改进YOLOv5系列:4.YOLOv5_最新MobileOne结构换Backbone修改,超轻量型架构,移动端仅需1ms推理!苹果最新移动端高效主干网络
Posted 芒果汁没有芒果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了改进YOLOv5系列:4.YOLOv5_最新MobileOne结构换Backbone修改,超轻量型架构,移动端仅需1ms推理!苹果最新移动端高效主干网络相关的知识,希望对你有一定的参考价值。
🚀🚀🚀YOLOv5改进,适用于 YOLOv7、YOLOv4、Scaled_YOLOv4、YOLOv3、YOLOR一系列YOLO算法的模块改进
🎈🎈🎈QAQ
一系列YOLO算法改进Trick排列组合!
很多Trick排列组合
助力论文实验🏆
数据集涨点🏆
创新点改进🏆
🎈🎈🎈新的仓库更新ing,可以 fork 和 star,持续更新完善
👇👇👇
链接YOLOAir仓库:https://github.com/iscyy/yoloair 更新ing

以下🍋MobileOne网络模块 的改进,最新MobileOne结构换Backbone
文章目录
1.MoblieOne理论
论文参考:最新MobileOne结构: Paper
MobileOne的核心模块基于MobileNetV1而设计,同时吸收了重参数思想,得到下图所示的结构。注:这里的重参数机制还存在一个超参k用于控制重参数分支的数量
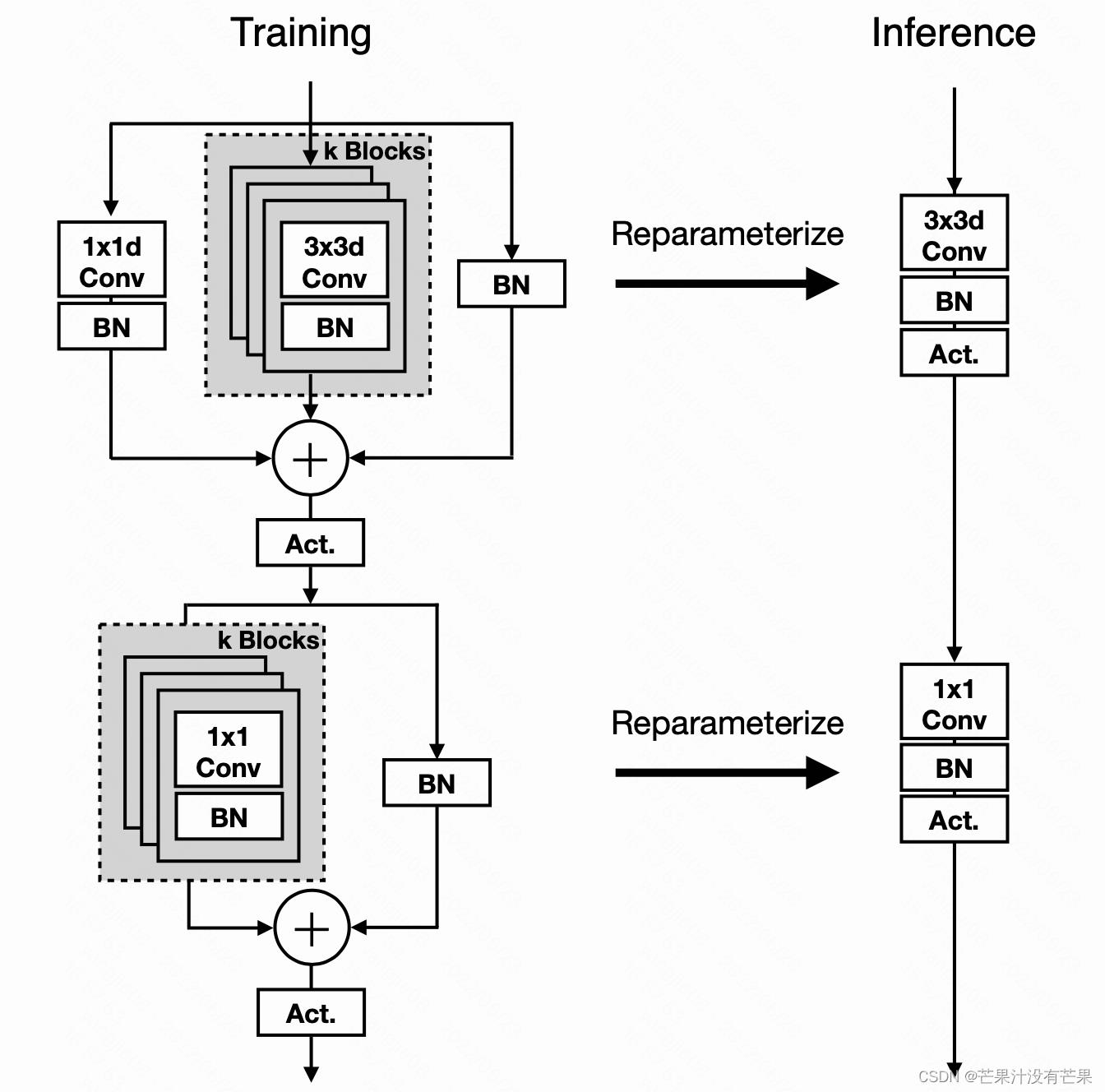
MobileOneBlock 块在训练时和测试时有两种不同的结构。左:具有可重新参数化分支的训练时间 MobileOne 块。右图:MobileOne 在重新参数化分支的推理。ReLU 或 SE-ReLU 都用作激活。过参数化因子是针对每个变体调整的超参数。
使用YOLOv5算法🚀作为演示,模块可以无缝插入到YOLOv7、YOLOv5、YOLOv4、Scaled_YOLOv4、YOLOv3、YOLOR等一系列YOLO算法中
2.在YOLOv5中加入MoblieOne模块
新增YOLOv5的yaml配置文件
首先增加以下yolov5_MobileOne.yaml文件
代码
# YOLOv5改进 🚀 MIT license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5改进 v1.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 6, MobileOne, [128, 4, 1, False]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, MobileOne, [256, 4, 1, False]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 6, MobileOne, [512, 4, 1, False]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 6, MobileOne, [1024, 4, 1, False]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5改进 v1.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
注意:YOLOv5的yaml文件中的MobileOne只是n个MobileOneBlock模块, 使用者可以自行再魔改结构
当需要修改yaml配置文件,将xx模块 加到你想加入的位置(层数);
首先基于一个可以成功运行的.yaml模型配置文件,进行新增或者减少层数 之后,那么该层网络后续的层的编号都会发生改变,对应的一些层都需要针对性的修改,以匹配通道和层数的关系
common.py配置
在./models/common.py文件中增加以下模块,直接复制即可
import torch.nn as nn
import numpy as np
import torch
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class DepthWiseConv(nn.Module):
def __init__(self, inc, kernel_size, stride=1):
super().__init__()
padding = 1
if kernel_size == 1:
padding = 0
# self.conv = nn.Sequential(
# nn.Conv2d(inc, inc, kernel_size, stride, padding, groups=inc, bias=False,),
# nn.BatchNorm2d(inc),
# )
self.conv = conv_bn(inc, inc,kernel_size, stride, padding, inc)
def forward(self, x):
return self.conv(x)
class PointWiseConv(nn.Module):
def __init__(self, inc, outc):
super().__init__()
# self.conv = nn.Sequential(
# nn.Conv2d(inc, outc, 1, 1, 0, bias=False),
# nn.BatchNorm2d(outc),
# )
self.conv = conv_bn(inc, outc, 1, 1, 0)
def forward(self, x):
return self.conv(x)
class MobileOneBlock(nn.Module):
def __init__(self, in_channels, out_channels, k,
stride=1, dilation=1, padding_mode='zeros', deploy=False, use_se=False):
super(MobileOneBlock, self).__init__()
self.deploy = deploy
self.in_channels = in_channels
self.out_channels = out_channels
self.deploy = deploy
kernel_size = 3
padding = 1
assert kernel_size == 3
assert padding == 1
self.k = k
padding_11 = padding - kernel_size // 2
self.nonlinearity = nn.ReLU()
if use_se:
# self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)
...
else:
self.se = nn.Identity()
if deploy:
self.dw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=in_channels, bias=True, padding_mode=padding_mode)
self.pw_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, bias=True)
else:
# self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
# self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
# self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
# print('RepVGG Block, identity = ', self.rbr_identity)
self.dw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'dw_3x3_k_idx',
DepthWiseConv(in_channels, 3, stride=stride)
)
self.dw_1x1 = DepthWiseConv(in_channels, 1, stride=stride)
self.pw_bn_layer = nn.BatchNorm2d(in_channels) if out_channels == in_channels and stride == 1 else None
for k_idx in range(k):
setattr(self, f'pw_1x1_k_idx',
PointWiseConv(in_channels, out_channels)
)
def forward(self, inputs):
if self.deploy:
x = self.dw_reparam(inputs)
x = self.nonlinearity(x)
x = self.pw_reparam(x)
x = self.nonlinearity(x)
return x
if self.dw_bn_layer is None:
id_out = 0
else:
id_out = self.dw_bn_layer(inputs)
x_conv_3x3 = []
for k_idx in range(self.k):
x = getattr(self, f'dw_3x3_k_idx')(inputs)
x_conv_3x3.append(x)
x_conv_1x1 = self.dw_1x1(inputs)
# print(x_conv_1x1.shape, x_conv_3x3[0].shape)
# print(x_conv_1x1.shape)
# print(id_out)
x = id_out + x_conv_1x1 + sum(x_conv_3x3)
x = self.nonlinearity(self.se(x))
# 1x1 conv
if self.pw_bn_layer is None:
id_out = 0
else:
id_out = self.pw_bn_layer(x)
x_conv_1x1 = []
for k_idx in range(self.k):
x_conv_1x1.append(getattr(self, f'pw_1x1_k_idx')(x))
x = id_out + sum(x_conv_1x1)
x = self.nonlinearity(x)
return x
class MobileOne(nn.Module):
# MobileOne
def __init__(self, in_channels, out_channels, n, k,
stride=1, dilation=1, padding_mode='zeros', deploy=False, use_se=False):
super().__init__()
self.m = nn.Sequential(*[MobileOneBlock(in_channels, out_channels, k, stride, deploy) for _ in range(n)])
def forward(self, x):
x = self.m(x)
return x
yolo.py配置
然后找到./models/yolo.py文件下里的parse_model函数,将类名加入进去
在 models/yolo.py文件夹下
- parse_model函数中
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部- 对应位置 下方只需要增加
MobileOne模块
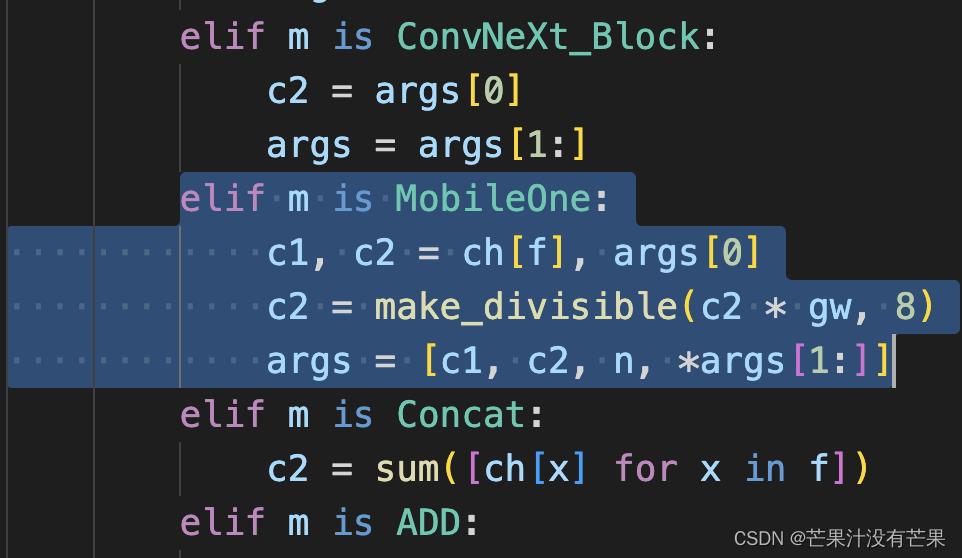
参考代码
elif m is MobileOne:
c1, c2 = ch[f], args[0]
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, n, *args[1:]]
参考示意图
训练yolov5_MobileOneBlock模型
python train.py --cfg yolov5_MobileOneBlock.yaml
针对以上yaml文件继续修改
关于yolov5_MobileOneBlockyaml文件配置中的MobileOneBlock模块,可以针对不同数据集自行再进行魔改,原理一致
未经允许,禁止转载
注: MobileOne模块复现代码引用链接:https://github.com/shoutOutYangJie/MobileOne
以上是关于改进YOLOv5系列:4.YOLOv5_最新MobileOne结构换Backbone修改,超轻量型架构,移动端仅需1ms推理!苹果最新移动端高效主干网络的主要内容,如果未能解决你的问题,请参考以下文章