Kibana:Alerting - 警报介绍
Posted 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kibana:Alerting - 警报介绍相关的知识,希望对你有一定的参考价值。
在我之前的很多文章中,我都介绍了 Alerting。你可以在 “Elastic:菜鸟上手指南” 中的 “通知及警报” 一节找到。在今天的文章中,我将使用最新的 7.13 版本来展示如何使用规则(rules) 来检测复制条件下的 alerts。
警报(alerting)允许你定义规则以检测不同 Kibana 应用程序中的复杂条件并在满足这些条件时触发操作。 警报与可观察性、安全性、地图和机器学习集成,可以从管理 UI 集中管理,并提供一组内置连接器和规则(称为堆栈规则)供你使用。
重要提示:要确保你可以访问警报和操作,请参阅设置和先决条件部分。
概念及术语
警报的工作原理是按计划运行检查以检测规则定义的条件。 当满足某个条件时,规则会将其作为警报进行跟踪,并通过触发一个或多个操作进行响应。 操作通常涉及与 Kibana 服务或第三方集成的交互。 连接器允许操作与这些服务和集成进行对话。 本节介绍所有这些元素以及它们如何协同工作。
什么是规则?
规则指定在 Kibana 服务器上运行以检查特定条件的后台任务。 它由三个主要部分组成:
- 条件(conditions):需要检测什么?
- 调度(schedule):检测检查应该何时/多久运行一次?
- 动作(actions):检测到条件满足时需要做什么?
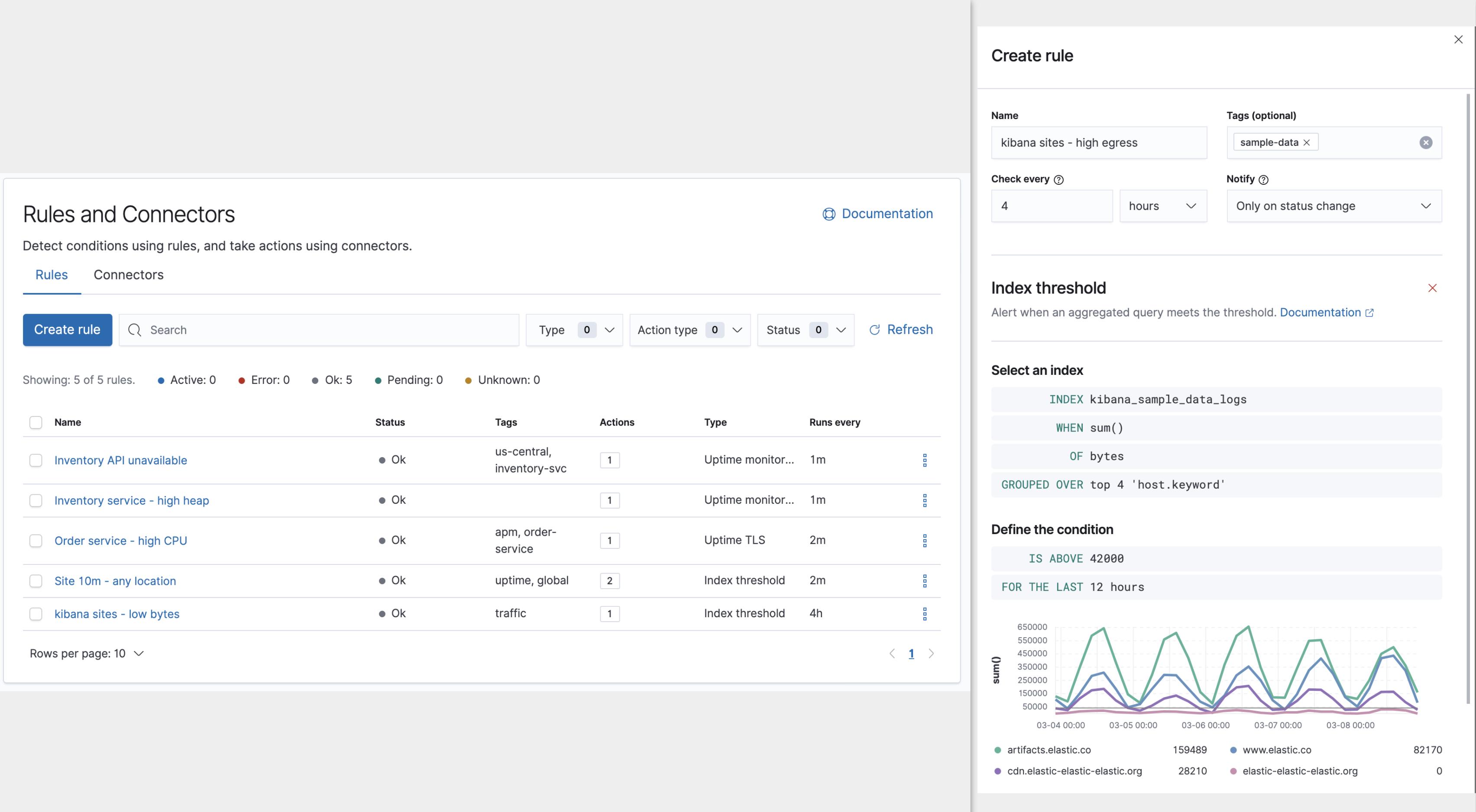
例如,在监控一组服务器时,规则可能会检查每台服务器上过去两分钟(条件)的平均 CPU 使用率 > 0.9,每分钟检查一次(schedule),通过 SMTP 发送警告电子邮件消息,主题为 “CPU on {{server}} is high”(action)。

以下部分更详细地描述了规则的每个部分。
条件
在幕后,Kibana 规则通过在 Kibana 服务器上运行 javascript 函数来检测条件,这使它能够灵活地支持各种条件,从简单的 Elasticsearch 查询的结果到涉及来自多个源或外部数据系统的数据进行的繁重计算。
这些条件被打包并公开为规则类型。 规则类型隐藏了条件的底层细节,并公开了一组参数来控制要检测的条件的细节。
例如,索引阈值规则类型允许你指定要查询的索引、聚合字段和时间窗口,但底层 Elasticsearch 查询的详细信息是隐藏的。
有关 Kibana 提供的规则类型及其表达条件的方式,请参阅堆栈规则类型和特定域的规则
调度
规则计划被定义为后续检查之间的间隔,范围从几秒到几个月不等。
重要:Kibana 中规则检查的间隔是近似的。 它们的执行时间受到诸如任务请求频率和系统任务负载等因素的影响。 有关详细信息,请参阅警报生产注意事项。
动作
动作是对连接器的调用,它允许与 Kibana 服务交互或与第三方系统集成。当满足规则条件时,动作在 Kibana 服务器上作为后台任务运行。
在规则中定义动作时,你指定:
- 连接器类型:要使用的服务或集成的类型
- 通过引用连接器获得该类型的连接
- 规则值到为该类型操作公开的属性的映射
结果是一个模板:提供调用服务所需的所有参数,除了仅在检测到规则条件时才知道的特定值。
在服务器监控示例中,使用电子邮件连接器类型,将服务器映射到电子邮件正文,使用模板字符串 CPU on {{server}} is high。
当规则检测到条件时,它会创建一个包含条件详细信息的警报,使用这些详细信息(例如服务器名称)呈现模板,并通过调用电子邮件连接器类型在 Kibana 服务器上执行操作。
有关 Kibana 提供的连接器类型的详细信息,请参阅连接器。
警报
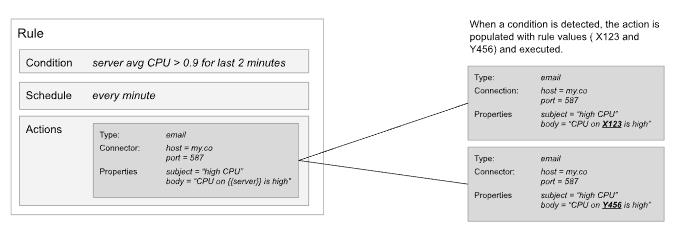
检查条件时,规则可能会标识条件的多次出现。 Kibana 分别跟踪这些警报中的每一个,并针对每个警报采取行动。
使用服务器监控示例,每台平均 CPU > 0.9 的服务器都会作为警报进行跟踪。 这意味着会为每个超出阈值的服务器发送单独的电子邮件。
抑制重复通知
由于每个警报都会执行操作,因此规则最终可能会生成大量操作。以以下示例为例,其中规则每分钟监控三台服务器的 CPU 使用率 > 0.9:
- 第 1 分钟:服务器 X123 > 0.9。为服务器 X123 发送一封电子邮件。
- 第 2 分钟:X123 和 Y456 > 0.9。发送了两封电子邮件,一封用于 X123,一封用于 Y456。
- 第 3 分钟:X123、Y456、Z789 > 0.9。发送了三封电子邮件,X123、Y456、Z789 各一封。
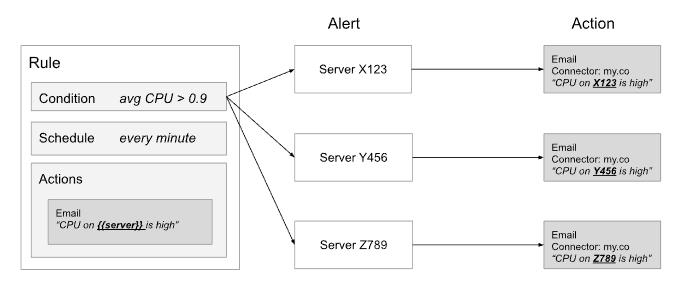
在上面的示例中,针对同一规则,在 3 分钟内为服务器 X123 发送了三封电子邮件。通常希望抑制频繁的重新通知。可以在警报级别应用静音(muting)和节流(throttling)等操作。如果我们将规则重新通知间隔设置为 5 分钟,我们将通过仅接收超过阈值的新服务器的电子邮件来减少噪音:
- 第 1 分钟:服务器 X123 > 0.9。为服务器 X123 发送一封电子邮件。
- 第 2 分钟:X123 和 Y456 > 0.9。为 Y456 发送一封电子邮件。
- 第 3 分钟:X123、Y456、Z789 > 0.9。为 Z789 发送一封电子邮件。
连接器
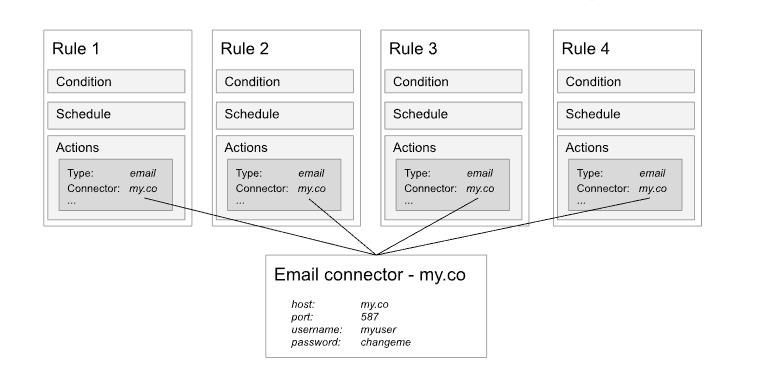
操作通常涉及连接 Kibana 内部的服务或与第三方系统集成。 Kibana 没有为每个操作重复输入连接信息和凭据,而是使用连接器简化了操作设置。
连接器提供了一个中心位置来存储服务和集成的连接信息。 例如,如果四个规则通过同一个 SMTP 服务发送电子邮件通知,它们都可以引用同一个 SMTP 连接器。 当 SMTP 设置更改时,你可以在连接器中更新一次,而不必更新四个规则。
概括
规则由条件(conditions)、动作(actions)和调度(schedule)组成。 当条件满足时,将创建呈现动作并调用它们的警报。 为了简化操作设置和更新,操作使用连接器来集中用于连接 Kibana 服务和第三方集成的信息。 以下示例将这些概念联系在一起:
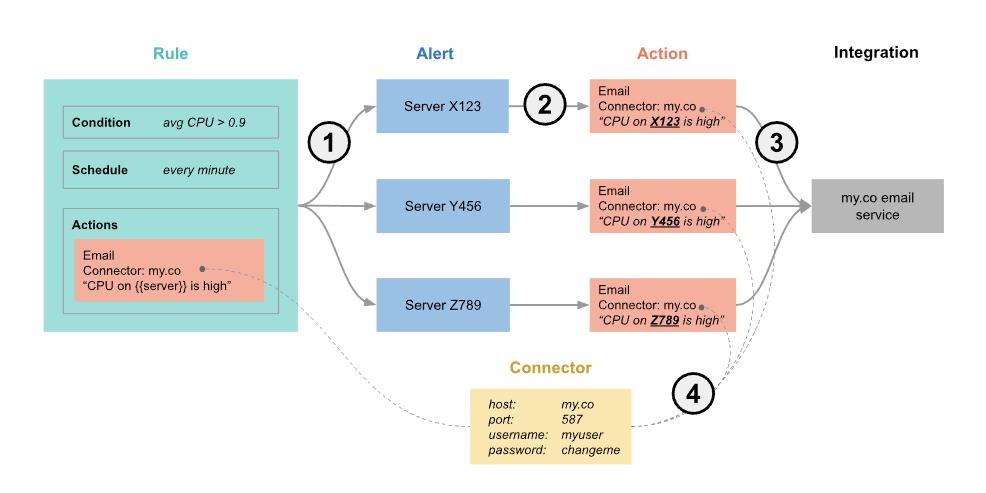
- 只要满足规则的条件,就会创建警报。 此示例检查平均 CPU > 0.9 的服务器。 三台服务器满足条件,因此创建了三个警报。
- 只要警报未被静音或限制,就会创建操作。 创建操作时,规则中设置的模板将填充实际值。 在此示例中,创建了三个操作,并且模板字符串 {{server}} 被替换为每个警报的服务器名称。
- Kibana 调用操作,将它们发送到第三方集成,如电子邮件服务。
- 如果第三方集成具有连接参数或凭据,Kibana 将从操作中引用的连接器中获取这些信息。
与 Watcher 的区别
Kibana 警报和 Elasticsearch 警报都用于检测条件并可以触发响应操作,但它们是完全独立的警报系统。
本节将阐明两个系统在功能和意图方面的一些重要差异。
在功能上,Kibana 警报的不同之处在于:
- 计划检查在 Kibana 而不是 Elasticsearch 上运行
- Kibana 规则通过规则类型隐藏了检测条件的细节,而 watcher 则提供对输入、条件和转换的低级控制。
- Kibana 规则通过警报跟踪和保留每个检测到的条件的状态。这使得静音和限制单个警报成为可能,并检测状态的变化,例如分辨率。
动作与 Kibana 警报中的警报相关联。每次检测到的情况都会触发动作,而不是针对整个规则。
在更高级别上,Kibana 警报允许跨 APM、指标、安全性和正常运行时间等用例进行丰富的集成。预先打包的规则类型简化了设置并隐藏了复杂的、特定于域的检测的细节,同时在 Kibana 中提供了一致的界面。
动手实践
在上面,我们已经讲了很多了。那么我们在实践中该如何来使用 rules 呢?接下来,我们来使用一个简单的例子来进行展示。首先我们按照我之前的文章 “Security:如何安装 Elastic SIEM 和 EDR” 来安装好 Elasticsearch 及 Kibana。
我们这样的安装肯定满足在 Kibana 中对我们的要求。安装完毕后,我们可以在 https://<elasticsearch>:9200 及 https://<kibana>:5601 进行访问。这里的 <elasticsearch> 及 <kibana> 依赖于你的安装地址而改变,比如:
我们接下来,也需要安装好 Filebeat。这里就不再累述了。不过为了能够使得我们的练习能够顺利进行,我们需要针对 Filebeat 的配置文件进行修改。针对 Ubuntu 操作系统而言,我们需要修改 /etc/filebeat/filebeat.yml 文件。
root@liuxgu:/etc/filebeat# pwd
/etc/filebeat
root@liuxgu:/etc/filebeat# ls
certs fields.yml filebeat.reference.yml filebeat.yml modules.d我们需要修改 kibana 的设置部分:
setup.kibana:
# Kibana Host
# Scheme and port can be left out and will be set to the default (http and 5601)
# In case you specify and additional path, the scheme is required: http://localhost:5601/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601
host: "192.168.0.4:5601"
protocol: "https"
ssl.certificate_authorities: ["/etc/filebeat/certs/ca/ca.crt"]请注意这里的证书 ca.crt 是在我们上一步安装 Elasticsearch 时所得到的。我们需要拷贝到上面指示的位置。192.168.0.4 是我的 Kibana 的 IP 地址。你需要换成你自己的 IP 地址。
我们同时需要修改 elasticsearch 的输出部分:
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["192.168.0.4:9200"]
# Protocol - either `http` (default) or `https`.
protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
username: "elastic"
password: "password"
ssl.certificate_authorities: ["/etc/filebeat/certs/ca/ca.crt"]这里的 192.168.0.4 是我的 Elasticsearch 的地址。当我们配置完毕后,我们需要重新启动 filebeat 服务:
service filebeat restart我们可以通过使用如下的命令来检查 filebeat 服务是否运行正常:
# service filebeat status
● filebeat.service - Filebeat sends log files to Logstash or directly to Elasti>
Loaded: loaded (/lib/systemd/system/filebeat.service; disabled; vendor pre>
Active: active (running) since Tue 2021-07-06 13:30:26 CST; 2h 28min ago
Docs: https://www.elastic.co/beats/filebeat
Main PID: 29120 (filebeat)
Tasks: 14 (limit: 18982)
Memory: 61.4M
CGroup: /system.slice/filebeat.service
└─29120 /usr/share/filebeat/bin/filebeat --environment systemd -c >
如果你看到显示的是 active,则标明 Filebeat 服务运行是正常的。
我们可以使用如下的命令来测试我们的配置是否成功:
# filebeat test config
Config OK我们可以使用如下的命令来检查 output 是否正常:
# filebeat test output
elasticsearch: https://192.168.0.4:9200...
parse url... OK
connection...
parse host... OK
dns lookup... OK
addresses: 192.168.0.4
dial up... OK
TLS...
security... WARN server's certificate chain verification is disabled
handshake... OK
TLS version: TLSv1.3
dial up... OK
talk to server... OK
version: 7.13.2我们接下来使用如下的命令来启动 system 模块:
# filebeat modules enable system我们使用如下的命令来进行配置:
# filebeat setup
Overwriting ILM policy is disabled. Set `setup.ilm.overwrite: true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
^C
root@liuxgu:/etc/filebeat# filebeat setup
Overwriting ILM policy is disabled. Set `setup.ilm.overwrite: true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Setting up ML using setup --machine-learning is going to be removed in 8.0.0. Please use the ML app instead.
See more: https://www.elastic.co/guide/en/machine-learning/current/index.html
Loaded machine learning job configurations
Loaded Ingest pipelines上面标明我们的配置是成功的。
如果你对如何使用 Filebeat 还不是很熟的话,请参阅我之前的文章 “Beats:Beats 入门教程 (二)”。
接下来,我们在 terminal 中,我们打入如下的命令:
# logger -t liuxg this is message上述命令将生成一个 system 日志,并且它的 process.name 是 liuxg。我们可以在 Kibana 的 Discover 中查找:
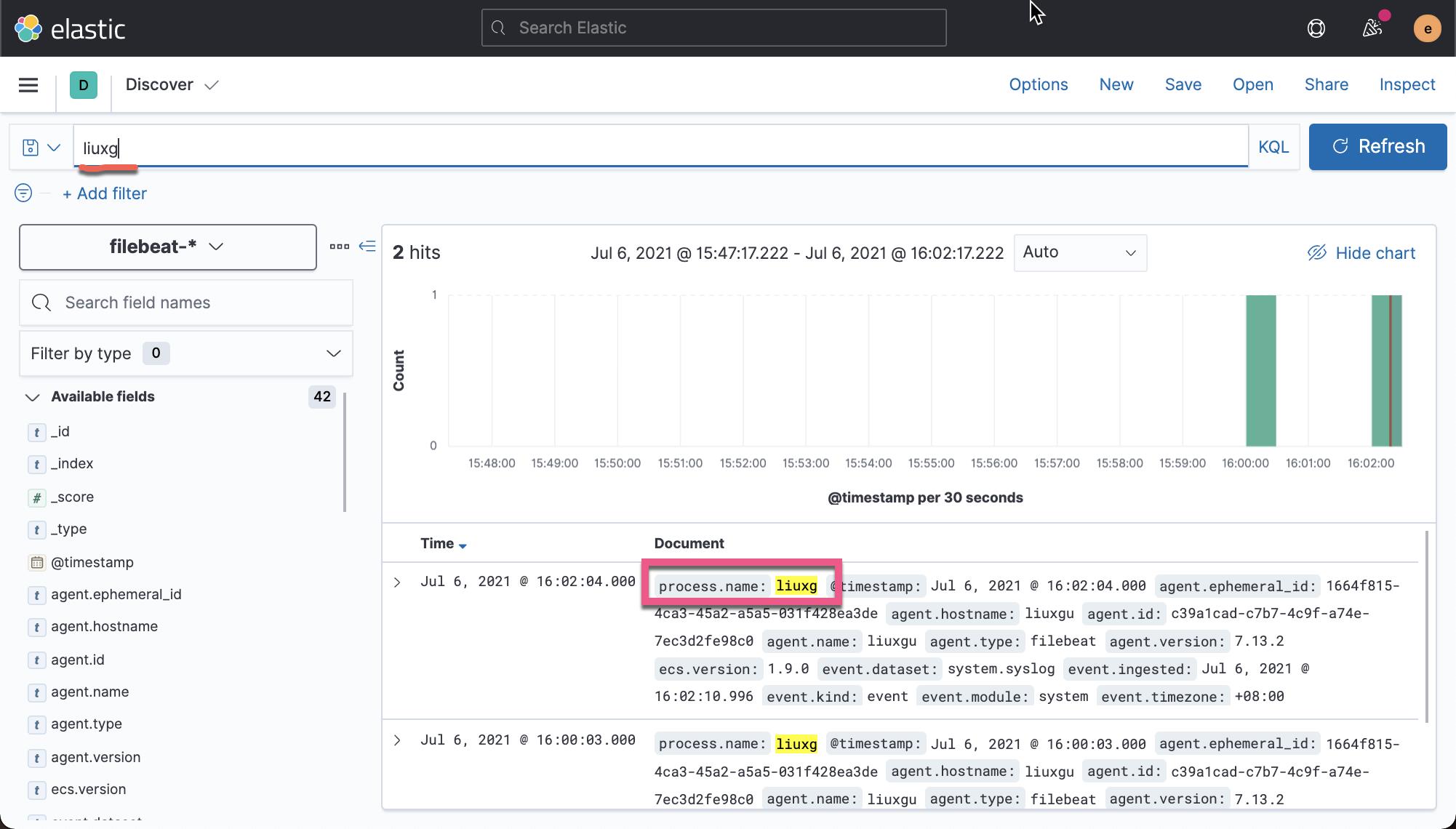
如果我们已经走到这一步,那么证明我们的配置是没有任何问题的。
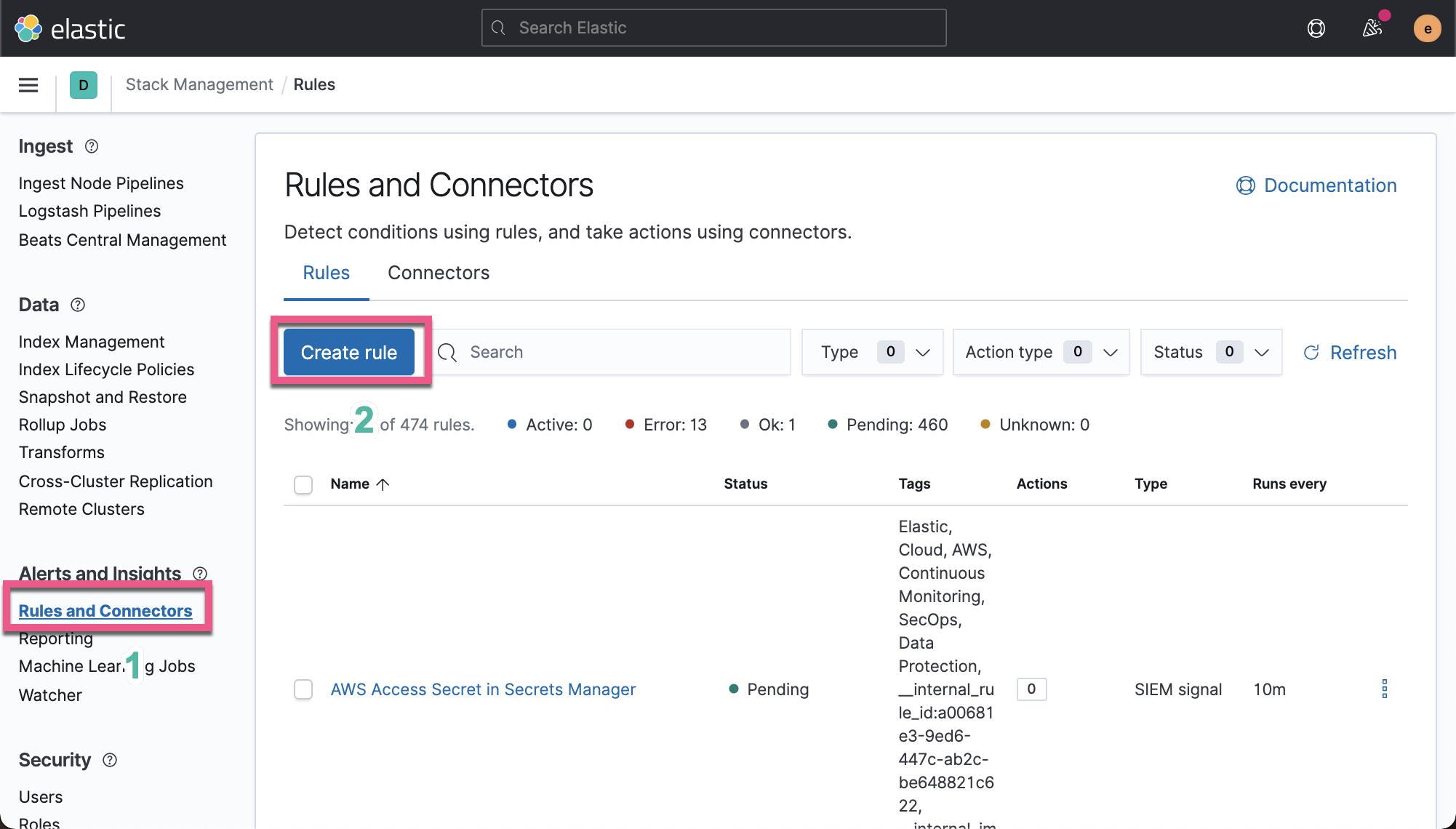
创建一个规则
Kibana 警报规则可以在各种应用程序中创建,包括 APM、机器学习、指标、安全性、Uptime 和管理 UI。 虽然警报详细信息可能因应用程序而异,但它们共享一个通用接口,用于定义和配置本节更详细描述的规则。
在今天的教程中,我们将直接从 “管理 UI” 来进行配置:
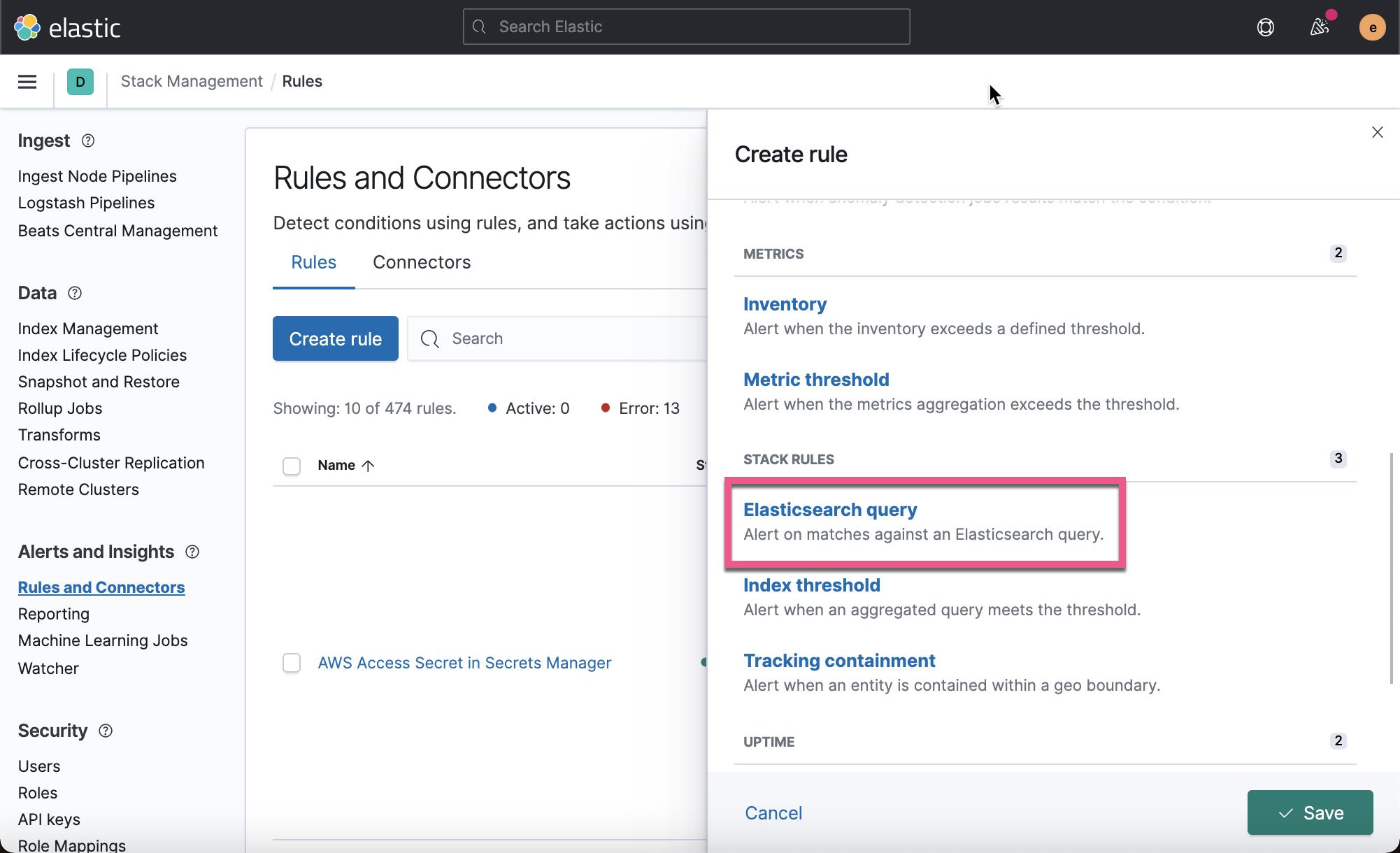
在上面我们选择 Elasticsearch query 来进行查询:
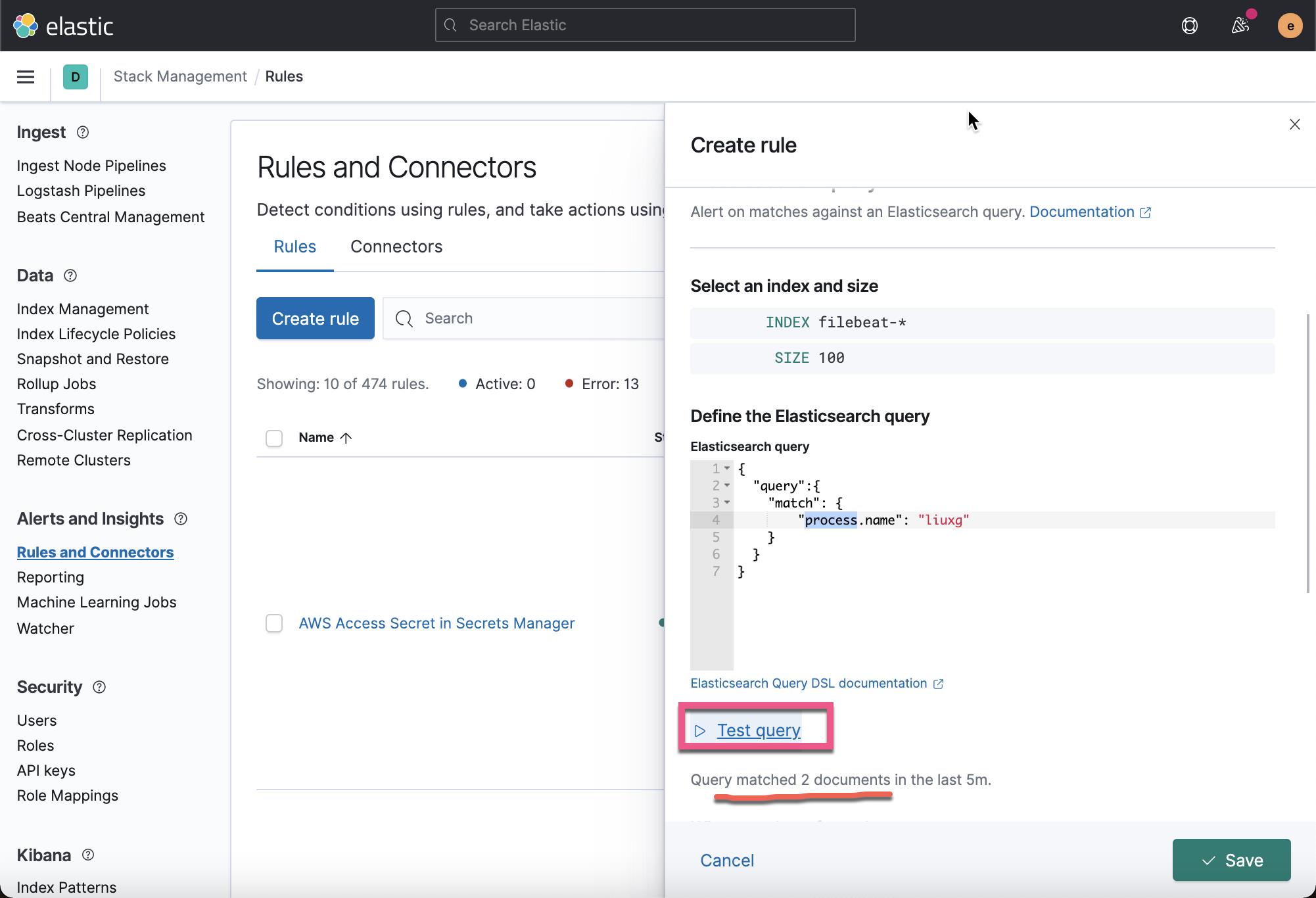
我们可以点击 Test query 链接来测试我们的查询。由于上面使用了 DSL 查询,所以我们可以使用任何复制的查询。在上面,我们是来很简单的一个 DSL 查询:
{
"query":{
"match": {
"process.name": "liuxg"
}
}
}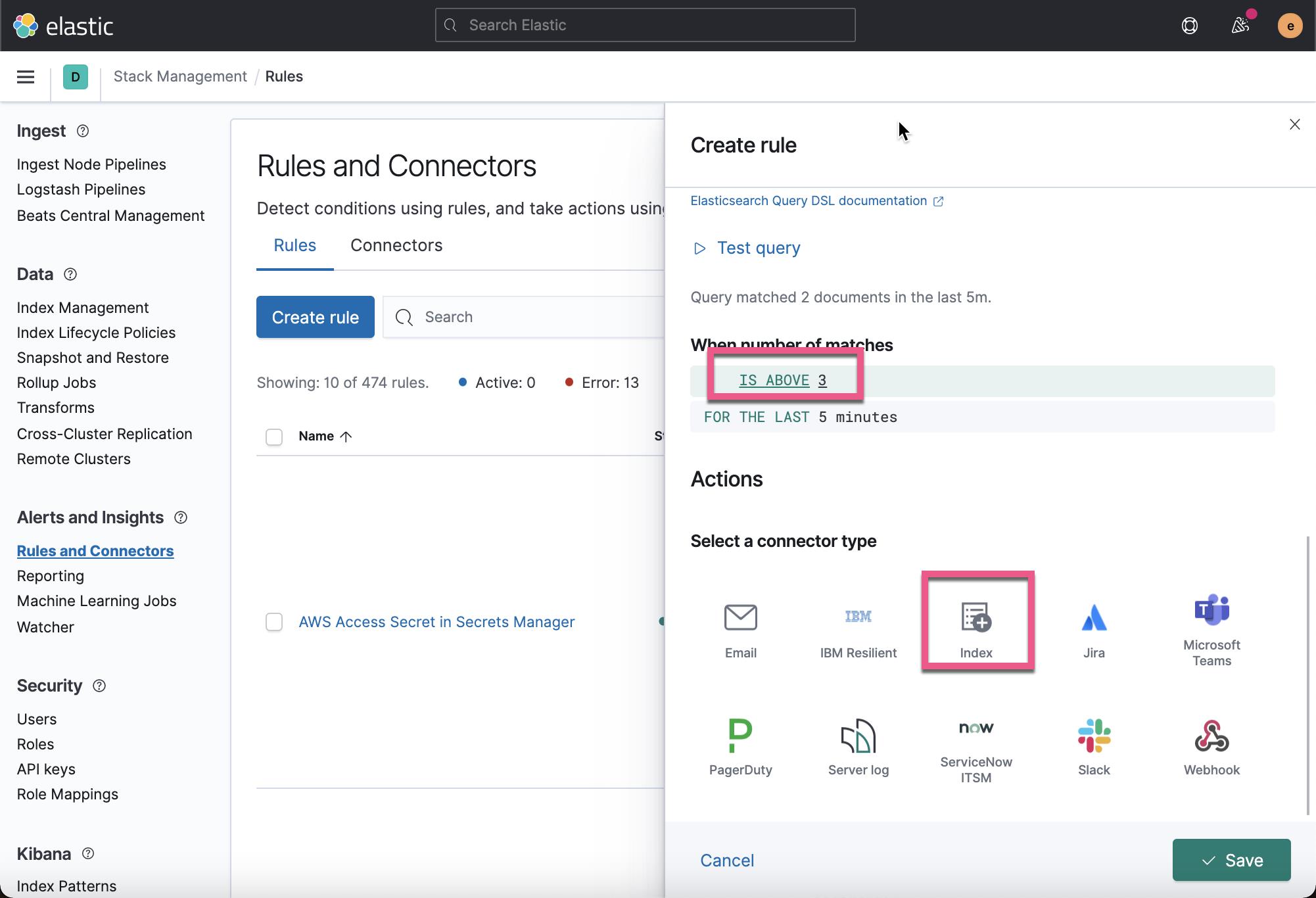
在上面,在5分钟之内,我们选择 match 的数量是超过3个就满足条件。当添加满足时,我们选择 Index 连接器:
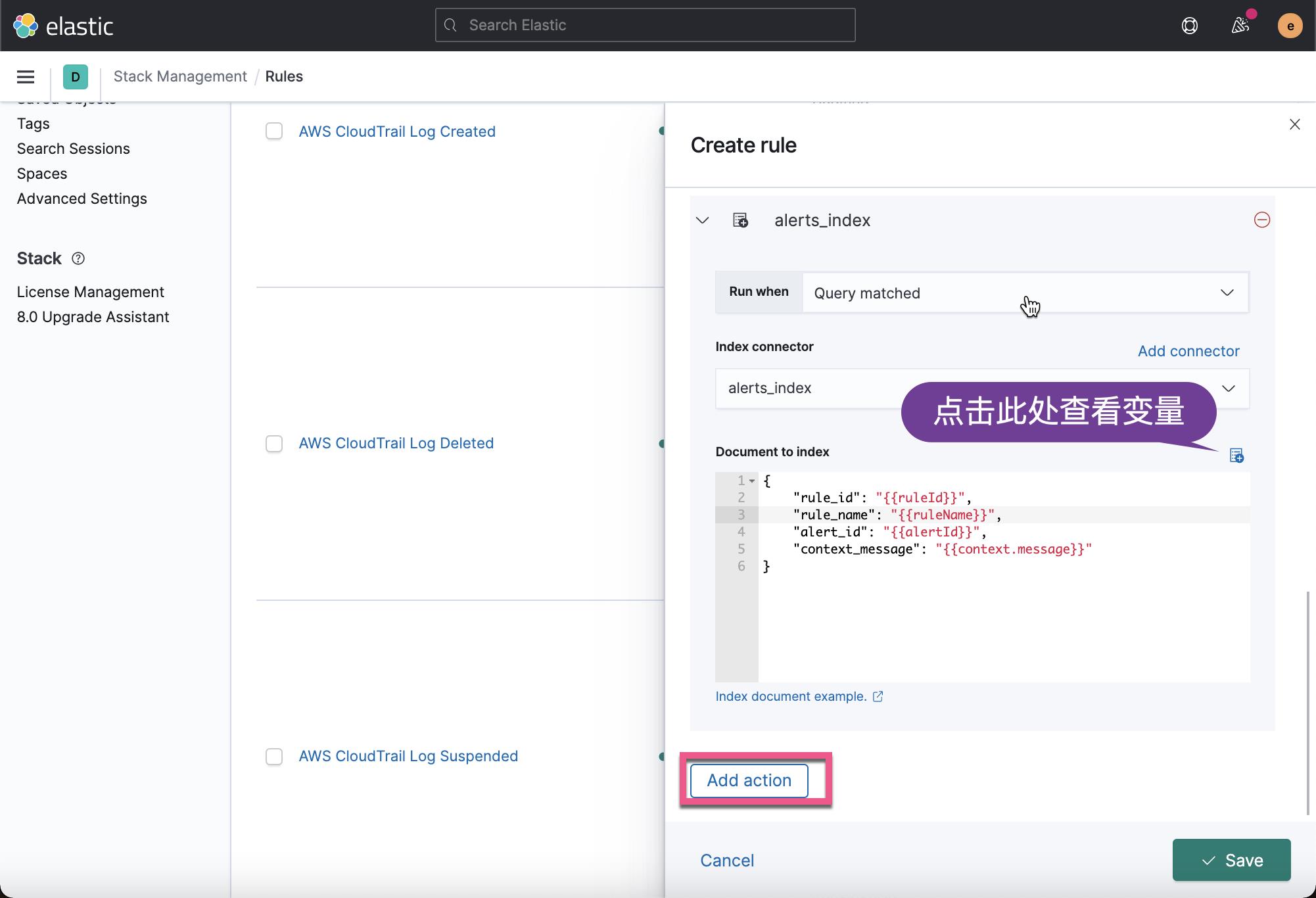
在上面的创建过程中,我们需要创建自己的 Index 连接器,如果你之前还没有创建的话。
我们接着点击上面 Save 按钮:
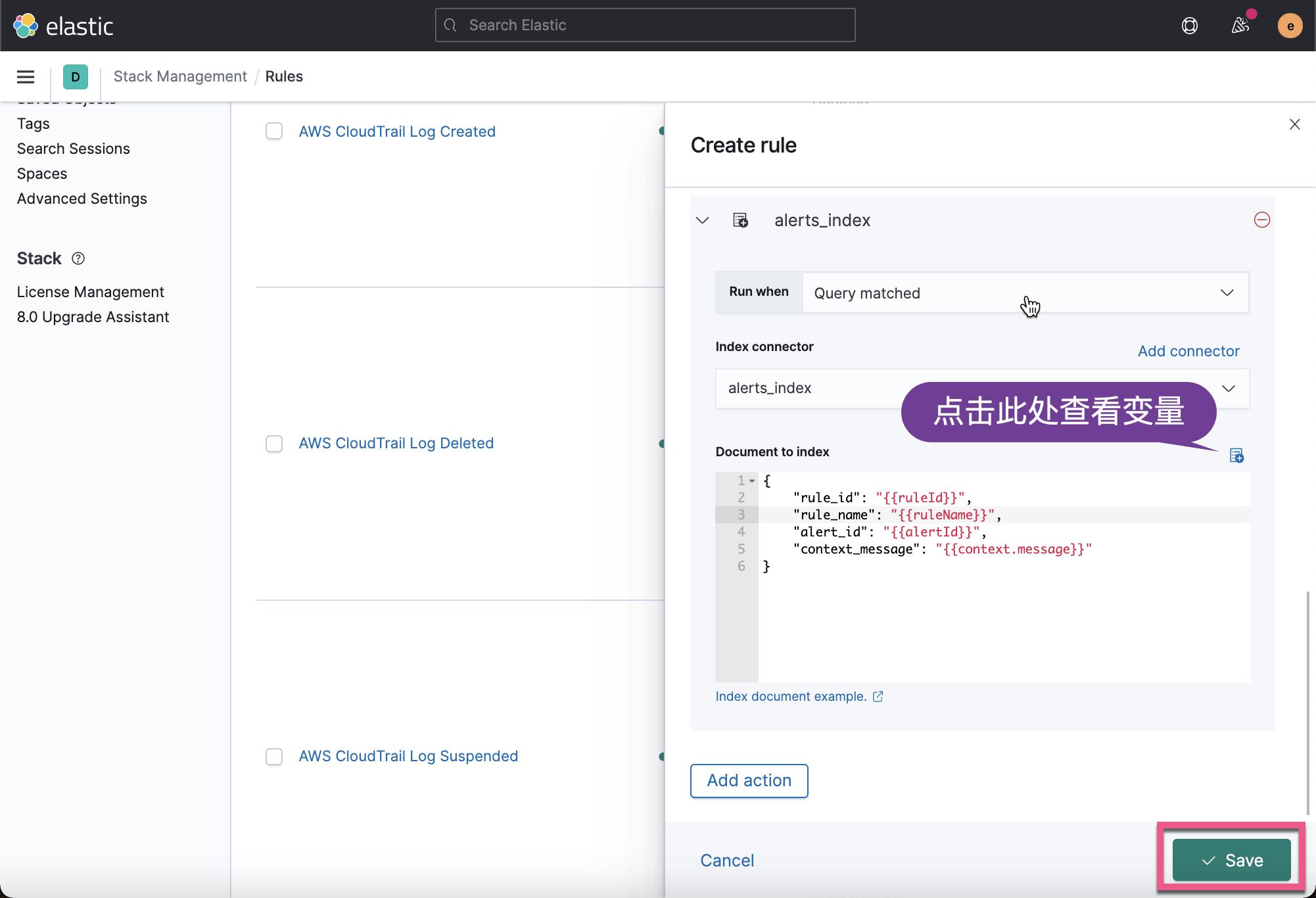
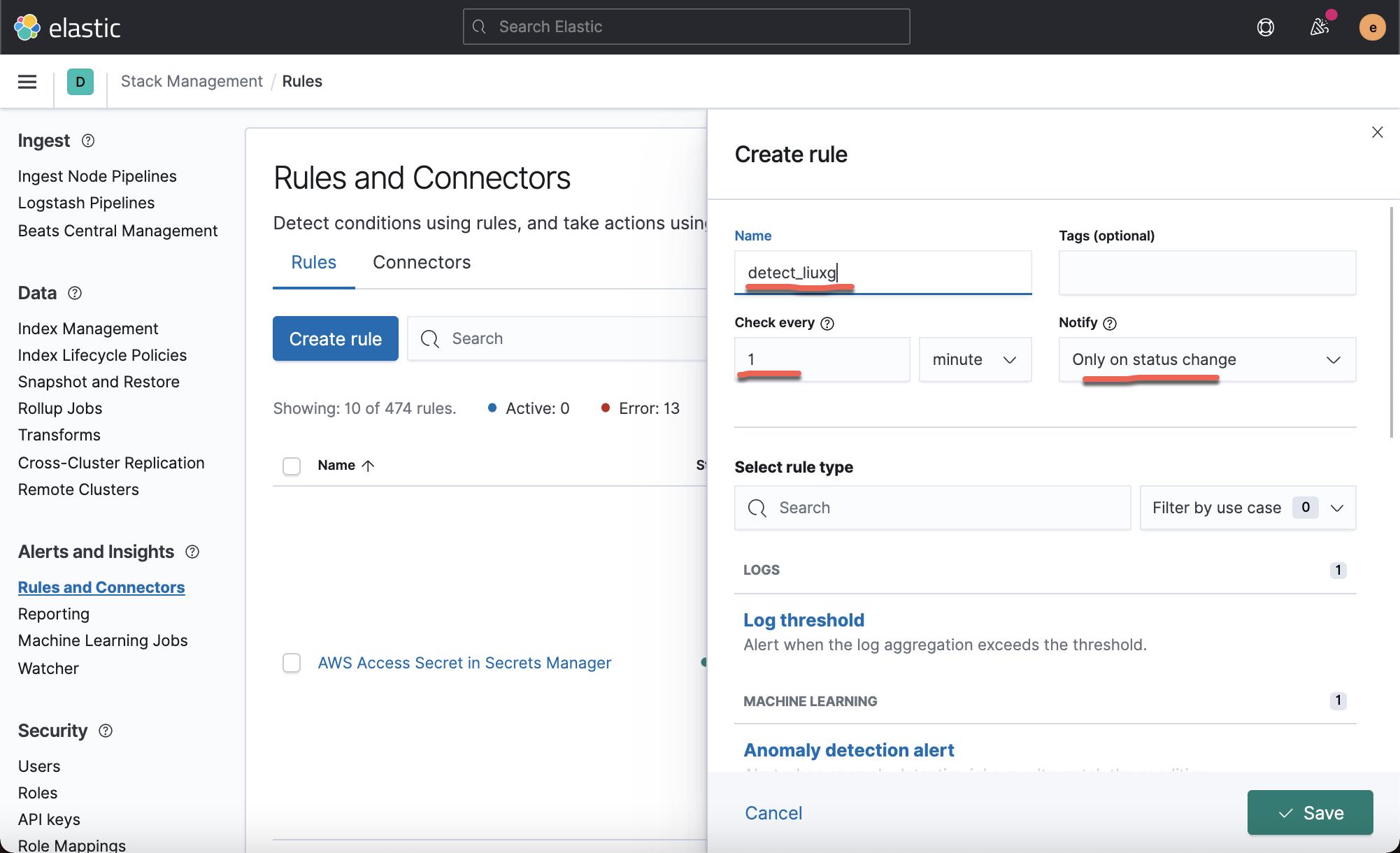
这样就创建了我们的叫做 detect_liuxg 的警报:
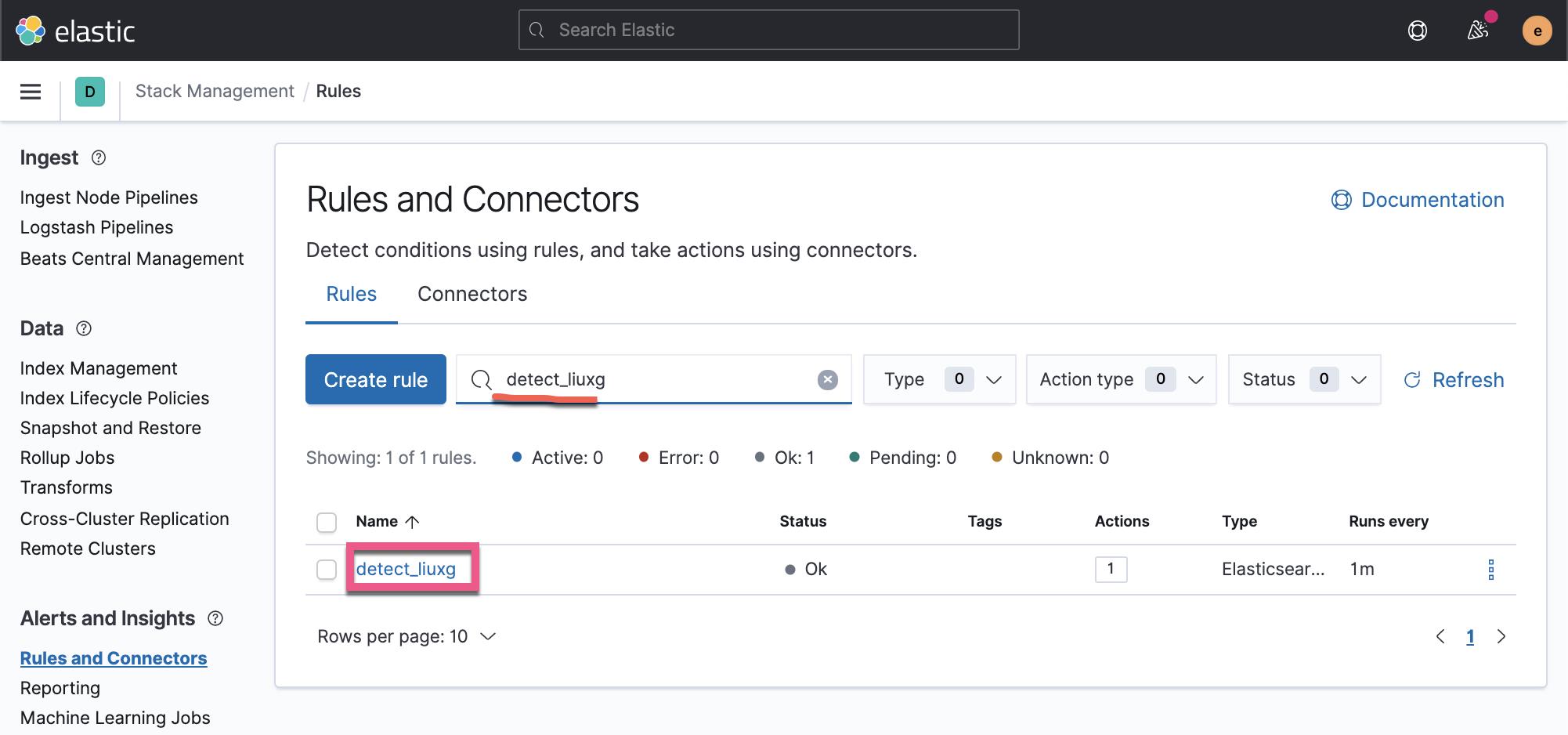
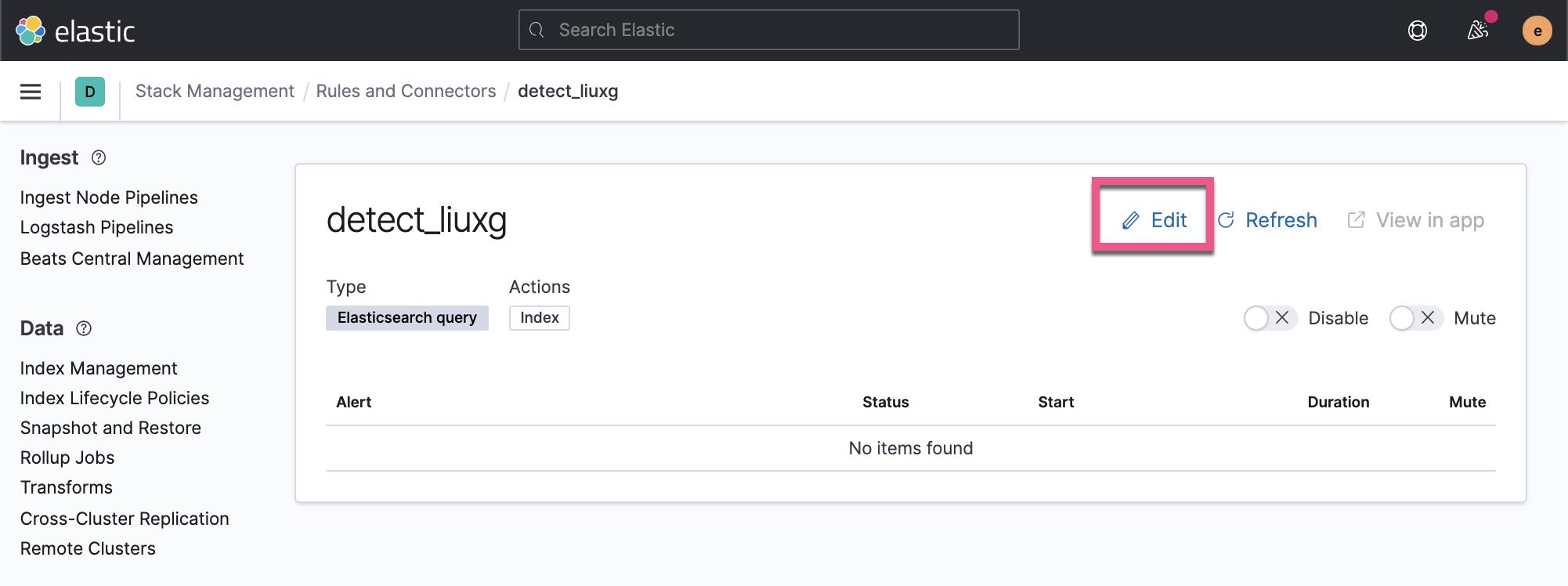
你可以点击上面的 Edit 链接对它进行修改或者编辑。
我们接下来在 Filebeat 运行的机器的 terminal 中打入如下的命令4次:
root@liuxgu:/etc/filebeat# logger -t liuxg this is message
root@liuxgu:/etc/filebeat# logger -t liuxg this is message
root@liuxgu:/etc/filebeat# logger -t liuxg this is message
root@liuxgu:/etc/filebeat# logger -t liuxg this is message我们等1分钟的时间来查看 Kibana 的界面:
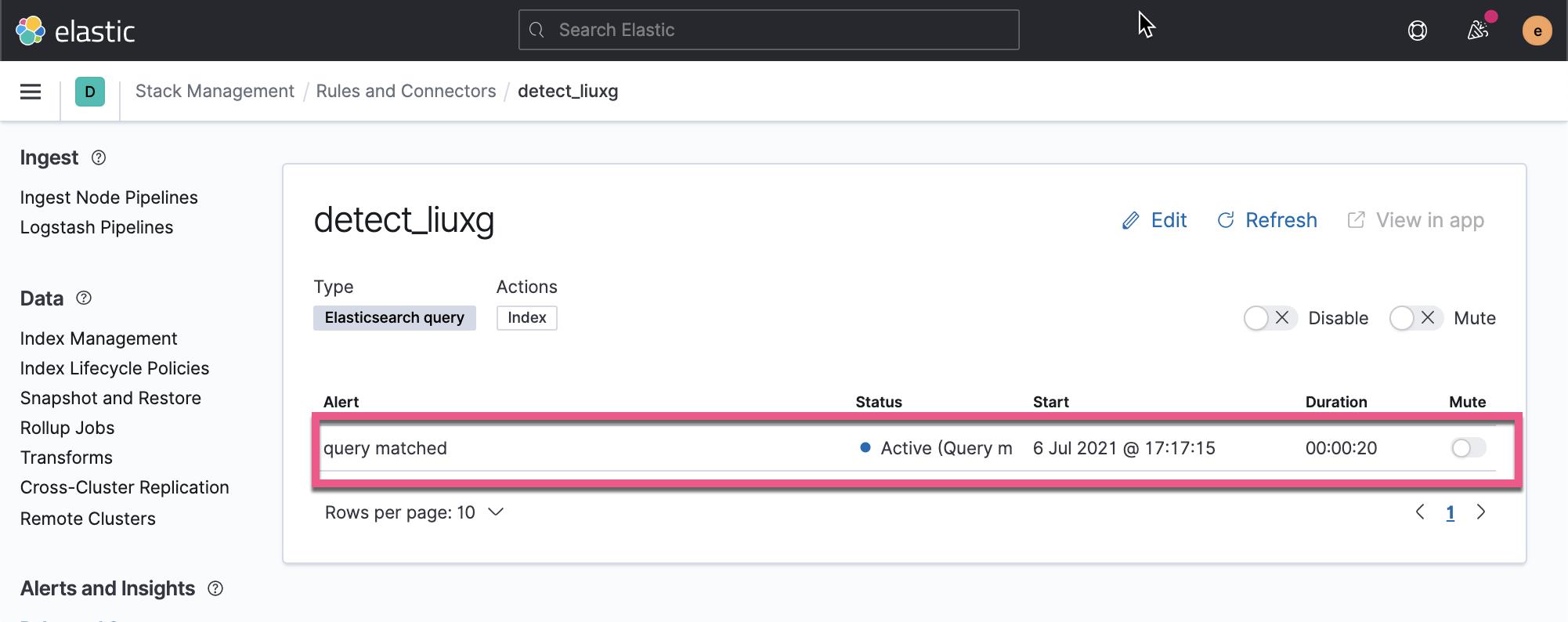
上面显示有一个警报已经发生了。我们再回到 Dev Tools 中去查看:
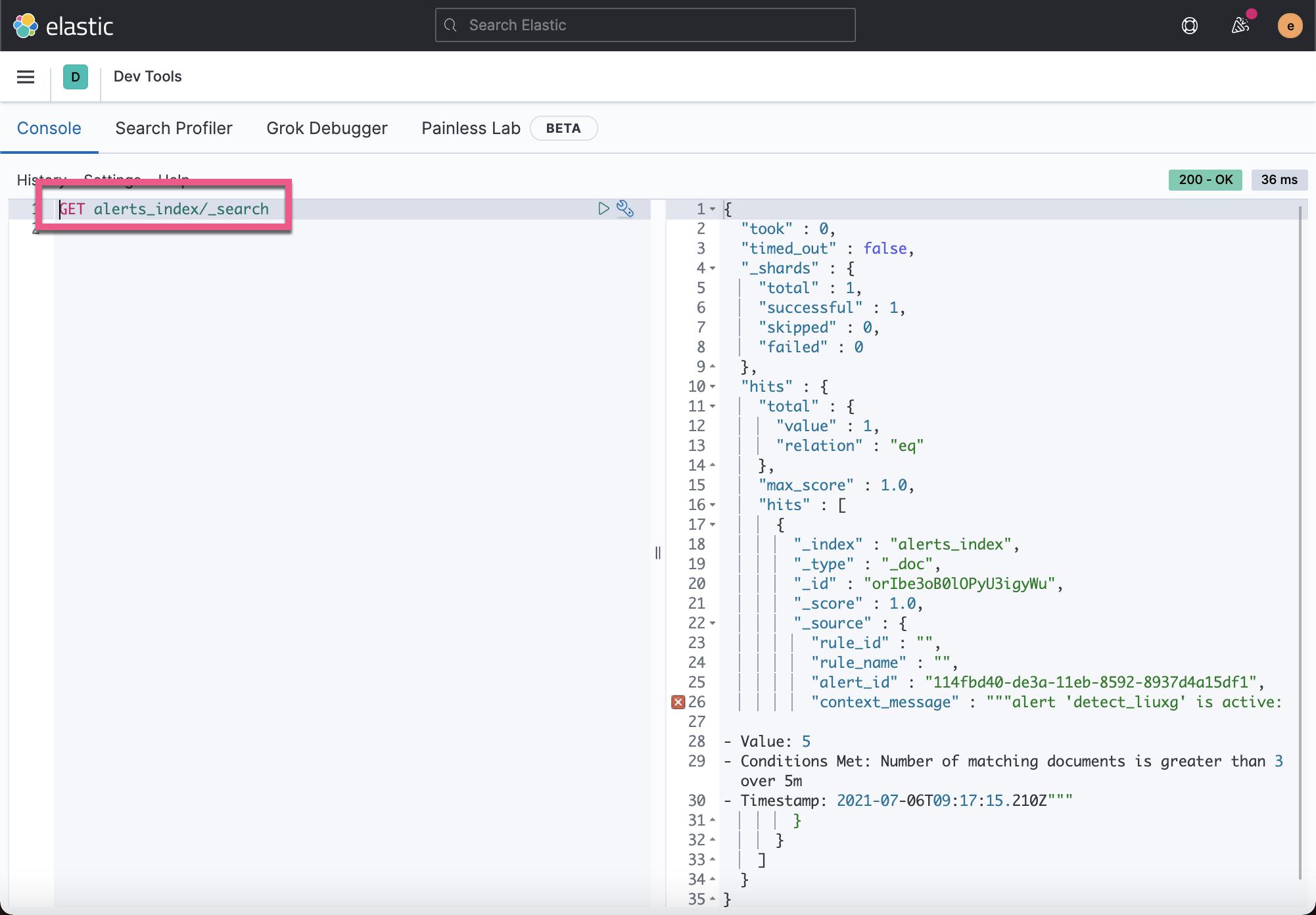
我们看到已经有一个警报写入到我们定义的索引 alerts_index 中了。它说明我们的警报已经起作用了。
以上是关于Kibana:Alerting - 警报介绍的主要内容,如果未能解决你的问题,请参考以下文章
Spring 批处理作业状态配置为使用 prometheus 发出警报
helm values.yaml 中的 alerting_rules.yml
Elasticsearch全文检索技术 一篇文章即可从入门到精通(Elasticsearch安装,安装kibana,安装ik分词器,数据的增删改查,全文检索查询,聚合aggregations)(代码片