Elasticsearch:使用 Jupyter Notebook 创建 Python 应用导入 CSV 文件
Posted 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:使用 Jupyter Notebook 创建 Python 应用导入 CSV 文件相关的知识,希望对你有一定的参考价值。
在开发 Python 应用时,经常会使用到 Jupyter 来完成 Python 应用的开发及调试。简而言之,Jupyter Notebook 是以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。在今天的文章中,我将使用 Jupyter 来进行展示。
今天我就一个简单的例子来进行展示如何使用 Python 语言导入一个 CSV 文件 。这个 CSV 的文件很简单,但是我们通过这个文件来展示如何在 Python 中使用相应的 API 来导入数据。
addresses.csv
id,firstname,surname,address,city,state,postcode
1,John,Doe,120 jefferson st.,Riverside,NJ,08075
2,Jack,McGinnis,220 hobo Av.,Phila,PA,09119
3,John Da Man,Repici,120 Jefferson St.,Riverside,NJ,08075
4,Stephen,Tyler,7452 Terrace At the Plaz road,SomeTown,SD,91234
5,Joan the bone,Anne,Jet 9th at Terrace plc,Desert City,CO,00123我们在自己的电脑上创建一个叫做 py-elasticsearch 的目录,并把 addresses.csv 文件拷贝到这个文件夹中。我们在这个目录中启动 jupyter:
$ pwd
/Users/liuxg/python/py-elasticsearch
$ ls
addresses.csv安装
我们需要安装如下的部分:
Elastic Stack
你可以参照文章 “Elastic:菜鸟上手指南” 来根据自己的操作系统来安装自己的 Elasticsearch 及 Kibana。你需要启动 Elasticsearch 及 Kibana。
Jupyter
你需要安装 Jupyter 来创建 notebook。请根据自己的操作系统安装相应的软件。
Python
你可以安装最新的 Python 来进行实践。在我的电脑上,我安装的版本是 3.8.5。
$ jupyter notebook这样就创建了我们的一个 jupyter notebook。我们创建一个叫做 py-elasticsearch 的 notebook:
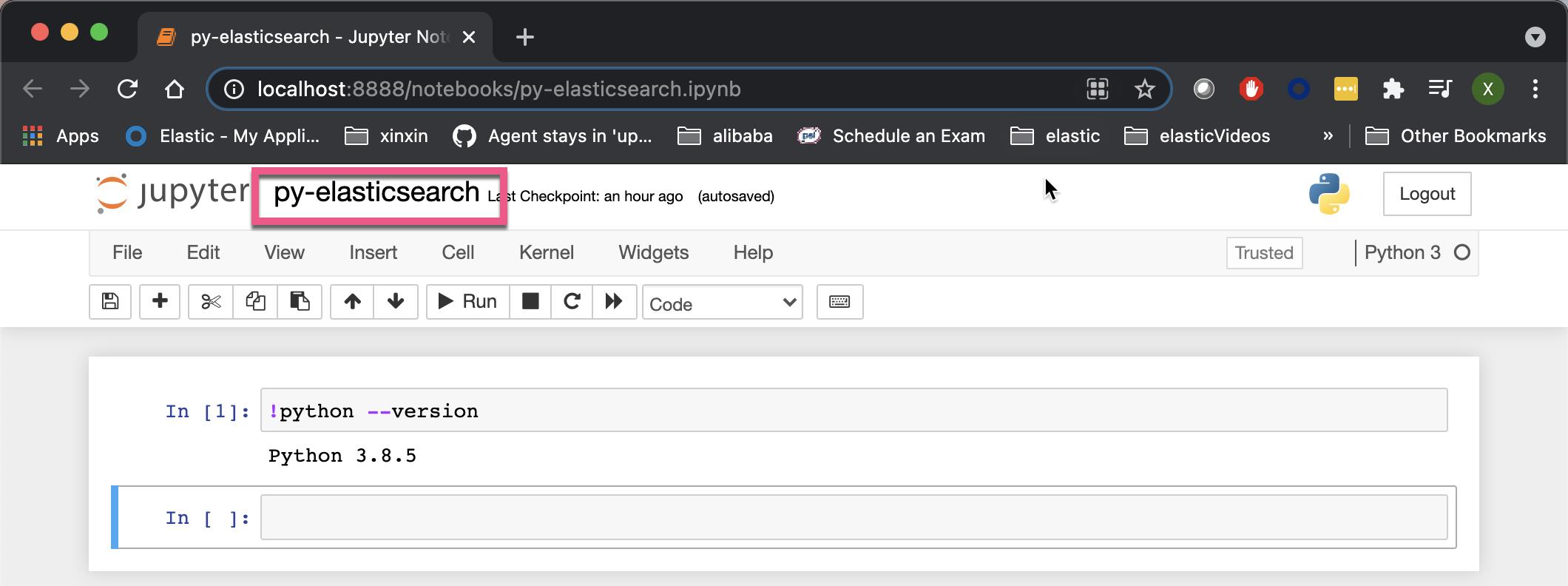
我们可以在命令前面添加 !来运行 SHELL 指令。上面显示我们的 python 版本信息。
创建 Python 应用
我们接下来需要在自己的电脑上安装相应的模块:
pip3 install elasticsearch
pip3 panda我们接下来输入如下的代码:
try:
import os
import sys
import elasticsearch
from elasticsearch import Elasticsearch
import pandas as pd
print("All Modules Loaded ! ")
except Exception as e:
print("Some Modules are Missing {}".format(e))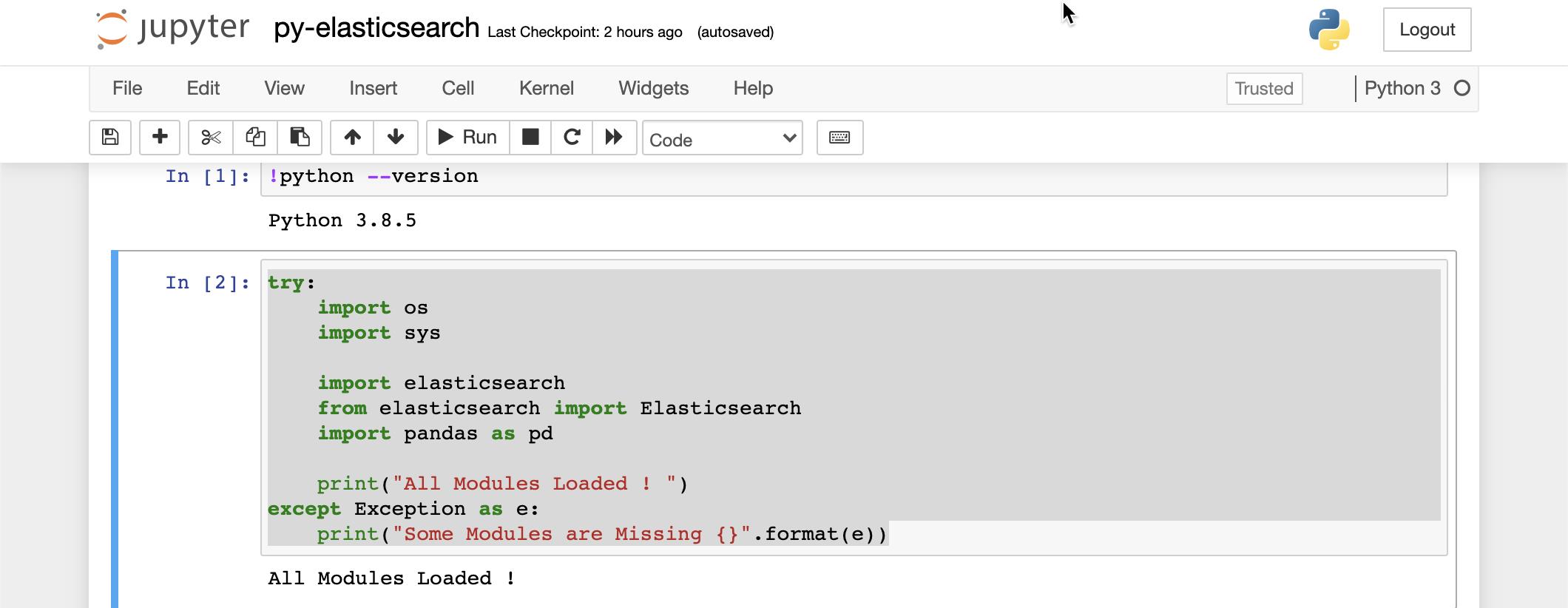
你可以使用 SHIFT + ENTER 来执行代码。上面显示所有的模块都已经被装载了。如果你没有看到上面的消息,你需要安装相应的模块。
我们接下来创建一个函数来连接 Elasticsearch:
def connect_elasticsearch():
es = None
es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
if es.ping():
print('Yupiee Connected ')
else:
print('Awww it could not connect!')
return es
es = connect_elasticsearch()
es.ping()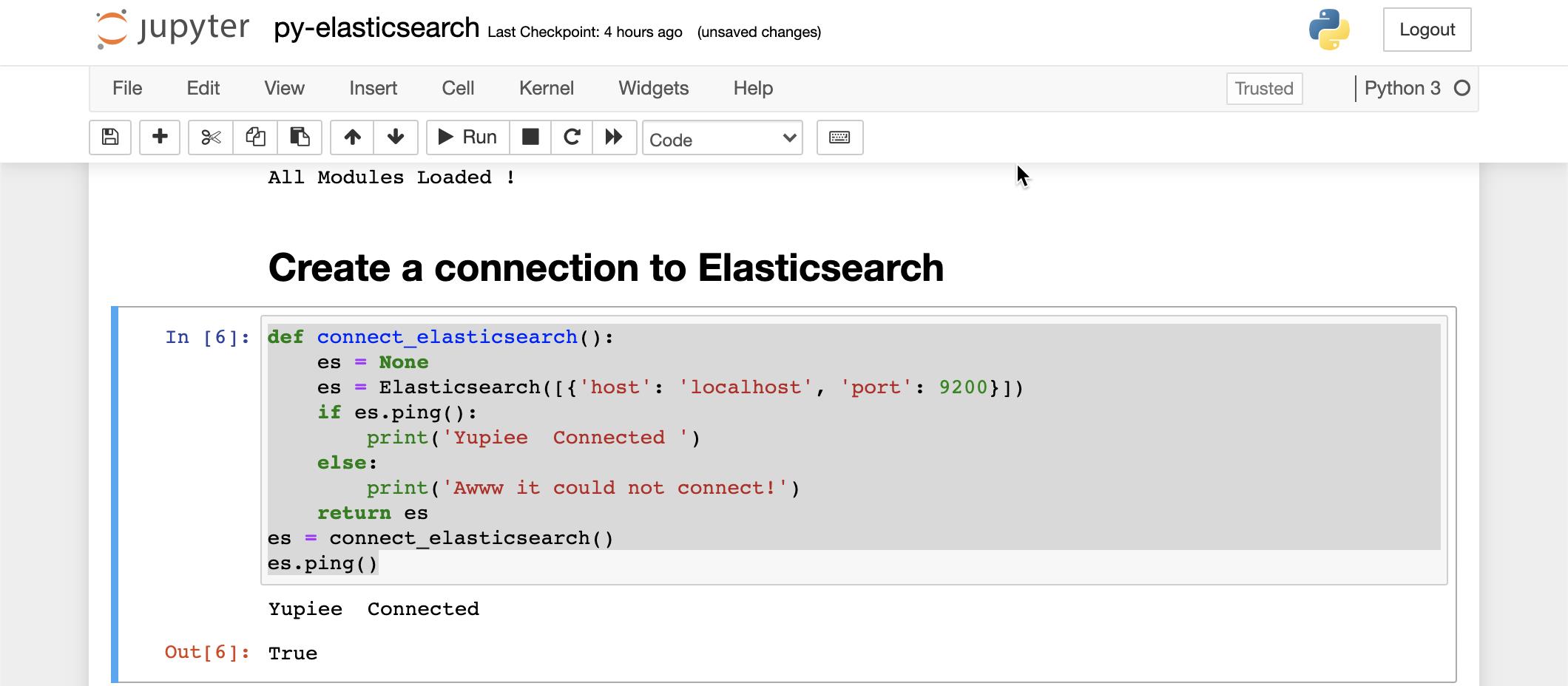
上面代码显示我们已经成功地连接到 Elasticsearch。接下来我们来创建一个叫做 liuxg-test 的 index:
es.indices.create(index="liuxg-test", ignore=400)
我们可以到 Kibana 中查看是否有一个叫做 liuxg-test 的 index 已经被创建:
GET _cat/indices/liuxg-test
我们接下来显示所有的索引:
res = es.indices.get_alias("*")
for name in res:
print(name)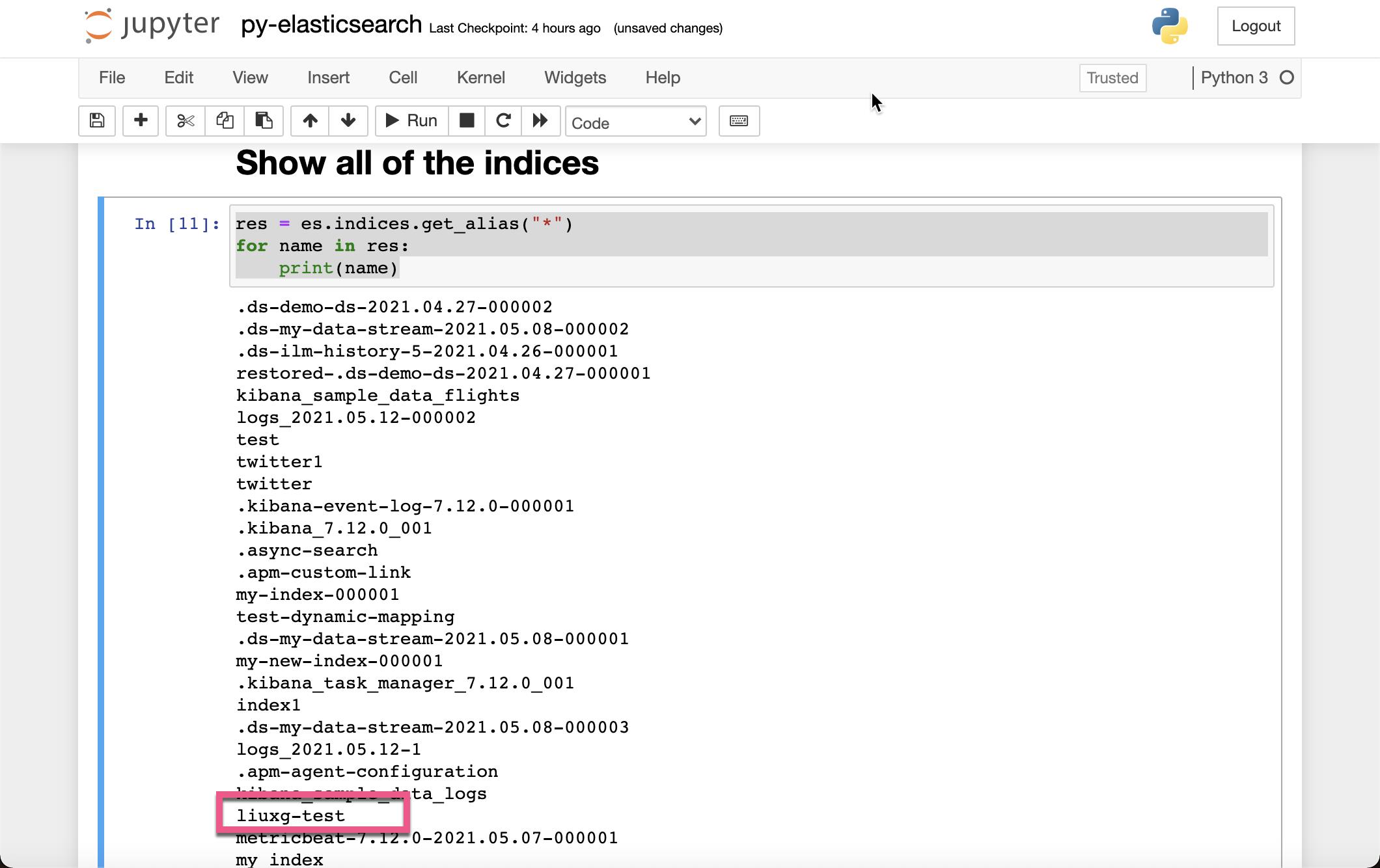
接下来,我们来删除上面我们已经创建的 liuxg-test 索引:
es.indices.delete(index="liuxg-test", ignore=[400,404])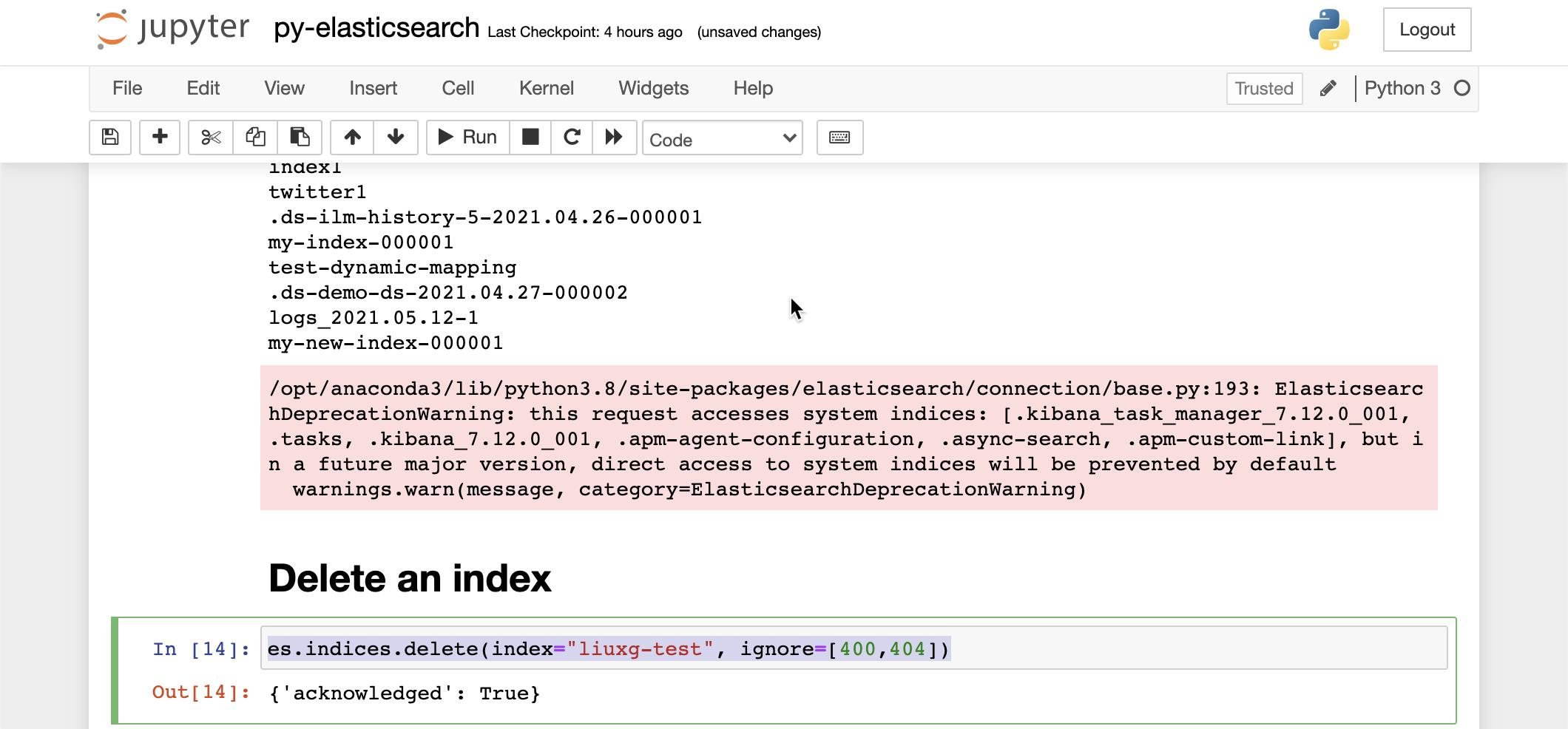
上面显示已经成功。我们可以去 Kibana,并再次查询 liuxg-test 索引:
GET _cat/indices/liuxg-test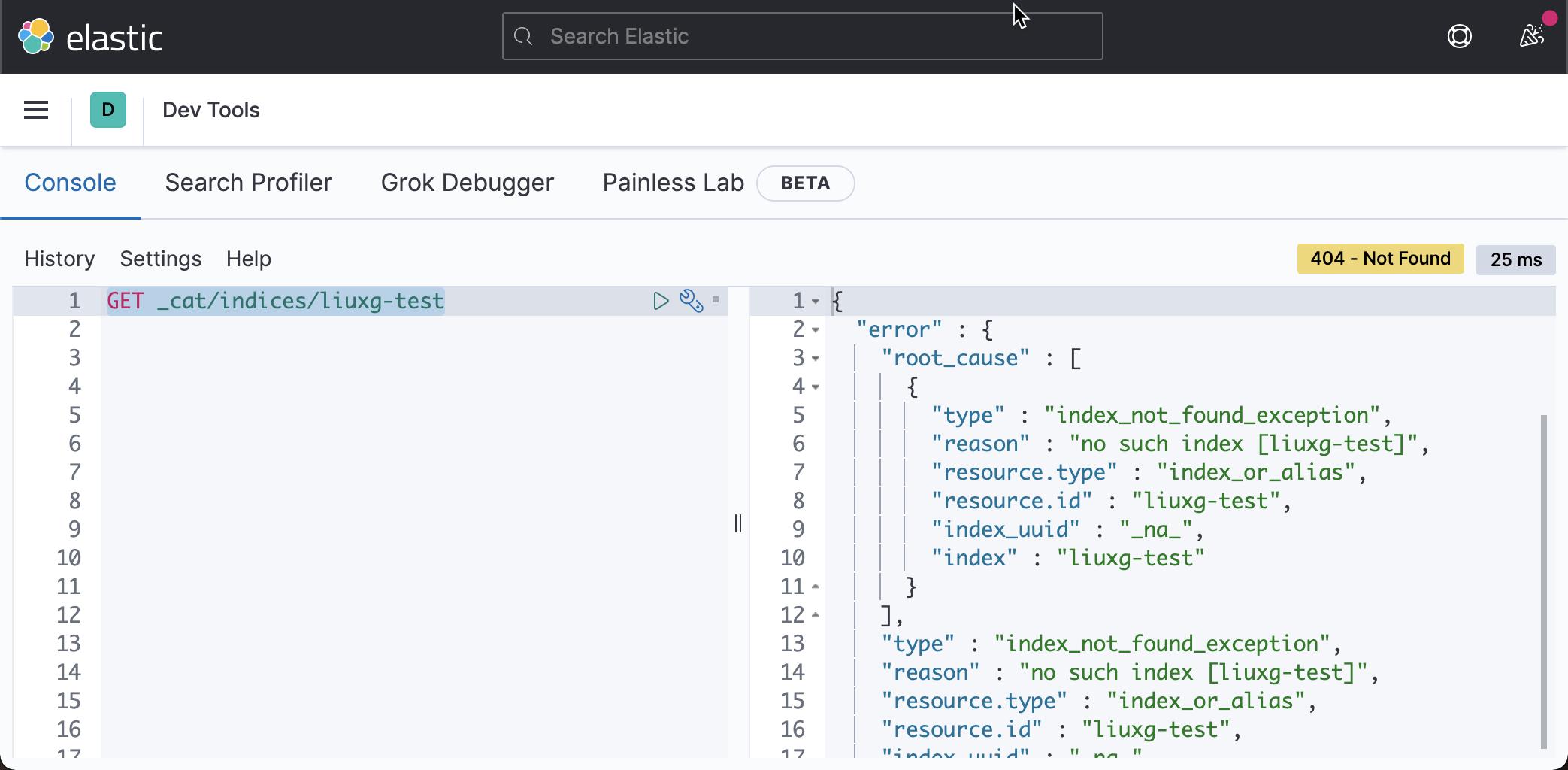
显然这次,我们没有看到 liuxg-test 这个索引。它表明我们的索引已经被删除了。
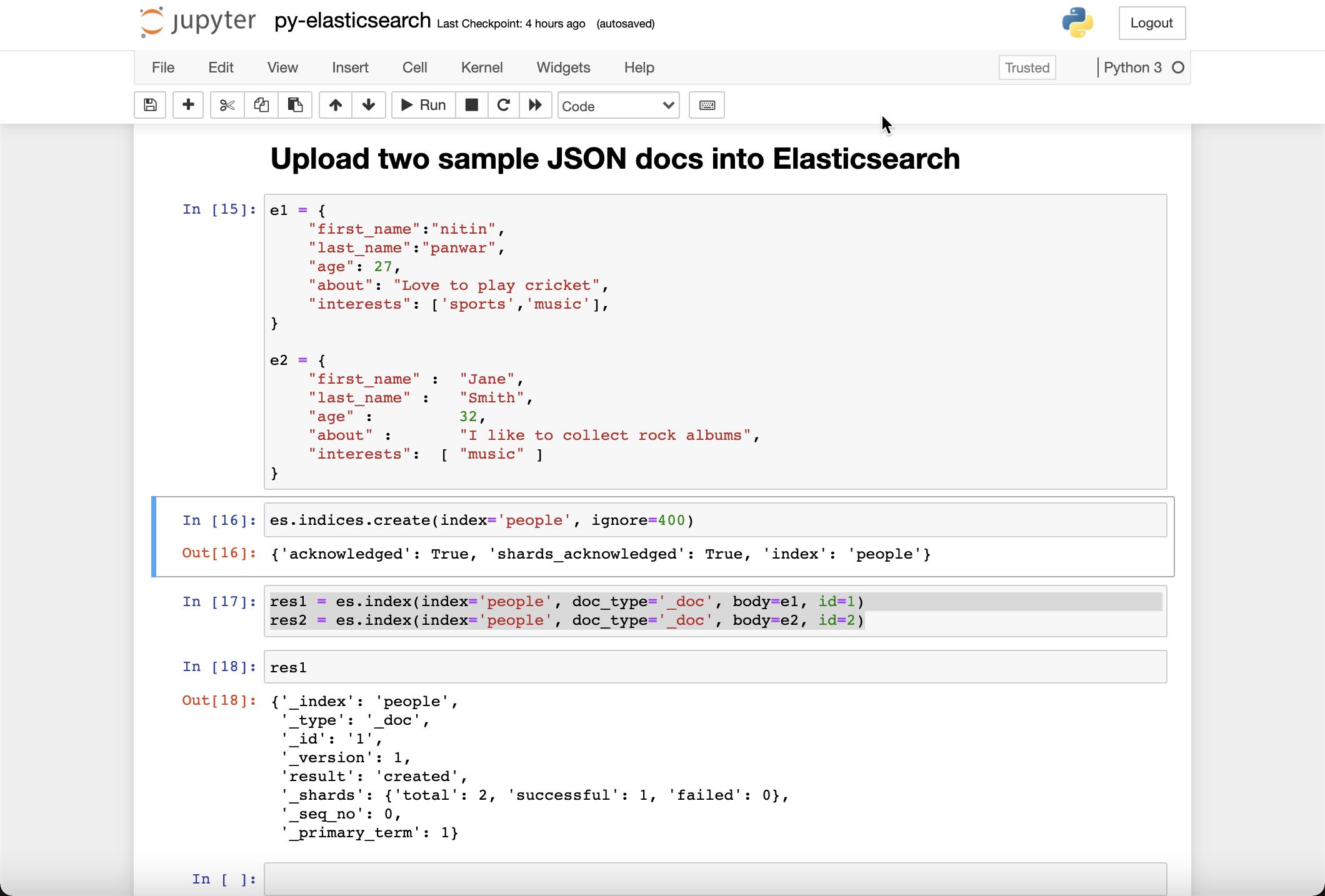
我们接下来导入两个文档到 Elasticsearch 中去:
e1 = {
"first_name":"nitin",
"last_name":"panwar",
"age": 27,
"about": "Love to play cricket",
"interests": ['sports','music'],
}
e2 = {
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}es.indices.create(index='people', ignore=400)
res1 = es.index(index='people', doc_type='_doc', body=e1, id=1)
res2 = es.index(index='people', doc_type='_doc', body=e2, id=2)在上面,我们创建了一个叫做 people 的索引,并把两个文档 e1 及 e2 导入到 Elasticsearch 中:
我们可以到 Kibana 中查看所以 people 的文档:
GET people/_search
我们可以清楚地看到有两个文档被成功地导入到 Elasticsearch 中。
我们接下来删除一个文档:
res = es.delete(index='people', doc_type='_doc', id=1)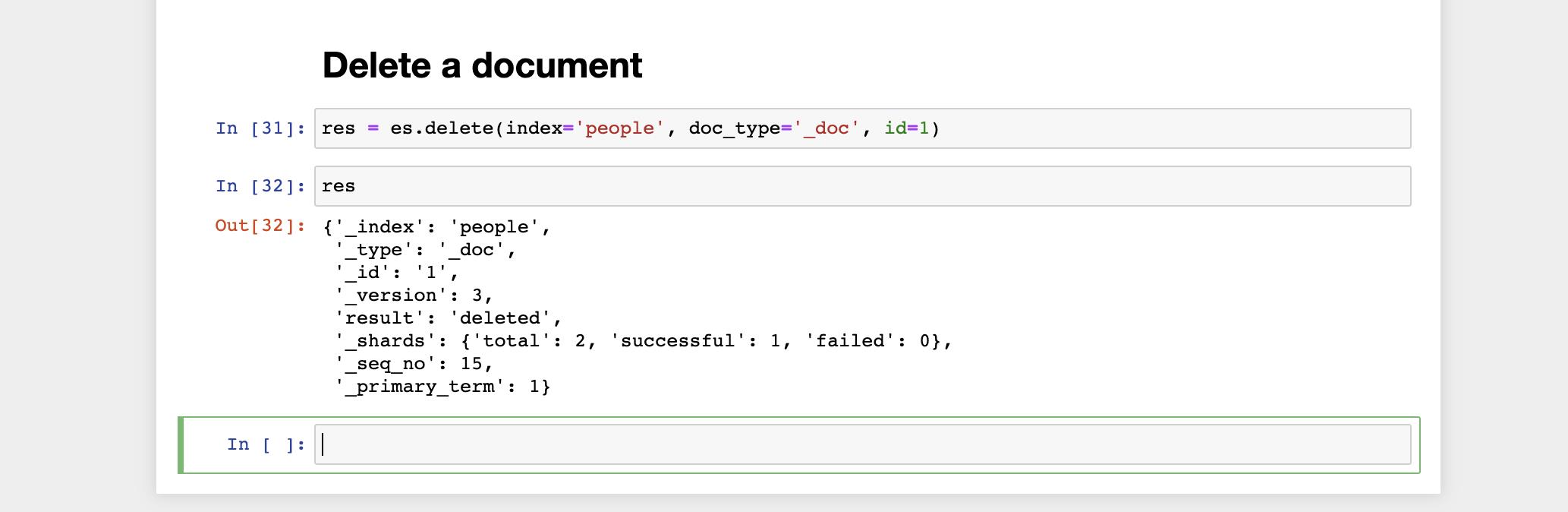
我们到 Kibana 中去查看 id 为1 的文档:
GET people/_doc/1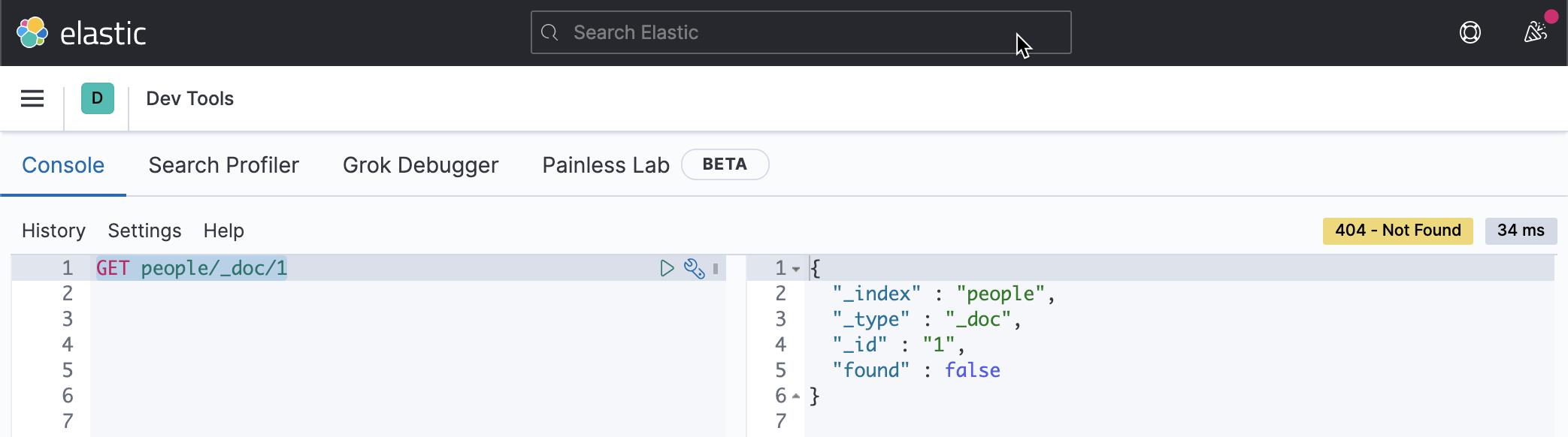
上面的命令显示该文档不存在。
接下来,我们来搜索所有的文档:
res = es.search(index = 'people', body = {'query': {"match_all": {}} } )
在很多的时候,我们需要定义一个索引的 settings 及 mapping。我们可以按照如下的调用来完成:
settings = {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"dynamic": "true",
"_source": {
"enabled": "true"
},
"properties": {
"title": {
"type": "text"
},
"name": {
"type": "text"
}
}
}
}
indexName = 'liuxg-with-mapping'
es.indices.create(index=indexName, ignore=[400,404], body=settings)
我们可以在 Kibana 中进行查看:
GET liuxg-with-mapping
导入 CSV 文件
接下来,我们来进行我们的正题。我们重新创建一个叫做 csv-elasticsearch 的 Notebook:
我们打入如下的命令来装载所有的模块:
try:
import elasticsearch
from elasticsearch import Elasticsearch
import pandas as pd
import json
from ast import literal_eval
from tqdm import tqdm
import datetime
import os
import sys
import numpy as np
from elasticsearch import helpers
print("Loaded ............")
except Exception as E:
print("Some Modules are Missing{}".format(e))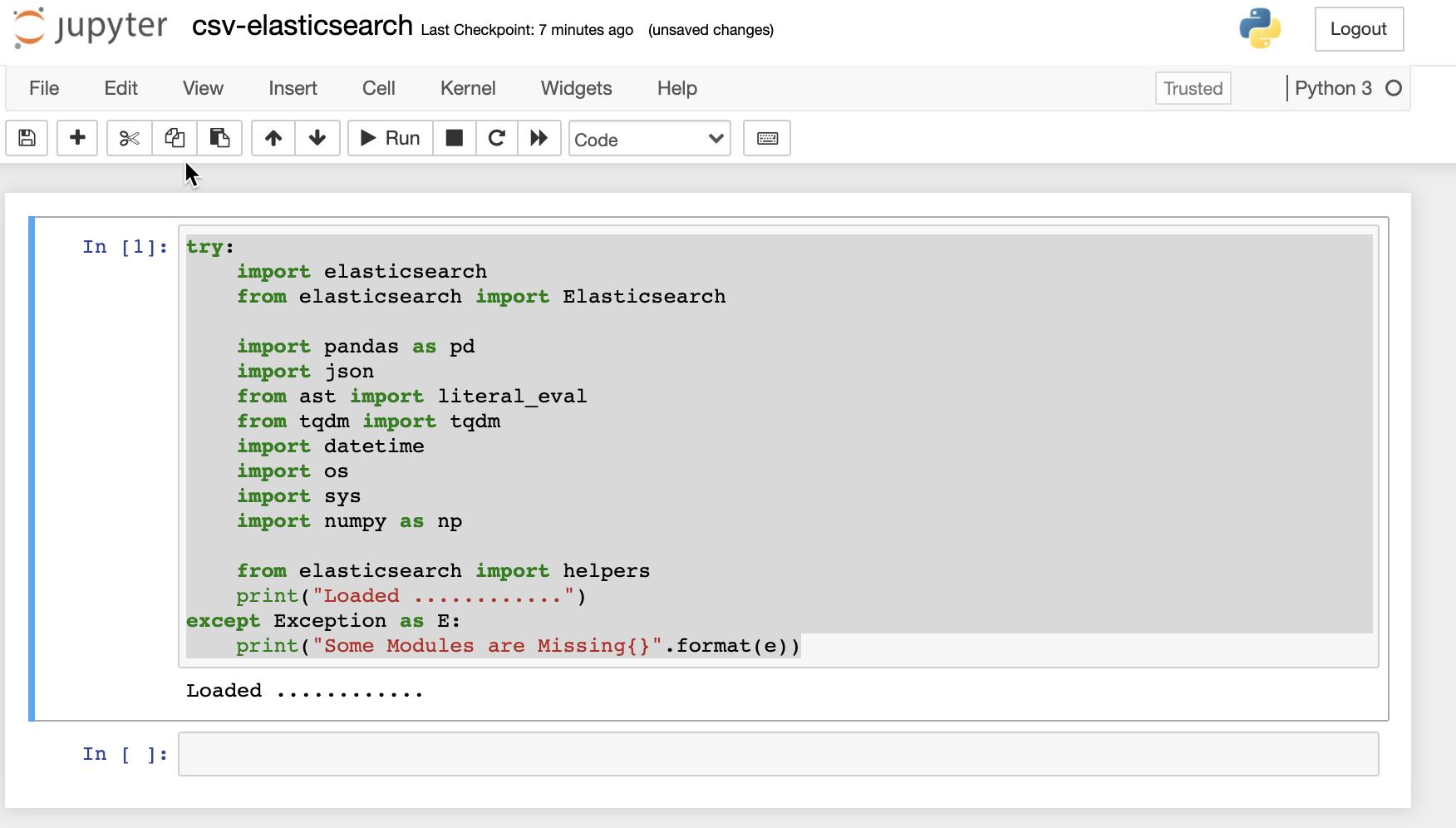
如果你看到 Loaded,则表明所有的模块都装载正确。否则,你需要安装相应的模块。接下来,我们确保我们之前的 addresses.csv 位于我们的 Jupyter 启动的目录里:
for name in os.listdir():
print(name)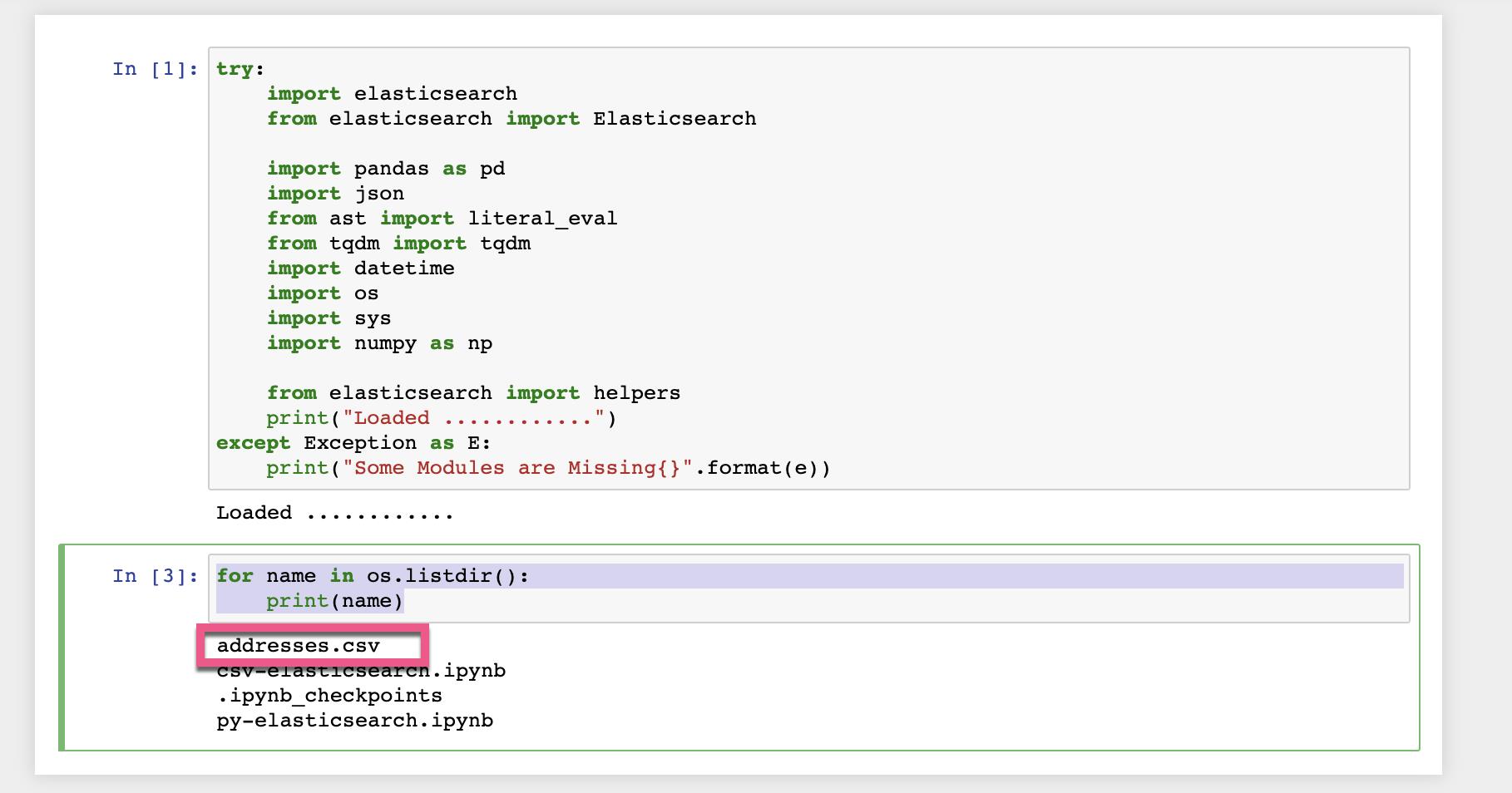
我们接下来尝试阅读这个 csv 文件。
df = pd.read_csv("addresses.csv")
df.head(2)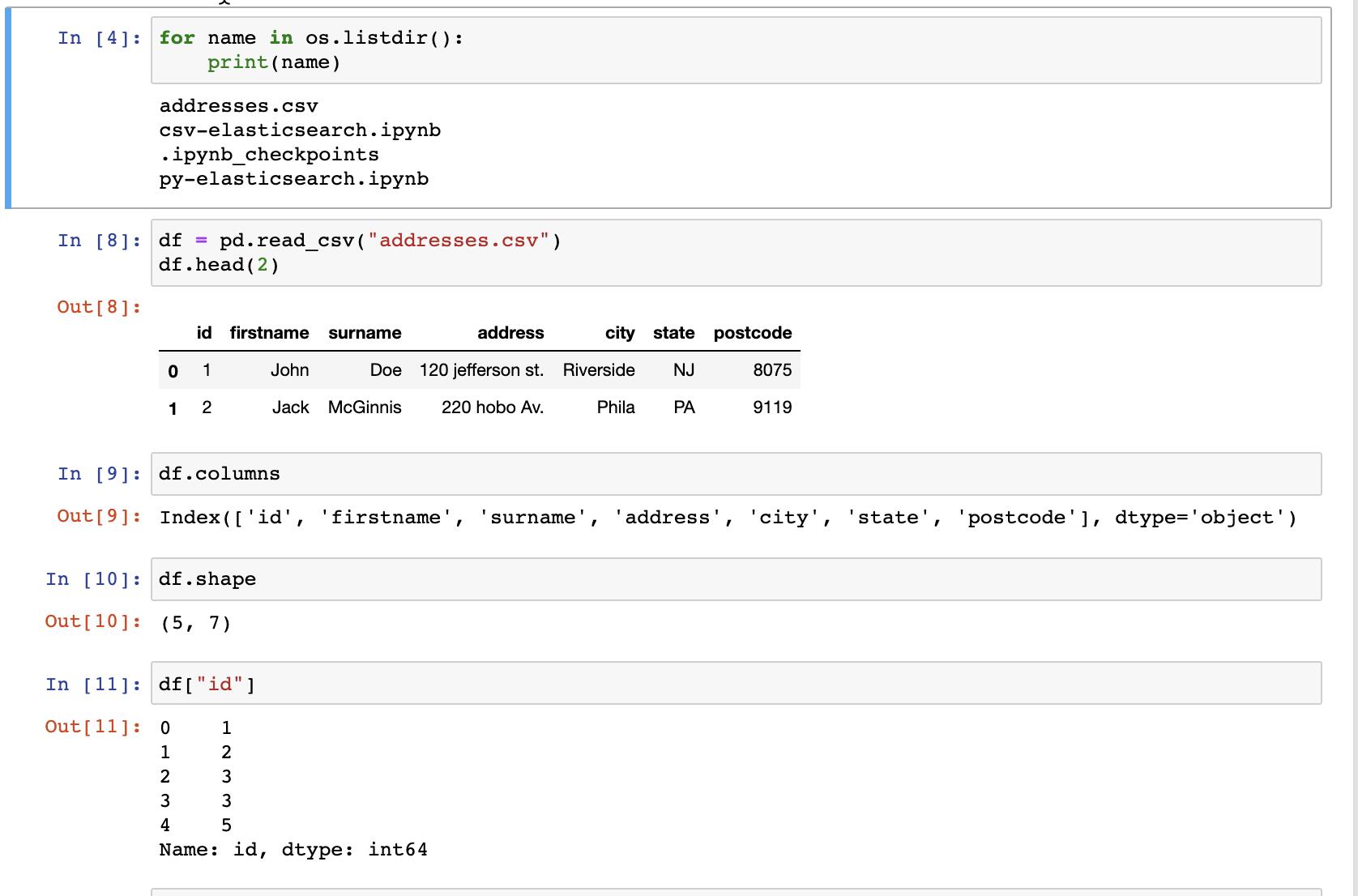
显然 Pandas 很方便地让我们读入我们的数据。上面显示我们有5个文档,有7列。在下面的代码中,我们将把文档中的 id 当做 Elasticsearch 文档中的 id。这个 id 是唯一的。我们来创建连接到 Elasticsearch 的实例:
ENDPOINT = "http://localhost:9200"
es = Elasticsearch(timeout=600, hosts = ENDPOINT)
es.ping()
在上面,我们对数据做了简单的清洗。对于确实任何一个项的文档,我们直接去掉。接下来,我们把 df 中的数据转换为 Elasticsearch 可以理解的格式:
df2 = df.to_dict('records')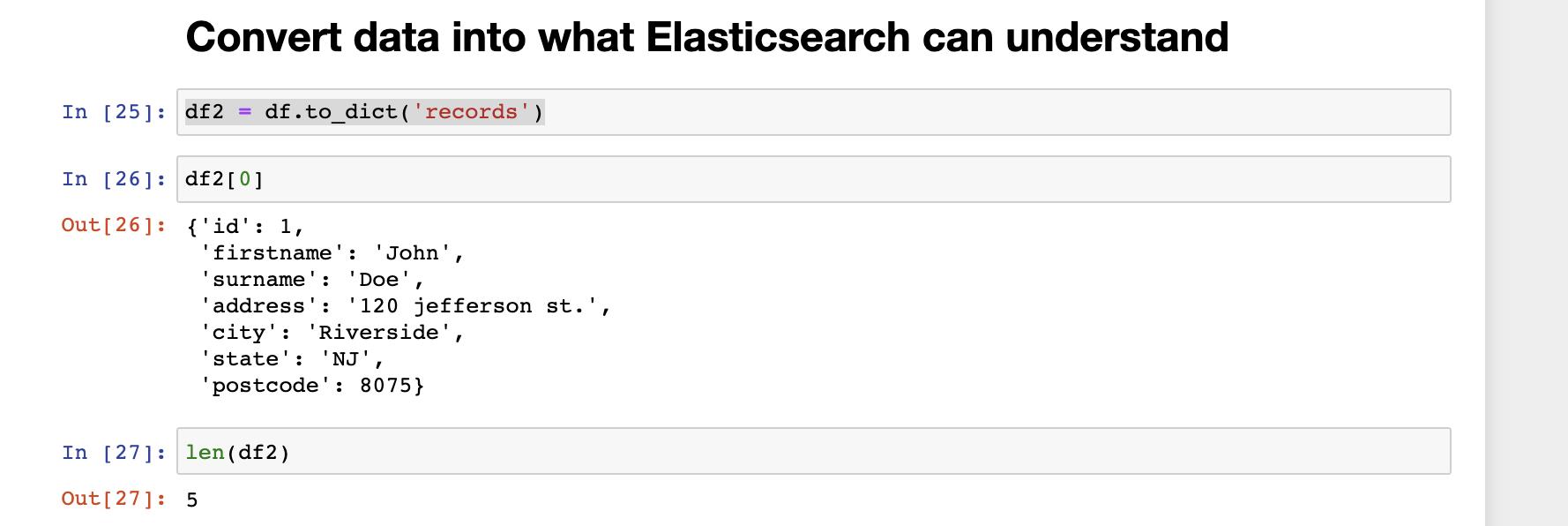
我们需要创建一个 generator 来把数据写入到 Elasticsearch:
def generator(df2):
for c, line in enumerate(df2):
try:
yield {
'_index': "addresses",
'_type': '_doc',
'_id': line.get("id", None),
'_source': {
"firstname":line.get("firstname", ""),
"surname":line.get("surname", ""),
"address":line.get("address", ""),
"city":line.get("city", ""),
"state":line.get("state", ""),
"postcode":line.get("postcode", "")
}
}
except StopIteration:
return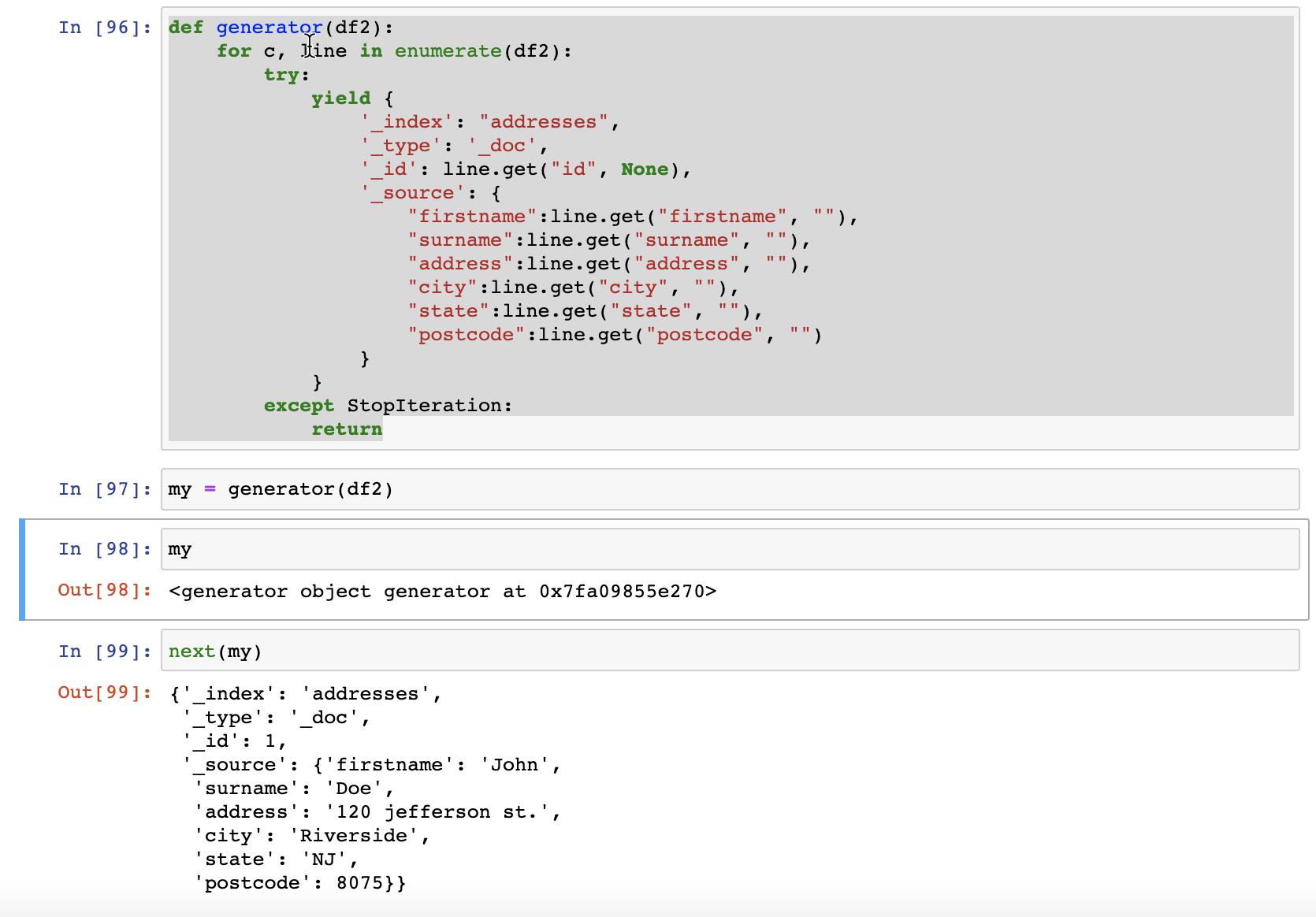
接下来,我们使用 helper 来导入数据:
try:
res = helper.bulk(es, generator(df2))
print("Working")
except Exception as e:
pass
我们到 Kibana 中查看 addresses 索引:
GET _cat/indices/addresses?vhealth status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open addresses eQCjFfWQTIyMR2D4eCyv-g 1 1 5 5 17.4kb 17.4kb上面显示有四个文档。我们最早的 CSV 文档中有5个文档,这是因为我们在进行 helper.bulk 之前,已经调用过 next(my) 一次。
我们可以使用如下的命令来进行查询:
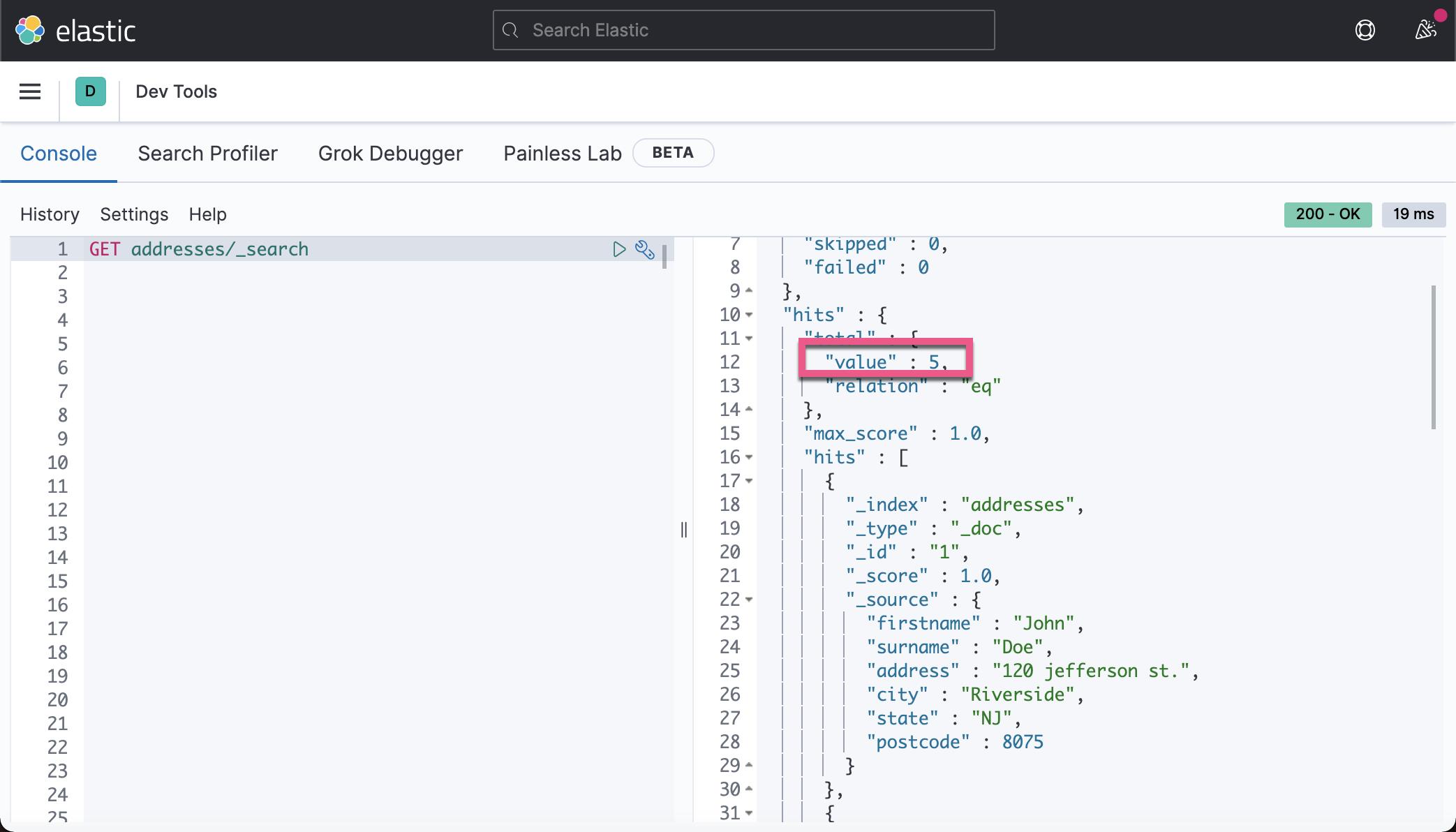
更多关于如何使用 Python 导入数据到 Elasticsearch 的介绍,可以参考文章 “Elasticsearch:Elasticsearch 开发入门 - Python”。
以上是关于Elasticsearch:使用 Jupyter Notebook 创建 Python 应用导入 CSV 文件的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch:使用 Python 进行 Bulk insert 及 Scan
Elasticsearch:使用 Python 进行 Bulk insert 及 Scan
Elasticsearch:运用 Python 来实现对搜索结果的分页
Elasticsearch:运用 Python 来实现对搜索结果的分页