Go 内存对齐的那些事儿
Posted qcrao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go 内存对齐的那些事儿相关的知识,希望对你有一定的参考价值。
在讨论内存对齐前我们先看一个思考题,我们都知道Go的结构体在内存中是由一块连续的内存表示的,那么下面的结构体占用的内存大小是多少呢?
type ST1 struct {
A byte
B int64
C byte
}在64位系统下 byte 类型就只占1字节,int64 占用的是8个字节,按照数据类型占的字节数推理,很快就能得出结论:这个结构体的内存大小是10个字节 (1 + 8 +1 )。这个推论到底对不对呢?我们让 Golang 自己揭晓一下答案。
package main
import (
"fmt"
"unsafe"
)
type ST1 struct {
A byte
B int64
C byte
}
func main() {
fmt.Println("ST1.A 占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST1{}.A)))
fmt.Println("ST1.A 对齐的字节数是:" + fmt.Sprint(unsafe.Alignof(ST1{}.A)))
fmt.Println("ST1.B 占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST1{}.B)))
fmt.Println("ST1.B 对齐的字节数是:" + fmt.Sprint(unsafe.Alignof(ST1{}.B)))
fmt.Println("ST1.C 占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST1{}.C)))
fmt.Println("ST1.C 对齐的字节数是:" + fmt.Sprint(unsafe.Alignof(ST1{}.C)))
fmt.Println("ST1结构体 占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST1{})))
fmt.Println("ST1结构体 对齐的字节数是:" + fmt.Sprint(unsafe.Alignof(ST1{})))
}
## 输出
ST1.A 占用的字节数是:1
ST1.A 对齐的字节数是:1
ST1.B 占用的字节数是:8
ST1.B 对齐的字节数是:8
ST1.C 占用的字节数是:1
ST1.C 对齐的字节数是:1
ST1结构体 占用的字节数是:24
ST1结构体 对齐的字节数是:8Golang 告诉我们 ST1 结构体占用的字节数是24。但是每个字段占用的字节数总共加起来确实是只有10个字节,这是怎么回事呢?
因为字段B占用的字节数是8,内存对齐的字节数也是8,A字段所在的8个字节里不足以存放字段B,所以只好留下7个字节的空洞,在下一个 8 字节存放字段B。又因为结构体ST1是8字节对齐的(可以理解为占的内存空间必须是8字节的倍数,且起始地址能够整除8),所以 C 字段占据了下一个8字节,但是又留下了7个字节的空洞。
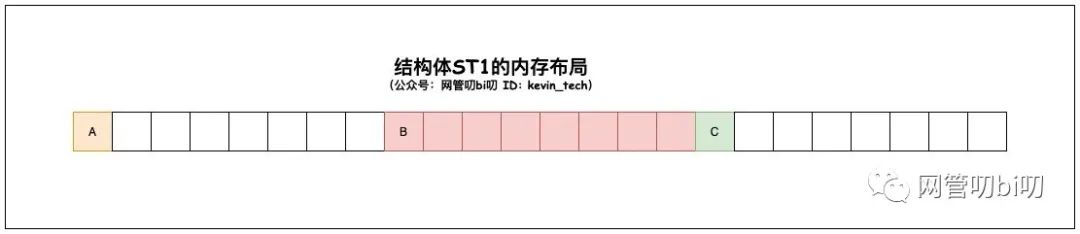
这样ST1结构体总共占用的字节数正好是 24 字节。
既然知道了 Go 编译器在对结构体进行内存对齐的时候会在字段之间留下内存空洞,那么我们把只需要 1 个字节对齐的字段 C 放在需要 8 个字节内存对齐的字段 B 前面就能让结构体 ST1 少占 8 个字节。下面我们把 ST1 的 C 字段放在 B 的前面再观察一下 ST1 结构体的大小。
package main
import (
"fmt"
"unsafe"
)
type ST1 struct {
A byte
C byte
B int64
}
func main() {
fmt.Println("ST1.A 占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST1{}.A)))
fmt.Println("ST1.A 对齐的字节数是:" + fmt.Sprint(unsafe.Alignof(ST1{}.A)))
fmt.Println("ST1.B 占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST1{}.B)))
fmt.Println("ST1.B 对齐的字节数是:" + fmt.Sprint(unsafe.Alignof(ST1{}.B)))
fmt.Println("ST1.C 占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST1{}.C)))
fmt.Println("ST1.C 对齐的字节数是:" + fmt.Sprint(unsafe.Alignof(ST1{}.C)))
fmt.Println("ST1结构体 占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST1{})))
fmt.Println("ST1结构体 对齐的字节数是:" + fmt.Sprint(unsafe.Alignof(ST1{})))
}
## 输出
ST1.A 占用的字节数是:1
ST1.A 对齐的字节数是:1
ST1.B 占用的字节数是:8
ST1.B 对齐的字节数是:8
ST1.C 占用的字节数是:1
ST1.C 对齐的字节数是:1
ST1结构体 占用的字节数是:16
ST1结构体 对齐的字节数是:8重排字段后,ST1 结构体的内存布局变成了下图这样
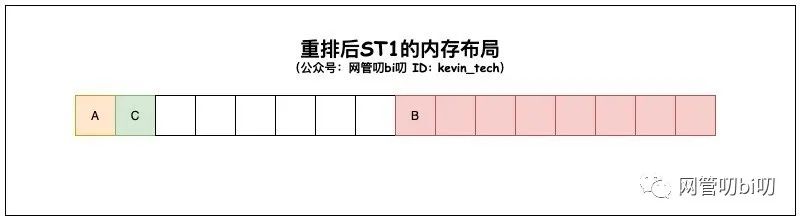
仅仅只是调换了一下顺序,结构体 ST1 就减少了三分之一的内存占用空间。在实际编程应用时大部分时候我们不用太过于注意内存对齐对数据结构空间的影响,不过作为工程师了解内存对齐这个知识还是很重要的,它实际上是一种典型的以空间换时间的策略。
内存对齐
操作系统在读取数据的时候并非按照我们想象的那样一个字节一个字节的去读取,而是一个字一个字的去读取。
字是用于表示其自然的数据单位,也叫
machine word。字是系统用来一次性处理事务的一个固定长度。字长 / 步长 就是一个字可容纳的字节数,一般 N 位系统的字长是 (N / 8) 个字节。
因此,当 CPU 从存储器读数据到寄存器,或者从寄存器写数据到存储器,每次 IO 的数据长度是字长。如 32 位系统访问粒度是 4 字节(bytes),64 位系统的就是 8 字节。当被访问的数据长度为 n 字节且该数据的内存地址为 n 字节对齐,那么操作系统就可以高效地一次定位到数据,无需多次读取、处理对齐运算等额外操作。
内存对齐的原则是:将数据尽量的存储在一个字长内,避免跨字长的存储。
Go 官方文档中对数据类型的内存对齐也有如下保证:
对于任何类型的变量 x,unsafe.Alignof(x) 的结果最小为1 (类型最小是一字节对齐的)。
对于一个结构体类型的变量 x,unsafe.Alignof(x) 的结果为 x 的所有字段的对齐字节数中的最大值。
对于一个数组类型的变量 x , unsafe.Alignof(x) 的结果和此数组的元素类型的一个变量的对齐字节数相等,也就是 unsafe.Alignof(x) == unsafe.Alignof(x[i])。
下面这个表格列出了每种数据类型对齐的字节数
| 数据类型 | 对齐字节数 |
|---|---|
| bool, byte, unit8 int8 | 1 |
| uint16, int16 | 2 |
| uint32, int32, float32, complex64 | 4 |
| uint64, int64, float64, complex64 | 8 |
| array | 由其元素类型决定 |
| struct | 由其字段类型决定, 最小为1 |
| 其他类型 | 8 |
零字节类型的对齐
我们都知道 struct{} 类型占用的字节数是 0,但其实它的内存对齐数是 1,这么设定的原因为了保证当它作为结构体的末尾字段时,不会访问到其他数据结构的地址。比如像下面这个结构体 ST2
type ST2 struct {
A uint32
B uint64
C struct{}
}虽然字段 C 占用的字节数为0,但是编译器会为它补 8 个字节,这样就能保证访问字段 C 的时候不会访问到其他数据结构的内存地址。
type ST2 struct {
A uint32
B uint64
C struct{}
}
func main() {
fmt.Println("ST2.C 占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST2{}.C)))
fmt.Println("ST2.C 对齐的字节数是:" + fmt.Sprint(unsafe.Alignof(ST2{}.C)))
fmt.Println("ST2 结构体占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST2{})))
}
## 输出
ST2.C 占用的字节数是:0
ST2.C 对齐的字节数是:1
ST2 结构体占用的字节数是:24当然因为 C 前一个字段 B 占据了整个字长,如果把 A 和 B 的顺序调换一下,因为 A 只占 4 个字节,C 的对齐字节数是 1, 足够排在这个字剩余的字节里。这样一来 ST2 结构体的占用空间就能减少到 16 个字节。
type ST2 struct {
B uint64
A uint32
C struct{}
}
func main() {
fmt.Println("ST2.C 占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST2{}.C)))
fmt.Println("ST2.C 对齐的字节数是:" + fmt.Sprint(unsafe.Alignof(ST2{}.C)))
fmt.Println("ST2 结构体占用的字节数是:" + fmt.Sprint(unsafe.Sizeof(ST2{})))
}
## 输出
ST2.C 占用的字节数是:0
ST2.C 对齐的字节数是:1
ST2 结构体占用的字节数是:16总结
内存对齐在我理解就是为了计算机访问数据的效率,对于像结构体、数组等这样的占用连续内存空间的复合数据结构来说:
数据结构占用的字节数是对齐字节数的整数倍。
数据结构的边界地址能够整除整个数据结构的对齐字节数。
这样 CPU 既减少了对内存的读取次数,也不需要再对读取到的数据进行筛选和拼接,是一种典型的以空间换时间的方法。
希望通过这篇文章能让你更了解 Go 语言也更了解内存对齐这个计算机操作系统减少内存访问频率的机制。
以上是关于Go 内存对齐的那些事儿的主要内容,如果未能解决你的问题,请参考以下文章