python爬虫招聘网站(智联)
Posted 鈴音.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫招聘网站(智联)相关的知识,希望对你有一定的参考价值。
爬虫目标
要求:搜索“大数据”专业,爬相关公司的招聘信息。列数不少于10列,行数不少于3000 。
目标:搜索“大数据”,爬取智联招聘 北京上海广州深圳天津武汉西安 职位名称,企业名称,薪资,什么市(区),学历要求,经验要求,公司规模,公司性质,工作类型,详情页链接https
具体过程
登录网站,搜索大数据,右键查看网页源代码
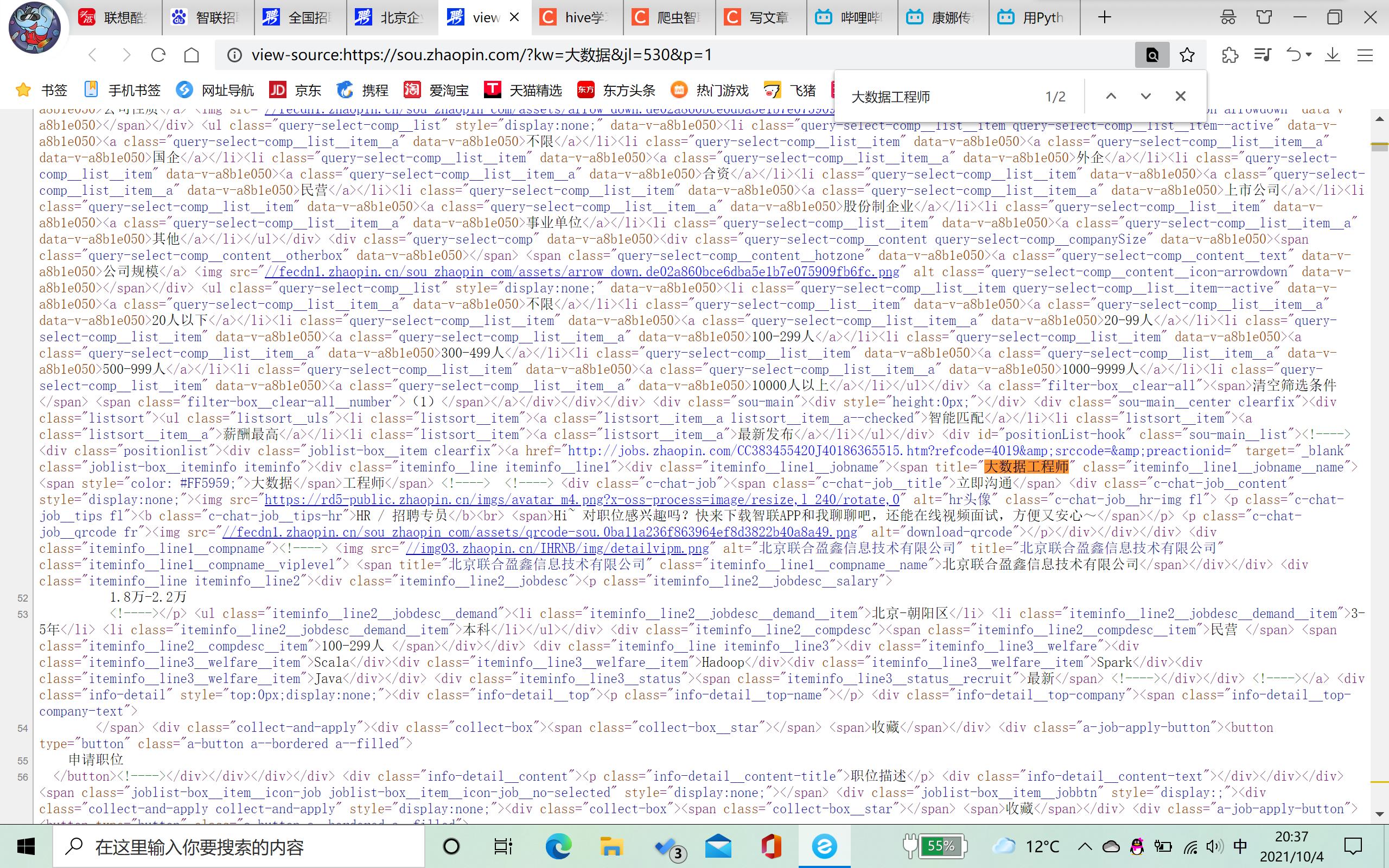
Ctrl+F搜索大数据工程师,发现数据都在网页源代码中

基本思路有了,可用正则直接在源码里匹配得到数据,也可以打开开发者工具抓包分析接口用scrapy爬。这篇博客用正则表达式匹配。
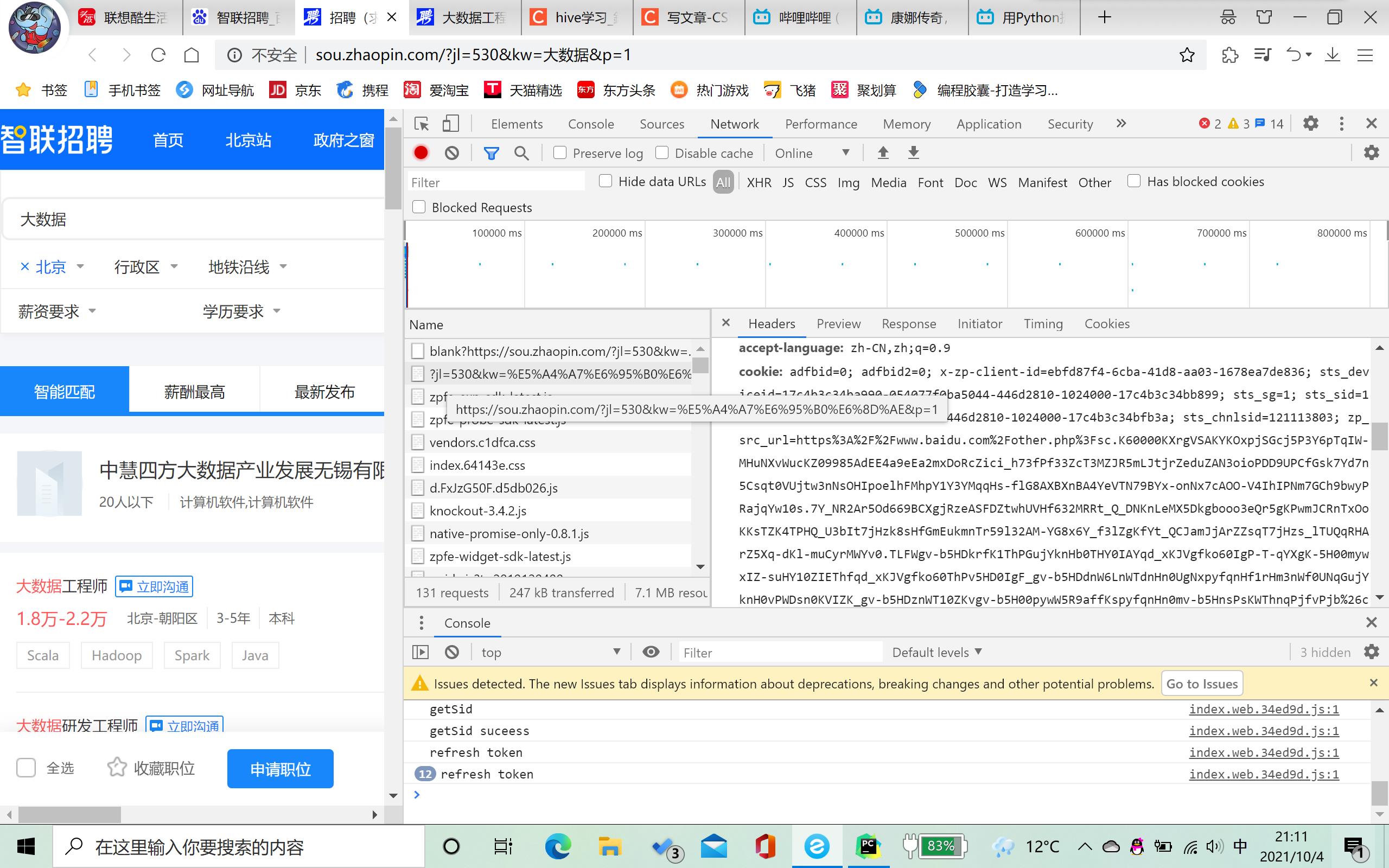
pycharm响应成功。
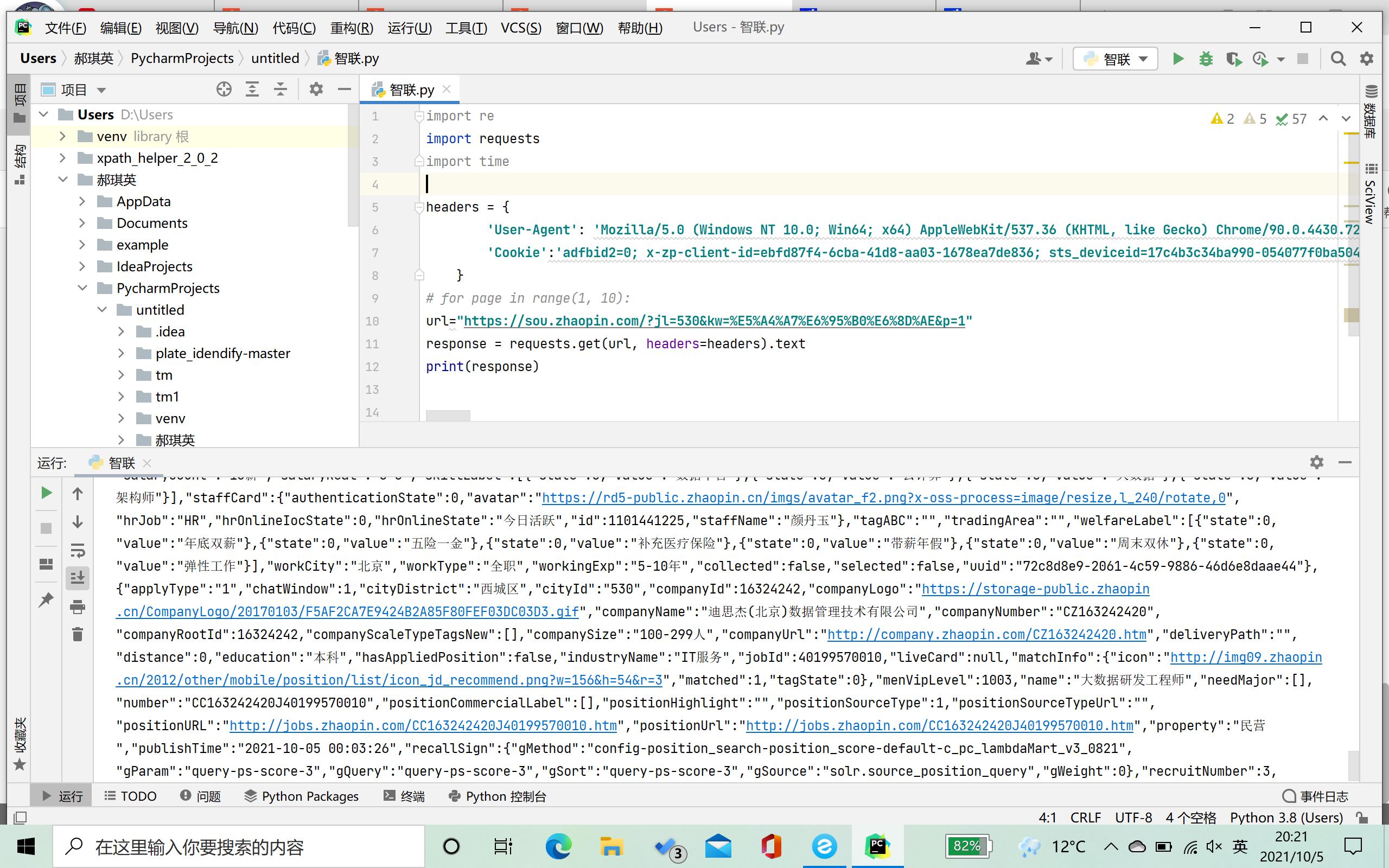
然后用正则写代码就行了。
源码
import re
import requests
import time
headers = {'User-Agent': '登陆后自己的user-agent',
'Cookie':'登陆后自己的cookie' }
for page in range(1,28):
#北京上海广州深圳天津武汉西安的url
url=f"https://sou.zhaopin.com/?jl=854&kw=%E5%A4%A7%E6%95%B0%E6%8D%AE&p={page}"
time.sleep(5)
#停顿5秒
response = requests.get(url, headers=headers).text
for i in range(30):
#每页有最多30条数据
name = re.findall(r'"matchInfo":.*?"name":"(.*?)"', response)[i] #工作名称
companyName = re.findall(r'"companyName":"(.*?)"', response)[i]
cityDistrict=re.findall(r'"cityDistrict":"(.*?)"',response)[i]
education=re.findall(r'"education":"(.*?)"',response)[i] #学历
salary60=re.findall(r'"salary60":"(.*?)"',response)[i] #薪资
workingExp=re.findall(r'"workingExp":"(.*?)"',response)[i] #经验要求
property=re.findall(r'"property":"(.*?)"',response)[i] #公司性质
companySize=re.findall(r'"companySize":"(.*?)"',response)[i] #公司规模
workType = re.findall(r'"workType":"(.*?)"', response)[i] #工作类型
positionURL=re.findall(r'"positionURL":"(.*?)"',response)[i]#详情页链接
f = open('zhilian.csv', 'a', encoding='utf8')
f.write('{},{},{},{},{},{},{},{},{},{}\\n'.format(name, companyName, cityDistrict,education,salary60,workingExp,property,companySize,workType,positionURL))
f.close()
以上是关于python爬虫招聘网站(智联)的主要内容,如果未能解决你的问题,请参考以下文章
携程智联等网站百分之60%的访问量都是爬虫,对此我们应该怎么办