蚂蚁森林「偷能量」和「反洗钱」,用的竟是同一种技术!
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了蚂蚁森林「偷能量」和「反洗钱」,用的竟是同一种技术!相关的知识,希望对你有一定的参考价值。
👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇
来源丨新智元(ID:AI_era)
https://mp.weixin.qq.com/s/cVa4Mowus8vFaJOc_XR8bg

新智元报道
编辑:Q 好困
【新智元导读】只知道蚂蚁森林可以偷能量?这次来看点新鲜的:「图计算」听说过么!
18世纪,欧拉提出了著名的哥尼斯堡七桥问题(Seven Bridges of Königsberg):
河中心的小岛与河岸由七座桥相连接,在所有桥都只能走一遍的前提下,如何才能把这个地方所有的桥都走遍?
在随后发表的论文中,欧拉证明了符合条件的走法并不存在,而该论文也成为图论史上第一篇重要文献。

图(Graph)是用于表示对象之间关联关系的一种抽象数据结构,使用顶点(Vertex)和边(Edge)进行描述:顶点表示对象,边表示对象之间的关系。
图计算,便是以图作为数据模型来表达问题并予以解决的这一过程。以高效解决图计算问题为目标的系统软件称为图计算系统。
对于图计算技术的研究,最早可追溯至20世纪四五十年代。
但图计算逐渐进入人们视野,则是2010年谷歌发表的「Pregel:一个大规模图计算系统这篇」这篇论文引起。

https://kowshik.github.io/JPregel/pregel_paper.pdf
「蚂蚁森林」=图计算?
「蚂蚁森林」都很熟悉吧,大家是不是都会一起床就跑去「偷」朋友的能量?
而你想象不到的是,这背后都是图计算在支撑!

在你进行了消费或者是做了其他低碳行为之后,就会得到一些能量并且能被自己和朋友实时看到,而这就需要超大图的高效计算能力。
当朋友把能量偷走时,打开蚂蚁森林的每个人都会实时看到。
既不会别人偷走了10克,用户自己这里还有10克;更不会因为还有别的朋友也来偷走10克,自己本来只有10克,最后被偷走了20克。
如果用户的规模变得十分巨大,「偷能量」这个动作对时效性以及对数据一致性的要求就会非常的高。
在这样一个「游戏」场景下,蚂蚁锻炼出了在超大规模图上对数据量高,吞吐率低,延时方面的计算的能力。
图计算,没那么简单
近几年,随着数据的多样化,数据量的大幅度提升和算力的突破性进展,超大规模图计算在大数据公司发挥着越来越重要的作用,尤其是以深度学习和图计算结合的大规模图表征为代表的系列算法。
相比于传统的基于二维表结构的数据库或大数据模型,图数据结构非常适合于对事物之间深层次的关系进行实时高效地分析。
图计算的发展和应用有井喷之势,各大公司也相应推出图计算平台,例如Google Pregel、Facebook Graph等。
随着新技术和新业务的推动,目前图计算技术已进入临近爆发的前夜。
根据DB-Engines的排名显示,图数据库关注热度在2013-2020年间增长了10倍,关注度增长排名第一。
而「图数据库、图计算引擎、知识图谱」三项热点技术方向也正在全球范围内加速产业化,国内阿里、华为、腾讯、百度等大型云厂商以及部分初创企业均已布局这一技术领域。
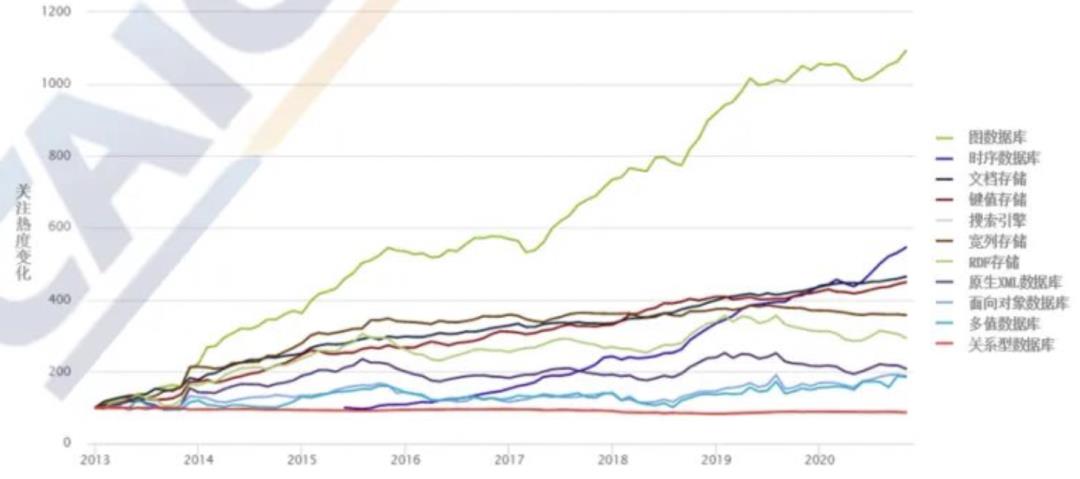
来源:中国信通院《大数据白皮书(2020年)》
对于传统的「大数据」来说,一般是以表的形式进行存储,这种关系型数据的特点就是数据往往是「同质化」的。
而图数据是一种更加高维的数据,从而能够涵盖那些「非同质化」的数据。
也就是说,图是对现有数据模型的一个升级,可以让很多技术可以做得更快更好。

举例来说,在推荐系统中,如果根据朋友的兴趣推出某用户的兴趣,或者通过用户购买的商品推荐出来还想要的商品,这个深度是比较浅的,如果要查它的邻居的邻居的邻居(下探3度)。
当然,上述这些计算也都是基于个人隐私保护基础之上的。
在传统的关系型数据中,这个过程中访问的数据量是指数级增加的,性能的下降也是指数级的,而当3度以上的时候,很有可能关系型数据库已经查不出来了。
但是在图数据库里面,不需要做很多个表的交、并等操作即可完成。
| 深度 | 关系型数据库(s) | 图数据库(Neo4j) | 返回个数 |
| 2 | 0.016 | 0.01 | 2500 |
| 3 | 30.267 | 0.168 | 110,000 |
| 4 | 1543.505 | 1.359 | 600,000 |
| 5 | 未完成 | 2.132 | 800,000 |
来源:《Graph Databases》
第一列的「深度」表示社交朋友之间的关系,深度为1,表明二人为直接好友;深度为2,表明二人为好友的好友,以此类推。
由图表可知,当深度达到5时,关系型数据库已无法完成任务,而图数据库的响应时间为2.132秒,在可接受范围内。
不过,优势在某种情况下往往也会变成劣势。图计算处理的最大难点也在于数据处理的不规整,这种不规整使得数据处理起来非常吃力,在处理亿级以上的海量数据时尤其如此。
当要下探6度的时候,相当于要把全图的数据都能够访问一遍,这也是现在很多图学习算法的限制。
蚂蚁集团计算存储首席架构师何昌华表示,目前几乎所有的图深度学习探索的基本上都是2度,能够探索到3度的深度已经是非常的少。
而蚂蚁在一些典型的图算法上已经可以做到10度以上的探索,而现在正在做的系统则希望能够在不强制采样的情况下不限制探索的深度。
当把图做了大规模甚至超大规模的分布式以后,图数据如何存储,计算和通讯如何做到高效,就成了非常棘手的一个问题,这也是所有做图计算相关工作面临的一个共同问题。
一个超大规模的图,往往会被分割成很多子图以后放到多台计算机上进行处理,而这些子图之间是需要通信的,通过通信才能够知道图全部的信息,计算才能不停的迭代和交互下去。
例如,在一个图里面,某个人增加了一笔交易,会影响这个图里面的很多条边,如何做到数据的一致变动,是非常难的问题。
此外,传统的很多图计算基本上要把所有的图全部载入内存以后计算才能够高效,但其实这样的高速是以高昂的成本为代价的。
现在很多的探索会尝试把内存里面的数据放到硬盘上去,成本就会极大的降低,同时问题也就转变成了如何高效地访问硬盘上的数据,是否能够牺牲部分的吞吐而把更多的数据放到外存上,在提升外存的效率的同时支持更大的图。
技术发展?定个标准先
作为一个在我国乃至全球都正在蓬勃发展的热门领域,制定相应技术标准的重要性则不言而喻,既能促进技术的全面发展,也有利于掌握相应的话语权。我国也一直希望建立一些「图」方面的标准,众多科技公司也一直积极的参与其中。
去年9月,国家标准化管理委员会通过全国标准信息公共服务平台公布,《信息技术-图数据库系统技术要求》的国家标准正式立项,这是国内首个图数据库方面的国家标准立项。
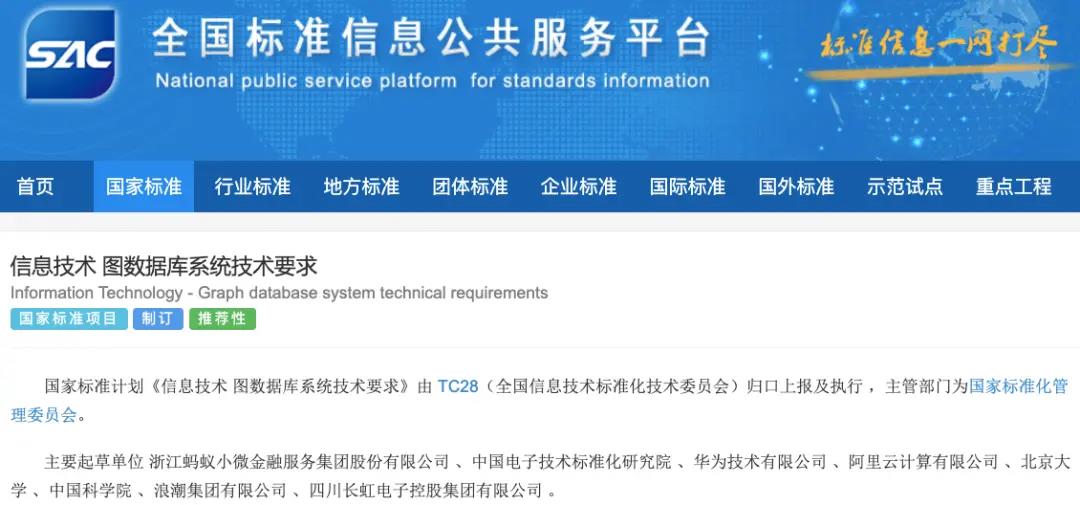
《信息技术图数据库系统技术要求》国家标准立项公示图
据公示信息可知,此国家标准由TC28(全国信息技术标准化技术委员会)归口,由蚂蚁集团牵头、多家公司共同参与制定。基于蚂蚁集团对于该标准的贡献,在全国信标委大数据标准工作组会议上,蚂蚁集团还被选为优秀成员单位。
除了立项的图数据库国家标准,基于自身在图智能领域的产业实践经验,蚂蚁集团还参与了一系列标准的制定:
在浙江互联网金融联合会牵头制定和发布了《互联网金融分布式架构技术应用指南》的团体标准;
在全国金融标准化技术委员会牵头立项了《金融IT基础设施 存储应用实施指南》的行业标准;
在CCSA TC601,参与信通院牵头的《图数据库白皮书》和《大数据图数据库技术要求与测试方法》团体标准;
在ISO/IEC JTC1 SC32参与《ISO/IEC 39075 : Graph Query Language》的国际标准。
作为图数据库国家标准的牵头和发起方,何昌华表示:「蚂蚁在图智能领域,具备图存储、图计算、图分析推理、图研发平台的全技术栈GeaGraph。我们希望与各方行业机构通过标准共建,来促进图智能技术的应用,促进数字经济的发展。」
蚂蚁走到哪了?
2015年初,蚂蚁开始组建图数据库的团队,2016年发布了第一个图数据库的版本——GeaBase。
上线以后,新版支付宝是GeaBase迎来的第一笔流量,接下来从支付宝的一个更大规模的改版到新春红包到双11,GeaBase进入到越来越多的业务里面。
到2019年双11,迎来了一个里程碑事件:单集群规模突破万亿边!
点边查询,针对点、边或者是关系的查询,突破了800万的TPS,并且平均延时小于10毫秒。
如今,蚂蚁对于海量超大规模图数据的存储的能力,已经能够做到超过万亿级别的点跟边的规模,在业界已经是非常领先的水平。
在TB这个数据规模的级别上,在5-6度左右都能做到毫秒级的结果的反馈。同时,还能实现百万级每秒这种高的吞吐量。
在LDBC的这种性能测试里面,是第二名的性能7.6倍,在斯坦福的图深度学习推理评测中打榜的时候也拿到了第一。
此外,在延时这些方面的比较上,蚂蚁是远远领先的,包括六跳的查询、迭代的算法,甚至要求很高的尾延时,在生产环境中都做到了小于20毫秒,这是业界的很多其他的图数据库远远达不到的。
而这些出色的能力,都依赖于蚂蚁自研的GeaGraph体系:
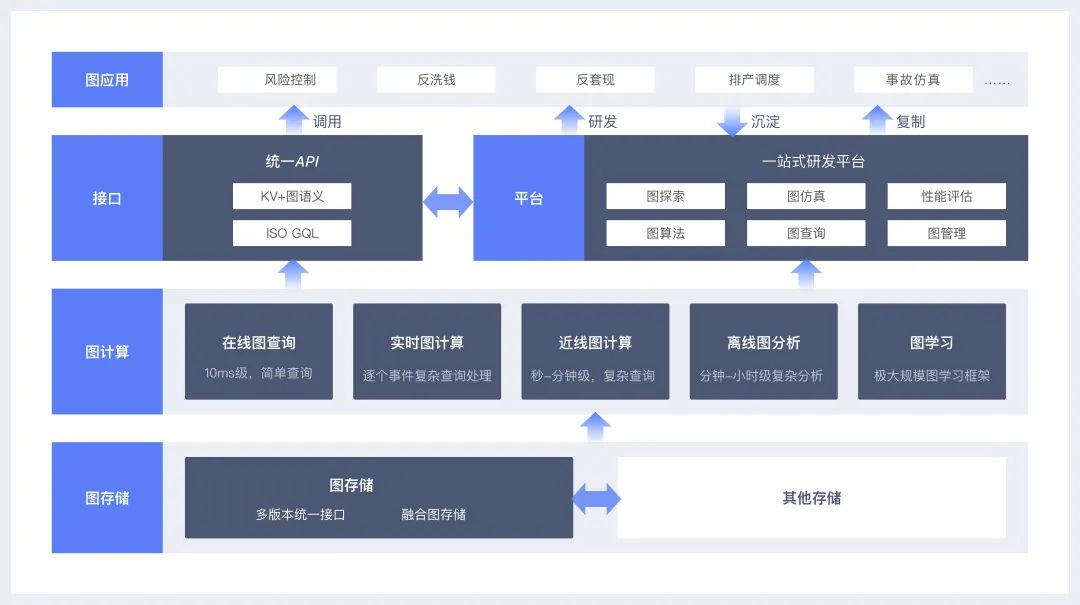
今年世界互联网大会期间,大规模图计算系统GeaGraph这个产品体系获得了世界互联网领先科技成果奖。
GeaGraph体系包括如下部分:
1. PhStore:蚂蚁纯自研的存储引擎,基于完美哈希(Perfect Hashing)技术,在图的读取性能上可以达到O(1)复杂度,是业界首创的基于完美哈希的KV图存储。
2. GeaBase:蚂蚁集团完全自主研发的金融级分布式图数据库,GeaBase单集群能支撑万亿边规模的图数据,写入和查询吞吐量超过每秒百万次,99.9%查询和写入延时小于20ms。
3. GeaBase Lite:一个支持事务处理和强隔离性的单机图数据库,可以单机支持百亿边的图数据,而且集成了全图迭代分析能力,可以同时满足用户对图的复杂分析、快速查询和可视化的需求。
4. GeaFlow:自研的流式图计算引擎,提供了图探索、图仿真、动态子图匹配和流式增量图计算等多种近线图计算能力,并支持了千亿级图数据的长周期(半年/一年)仿真回溯验证、秒级6度以上的流式子图匹配和秒级全图时序增量图计算等关键技术能力。
5. GeaComputing:在清华大学研发的Gemini和ShenTu离线图计算系统上进一步优化的分布式图计算平台,支持万亿级图数据,能够为用户提供高效的复杂图分析能力。
6. GeaLearning:自主研发的以图为核心的超大规模分布式深度学习系统,支持多种灵活图模型训练方法,不限制图神经网络层数和节点邻居个数,以模型并行为核心的混合并行执行方式等。
7. GeaMaker:蚂蚁自主研发的一站式图计算研发探索平台,平台融合了上述底层系统的能力,为用户提供了具备探索、仿真、性能评估等功能,集在线查询,近线计算,离线分析和图学习于一体,可以让开发者更方便地使用。
反欺诈
在线上交易中,最让银行和第三方头疼的就是「套现」这种欺诈行为。
例如有一些不良的商家,会通过银行卡、花呗或者熟人等来完成一个套现的回路。
以前,挖掘的关系数或者关系的深度往往都有限,并且很难,计算起来也不够高效。而现在能够把这种行为建模成一个图,在这个图上就会发现它形成了一个欺诈的闭环。
在数据量很小的时候,传统的图计算单机就可以解决这个问题,现在的海量数据的情况下,需要对超大规模图进行切割,还要做高效的存储,更需要很低的时延。
蚂蚁则希望在每一笔交易发生的时候,都能够实时的检测到并阻止这样的行为。

除此之外,现在欺诈的形式上也有了新的变化:以前的欺诈行为很集中,就在一个人或者账户上,通过简单的技术进行个体挖掘就能看到特征找到欺诈。
而现在是对抗的,甚至升级成了团伙,会租借一些正常交易的合法账户,混在海量的交易数据中,可能只有中间的几笔交易才是欺诈,使得欺诈行为变得非常隐蔽,很难找到。
2020年时,欺诈手法变成不仅仅是一个团伙,而且它的团伙还在演变,团伙成员还在不停的变化。
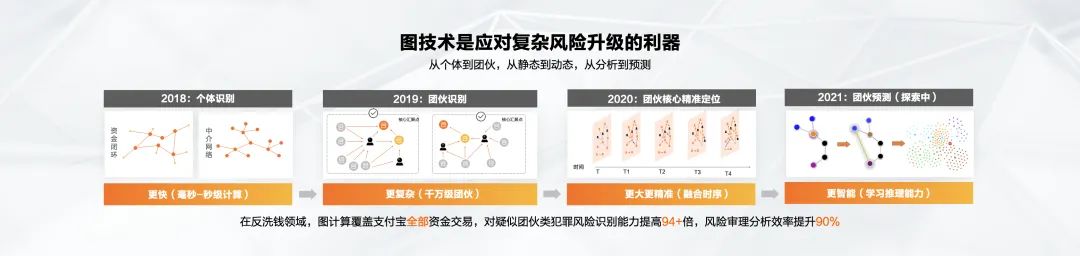
在观察它按照时间往前演进的过程中,能够识别到这些团伙里的一些关键的角色,这样就能够更加快速精准的定位团伙的核心成员,这就是时序图计算。
这也对蚂蚁的底层图计算计算提出了新的挑战,现在能做到的是对欺诈行为的被动识别,未来蚂蚁希望可以能够更进一步,对风险也能进行主动的预测。
反洗钱
反洗钱跟反欺诈的很多技术是非常类似的,反洗钱对于时效性要求非常高,判断的逻辑也越来越复杂。
在洗钱的行为里面,常见手段是通过在海量的交易里面混杂洗钱和一些艺术品的拍卖,来掩盖洗钱行为。
作案的人员可能有很多重身份和大量的账号,并且交易的频率不高,交易的路径也非常复杂,可能是在正常的交易中混杂着这样的一些可疑的交易。
要找到这样的一些欺诈的行为,并且阻止他,就需要深入的图分析、图计算的能力。
从2018年开始,基于资金网络、中介网络这样一些典型的欺诈,蚂蚁已经能够做到百万吞吐级别对应毫秒级的响应。
类似传统的方法做在图上,但是把它的吞吐量变大、响应时间变短,能够更快速的抓到这些行为,而这些工作如果使用传统的方法用人来做,可能需要几个小时或者一天,但蚂蚁把它做到了线上这样高效的能力。
2021年,GeaStack应用于蚂蚁集团反洗钱分析,覆盖支付宝全部资金交易,对疑似团伙类犯罪风险识别能力提高94倍多,风险审理分析效率提升90%。
除了金融领域之外,蚂蚁集团还进行了很多外部合作。
在人工智能时代,NLP、CV、RL等领域已经百家争鸣,而图计算作为最前沿的技术高地之一,谁能够在这个方面打造出核心的能力,谁就能够站到未来世界通用人工智能的最前沿。
而目前国内的很多公司包括蚂蚁集团在内,在图计算方面的一些探索已经走在了世界前列。
一直以来人们对于技术的探索从来都只有一个目标,就是让人类从中受益。
何昌华说,「蚂蚁的初心也一直都是不断探索革命性的技术,并在支持好蚂蚁业务的同时把达到一定水平的成熟技术开放给社会,希望它在更多的场景中发挥出社会价值。」
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击👆卡片,关注后回复【面试题】即可获取
在看点这里 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于蚂蚁森林「偷能量」和「反洗钱」,用的竟是同一种技术!的主要内容,如果未能解决你的问题,请参考以下文章