学习笔记Hive —— Hive应用—— 数据库定义创建表
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Hive —— Hive应用—— 数据库定义创建表相关的知识,希望对你有一定的参考价值。
一、任务讲解
泰坦尼克号乘客信息存储与分析

泰坦尼克号乘客信息存储与分析:
- 创建乘客信息表
- 导入数据到表中
- 统计获救与死亡情况
- 统计舱位分布情况
- 统计港口登船人数分布情况
- 统计性别与生存率的关系
- 统计客舱等级与生存率的关系
- 统计登船港口与生存率的关系
二、数据库定义
2.1、HQL语句简介
HiveQL是一种类SQL语言,用于分析存储在HDFS中的数据。
不支持事务及更新操作。
HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上, 延迟比较大。
2.2、数据类型
基础数据类型

复杂数据类型

2.3、Hive CLI
1、执行shell命令
用户不需要退出hive CLI就可以执行简单的bash shell命令。只要在命令前加上!并且以分号(;)结尾就可以

2、在Hive中使用Hadoop的dfs命令

2.4、创建与查看数据库
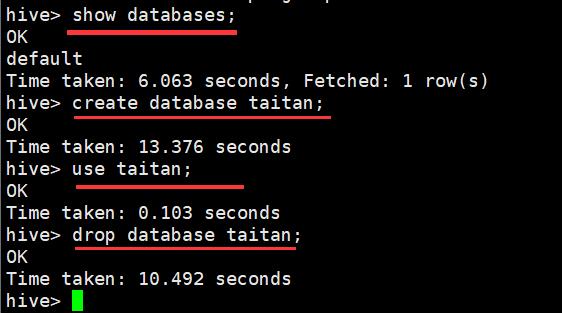

2.5、创建数据表
(中括号表示可选)
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name #[EXTERNAL]:外表/内表
(col_name data_type [COMMENT col_comment], ...)
[PARTITIONED BY (col_name data_type, ...)] #分区表 指定字段
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format] #字段将分隔符或行间分隔符
[STORED AS file_format] #定义存储格式
[LOCATION hdfs_path] #指定表数据存放的路径
三、创建表

3.1、创建内表
在train数据库下创建表person
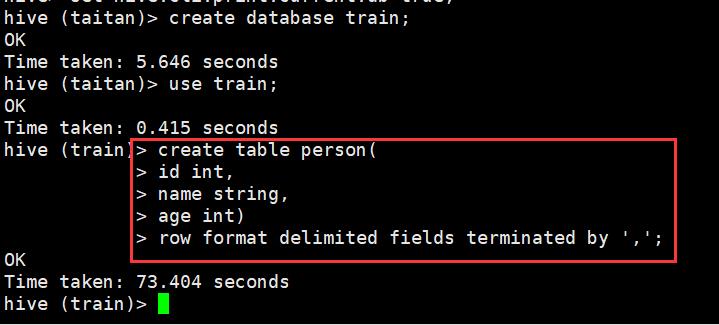
(在浏览器输入:master:50070可以看到)

数据内容
person.txt(我放在/opt目录下)
1,Tom,23
2,Kate,24
3,Betty,22
4,Ketty,23
5,Jhon,21
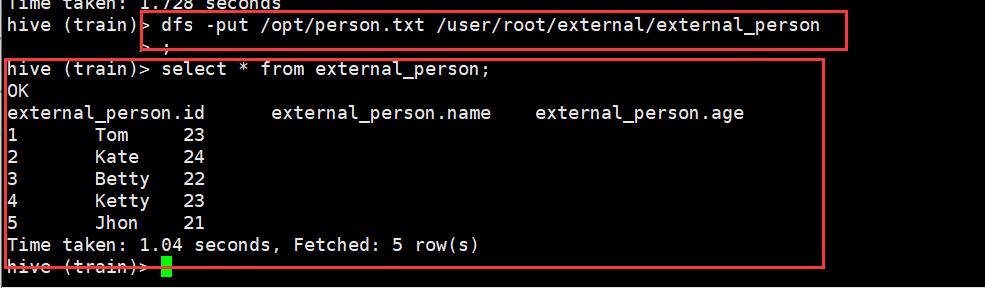
这里有种简易的方式导入到hive中就是:先上传到HDFS:


3.2、创建外表
创建Hive外部表external_person,指定HDFS的路径为/user/root/external/person


数据内容
person.txt(我放在/opt目录下)
1,Tom,23
2,Kate,24
3,Betty,22
4,Ketty,23
5,Jhon,21
上传到hdfs:
*补充:内外部差别
学习了内表和外表,那么疑问来了,它们是不是就差别在能否自定义目录?其实它们的差别主要体现在删除,别急!看完下面例子你就明白了!
① 先删除内表和外表

② 查看它们在hdfs的数据文件是否被删除
内表被删除了:

外表没被删除:

总结:内表删除时会把原数据及hdfs上的数据都删掉,而外表删除时只会删掉原数据不会删掉hdfs上的数据;
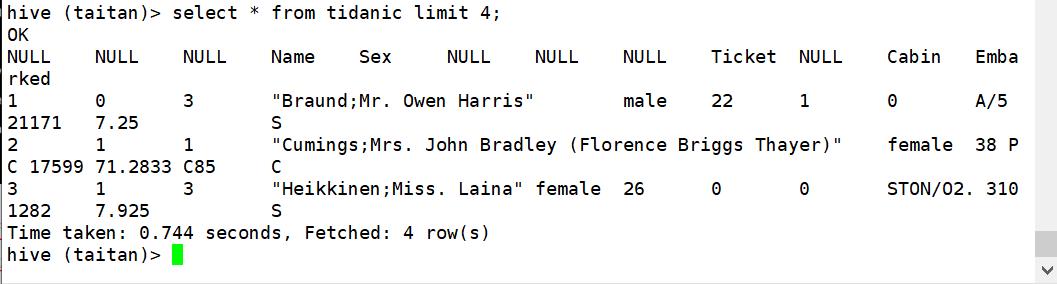
3.3、创建泰坦尼克乘客信息表
任务实现:创建泰坦尼克乘客信息表
- 创建一个内/外部表,指定数据的存放路径。
- 通过HDFS命令导入数据到指定路径。
创建(内)表

数据文件
train.csv
(导入时删掉头一行)

上传到hdfs

查看:
3.4、静态分区表
- 创建静态分区表tidanic_part,字段为:passengerid、survived、 pclass、 name
- 分区字段为gender,按照性别字段sex分区



OK

3.5、动态分区表
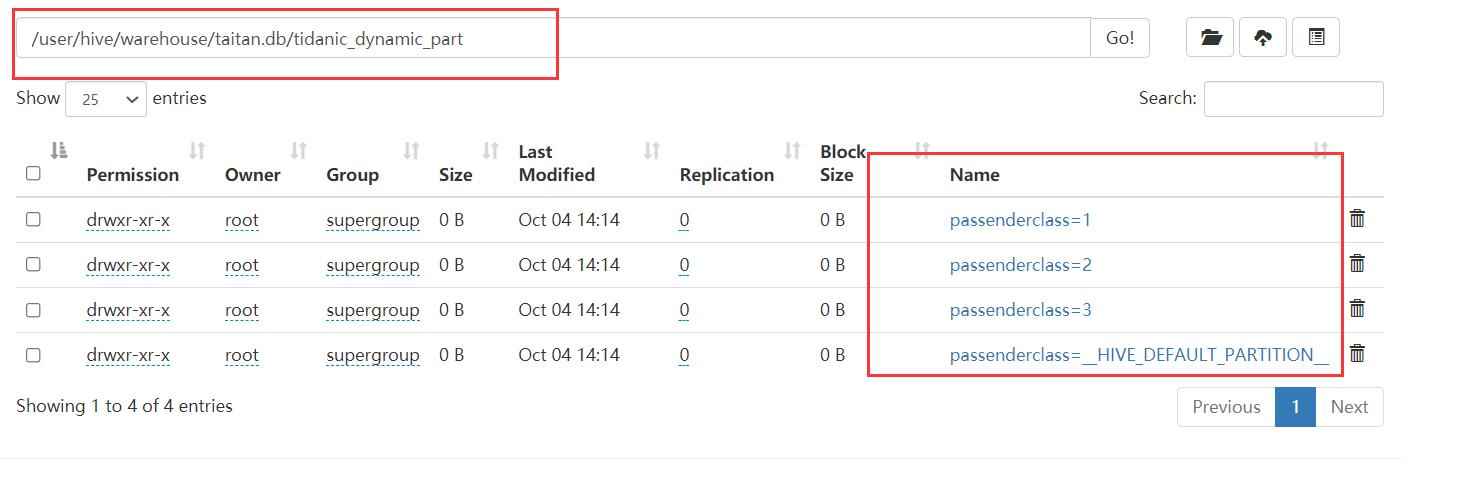
- 创建动态分区表tidanic_dynamic_part,字段为:passengerid、survived、 name
- 分区字段为passenderclass,按照pclass值进行分区

(我们可以看出动态分区建表其实和静态分区的建表是一样的,他们不同在动态分区进行插入时要初始化)

OK
3.7、创建带数据的表
- 创建一个tidanic的子集


3.8、创建桶表
- 桶是比表或分区更为细粒度的数据范围划分。针对某一列进行桶的组织,对列值哈希,然后除以桶的个数求余,决定将该条记录存放到哪个桶中。
获得更高的查询处理效果
抽样调查
- 创建桶表,按年龄将数据分到4个桶,抽取两个桶的数据创建一个新表tidannic_sample



语法:
TABLESAMPLE(BUCKET x OUT OF y)X代表从哪个桶开始抽, y代表抽取桶个数为(桶数/y)个,y必须是桶数的倍数或者因子
以上是关于学习笔记Hive —— Hive应用—— 数据库定义创建表的主要内容,如果未能解决你的问题,请参考以下文章