js的搜索遍历精讲
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了js的搜索遍历精讲相关的知识,希望对你有一定的参考价值。
搜索算法应该算是每种算法的重点与难点了,本文将讲解javascript中的各种常用的遍历算法;希望对大家有所帮助。
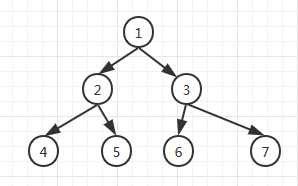
深度优先遍历顺序:1245367 广度优先遍历:1234567
1.深度优先遍历:分为递归与非递归两种方法。
规则:从初始访问结点出发,我们知道初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点。总结起来可以这样说:每次都在访问完当前结点后首先访问当前结点的第一个邻接结点.
具体算法表述如下:
-
访问初始结点v,并标记结点v为已访问。
-
查找结点v的第一个邻接结点w。
-
若w存在,则继续执行4,否则算法结束。
-
若w未被访问,对w进行深度优先遍历递归(即把w当做另一个v,然后进行步骤123)。
-
查找结点v的w邻接结点的下一个邻接结点,转到步骤3
递归算法
function traverseDF(node,nodeList){ if(node){ nodeList.push(node); for(var i=0;i<node.children.length;i++){ traverseDF(node.children[i],nodeList); } } }
非递归算法
function deepTraversal(node) { var nodes = []; if (node != null) { var stack = []; stack.push(node); while (stack.length != 0) { var item = stack.pop(); nodes.push(item); var children = item.children; for (var i = children.length - 1; i >= 0; i--) stack.push(children[i]); } } return nodes; }
非递归算法的效率会优于递归算法,因为递归算法在需要一次次的调用函数,而调用函数时需要比如准备函数内局部变量使用的空间、搞定函数的参数等等,这些事情每次调用函数都需要做,因此会产生额外开销导致递归效率偏低,所以逻辑上开销一致时递归的额外开销会多一些;非递归算法就是单独创建了一个”队列“,解决了递归算法的内存溢出问题。
2.广度优先算法,类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来访问这些结点的邻接结点。
具体算法表述如下:
-
访问初始结点v并标记结点v为已访问。
-
结点v入队列
-
当队列非空时,继续执行,否则算法结束。
-
出队列,取得队头结点u。
-
查找结点u的第一个邻接结点w。
-
若结点u的邻接结点w不存在,则转到步骤3;否则循环执行以下三个步骤:
1). 若结点w尚未被访问,则访问结点w并标记为已访问。
2). 结点w入队列
3). 查找结点u的继w邻接结点后的下一个邻接结点w,转到步骤6。
递归算法
function wideTraversal(node) { var nodes = []; var i = 0; if (!(node == null)) { nodes.push(node); wideTraversal(node.nextElementSibling); node = nodes[i++]; wideTraversal(node.firstElementChild); } return nodes; }
非递归算法
function wideTraversal(selectNode) { var nodes = []; if (selectNode != null) { var queue = []; queue.unshift(selectNode); while (queue.length != 0) { var item = queue.shift(); nodes.push(item); var children = item.children; for (var i = 0; i < children.length; i++) queue.push(children[i]); } } return nodes; }
前序,中序,后序遍历,前,后,中是相对于根节点而言的,前序及首先遍历根节点,中序及首先访问左子节点,然后才访问根节点,最后访问右子节点。
//前序遍历 function preOrder(node) { if (!(node == null)) { divList.push(node); preOrder(node.firstElementChild); preOrder(node.lastElementChild); } } //中序遍历 function inOrder(node) { if (!(node == null)) { inOrder(node.firstElementChild); divList.push(node); inOrder(node.lastElementChild); } } //后序遍历 function postOrder(node) { if (!(node == null)) { postOrder(node.firstElementChild); postOrder(node.lastElementChild); divList.push(node); } }
以上是关于js的搜索遍历精讲的主要内容,如果未能解决你的问题,请参考以下文章