Elasticsearch:运用 Python 来实现对搜索结果的分页
Posted 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:运用 Python 来实现对搜索结果的分页相关的知识,希望对你有一定的参考价值。
在今天的文章中,我将展示如何使用 Python 语言来针对搜索结果进行分页处理。我将使用 Jupyter 来进行展示。在我之前的文章 “Elasticsearch:使用 Jupyter Notebook 创建 Python 应用导入 CSV 文件” 中,我展示了如何使用 Jupyter 来对 Python 进行开发。在今天的文章中,我将进一步介绍如何使用 Python 来对 Elasticsearch 进行搜索。如果你对 Elasticsearch 的分页搜索还不是很熟的话,请参阅我之前的文章:
准备数据
在进行 Python 编程之前,我们可以在 Kibana 中输入如下的命令来导入一些实验数据:
POST _bulk
{ "index" : { "_index" : "twitter", "_id": 1} }
{"user":"双榆树-张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}}
{ "index" : { "_index" : "twitter", "_id": 2 }}
{"user":"东城区-老刘","message":"出发,下一站云南!","uid":3,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}}
{ "index" : { "_index" : "twitter", "_id": 3} }
{"user":"东城区-李四","message":"happy birthday!","uid":4,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}}
{ "index" : { "_index" : "twitter", "_id": 4} }
{"user":"朝阳区-老贾","message":"123,gogogo","uid":5,"age":35,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}}
{ "index" : { "_index" : "twitter", "_id": 5} }
{"user":"朝阳区-老王","message":"Happy BirthDay My Friend!","uid":6,"age":50,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}}
{ "index" : { "_index" : "twitter", "_id": 6} }
{"user":"虹桥-老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":90,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}}上面有6个数据。在搜索时,我们可以分为3页,也就是每页有2个文档。这是为了展示的方便。在实际的使用中,这个 pageSize 可以会比较大。
Python 分页展示
在下面,我们将使用3中不同的方式来进行展示。
from + size
我们可以使用 from + size 来进行搜索。这个适合于小数量的数据分页。首先,我们启动 Jupyter:
jupyter notebook我们接下来创建一个叫做 es-pagination 的 notebook:
我们接着修改 notebook 的名字为 es-pagination:

这样我们就创建好了我们的 notebook。
接下来,我们需要装载所有的模块:
try:
import os
import sys
import elasticsearch
from elasticsearch import Elasticsearch
import pandas as pd
print("All Modules Loaded ! ")
except Exception as e:
print("Some Modules are Missing {}".format(e))
如果我们不能看到上面的 All Modules Loaded !,则说明你需要安装相应的模块。这里就不再赘述。
我们接着创建一个连接到 Elasticsearch 的连接:
def connect_elasticsearch():
es = None
es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
if es.ping():
print('Yupiee Connected ')
else:
print('Awww it could not connect!')
return es
es = connect_elasticsearch()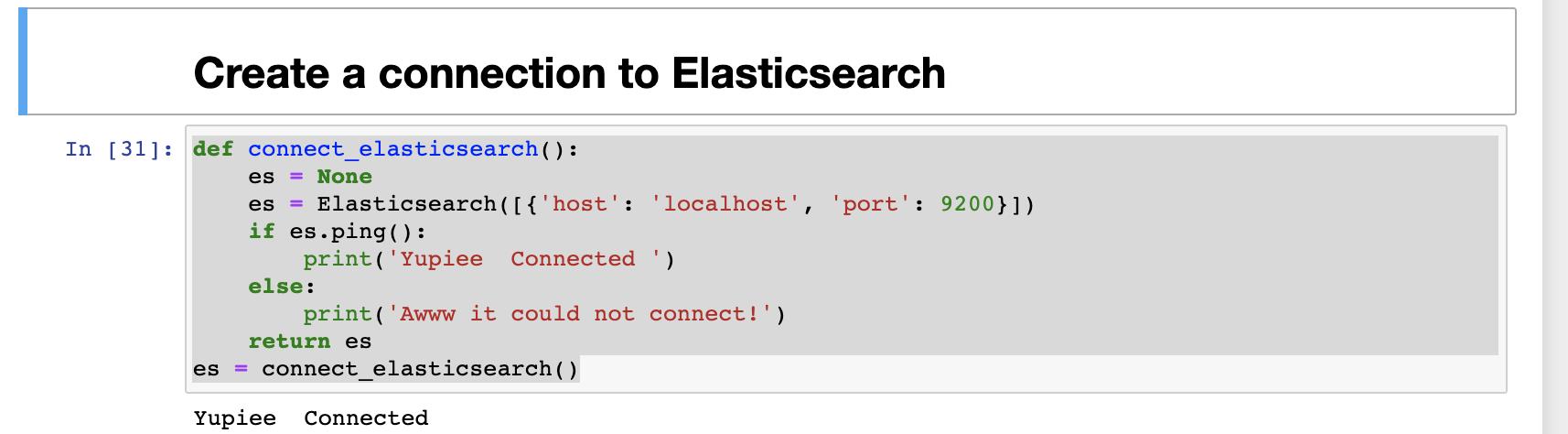
我们接下来创建一个搜索。在这个搜索中,我们定以 from 及 size 的值:
myquery = {
"query": {
"match": {
"city": "北京"
}
},
"from": 2,
"size": 2,
"sort": [
{
"user.keyword": {
"order": "desc"
}
}
]
}
res = es.search(
index = 'twitter',
size = 2,
body = myquery)
我们打印出来上面 res 的值:
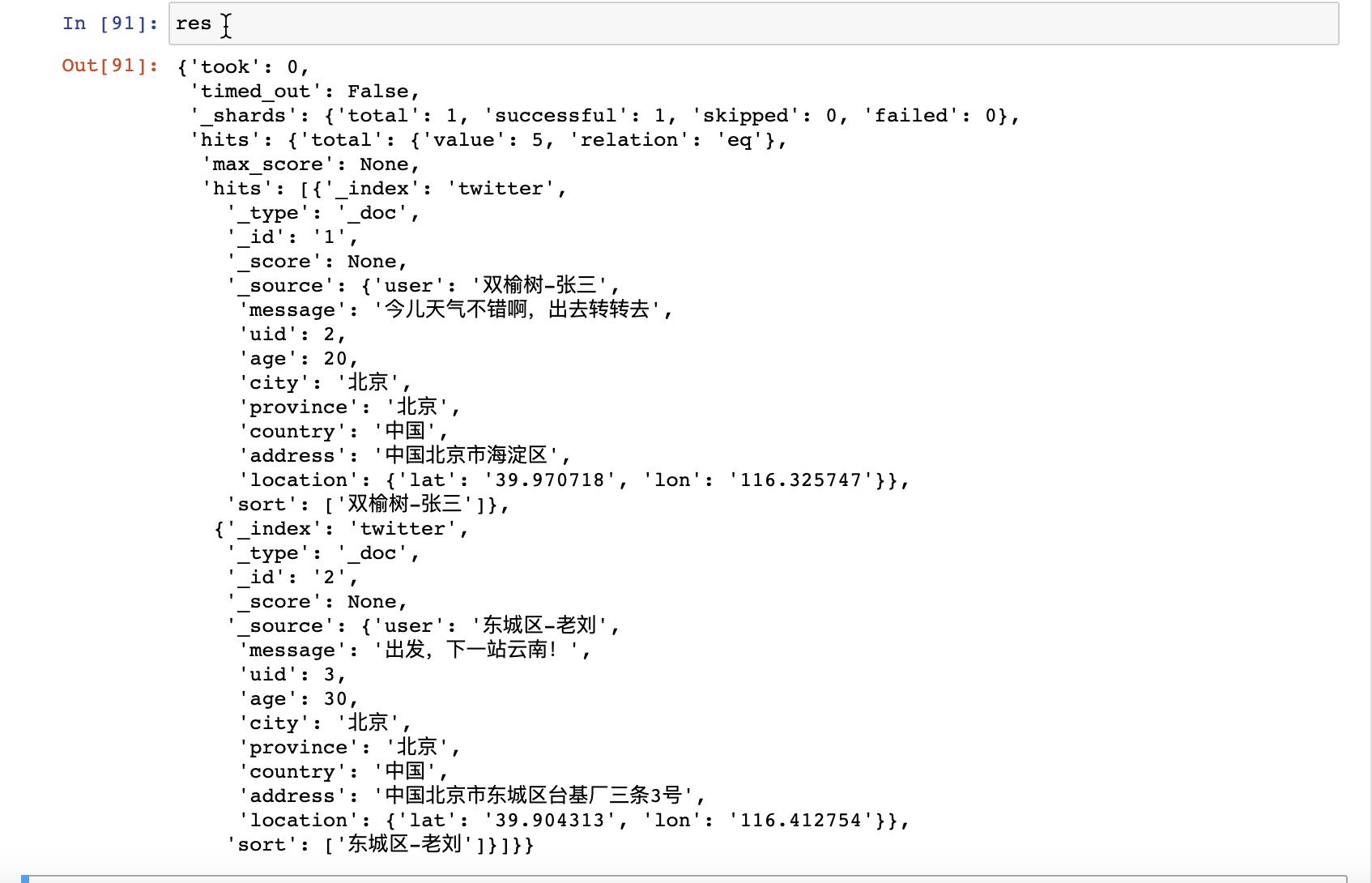
从上面,我们可以看出来有两个返回的结果。它返回的是第二页的结果。这个正是我们所需要的结果。
使用 scroll 来进行分页
在这种情况下,我们不能定义 from 参数。我们重新定义如下的 query:
myquery = {
"query": {
"match": {
"city": "北京"
}
},
"size": 2
}
res = es.search(
index = 'twitter',
scroll = '2m',
size = 2,
body = myquery)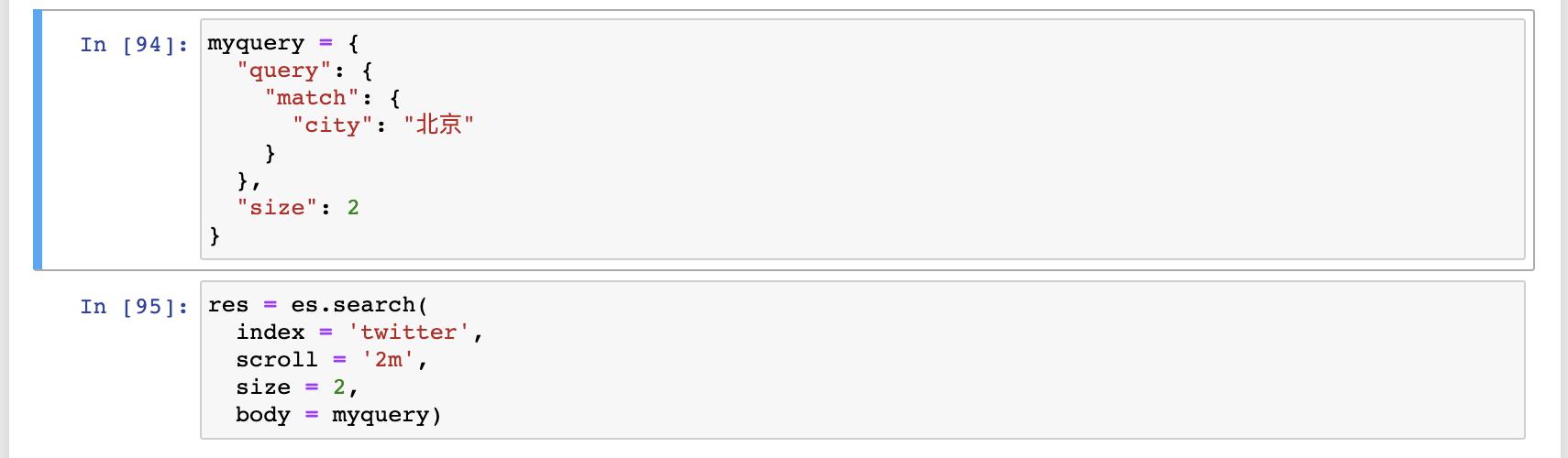
上面 res 的返回结果是:
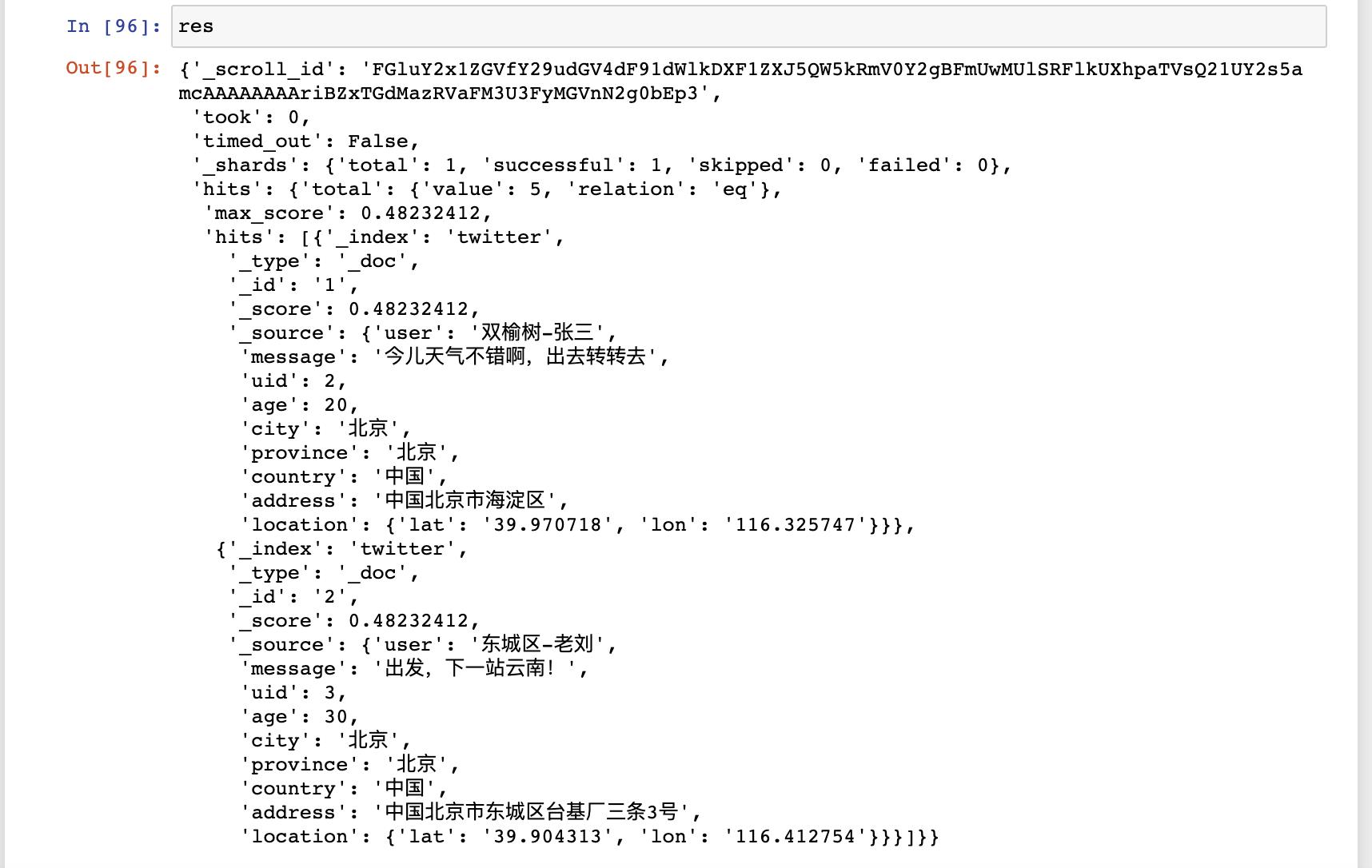
从上面的结果中,我们可以看出来一个叫做 _scroll_id 的字段。我们可以利用如下的程序来算出来有多少个 page:
counter = 0
sid = res["_scroll_id"]
scroll_size = res['hits']['total']
scroll_size = scroll_size['value']
# Start scrolling
while (scroll_size > 0):
#print("Scrolling...")
page = es.scroll(scroll_id = sid, scroll = '10m')
#print("Hits : ",len(page["hits"]["hits"]))
# Update the scroll ID
sid = page['_scroll_id']
# Get the number of results that we returned in the last scroll
scroll_size = len(page['hits']['hits'])
#print("Scroll Size {} ".format(scroll_size))
# Do something with the obtained page
counter = counter + 1
print("Total Pages : {}".format(counter))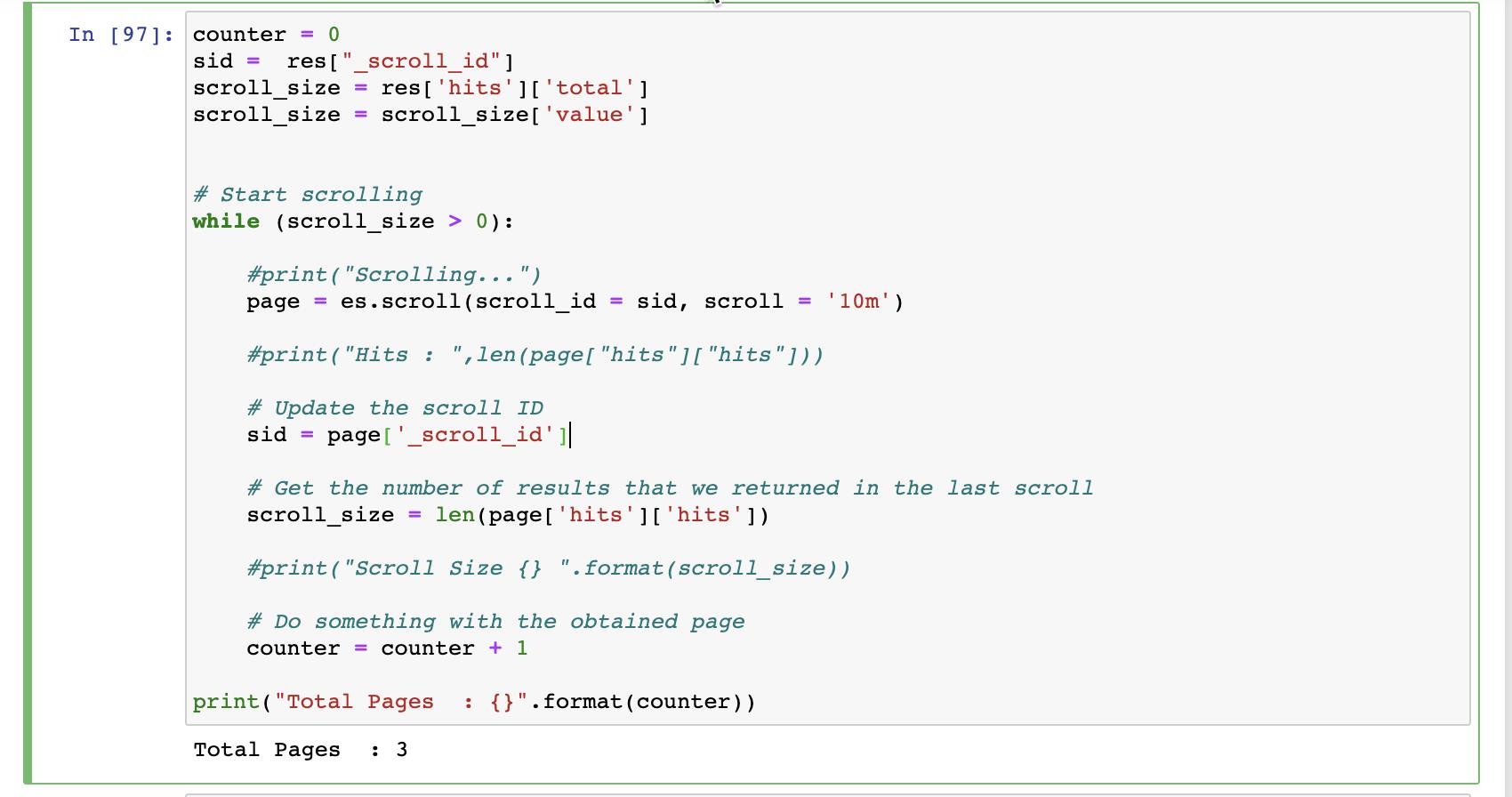
从上面的显示结果中,我们可以看出来有3页。当然,我们也可以在上面的代码中通过 page['hits']['hits'] 来得到每一个页里的文档的详情。
使用 search_after 来进行分页
我们可以重新定义如下的搜索:
myquery = {
"size": 2,
"query": {
"match": {
"city": "北京"
}
},
"sort": [
{
"age": {
"order": "asc"
}
},
{
"user.keyword": {
"order": "asc"
}
}
]
}
res = es.search(
index = 'twitter',
size = 2,
body = myquery)
上面显示的结果为:
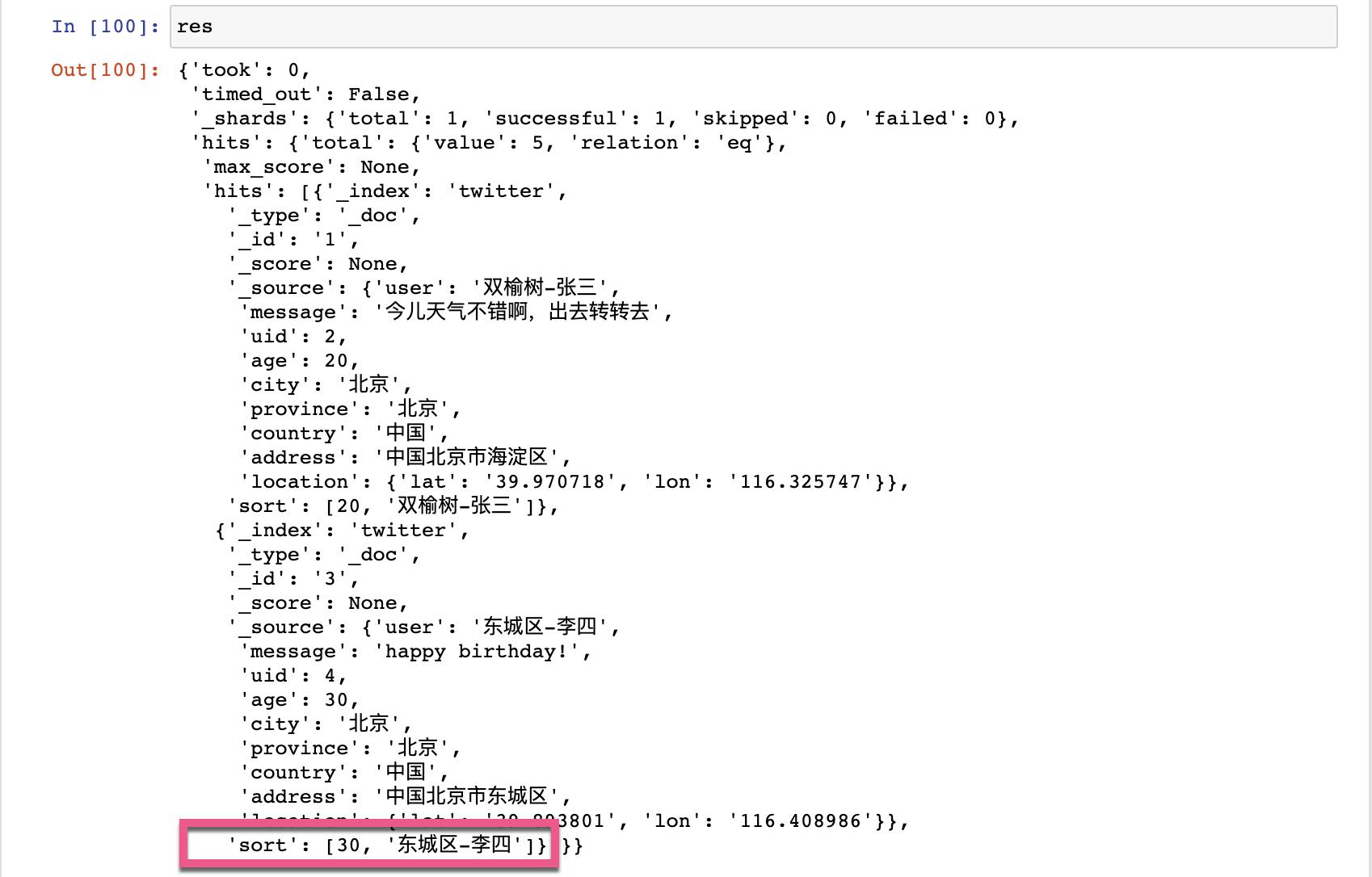
在上面,我们可以看到一个叫做 sort 的返回项。这个 sort 值可以用于接下来的 search_after 字段:
def create_scroll(res):
"""
:param res: json
:return: string
"""
try:
data = res.get("hits", None).get("hits", None)
data = data[-1]
sort = data.get("sort", "None")
return sort
except Exception as e:
return "Error,scroll error "
scroll = create_scroll(res)
myquery["search_after"] = scroll
我们接着进行如下的搜索:
res = es.search(
index = 'twitter',
size = 2,
body = myquery)
从上面的搜索结果中,我们可以看出来它显示的是接下来一页的结果。
在上面的例子中,由于考虑到简单的原因,我在 sort 时使用了 age 及 city 两个来进行排序。在实际的使用中,应该尽量使用两个字段的组合是唯一性,这样才会有正确的结果。在我们的例子中假如有两个人的 age 和 city 是一样的,那么会造成分页的错误。
如果我们想得到总的分页数,我们可以使用如下的方法。在得到第一个搜索结果后:
docs = len(res['hits']['hits'])
pages = 0
while docs != 0:
scroll = create_scroll(res)
myquery["search_after"] = scroll
print(scroll)
res = es.search(
index = 'twitter',
size = 2,
body = myquery)
docs = len(res['hits']['hits'])
print(docs)
pages += 1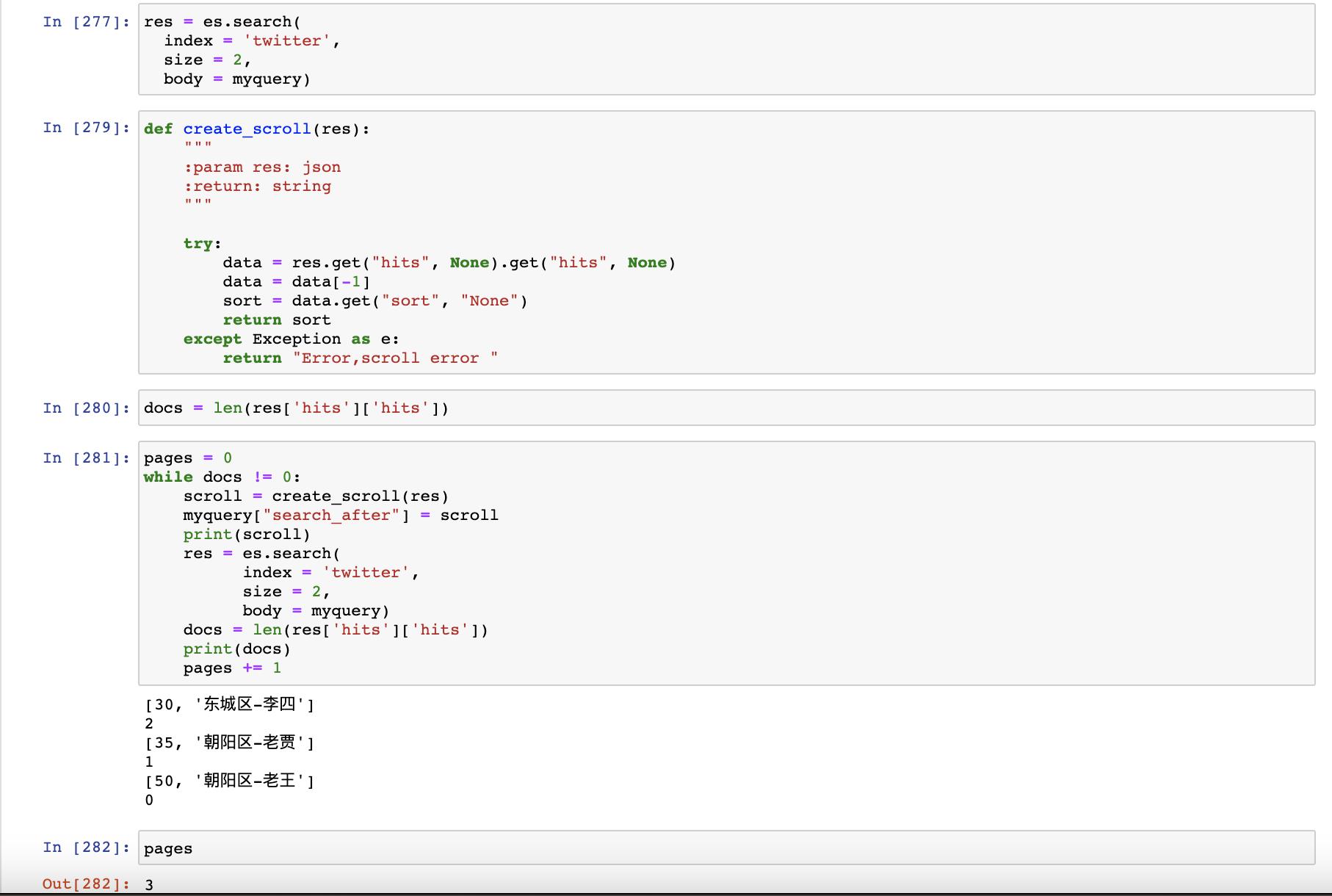
以上是关于Elasticsearch:运用 Python 来实现对搜索结果的分页的主要内容,如果未能解决你的问题,请参考以下文章