全球最大AI巨量模型,参数2457亿炼丹16天专注中文,打造者绝对让你意外
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全球最大AI巨量模型,参数2457亿炼丹16天专注中文,打造者绝对让你意外相关的知识,希望对你有一定的参考价值。
晓查 梦晨 发自 凹非寺
量子位 报道 | 公众号 QbitAI
一个比GPT-3还大的AI模型,如果把近5年中文互联网能爬取到的内容看了个遍,会怎么样?
能学会日语。

我们把日语词汇“气持”的中文含义告诉它,它能熟练运用“气持”造句。
也许你没见过“气持”这个词,但你大概听过它的发音“kimochi”(手动狗头)
新词 | 输入-语义 | 生成文本 |
气持 | “气持”是心情、精神状态的意思。例:“那种消极的气持又控制了他”。用“气持”写一句话: | 他的气持,使我无法接近 |
悬命 | “悬命”是拼命,竭尽全力,做出最大努力的意思。他凡事必悬命,绝不打马虎眼。用“悬命”造句: | 他这个人做事太悬命了,为了取得第一手材料,连饭也顾不上吃 |
开发它的工程师还告诉我们,如果把“yyds”的意思是“永远的神,用于夸张地赞叹某人某事很厉害”输进去,也可以达到相同效果。
也就是说,如果网络上诞生什么新的词汇,这个AI学会它只需一句话。
而且这个AI看完全部内容只用了16天。
它就是全球最大规模AI巨量模型“源1.0”,带着2457亿参数和最大高质量中文数据集来了,突如其来。

在过去4个月里,有一群浪潮工程师,他们把近5年互联网内容浓缩成2000亿词,让AI在16天内读完,终于炼成了“源1.0”。
除了“学习日语”,诸如知识问答:
问:大李杜是李白杜甫,小李杜是李商隐和谁?
源1.0答:杜牧
甚至和女朋友吵架(doge):
输入:我好心问你吃了饭没,你又骂我
源1.0回答:我又没骂你,你自己对号入座
这些现代社交基本技能,“源1.0”不在话下。
更厉害的是“源1.0”拥有的2000亿词是“人类高质量中文数据集”,这是什么概念呢?
假如一个“读书狂魔”一个月能读10本20万字小说,那么他需要读1万年才能看完整个语料库,而且还是剔除99%数据后的高质量文本。
去年GPT-3横空出世效果惊人,除了1750亿的参数规模,还有就是570GB的英文语料库。
而“源1.0”的参数量比GPT-3多出40%,语料库总体积达到5000GB,是GPT-3的近10倍。
源1.0中文语言模型 | GPT-3英文语言模型 | |
参数量 | 2457亿 | 1750亿 |
数据量 | 5000GB | 570GB |
计算量 | 4095PD | 3640PD |
业内人士指出,5TB这样的数据体量在中文互联网资源上,应该已经做到了极致。
有了“人类高质量中文数据集”,“源1.0”通过图灵测试证明了自己能搞定中文,而且整体效果比GPT-3处理英文更佳。
“源1.0”生成的文本,只有不到半数能被人正确识别为AI生成,仅诗歌“骗过”人类的概率较低。
毕竟是处理古文,对于主要学习网络中文资源的AI来说,是有点超纲了。

这样一个AI,训练起来一定花费了很多算力吧?
的确,源1.0在浪潮计算集群上“火力全开”训练了16天,能在CLUE上成功“霸榜”也就毫无意外了。
在零样本学习榜单中,“源1.0”超越业界最佳成绩18.3%,在文献分类、新闻分类,商品分类、原生中文推理、成语阅读理解填空、名词代词关系6项任务中获得冠军。

(注:第一名是人类)
在小样本学习的文献分类、商品分类、文献摘要识别、名词代词关系等4项任务获得冠军。在成语阅读理解填空项目中,源1.0的表现已超越人类得分。

但是要让大模型效果好,不是光靠堆算力和数据就能堆出来的,还需要解决巨量模型训练不稳定等诸多技术难题。
至于背后更多技术细节,浪潮透露,他们近期会将研究论文发布在arxiv上。
作为一家提供服务器、数据存储相关业务的公司,浪潮为何也开始加入“炼大模型”队伍了?这让人感到意外,也许真的是时候转变老观念了。
“源1.0”诞生靠什么?
在不少人的观念里,超大规模NLP模型的前沿基本由互联网软件公司把持。
但实际上,很多超大模型已经是“三位一体”——算力、数据、算法都来自一家——的研究方式了。
OpenAI的研究已表明,算力、数据量、参数量的增加都会降低模型训练的损失。
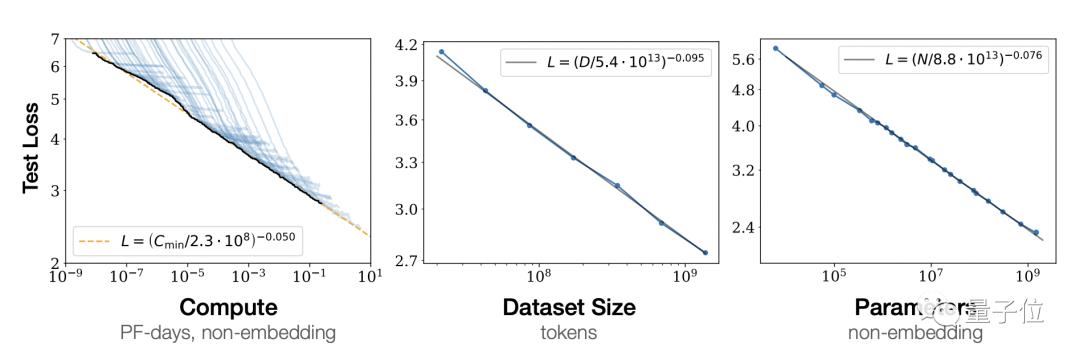
而且三者之中的任何一个因素都是独立的,优化模型性能需要三者协力。
浪潮的硬件底子有能力把算力、数据都推到了极致。
连续16天训练
“源1.0”整个训练过程中,消耗算力约4095PFLOPS-day,这是什么概念呢?比去年GPT-3还多12.5%。
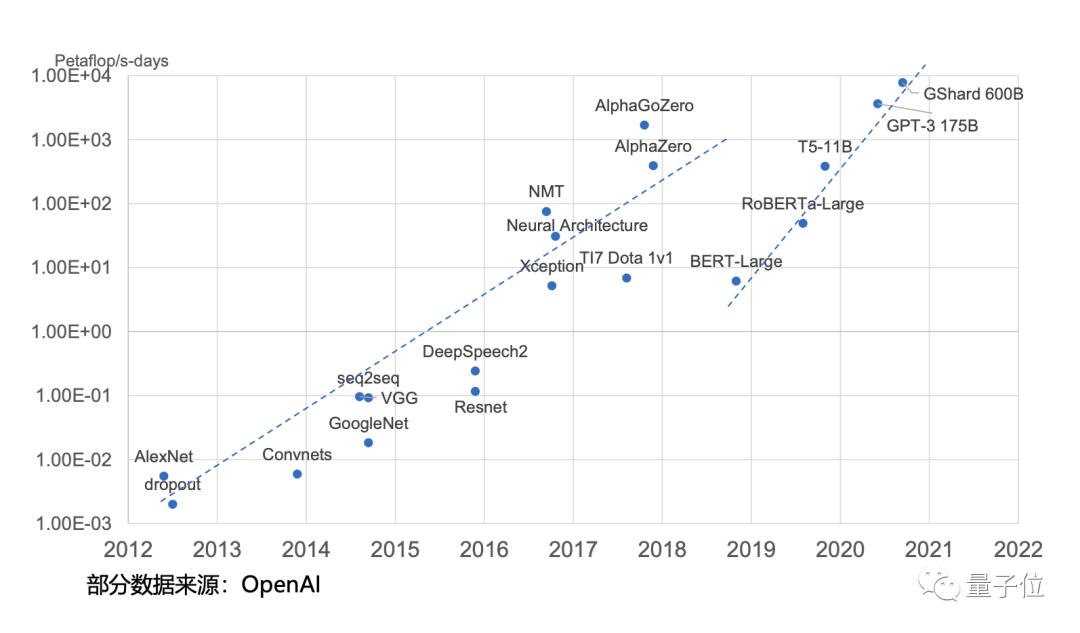
但训练模型不是简单的插入GPU板卡,在大规模并行计算中的硬件优化更考验能力。
凭借多年大型服务器上的经验,多年前,浪潮就推出了深度学习并行计算框架Caffe-MPI,后来又推出了TensorFlow-Opt。
这些框架针对大型服务器进行优化,在多GPU场景下性能损失很少。

人类高质量数据集
仅仅有强大算力是远远不够的,当今的AI技术重度依赖于数据。
做中文自然语言模型,面临的第一道障碍就是语料库。
当今全球互联网仍然以英文资源为主。以维基百科为例,英文维基共有638万词条,而中文仅123万,还不到前者的1/6。
再加上互联网上充斥着大量低质量文本,比如广告、最近流行的废话梗,要是都让AI学了去恐怕会学成“智障”。
浪潮此次抓取了2017至2021年所有中文网页内容、新闻、百科以及电子书。
为了剔除绝大多数的低质量文本,浪潮开发高性能分布式数据清洗软件,耗时近一个月,终于得到5TB的全球最大高质量中文数据集。
最大单一模型
另外,“源1.0”还创下另一项之最:全球最大单体AI模型。如何理解?
浪潮信息副总裁、AI&HPC产品线总经理刘军表示:
具体来讲就是说单体特别大叫巨量模型,现在最典型巨量模型是GPT-3,有1750亿参数,浪潮“源1.0”是2457亿,不管在中国还是在全球都是最大规模的。
与单体模型对应的是混合模型。
混合模型是专家模型的一个混合、集合。它是由多个小模型混合起来的,中间通过开关机制来工作,每一个小模型大约在100亿参数左右。
如果要做比喻的话单体模型就是珠穆朗玛峰,而混合模型就是一群小山。
研究单体模型如同去攀珠穆朗玛峰,这种巨量模型的在科学和产业中价值是非常大的。
“会当凌绝顶,一览众山小。”

单体模型能见所未见,从训练中产生更高层次的知识。这也是“源1.0”为何无需微调就能在零样本和少样本任务中取得不俗成绩。因为单体模型的“思维”在训练中得到升级。
当然,训练单体模型付出的代价也更高。
为提升计算效率,浪潮通过优化大模型结构、节点内张量并行等算力协同优化的方式大大提升计算效率,取得了当前业界一流的计算性能。
浪潮的深度学习训练集群管理软件AIStation、集群并行计算深度学习框架Caffe-MPI、TensorFlow-Opt等在其中发挥了重要作用。
“源1.0”能做什么?
浪潮花费巨大精力将AI巨量模型炼出来,能做什么?
从CLUE榜单的成绩中可以看出,“源1.0”最擅长的是少样本学习和零样本学习,特别是在文本分类、阅读理解和推理方面的一系列的任务上都获得冠军。
不过真正落地应用时考验的还是AI模型的综合实力,就像一个人走出学校来到工作岗位,这时分科目的考试分数不再重要,最终看的是如何把学习到的知识用起来,去解决真正的问题。
以智能客服为例,这种与人类一对一交流的场景就对AI模型能力的要求极高。
从最基本的理解用户意图并给出正确答案,到多轮对话中保持上下文的连贯性,最后还要让AI能识别用户的情绪变化,在对话中满足用户在情感上的需求。
如果换成手机上的智能助手,还要求AI在长时间对话中保持身份的一致性,不能出现前后矛盾。
对话之外,还有商业和法律上的长文档的阅读理解、生成摘要,新闻和小说等文本生成辅助创作,都是巨量模型的用武之地。

被问及为何将模型命名为“源”时,刘军的解释是:
希望巨量模型成为整个产业AI化的创新源头。
浪潮为何要做“源1.0”?
一家传统观念中的服务器和IT服务厂商,为何突然做出超大语言模型?
浪潮此举似乎令人意外。
但是梳理浪潮近年来的发展轨迹,可以说是“蓄谋已久”了。
在基础算力方面,浪潮在全国各地建立智算中心,作为AI基础设施。
在基础软件方面平台方面,浪潮有AIStation开发训练平台,还先后推出深度学习并行计算框架Caffe-MPI、TensorFlow-Opt、全球首个FPGA高效AI计算开源框架TF2等等。
同时,浪潮还提供大数据服务云海Insight。
算力、软件平台、大数据能力聚齐,不足的就只剩算法。
浪潮其实早已加码AI算法的研究,多年前低调成立了人工智能研究院,终于补上了最后一块拼图。
最终,人工智能研究院的研发团队,历时4个月打造出2457亿参数中文模型“源1.0”。
“源1.0”的发布,意味着 “算力、数据、算法”三位一体的时代已经到来,我们不能再将AI公司看成三要素中的一环,浪潮已经成为一家“全栈式”AI企业。
从去年GPT-3出现以来,人们已经看到NLP将大规模落地的前景。
但问题在于,中国有能力开发出中文AI巨量模型的公司屈指可数,大大限制NLP的应用。
去年OpenAI发布的GPT-3现在也只是少量开放API,处于供不应求状态。超大NLP模型效果惊人,却难“接地气”。
OpenAI的解决方法是:将AI开放给有能力的开发者,由他们二次开发,再提供给用户。
例如GitHub用GPT-3开发出自动编程工具Copilot,再将插件提供给其他公司,用于提升程序员效率。
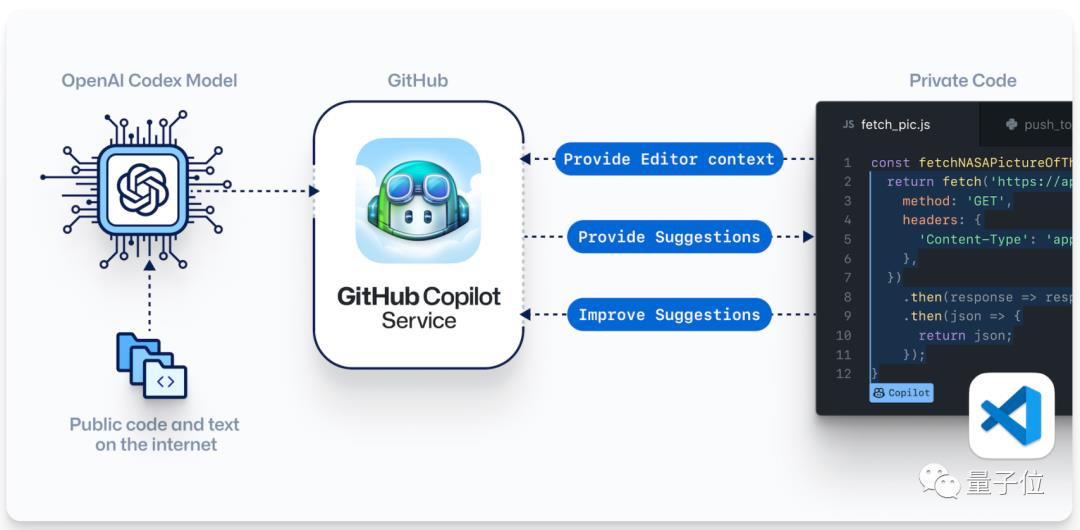
△ 利用GPT-3自动补全代码
不同于GPT-3商用思路,源1.0未来将定向免费开放API。2019年,浪潮推出了“元脑生态计划”,生态中的参与者有两类,一类是擅长做技术的“左手伙伴”,另一类是具有业务落地能力的“右手伙伴”。
发布“源1.0”巨量模型后,浪潮的下一步是向元脑生态社区内所有开发者开放API。
左手伙伴进行二次开发,右手伙伴再利用二次开发技术应用于产业。
有了“源1.0”的开放API,左手伙伴开发出单打独斗时靠小模型难以实现的功能,再交由右手伙伴落地实施。
且随着NLP推理需要的运算资源越来越大,“源1.0”与浪潮智算中心的云端算力结合,才能开发出更多类似于Copilot等以前无法部署的AI应用。
10年前,没人会料到AI算力和模型的发展速度如此之快。
2012年AlexNet刷新ImageNet模型,打开了计算机视觉落地的时代,如今任何一台手机都可以轻松运行各类图像识别、后处理AI任务。
去年GPT-3的出现,开启了NLP超大模型落地时代。至于它什么时候能用在手机上,刘军说:“乐观估计在5年以内。”
在过去两年,我们已经零星看到了小型NLP模型在手机上的应用。例如谷歌在手机上实现离线的语音识别,即使没有手机没有信号、没有WiFi。
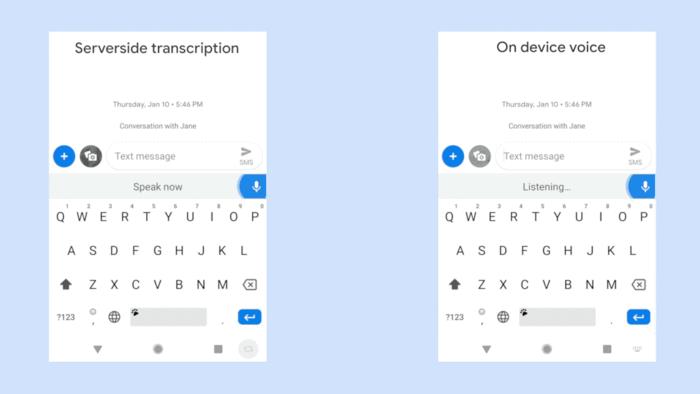
现在,手机AI离线翻译开始逐步上线,但由于手机算力以及模型体积原因,离线翻译的效果还远远比不上在线翻译。
但NLP应用遭遇到算力瓶颈,由于算力资源宝贵,基于GPT-3的代码补全工具Copilot现在只能处于小规模试用阶段。
AI写小说、与人对话、辅助编程现在就已经充满了想象空间,待算力资源、超大NLP模型普及,未来还有哪些应用现在真的难以想象。
斯坦福大学李飞飞教授等知名学者近期在一篇阐述预训练模型的机遇与风险的论文中表示,这类巨量模型的意义在于突现(Emergence)和均质(Homogenization)。

李飞飞所说的“突现”是指,当数据规模和参数规模大到一定程度时,量变最终能产生质变,完成更高难度的任务。
现在2457亿参数、5TB数据集训练出来的“源1.0”是通往质变路上的一次必然的尝试。
“均质”是指,AI有了小样本和零样本学习的泛化能力,不经过微调就能直接用于之前没见过的新任务,让语言AI具备举一反三的通识能力。
而且这种通识,让预训练模型不必在经过复杂的“微调”过程,一家训练完成,便可开放给各行各业使用,进一步降低AI应用门槛。
我们不知道未来AI巨量模型的质变会带来什么“杀手级应用”,但至少有一些科技公司正在朝着质变的道路上探索,“源1.0”就是这样一种尝试。
以上是关于全球最大AI巨量模型,参数2457亿炼丹16天专注中文,打造者绝对让你意外的主要内容,如果未能解决你的问题,请参考以下文章