5300亿NLP模型“威震天-图灵”发布,由4480块A100训练,微软英伟达联合出品
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5300亿NLP模型“威震天-图灵”发布,由4480块A100训练,微软英伟达联合出品相关的知识,希望对你有一定的参考价值。
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
5300亿参数!全球最大规模NLP模型诞生。
由微软联手英伟达推出,名叫威震天-图灵自然语言生成模型(Megatron Turing-NLG)。

据他们介绍,这样的量级不仅让它成为全球规模最大,同时也是性能最强的NLP模型。
训练过程一共使用了4480块英伟达A100 GPU,最终使该模型在一系列自然语言任务中——包括文本预测、阅读理解、常识推理、自然语言推理、词义消歧——都获得了前所未有的准确率。
三倍规模于GPT-3
此模型简称MT-NLG,是微软Turing NLG和英伟达Megatron-LM两者的“继任者”。
Turing NLG由微软于2020年2月推出,参数为170亿;Megatron-LM来自英伟达,2019年8月推出,参数83亿。
它俩在当时分别是第一、二大规模的Transfomer架构模型。
我们都知道大参数规模的语言模型效果会更好,但训练起来也很有挑战性,比如:
即使是最大容量的GPU,也存不下如此规模的参数;
如果不特别注意优化算法、软件和硬件堆栈,那么所需的大量计算操作可能会导致训练时间过长。
那这个参数已是GPT-3三倍的MT-NLG又是如何解决的呢?
答案就是汲取“两家”所长,融合英伟达最先进的GPU加速训练设备,以及微软最先进的分布式学习系统,来提高训练速度。

并用上千亿个token构建语料库,共同开发训练方法来优化效率和稳定性。
具体来说,通过借鉴英伟达Megatron-LM模型的GPU并行处理,以及微软开源的分布式训练框架DeepSpeed,创建3D并行系统。
对于本文中这个5300亿个参数的模型,每个模型副本跨越280个NVIDIA A100 GPU,节点内采用Megatron-LM的8路张量切片(tensor-slicing),节点间采用35路管道并行(pipeline parallelism)。
然后再使用DeepSpeed的数据并行性进一步扩展到数千个GPU。
最终在基于NVIDIA DGX SuperPOD的Selene超级计算机上完成混合精度训练。
(该超级计算机由560个DGX A100服务器提供支持,每个DGX A100有8个 NVIDIA A100 80GB Tensor Core GPU,通过NVLink 和 NVSwitch相互完全连接)。
该模型使用了Transformer解码器的架构,层数、hidden dimension和attention head分别为 105、20480和128。
训练所用数据集包括近20万本书的纯文本数据集Books3、问答网站Stack Exchange、维基百科、学术资源网站PubMed Abstracts、ArXiv、维基百科、GitHub等等,这些都是从他们先前搭建的Pile数据集中挑出的质量较高的子集。
最终一共提取了2700亿个token。

五大任务上的准确度测试
开发者在以下5大任务上对MT-NLG进行了准确度测试。
在文本预测任务LAMBADA中,该模型需预测给定段落的最后一个词。
在阅读理解任务RACE-h和BoolQ中,模型需根据给定的段落生成问题的答案。
在常识推理任务PiQA、HellaSwag和Winogrande中,每个任务都需要该模型具有一定程度的常识了解。
对于自然语言推理,两个硬基准,ANLI-R2和HANS考验先前模型的典型失败案例。
词义消歧任务WiC需该模型从上下文对多义词进行理解。
结果该模型在PiQA开发集和LAMBADA测试集上的零样本、单样本和少样本三种设置中都获得了最高的成绩。
在其他各项任务上也获得了最佳。

除了报告基准任务的汇总指标外,他们还对模型输出进行了定性分析,并观察到,即使符号被严重混淆,该模型也可以从上下文中推断出基本的数学运算。
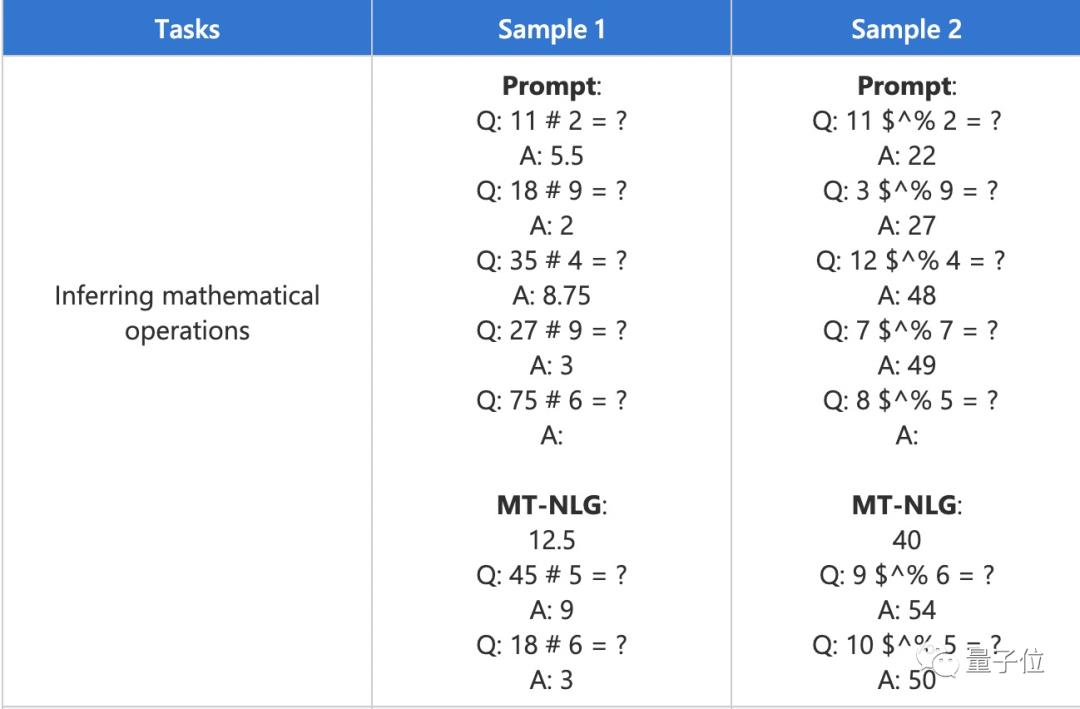
当然,该模型也从数据中也提取出了刻板印象和偏见。微软和英伟达表示也在解决这个问题。
另外,他们表示在生产场景中使用MT-NLG都必须遵守微软的“负责任的AI原则”来减少输出内容的负面影响,但目前该模型还未公开。
参考链接:
https://www.microsoft.com/en-us/research/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/
以上是关于5300亿NLP模型“威震天-图灵”发布,由4480块A100训练,微软英伟达联合出品的主要内容,如果未能解决你的问题,请参考以下文章
5300亿NLP模型“威震天-图灵”发布,由4480块A100训练,微软英伟达联合出品