可配置智联爬虫
Posted liangliangzz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可配置智联爬虫相关的知识,希望对你有一定的参考价值。
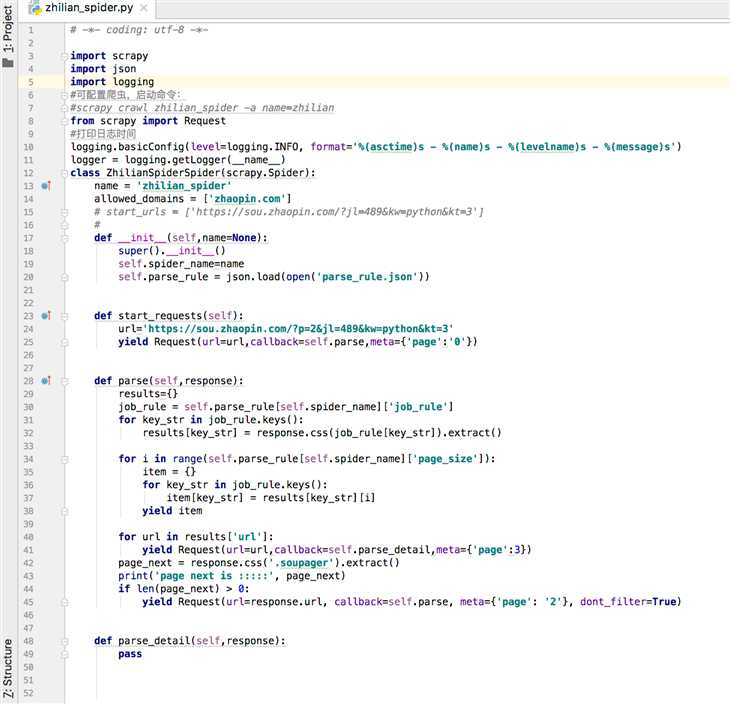
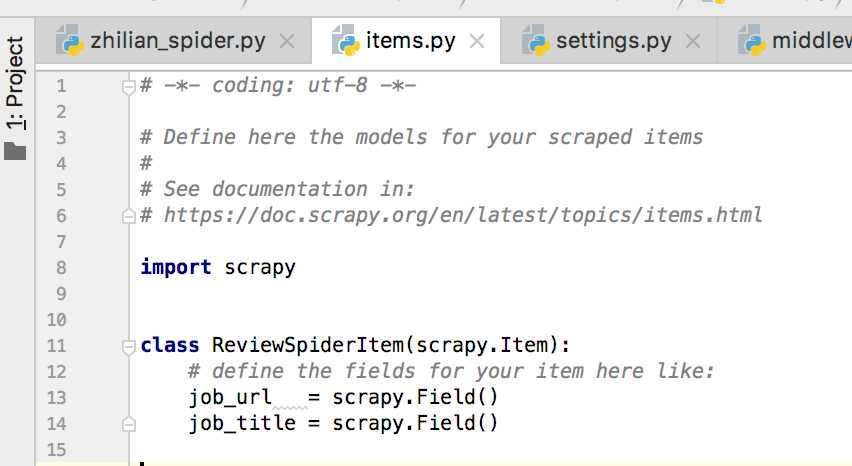
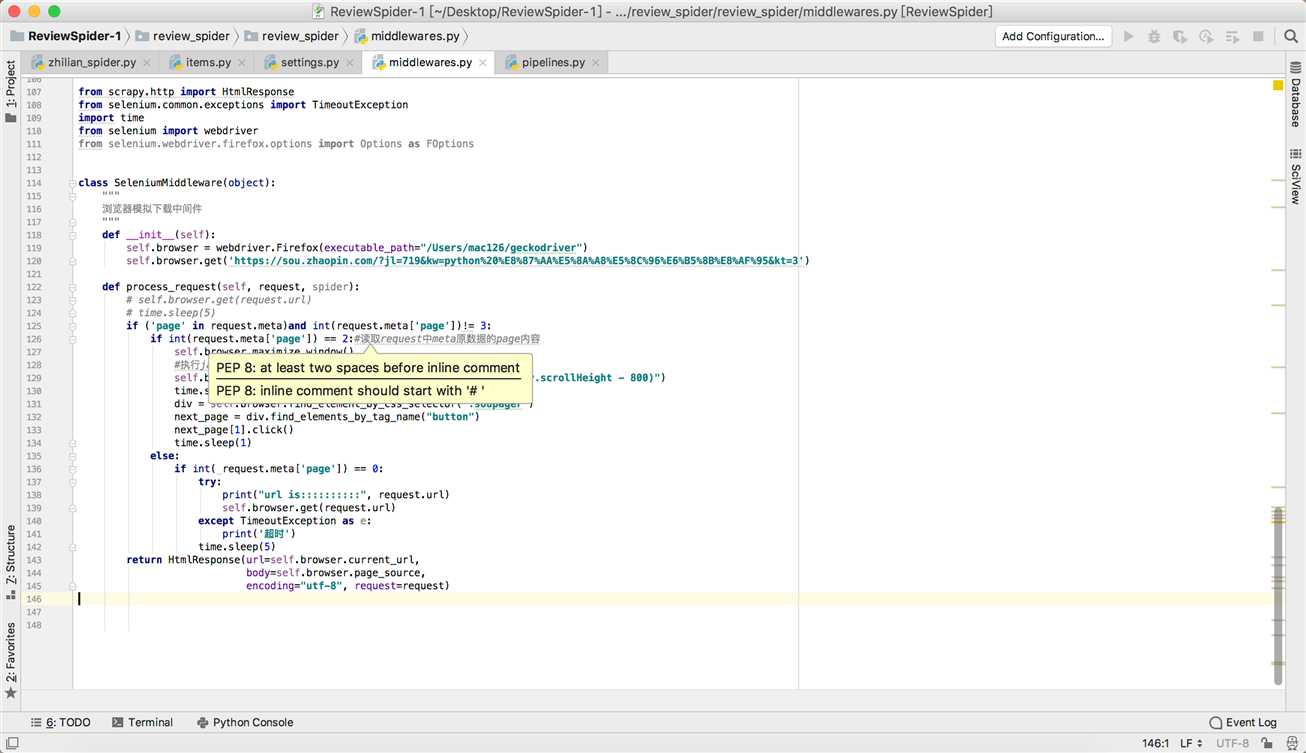
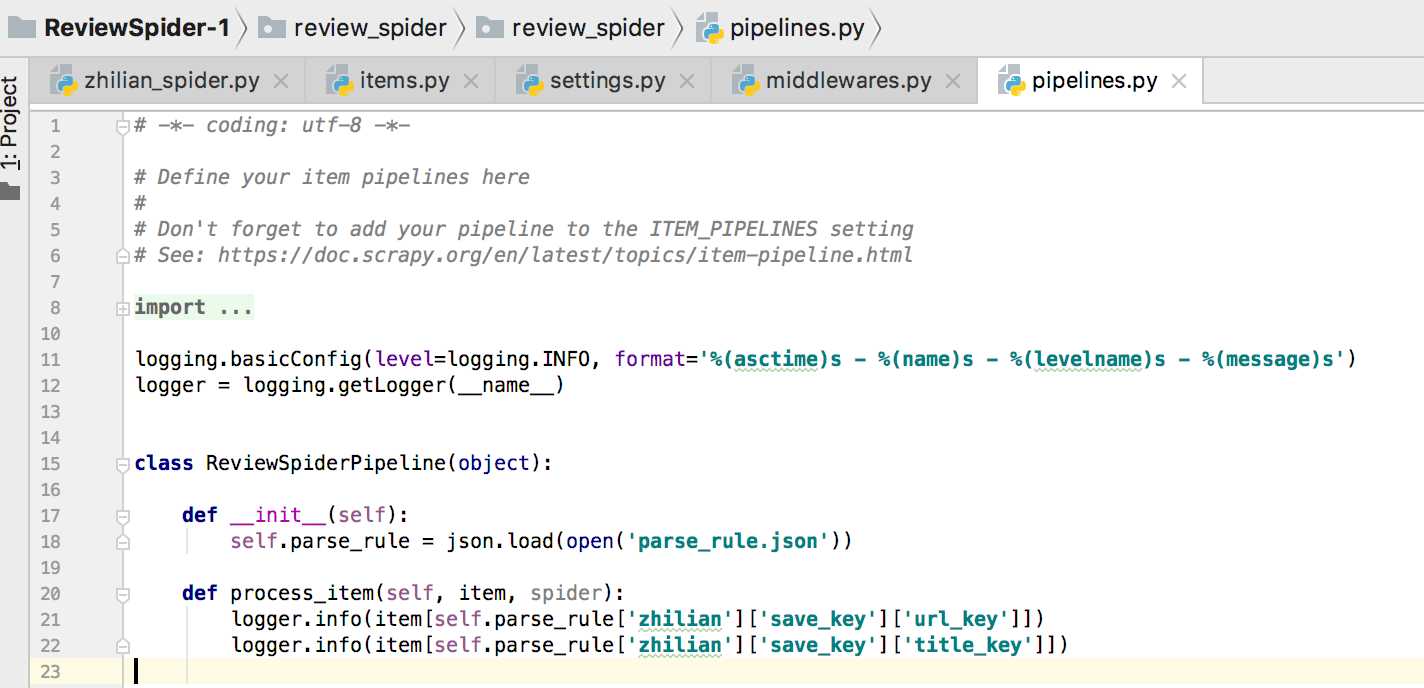
settings.py # -*- coding: utf-8 -*- # Scrapy settings for review_spider project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = ‘review_spider‘ SPIDER_MODULES = [‘review_spider.spiders‘] NEWSPIDER_MODULE = ‘review_spider.spiders‘ # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = ‘review_spider (+http://www.yourdomain.com)‘ # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, # ‘Accept-Language‘: ‘en‘, #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # ‘review_spider.middlewares.ReviewSpiderSpiderMiddleware‘: 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { #‘review_spider.middlewares.ReviewSpiderDownloaderMiddleware‘: 543, ‘review_spider.middlewares.SeleniumMiddleware‘: 520, } # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # ‘scrapy.extensions.telnet.TelnetConsole‘: None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { ‘review_spider.pipelines.ReviewSpiderPipeline‘: 300, } # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = ‘httpcache‘ #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage‘ LOG_FILE = "ZhilianSpiderSpider.log" LOG_LEVEL = "INFO" # LOG_STDOUT=True LOG_LEVEL_1 = "ERROR"
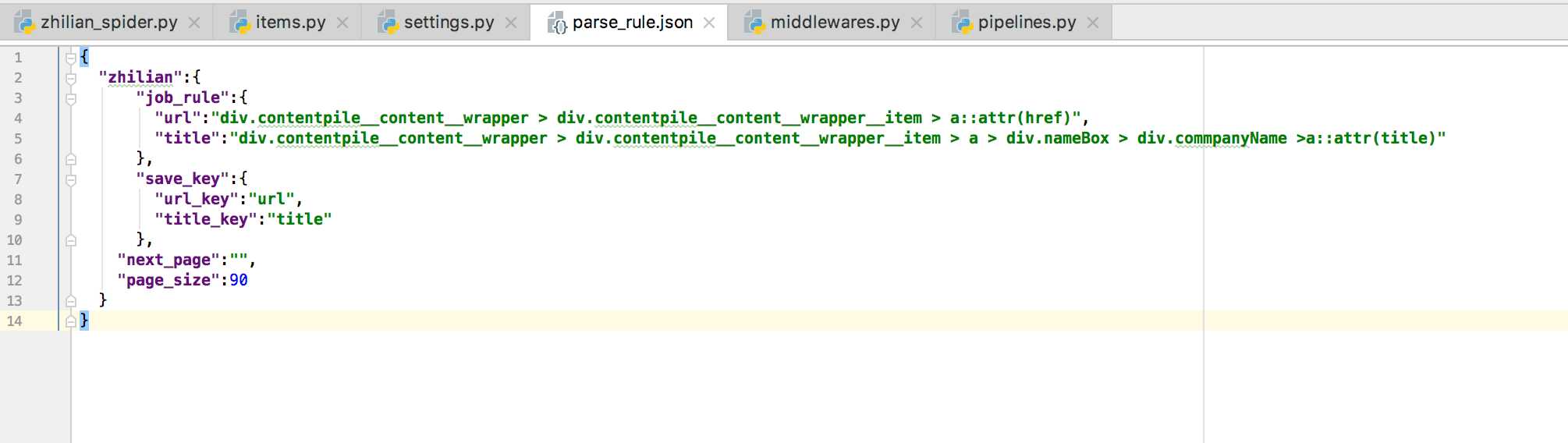
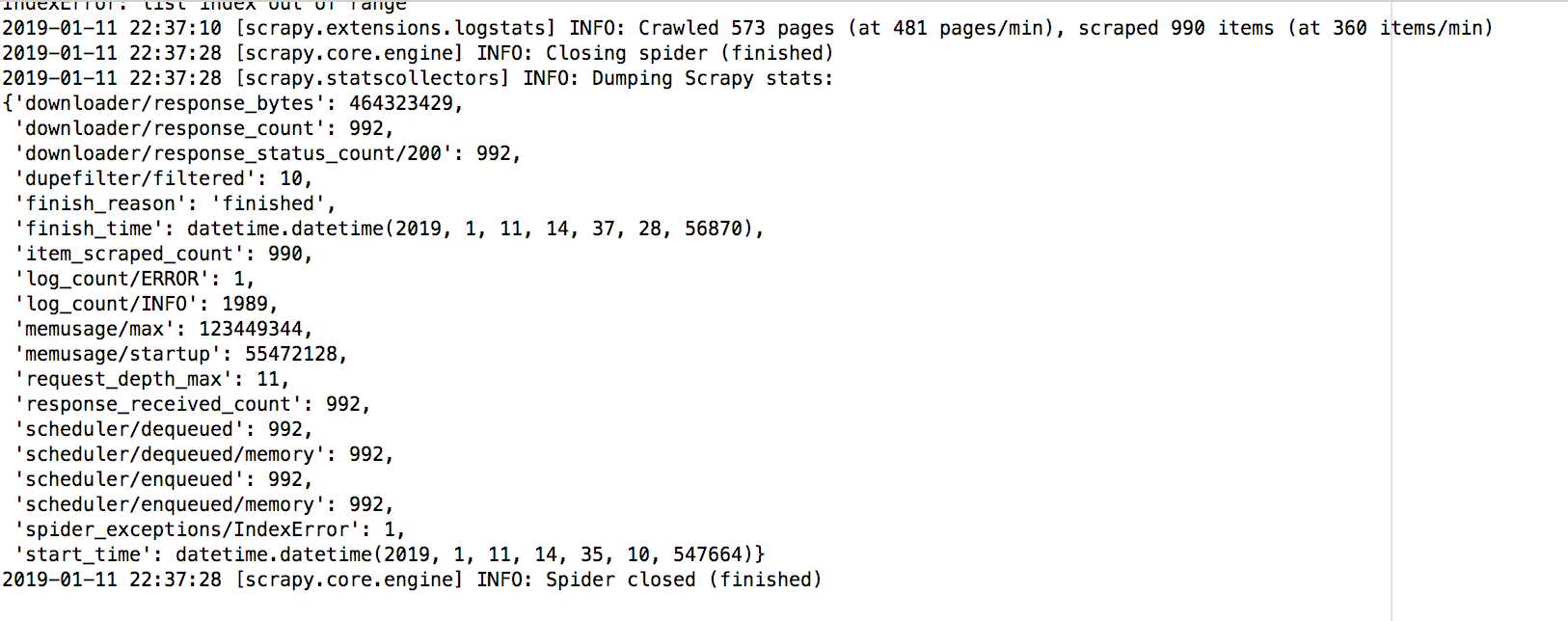
以上是关于可配置智联爬虫的主要内容,如果未能解决你的问题,请参考以下文章
携程智联等网站百分之60%的访问量都是爬虫,对此我们应该怎么办