学习笔记Spark—— Spark入门
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Spark—— Spark入门相关的知识,希望对你有一定的参考价值。
一、Spark简介
什么是Spark?
- 快速、分布式、可扩展、容错的集群计算框架;
- Spark是基于内存计算的大数据分布式计算框架;
- 低延迟的复杂分析;
- Spark是Hadoop MapReduce的替代方案。
二、Spark的发展历史
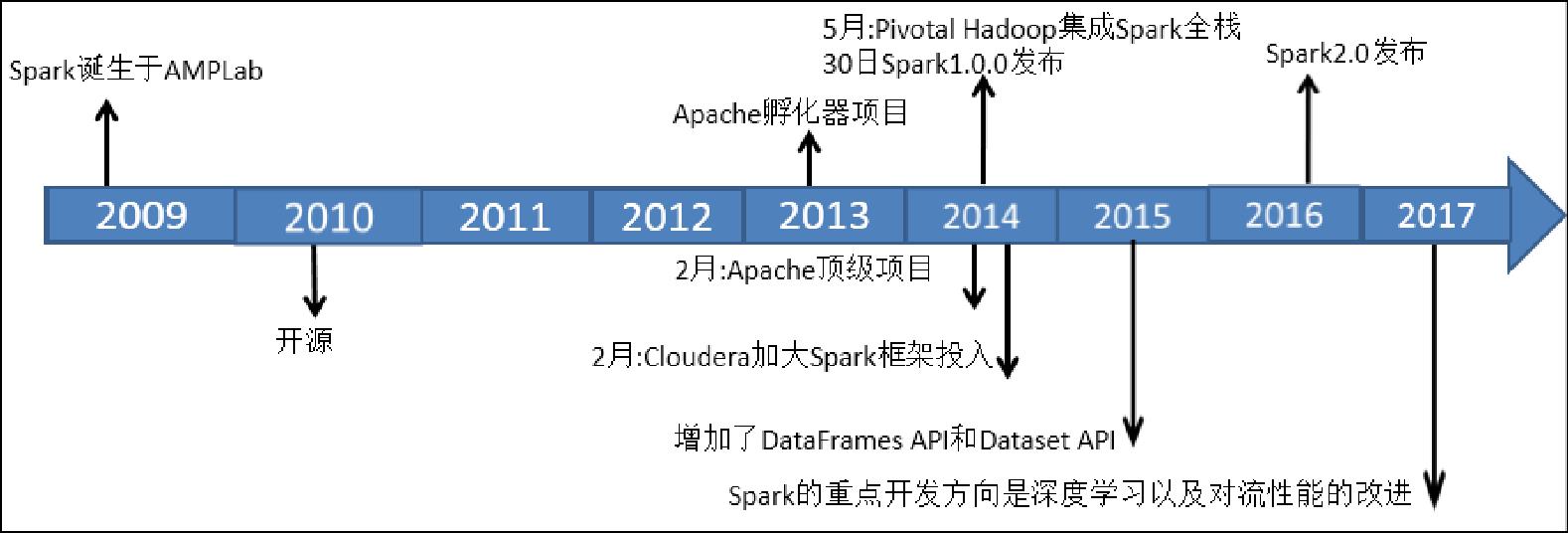
对于一个具有相当技术门槛与复杂度的平台,Spark从诞生到正式版本的成熟,经历的时间如此之短,让人感到惊诧。目前,Spark已经成为Apache软件基金会旗下的顶级开源项目。下面是Spark的发展历程简述:
- 2009年,Spark诞生于伯克利大学AMPLab,最初属于伯克利大学的研究性项目,实验室的研究人员之前基于Hadoop MapReduce工作,他们发现MapReduce对于迭代和交互式计算任务效率不高,因此他们研究的Spark主要为交互式查询和迭代算法设计,支持内存存储和高效的容错恢复。
- 2010年Spark正式开源。
- 2013年6月成为了Apache基金会的孵化器项目。
- 2014年2月,仅仅经历8个月的时间Spark就成为Apache基金会的顶级项目,同时,大数据公司Cloudera宣称加大Spark框架的投入来取代MapReduce。
- 2014年5月,Pivotal Hadoop集成Spark全栈,同月30日,Spark1.0.0发布。
- 2015年Spark增加了新的DataFrames API和Dataset API
- 2016年Spark2.0发布,Spark2.0与1.0的区别主要是2.0修订了API的兼容性问题。
- 2017年在美国旧金山举行Spark Summit 2017,会议介绍2017年Spark的重点开发方向是深度学习以及对流性能的改进。
三、Spark的特点
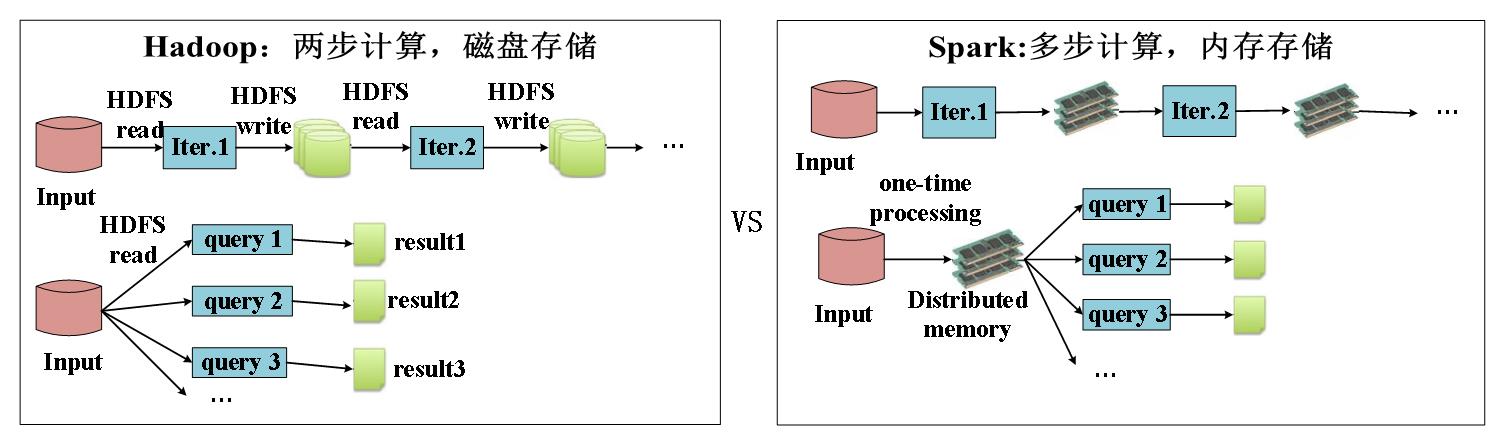
1、快速
一般情况下,对于迭代次数较多的应用程序,Spark程序在内存中的运行速度是Hadoop MapReduce运行速度的100多倍,在磁盘上的运行速度是Hadoop MapReduce运行速度的10多倍。

2、易用性
Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高级运算符,使得编写并行应用程序变得容易并且可以在Scala、Python或R的交互模式下使用Spark。
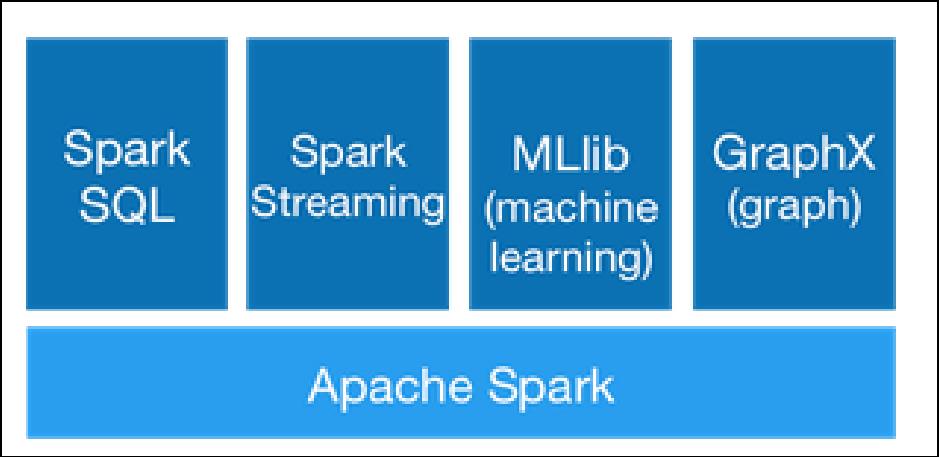
3、通用性
Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming,并且支持在一个应用中同时使用这些组件
4、随处运行
用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据
5、代码简洁
四、Spark的生态圈
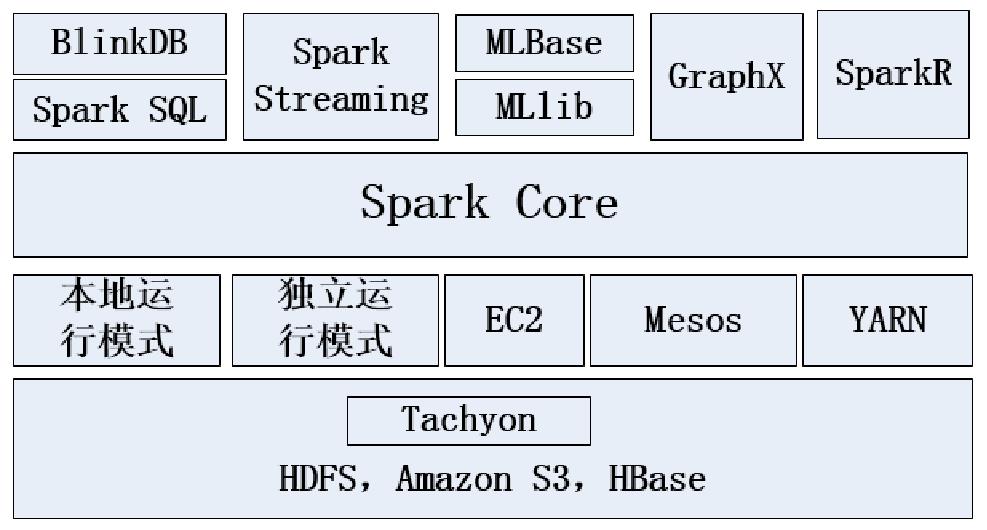
(1)Spark Core:Spark核心,提供底层框架及核心支持。包含Spark的基本功能,包括任务调度、内存管理、容错机制等。Spark Core内部定义了RDDS,并提供了很多API来创建和操作RDD
(2)BlinkDB:一个用于在海量数据上运行交互式SQL查询的大规模并行查询引擎,它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。
(3)Spark SQL:可以执行SQL查询,包括基本的SQL语法和HiveQL语法。读取的数据源包括Hive表、Parquent文件、JSON数据、关系数据库(如mysql)等。
(4)Spark Streaming:流式计算。比如,一个网站的流量是每时每刻都在发生的,如果需要知道过去15分钟或一个小时的流量,则可以使用Spark Streaming来解决这个问题。
(5)MLBase:MLBase是Spark生态圈的一部分,专注于机器学习,让机器学习的门槛更低,让一些可能并不了解机器学习的用户也能方便地使用MLBase。MLBase分为四部分:MLlib、MLI、ML Optimizer和MLRuntime。
(6)MLlib:MLBase的一部分,MLlib是Spark的数据挖掘算法库,实现了一些常见的机器学习算法和实用程序,包括分类、回归、聚类、协同过滤、降维以及底层优化。
(7)GraphX:图计算的应用在很多情况下处理的数据都是很庞大的,比如在移动社交上面的关系等都可以用图相关算法来进行处理和挖掘,但是如果用户要自行编写相关的图计算算法,并且要在集群中应用,那么难度是非常大的。而使用Spark GraphX就可以解决这个问题,它里面内置了很多的图相关算法。
(8)SparkR:SparkR是AMPLab发布的一个R开发包,使得R摆脱单机运行的命运,可以作为Spark的Job运行在集群上,极大地扩展了R的数据处理能力。
五、Spark的应用场景举例
腾讯广告
广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上,支持每天上百亿的请求量。
Yahoo
Yahoo将Spark用在Audience Expansion中。Audience Expansion是广告中寻找目标用户的一种方法,首先广告者提供一些观看了广告并且购买产品的样本客户,据此进行学习,寻找更多可能转化的用户,对他们定向广告。Yahoo采用的算法是Logistic Regression。同时由于某些SQL负载需要更高的服务质量,又加入了专门跑Shark的大内存集群,用于取代商业BI/OLAP工具,承担报表/仪表盘和交互式/即席查询,同时与桌面BI工具对接。
淘宝
淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等,将Spark运用于淘宝的推荐相关算法上,同时还利用GraphX解决了许多生产问题,包括以下计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。
以上是关于学习笔记Spark—— Spark入门的主要内容,如果未能解决你的问题,请参考以下文章
[学习笔记]黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程
spark学习笔记——sparkStreaming-概述/特点/构架/DStream入门程序wordcount
Spark StreamingSpark Day11:Spark Streaming 学习笔记