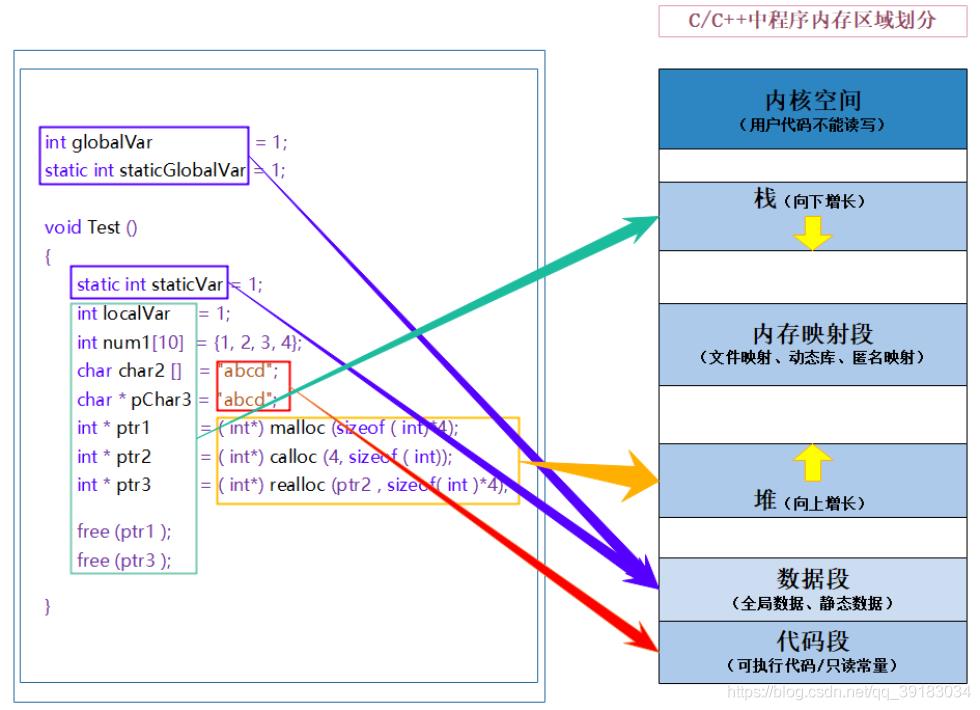
static为什么可以更改局部变量的生命周期呢?因为被static修饰的变量会将其从栈区移动到数据段,当然这就涉及到了C/C++地址空间的问题了
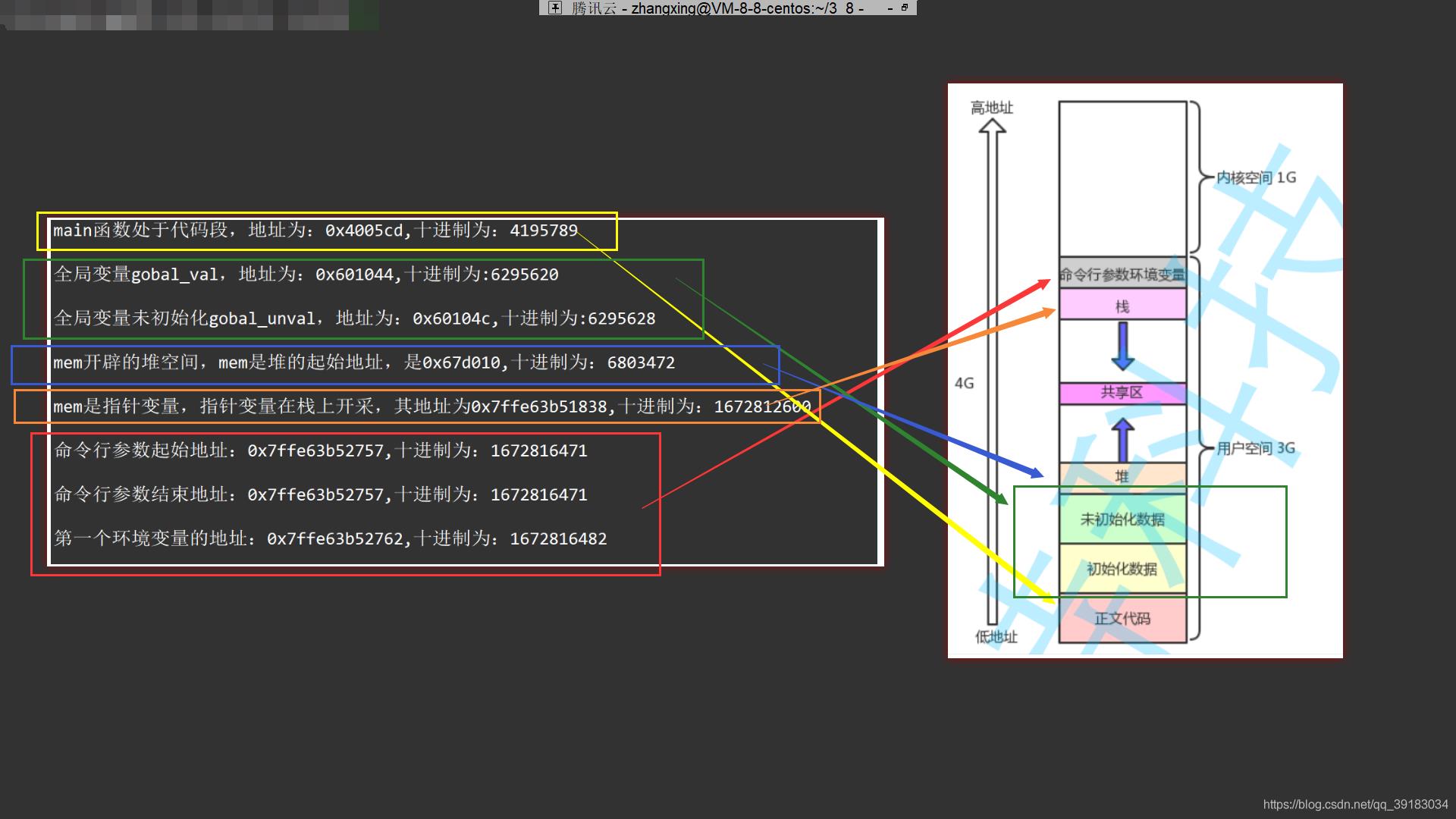
查看实际地址
#include <stdio.h>
#include <stdlib.h>
int gobal_val=100;//全局变量已经初始化
int gobal_unval;//全局变量未初始化
int main(int argc,char* argv[],char* env[])
{
printf("main函数处于代码段,地址为:%p,十进制为:%d\\n",main,main);
printf("\\n");
printf("全局变量gobal_val,地址为:%p,十进制为:%d\\n",&gobal_val,&gobal_val);
printf("\\n");
printf("全局变量未初始化gobal_unval,地址为:%p,十进制为:%d\\n",&gobal_unval,&gobal_unval);
printf("\\n");
char* mem=(char*)malloc(10);
printf("mem开辟的堆空间,mem是堆的起始地址,是%p,十进制为:%d\\n",mem,mem);
printf("\\n");
printf("mem是指针变量,指针变量在栈上开采,其地址为%p,十进制为:%d\\n",&mem,&mem);
printf("\\n");
printf("命令行参数起始地址:%p,十进制为:%d\\n",argv[0],argv[0]);
printf("\\n");
printf("命令行参数结束地址:%p,十进制为:%d\\n",argv[argc-1],argv[argc-1]);
printf("\\n");
printf("第一个环境变量的地址:%p,十进制为:%d\\n",env[0],env[0]);
printf("\\n");
}
四:sizeof关键字
sizeof用于确定一种类型对应在开辟空间的时候的大小,注意它是关键字而不是函数
它的基本用法就是下面这样,这我就不再多说了(注意Windows32位平台)
int main()
{
cout <<"char:" <<sizeof(char) << endl;
cout << "short:" << sizeof(short) << endl;
cout << "int:" << sizeof(int) << endl;
cout << "long:" << sizeof(long) << endl;
cout << "long long:" << sizeof(long long) << endl;
cout << "float:" << sizeof(float) << endl;
cout << "double:" << sizeof(double) << endl;
}

特别注意,sizeof求一种类型大小的写法共有三种,特别第三种很多人认为是错误的,而考试就爱给你整这些犄角旮旯的东西
int main()
{
int a = 10;
第一种:cout << sizeof(a) << endl;
第二种:cout << sizeof(int) << endl;
第三种:cout << sizeof a << endl;//这种写法其实也证明了sizeof不是函数
cout << sizeof int << endl;//注意这种写法是错误的
}

五:signed、unsigned关键字
这一部分需要涉及数据存储及原码反码等基础概念,请参照以下章节
第一点: 需要深刻理解signed和unsigned只是对数据的一种解读方式,其中signed会把首位数据解读为符号位,符号位用于标识其正负,unsigned的首位也算作数据位,也就是说类型决定了其读写的时候的解释方式
因此像下面的这样一句代码,看似不合适,但是它是没有问题的,因为存储时对于变量a它只关心我所开辟的空间上的二进制数据放进了没有,并不关心你之前是怎么样的
unsigned int b=-10;
-10的原码:1000 0000 0000 0000 0000 0000 0000 1010
-10的反码:1111 1111 1111 1111 1111 1111 1111 0101
-10的补码:1111 1111 1111 1111 1111 1111 1111 0110
也就是说b里面的存储的内容会按照不同的解释方式而变化
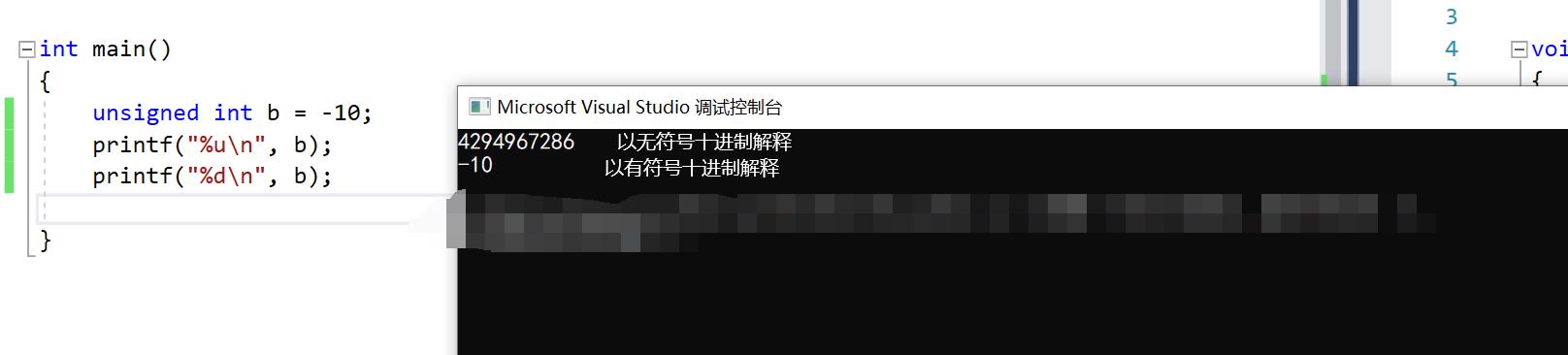
第二点: signed和unsigned也是相关C语言考试的重点,下面代码可以帮助你很好的理解
#include <windows.h>
#include <stdio.h>
#include <stdlib.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\\n", i);
Sleep(100);
}
}
由于变量i是无符号整形,因此在与0比较的时候,不会小于0,所以会死循环,并且打印时从9开始减小到0,然后接着是42亿多,然后依次减小,最后再到0

第三点:使用unsigned时初始化变量时,建议带上u,也即
unsigned int b=10u;
六:if、else
if和else如果简单点学其实也很简单,主要就是以下内容
- 0为表示假,非0表示真
- if语句执行时,必然是先执行
“()”里面的表达式或者是函数,得到真假后,然后进行判定,再进行分支功能
(1)关于C语言中bool类型
在C99之前C语言是没有bool类型的,在C00之后引入了_Bool类型,它处于头文件stdbool.h中
#include <windows.h>
#include <stdio.h>
#include <stdbool.h>
int main()
{
bool ret = false;
ret = true;
printf("%d\\n", sizeof(ret));//在vs中为1
return 0;
}
源码中显示就是一个宏定义
//
// stdbool.h
//
// Copyright (c) Microsoft Corporation. All rights reserved.
//
// The C Standard Library <stdbool.h> header.
//
#ifndef _STDBOOL
#define _STDBOOL
#define __bool_true_false_are_defined 1
#ifndef __cplusplus
#define bool _Bool
#define false 0
#define true 1
#endif /* __cplusplus */
#endif /* _STDBOOL */
/*
* Copyright (c) 1992-2010 by P.J. Plauger. ALL RIGHTS RESERVED.
* Consult your license regarding permissions and restrictions.
V5.30:0009 */
(2)float与“零值”的比较
使用if进行浮点数比较时,下面的代码正确吗?按照道理1.0-0.9=0.1,应该是正确的
int main()
{
double x = 1.0;
double y = 0.1;
if ((x - 0.9) == y)
{
printf("correct\\n");
}
else
{
printf("wrong\\n");
}
return 0;
}
但实际结果却是:

为什么会这样呢,其实这涉及到的的浮点数如何在计算机中存储的问题,详细细节请移步:
其实如果你打印出来后,你会发现两者根本不相等,精度丢失

既然浮点数比较时不能直接使用“==”,那么应该怎么办呢?
比较时,有点像高等数学中的取极限, δ \\delta δ可以被视为一个误差范围,这个 δ \\delta δ需要你自己定义,当两者的绝对值之差小于该范围时,C语言就认定他们相等,否则不相等
int main()
{
double x = 1.0;
double y = 0.1;
if (fabs((1.0 - 0.9)-0.1) < CMP)
{
printf("correct\\n");
}
else
{
printf("wrong\\n");
}
return 0;
}

这里的
δ
\\delta
δ其实C语言已经帮我们定义好了,处在float.h头文件之下
#define DBL_EPSILON 2.2204460492503131e-016 /* smallest such that 1.0+DBL_EPSILON !=1.0 */
#define FLT_EPSILON 1.192092896e-07F /* smallest such that 1.0+FLT_EPSILON !=1.0 */
回归到主题,如果0被定义为了浮点数,我们要判断某个数是否是0的话可以这样写
int main()
{
double x = 0;
if (fabs(x) < DBL_EPSILON)//注意不要写成<=
{
printf("x是0\\n");
}
else
{
printf("x不是0\\n");
}
return 0;
}

(3)if和else的匹配问题
这是一个老生常谈的话题。下面代码看似会输出“2”,但实际什么都不会输出
int main()
{
int x = 0;
int y = 1;
if (10 == x)
if (11 == y)
printf("1\\n");
else
printf("2\\n");
return 0;
}
这属于代码风格问题,else匹配采用的是就近原则
七:switch-case组合
第一: switch case的基本语法结构
switch(整型变量/常量/整型表达式)//注意只能这三种
{
case var1://判断在这里
break;
case var2:
break;
case var3:
break;
default:
break;
}
其中case完成的判断功能,break完成的是分支功能,所以如果忘记写break,就会导致击穿现象
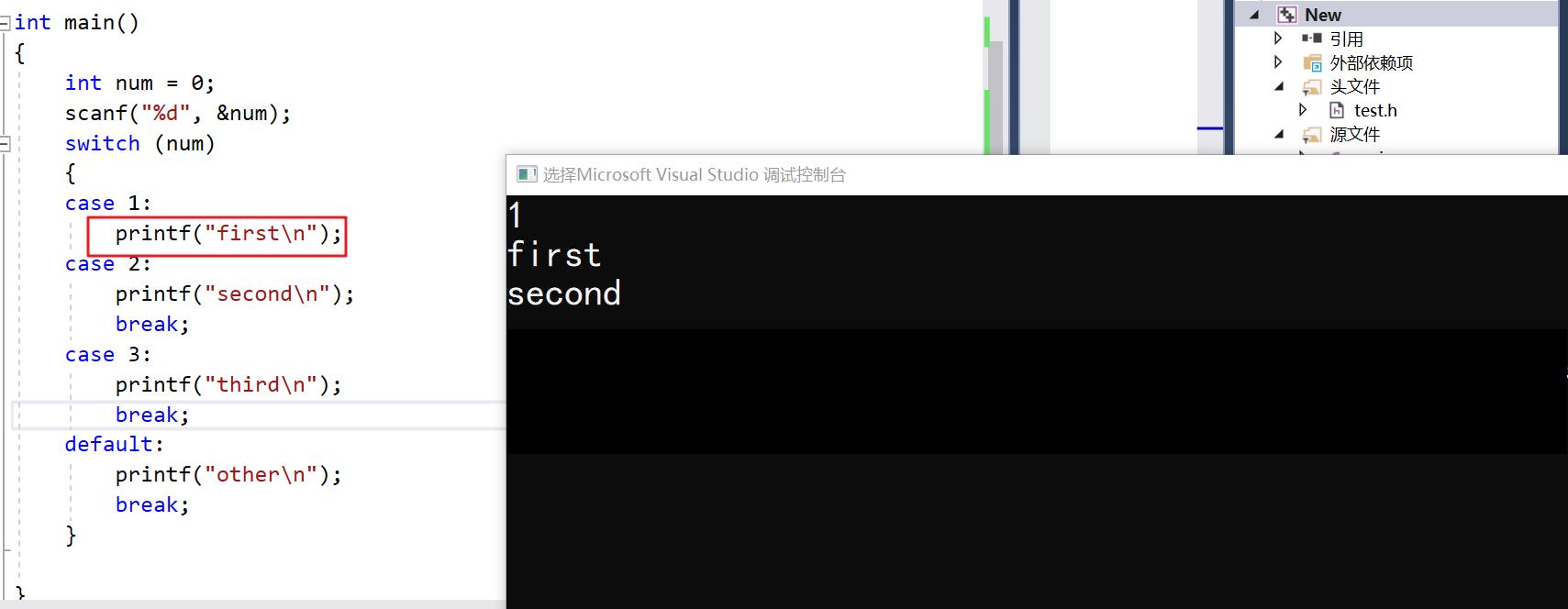
第二: 注意一个语法细节,就是case里面如果要定义变量的话,必须加花括号
int main()
{
int num = 0;
scanf("%d", &num);
switch (num)
{
case 1:
{
int a = 1;//注意花括号
printf("first\\n");
break;
}
case 2:
printf("second\\n");
break;
case 3:
printf("third\\n");
break;
default:
printf("other\\n");
break;
}
}
第三: 多条件匹配时可以这样写
int main()
{
int num = 0;
scanf("%d", &num);
switch (num)
{
case 1:
case 2:
case 3:
printf("first\\n");
break;
case 4:
case 5:
printf("second\\n");
break;
default:
printf("other\\n");
break;
}
}
第四: 注意default可以放在任意位置
第五: switch中可以使用return语句,但不建议使用
八:do 、while 、for关键字
第一: 这三种循环基本语法如下
//while
条件初始化
while(条件判定){
//业务更新
条件更新
}
//for
for(条件初始化; 条件判定; 条件更新){
//业务代码
}
//do while
条件初始化
do{
条件更新
}while(条件判定)
第二: 三种循环对应的死循环写法如下
while(1){
}
for(;;){
}
do{
}while(1);
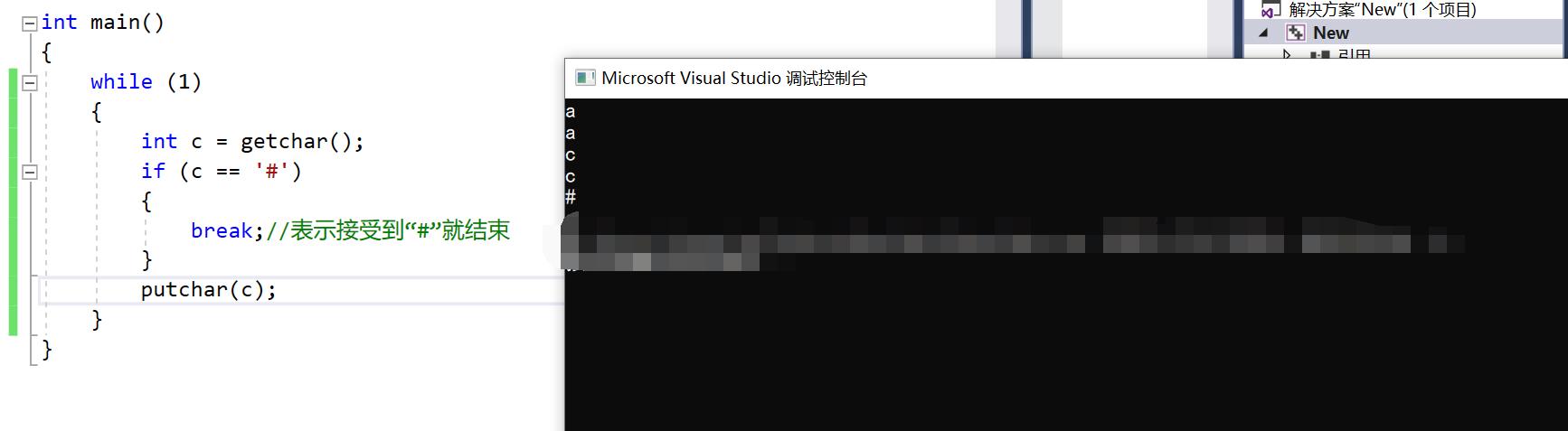
第三: break是跳出该循环,continue是结束一次循环
int main()
{
while (1)
{
int c = getchar();
if (c == '#')
{
break;//表示接受到“#”就结束
}
putchar(c);
}
}
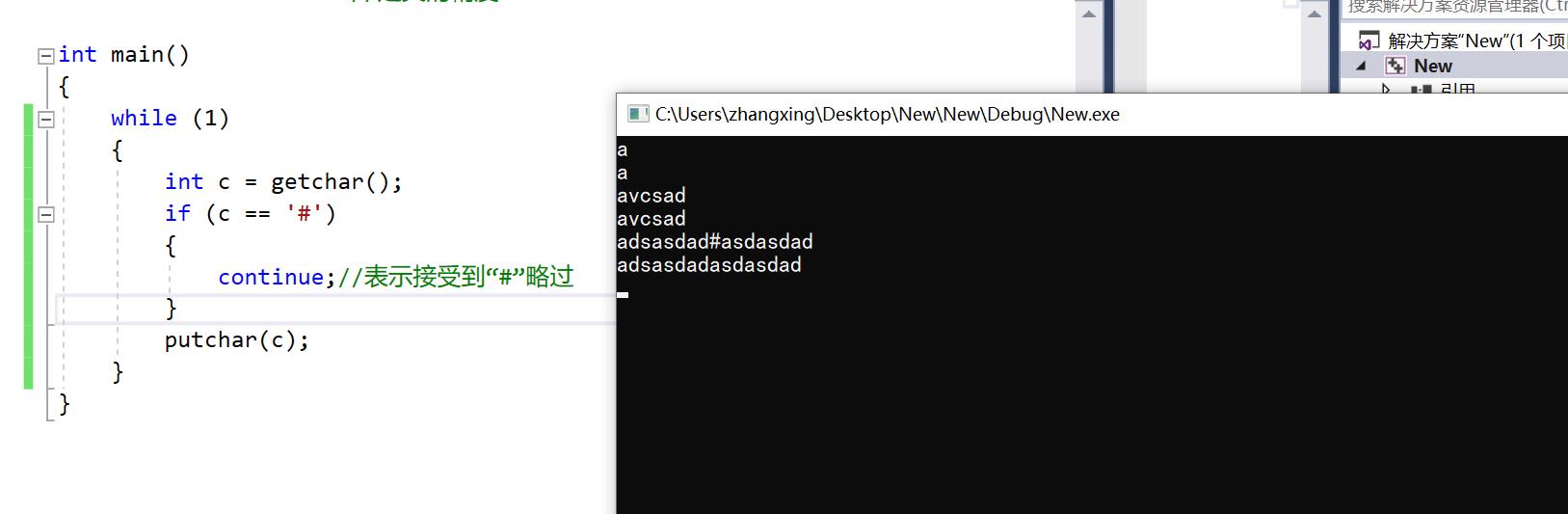
int main()
{
while (1)
{
int c = getchar();
if (c == '#')
{
continue;//表示接受到“#”略过
}
putchar(c);
}
}
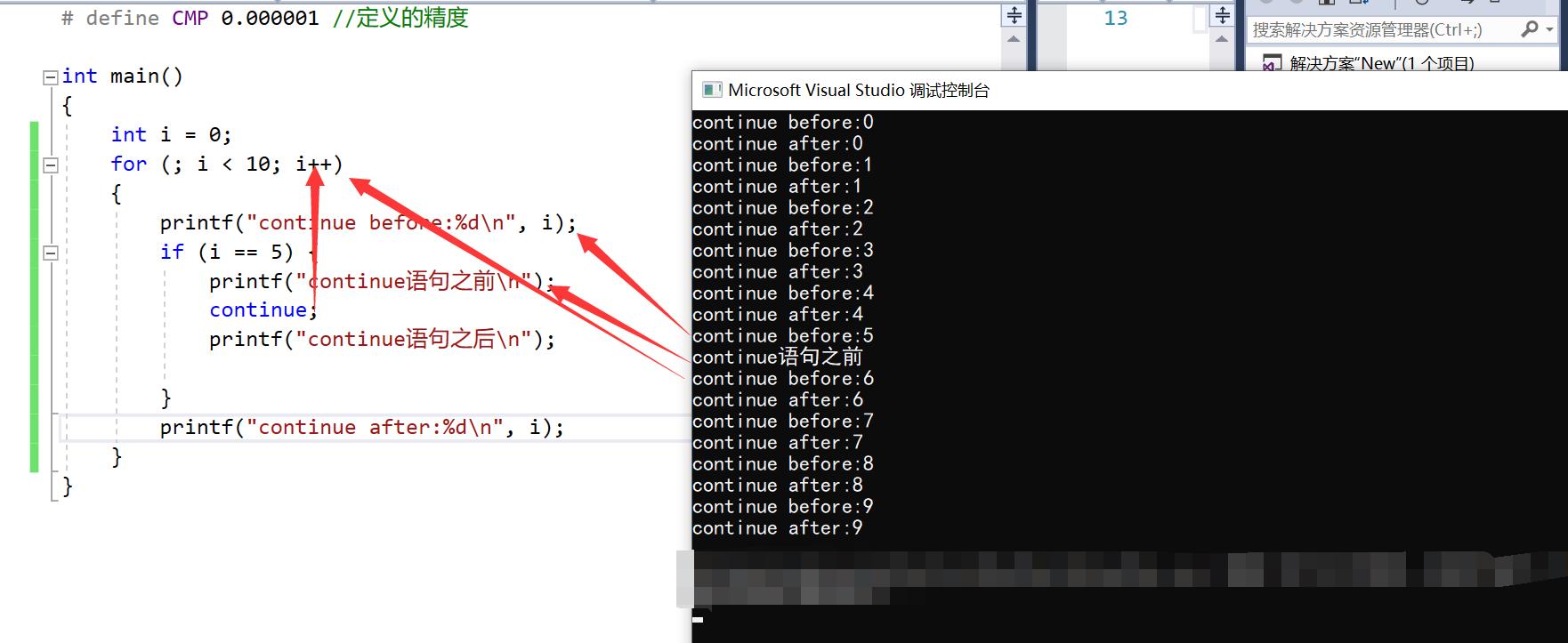
这里需要注意for循环的continue,经常爱考察。for循环在continue时是跳到循环更新处
int main()
{
int i = 0;
for (; i < 10; i++)
{
printf("continue before:%d\\n", i);
if (i == 5) {
printf("continue语句之前\\n");
continue;
printf("continue语句之后\\n");
}
printf("continue after:%d\\n", i);
}
}
第四: for循环区间建议是前闭后开
for(int i=0;i<10;i++)
{
//循环10次
}
for(int i=6;i<10;i&#以上是关于C语言重点难点精讲关键字精讲的主要内容,如果未能解决你的问题,请参考以下文章