yolov5代码解读-网络架构
Posted 一只眠羊e
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了yolov5代码解读-网络架构相关的知识,希望对你有一定的参考价值。
前言
上一篇:yolov5代码解读-dataset
下一篇:yolov5代码解读-训练
代码已上传到github,数据集和权重文件已上传到百度网盘(链接在github里),如需下载请移步:https://github.com/scc-max/yolov5-scc
数据处理好之后,就来具体看看网络模型是怎么搭建的吧。
目录
网络架构可视化
可视化工具
网络架构可视化工具netron的安装参考:
(1)netron
可以看我之前写的netron安装和使用文章。
也可以直接下面的netron网址:
https://lutzroeder.github.io/netron/
点击后直接就可以打开本地模型可视化,比如yolov5s.pt。

(2)onnx
但是.pt比较简单,细节不够。这时可以再安装一个onnx工具,方法是终端输入:pip install onnx
之后要做的是将pt文件转换成onnx文件。
这个在yolov5中,已经有写好的脚本了,在models下的export.py中。
设置好参数运行以后,会生成一个onnx的文件

打开上面那个网页版的natron地址,然后load生成的onnx文件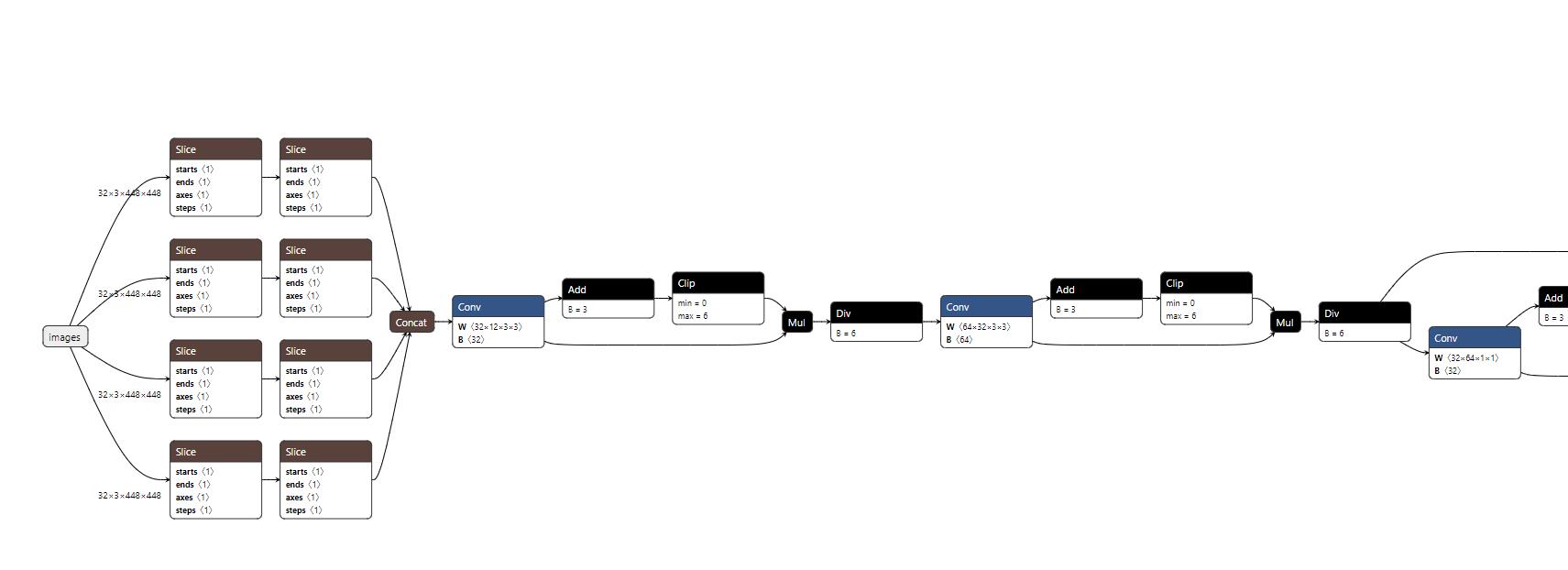
配置文件解读
打开yolov5s.yaml,
nc是类别数量,我做的是矿山提取,只有矿山和背景两个类别。
后面的depth_multiple和width_multiple就体现除了s,m,l,x的区别了。
depth_multiple是指模块走的深度。0.33就是1/3, 也就是所有模块走的次数是1/3次(最小保留1)。
width_multiple是卷积核的个数。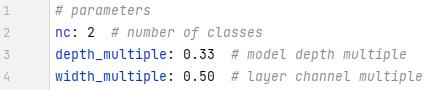
5m的yaml文件
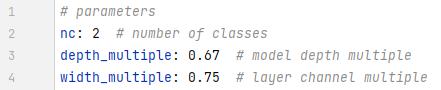
5x

5l
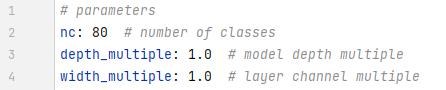
总结规律就是l是1,往前是深度-1/3, 卷积核个数-1/4,后面是加。
红色这一列就是要压缩(膨胀)的参数,如果是5s,那1保持不变,3和9就被压缩成1和3了。
橙色的部分就是卷积核的个数了,也是要压缩(或者膨胀)的。
上面说了橙色框是卷积核个数,红色框是当前模块执行次数。
第一列,即全是-1的这一列,代表输入层,如果是-1就代表是上一层。而Focus这一列是模块的名字,卷积核个数后面分别是卷积核尺寸和降采样尺寸。
head也是一样,只是连接更复杂了。

这几个候选框都是可以改的,自己加也是可以的。
网络层
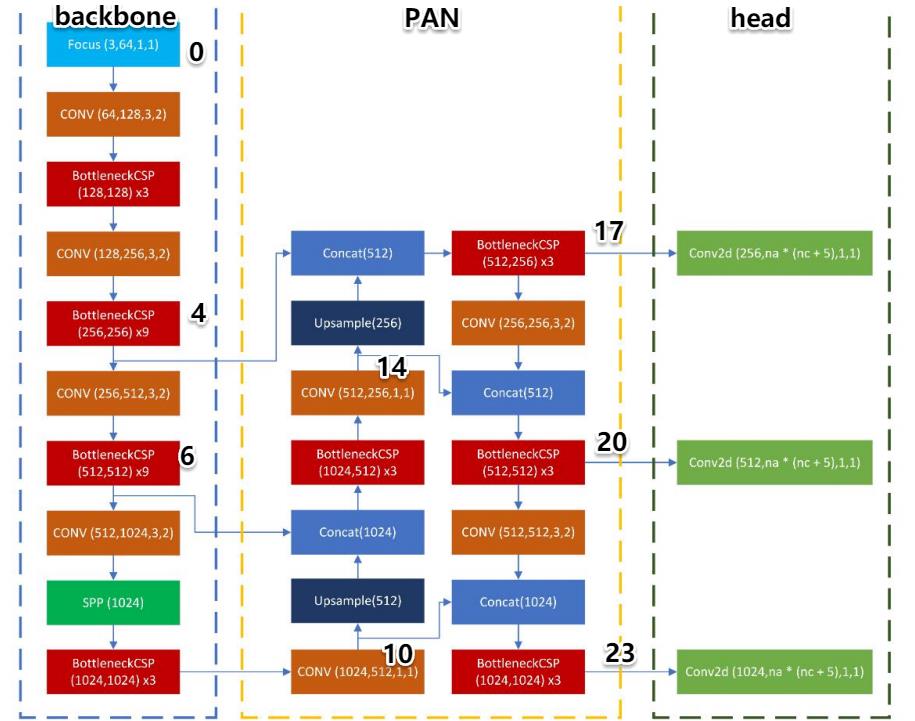
看看这图画的!我只能说,大神请收下我的膝盖。之前一直不知道PAN是怎么实现的,什么叫先往上走,再往下走。看看这里的网络结构,不是很清晰吗?
- Backbone:这一部分不用多说,卷积层+BottleneckCSP,连续4次(后3个被依次拿去做PAN了,最后一个是拿去做上采样,其他两个是concat),最后一次在卷积层和BottleneckCSP中间加了SPP层。这一部分的基础模块是:Conv+BottleneckCSP。模块数:2×4+1=9
- PAN:先向上走,再向下走,然后同维度的concat起来,经过一个BottleneckCSP模块后送到head层。这一部分也是4个BottleneckCSP(后3个被依次拿去送到head)。这一部分抛去连接,基础模块是:Conv+(Upsample)+Concat+BottleneckCSP。模块输:4×2 + 3×2 = 8 + 6 = 14
网络架构代码
在models中打开yolo.py,查看模型架构代码
yolo.py
model
(1)模型解析
首先是加载yaml文件,用的是yaml.load这个功能加载的。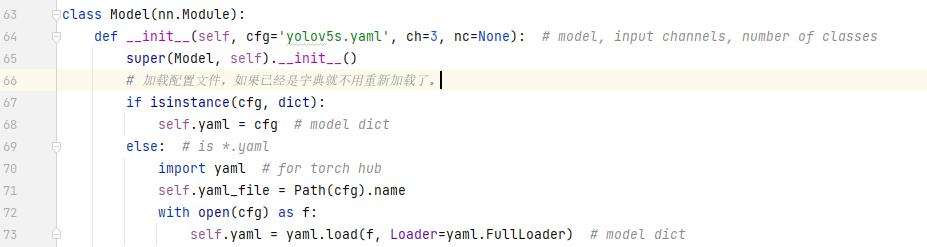
下一步是定义模型,先判断类别数是不是对,如果代码中输入的类别和yaml不相符,就重写yaml的类别数。parse_model是解析模型,具体如何解析,跳到后面的parse_model去看。
解析完模型后,就得到了Sequential的model。下面这这一段是检测要用的。s是步长,先初始化成128,再根据下面的式子调节。
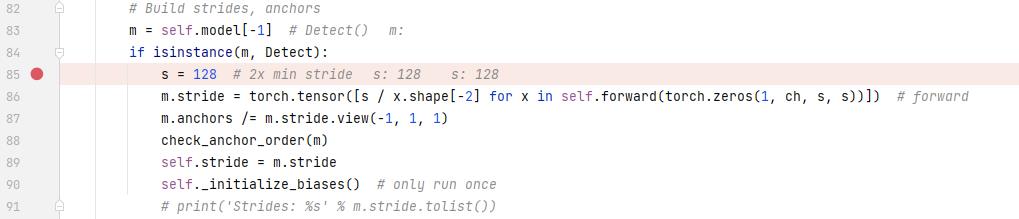
dubug看一下stride的值,有3个不同的尺度,对应着3种大小不同的头。
对于anchor的值,暂时不清楚。它是根据原始的值再除去stride的。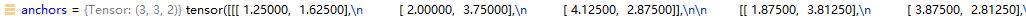
之后是初始化权重
(2)前向传播
这样整个模型的初始化就完成了,后面就是前向传播了,看forward。在forward函数中,因为没有做增强,所以直接走else路线,也就是其实执行的是forward_once这个函数。
下面这段就是实际要走的前向传播函数了。
第一模块m是Focus模块,可以具体查看一下m
看看focus中的参数:
分别对应着f,n,m,args
对于focus,f=-1,在上面代码中,前面的都不会走,直接走到x = m(x)这里了。
那m(x)代表什么呢?m是模块,现在是focus模块,也就是把x传给focus类。执行了foxus里面的forward函数。
当前向传播走到concat模块的时候,f就不是-1了,也就是不是直接连接上一层了,这时上面那个被忽略的支路就要回来了,这里的y是在parse_model时加入的f不为-1(也就是concat预备选手)的张量,然后m.f在这里就是拿出了一个索引,去定位到底是哪一层要和俺一起concat。
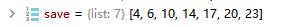


将上一层和第6层做拼接。这是一个大循环套小循环有没有,else里面有嵌套了一个if else。当f是-1的时候,直接就把x拿过来就行,因为x就是上一层传过来的嘛。如果f不是-1,就是去y里面取那一层的输出。
对于122行代码的解释,看下面这段示例就清楚了。如果是-1,就把原本的x直接拿过来,如果是6,就加y[6]。至于为什么前面还有个isinstance,那是因为f可能还有f = 5,这种只有一个整数,不是列表,但是又不是-1的情况。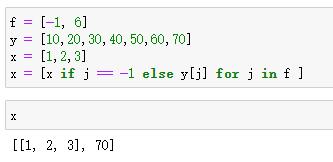
那么问题来了,y不是空list吗?值哪里来的呢?看这部分最后一行代码:(i忽略,博主写别的功能用的)

y把m.i append进去了。这里注意只有当第i层在save名单里才会添加(废话,只有concat需要的层也放进去,都放进去干嘛),save名单哪里来的呢?
不是直接取-1,也就是前一层的,都会被放进save小本本里,进而append给y。
当m走到detect层的时候,又不一样了,来看看detect层是参数:
这里的17,20,23,对应着yolov5网络结构图中的输出head的那几层
parse_model
先创建了日志
之后是从读取的yaml字典中加载anchor、类别数、深度和卷积核个数两个参数
na是每个网格对应的anchor数量,1/2是因为每个anchor都有宽高两个元素,no就是每个网格对应的输出了。
之后对backbone和head层做遍历,与yaml中对应的信息结合看。f是from,n是number,m是module,args是卷积核参数。对于m,这里第一次遍历取到的是字符串’Focus’,用eval()函数就会直接去执行Focus这个命令。Focus是在common.py中定义的一个类。
执行完m
继续向下走,根据m是什么模块决定怎么执行
第一个if: c1是通道数,c2是卷积核个数(注意要和yaml中的压缩系数处理),args中的参数是卷积核个数和卷积核大小。如果是CSP,还要在list索引为2的位置插入一个重复次数。当模块是concat的时候,输出通道就是c1和c2的sum()了。
总之,这一段主要是根据不同的模块要求修改对应的参数,主要包括输入通道数、输出通道数、模块重复次数。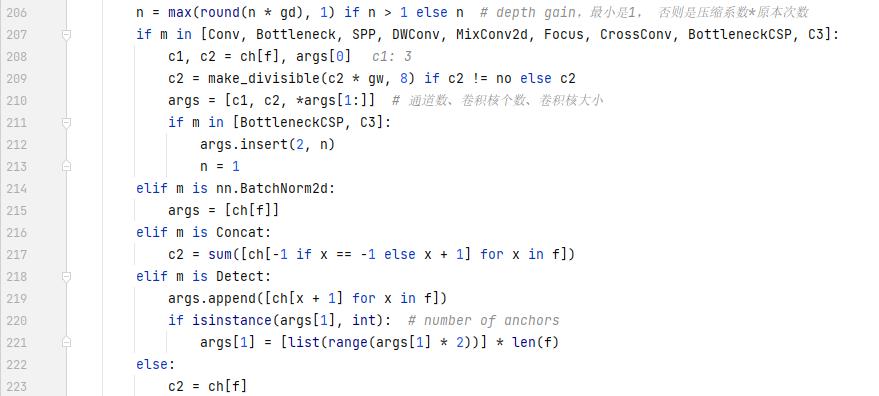
看看nn.Sequential是怎么添加参数的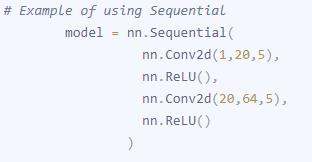
再看看卷积模块的参数
那么对于m(*args)就很好理解了。args不就是[input_channel, output_channel, kerna_size]吗?解压后传给m当参数、如果m是conv2d,就和上面是一样的效果。对于重复多次的模块,要添加多次,下面这行代码就是讲的这么个事
执行完之后的m_是
这一段代码是将上面的模块添加进Sequential里,然后添加几个属性,像参数量,index,类型这些。之后再写入日志,打印出来。
第232行为啥要用x % i呢?x是待添加的模块索引,也就是4,6,10,14这些。注意看,它是当模块运行到concat,也就是f是个列表的时候才添加,这是的i是大于x的。i是当前层,x是要取的前面的层。所以这里取余之后还是x,可能使得程序更加健壮了吧。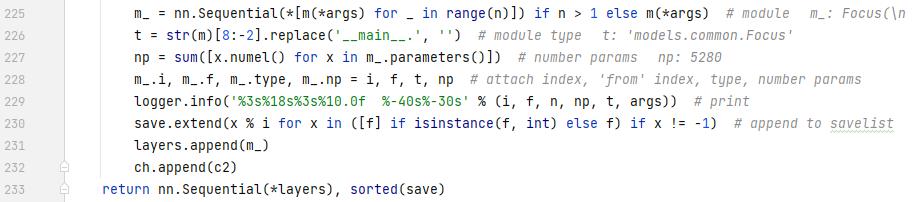
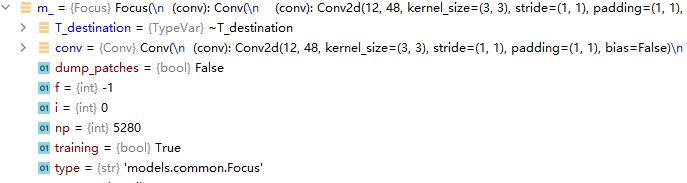
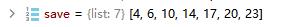
这部分代码看着很复杂,其实真正的效果就和那个Sequential是一样的。只是要从yaml文件中取出相关信息,还要根据不同模块修改,显得复杂了点。就是完成了配置文件解析的任务。
common.py
Conv
这个是卷积层,最基础的模块,被后面多次用到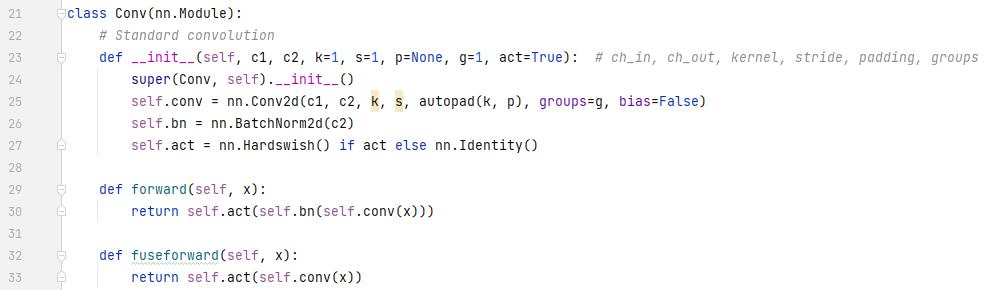
卷积层就是这么朴实无华,一个卷积,一个bn,再加一个hardswish激活函数,我愿称之为CBH。
hardswish激活函数是这样的:
forward给了两个版本
fuse版本:无bn
CBH版本:有bn
好吧,我翻遍整个网络,也没看到使用这个版本。bn后接的都是leaky relu激活函数,并且bn前一般都是经过了concat操作。
Focus
focus不会增加训练精度,但是会提高速度。其被提出的原因是因为原始图像比较大的时候,第一层卷积计算量就比较大,通过focus模块可以减小尺寸,增加深度,降低计算量。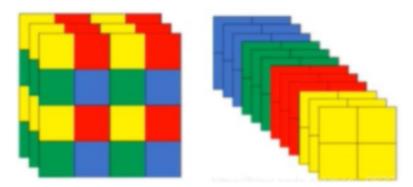
第一个就先看Focus模块,前面经过了一个卷积层,这个卷积层也不是简单的卷积层,到Conv那里去看看,其实有conv2d,bn和hardswish三个聚在一起的,我愿称之为CBH。不过这个不是重点,重点是focus模块怎么走的。看看forward前向传播,它返回的是对tensor的一个切片,步长为2。具体操作是这样的,先切片,再拼接,再卷积。
切片:通道数保持不变,第一个切出来的是宽高0开始,步长为2,第二个切的是高(还是宽?无所谓)从1开始,宽从0开始,步长为2。后面类似。
拼接:将切好的部分cat起来,按照通道拼接,之前3通道的输入经过这一步通道就变为了12,但是宽高的尺寸各降一半。通过这个操作就大大较少了后面走卷积的参数量
卷积:将拼接好的tensor送到conv模块进行卷积。
Focus的网络结构: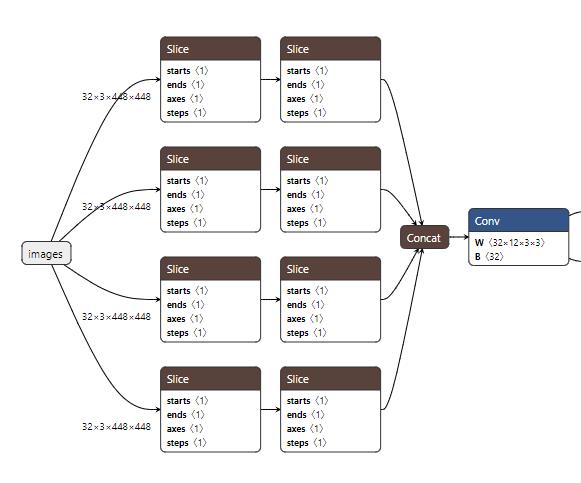
BottleneckCSP
这一部分是Bottleneck+BottleneckCSP。
可以先看这张图: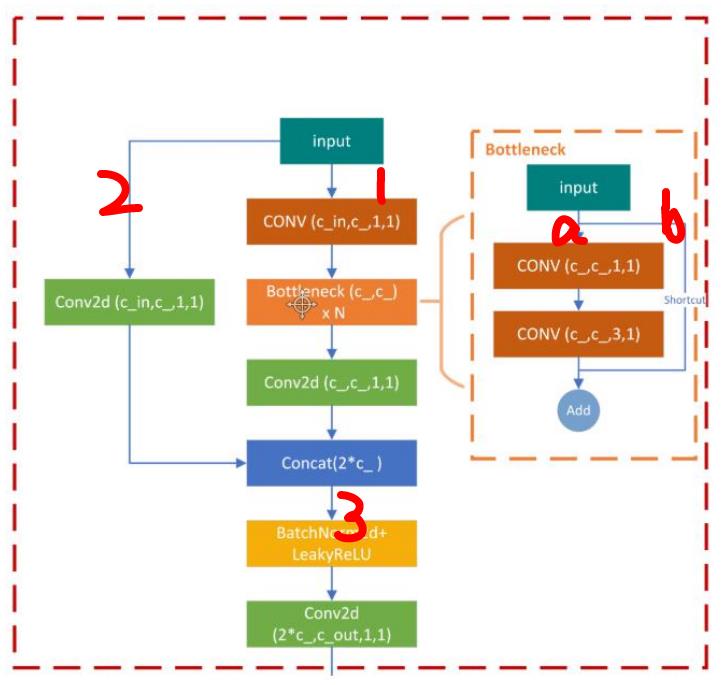
在BottleneckCSP模块中,input分成了两条路走,分别是支路1和支路2。走完后再汇合到主路3。
- 支路2:比较简单,就是一个卷积层(包括conv2d,bn,hardswish, CBH)
- 支路1:先走了一个1×1的卷积模块,然后走了Bottlebeck模块。可以看图的右边,Bottleneck模块也是分成了两路走,a路先走了一个1×1的卷积,又走了一个3×3的卷积,b路直接就原封不动拿过来了。最后a路的结果和b路的结果相加。走完Bottleneck后,支路1接着走了一个卷积层,和支路2一样的。
- 拼接:支路1和支路2的结果concat到一起。可以发现,在BottleneckCSP的汇合中,使用的是concat的操作,而在Bottleneck中,直接add到一起的。
- 主路3:拼接后又走了一个BN和一个Leaky Relu激活函数(这里不是Hardswish激活函数了),直走再走一个卷积层,就完事了。
看代码:y1就是支路1,y2就是支路2,最后concat一起在走bn,leaky relu,卷积层。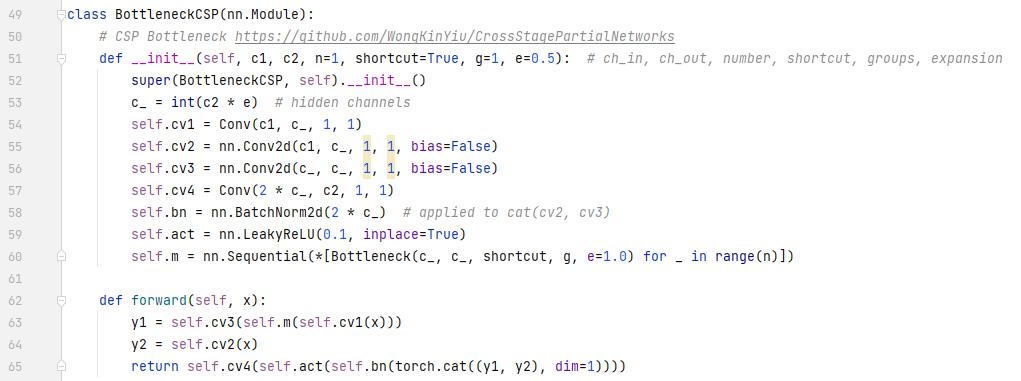
Bottleneck层: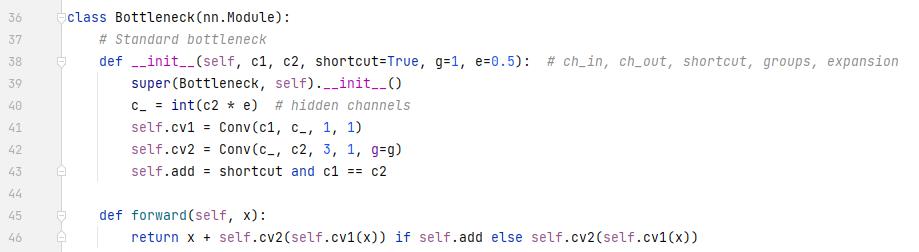
SPP
这部分两次面试问到我SPP是怎么实现的,我都没有答出来,现在就具体看一看。
记住了,SPP是通过多次最大池化实现的,看看配置文件里的参数: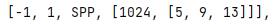
[5,9,13]就是池化的keinal_size,例如5,代表在5×5这个范围内求得一个最大值。
看一下SPP核心网络结构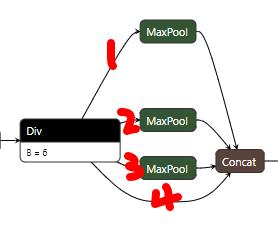
其实还是很简单的,4条支路。前3条都做了maxpool,最后一条路直接走过去,然后再拼接。真的是异常简单有没有!
[5,8,13]对应的padding分别是[2,4,6],这是根据那个从输入到输出的公式求得的,目的是为了保持输出尺寸和输入一样。以高举栗子,当p为2,f为5,s为1时,out和h是一样的:
out =(h-f+2p)/s +1
不过别忘了前面还有一个卷积层,所以SPP的总体结构是介个样子的:
前后的卷积都是为了调整维数,尤其是后面那个,当4个256拼接到一起就是1024,通道数太多,再走一个卷积降降维数。
这个是SPP的代码实现,先走了了cv1,也就是一个卷积层。然后是走ModuleList,这里面是池化操作,后面有个for循环,把[5,9,13]都加进去了。这几个池化结果cat,然后走cv2,也是一个卷积层。和上面那个可视化网络是一样的。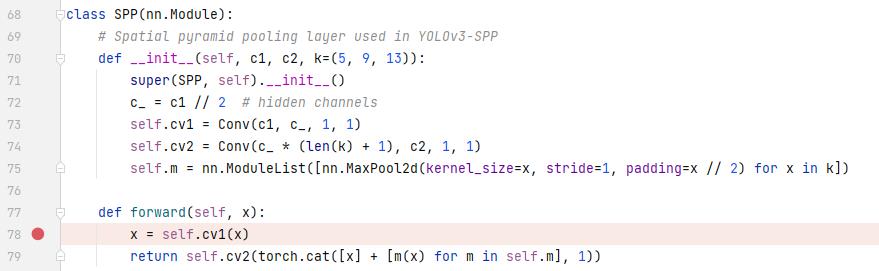
看看SPP具体样子:
总的来说,SPP就是:卷积层+不同大小的池化+卷积层
到这里,backbone的几个层就全都说完了。
Upsample
上采样是怎么实现的?上次面试面试官让我不要用人家写好的API,自己写一个上采样。虽然我自己写出来是不太可能,但是人家是咋实现的呢?
上采样有几种不同的实现方法,其中一种是插值的方法,还有反卷积的方法,可以具体看我的前面两篇博文:
“上采样”与“反卷积”和图像插值:理论与Python实现
common.py里面并没有单独写上采样,直接用了pytorch的nn.Upsample()
如果觉得有帮助,请点赞鼓励,蟹蟹~
下一篇:yolov5代码解读-训练
以上是关于yolov5代码解读-网络架构的主要内容,如果未能解决你的问题,请参考以下文章
改进YOLOv5系列:4.YOLOv5_最新MobileOne结构换Backbone修改,超轻量型架构,移动端仅需1ms推理!苹果最新移动端高效主干网络