中国最懂自动驾驶量产公司秀肌肉:自动驾驶算力怪兽百亿参数云端超大模型百万公里路测里程...
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中国最懂自动驾驶量产公司秀肌肉:自动驾驶算力怪兽百亿参数云端超大模型百万公里路测里程...相关的知识,希望对你有一定的参考价值。
贾浩楠 发自 凹非寺
量子位 报道 | 公众号 QbitAI
这可能是中国进展最迅猛的自动驾驶公司。
刚刚结束的毫末智行Q3品牌日,这家被业内人视作“中国最懂量产自动驾驶”的公司晒出最新成绩单:
增收快,成立不到2年的毫末智行,今年已经实现亿级别营收。
这本身已不可思议。

产品落地方面,今年2季度一口气亮出10款量产产品,硬件软件都有落地,最新产品是和阿里达摩院合作的无人末端配送车“小蛮驴”。
更超出行业经验认知的,是技术迭代迅速。
从今年1月开始,已累计超过100万公里智能驾驶数据,而且不是仿真,是在中国真实道路上的实际里程。
如此惊人的进度,毫末智行到底有什么杀手锏?
毫末高管悉数亮相,罕见分享技术细节,看家法宝“和盘托出”。
100万公里数据到手,问题却没那么简单
先来解答一下,毫末智行的100万公里从哪来。
毫末智行孵化于长城汽车集团,诞生于这个传统汽车巨头的自我忧患中,也肩负着长城智能化转型的核心重任。
今年上市的魏品牌摩卡车型,就是毫末智能驾驶系统的首秀。

100万公里,从今年1月测试开始算起,也包括上市后普通用户贡献的数据,都从这款车上来。
但100万公里数据到手,毫末发现问题却没那么简单。
品牌日现场,出身百度无人车的团队的CEO顾维灏先从问题入手,揭秘毫末成绩单背后的努力和探索。
首先是海量的数据中,对辅助驾驶系统能力提升的关键数据,并不多。
比如,一段城市快速路上的视频图像中,可能有超过60%是没有突发情况发生的平直路段。
这样的数据再多,也不会对系统能力提升有决定性作用。
反倒是出现频率低、目标小的图像数据,才是补上系统短板的关键。
如何挑出这些有价值的数据,是第一个挑战

而在有价值图像中,模型能力的不足,也会导致关键小目标的漏检,降低数据利用率。
另外在模型能力上,也会存在“数据偏见问题”,比如能识别白色乘用车,却识别不了被植物遮挡的白色乘用车。
这两个问题,是在数据收集前期阶段出现的。
拿到处理好的有价值的数据之后,系统还要攻克其他挑战。
其一,是如何快速迭代,更通俗的说,调参之后如何加快新模型训练速度。
其二,是源源不断的数据涌进来,使得模型版本快速迭代,如何在短时间验证这些不同模型,挑战也不小。
自动驾驶公司没数据发愁,像毫末这样从不缺数据和场景的,却面临另一层面的难题。
刚刚在毫末智行第三个品牌日上,CEO顾维灏首次详细揭露的毫末应对之法。
数据、训练双管齐下,“最懂”自动驾驶量产公司如是说
开发过程中的问题找到了,如何解决这些问题就成了毫末智行品牌日的核心重点。
从应对这些挑战的技术方案,也能体会一番为何毫末这家公司,是最懂自动驾驶量产落地的。
“大带小”的数据诊断方法
先说找到有价值的场景数据,毫末把这个过程叫做诊断。

目前诊断的手段有两种。
第一种方法是通过明确的系统失效信号得到诊断结果,例如通过人工接管信号。
也就是说由用户在使用过程中发现系统能力的不足而接管,系统会抓取接管前后一段时间内的数据上传场景库分析学习。
第二种方法则是通过更强大的后方服务端模型去诊断车端模型的错误。

车端模型受制于算力、传输延迟、参数有限,初期能力自然不足有限,一般一个小模型负责一部分感知任务。
所以毫末在实测中发现了对于远距离小目标,之前的系统版本时常会出现漏检情况。
而部署在服务端的大模型叫做Fundamental Model,是一个基于Transformer的全任务感知大模型。
算力要求高,资源占用大,但能力却超强,能发现小模型漏检错检、或在恶劣天气下识别能力下降的错误。
 △上为车端模型漏检,下为大模型的纠正
△上为车端模型漏检,下为大模型的纠正
找出问题后,再把结果返回车端模型重新训练学习,这样就能最大程度捕捉有效数据。
“举一反三”解决数据偏见
找到有问题的场景之后,就需要针对这个场景补充足够的样本数据,也就是找到足量的和它同类型的其他相似数据。
以此进行样本调配,才能做出一个更好的AI模型
通过已经上市的长城魏摩卡车型,毫末已经积累了巨量的道路场景数据库。
面对海量场景,毫末的方法是首先以无监督学习方法将图像向量化,把图片数据转化为特征向量,然后通过谱聚类,将相似的图像聚类在一起。
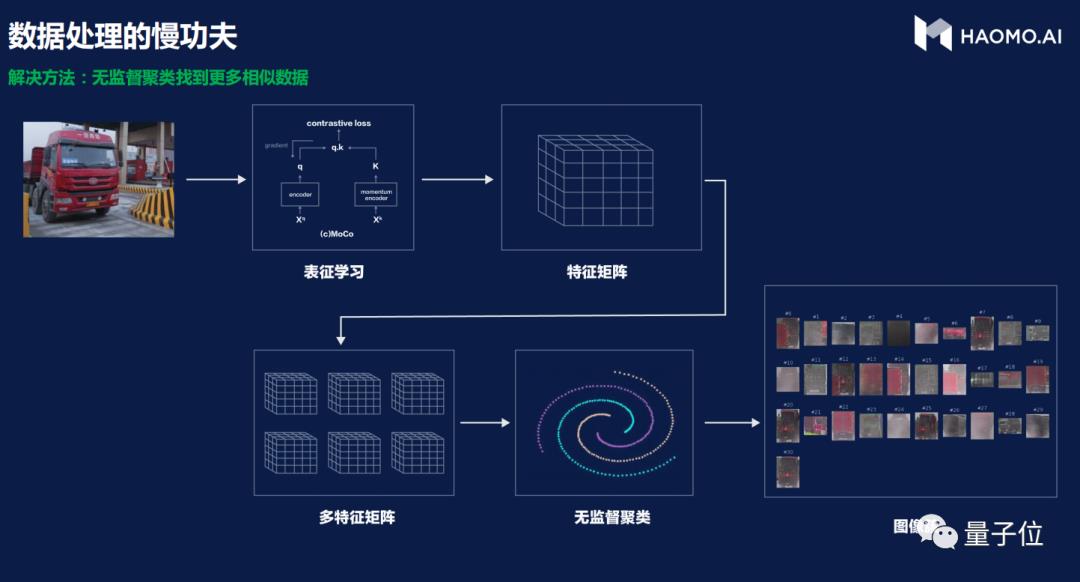
得到聚类结果以后,对于需要的目标场景,就能找到大量和其同一类别的相关数据作为正样本,以及相似易混的其他类别数据作为负样本。
并且在类别当中,只挑选类中心和类边界附近的数据,以此提升标注效率。

这种方式还可以非常有效的将异源数据以合适的方式混用起来,提升最终模型的效果。
数据诊断依靠“大带小”,而“数据偏见”则通过举一反三的方法解决。
并行训练,炼丹时间缩短一半
现在,已经拿到了对于模型能力提升的关键数据,接下来就是“炼丹”了。
Transformer能力强,但是训练速度也慢。
Swin-Transformer网络即使在360GB RAM、4块V100 GPU的服务器上,标准数据并行DDP训练也需要超过100小时。

毫末的工程师如果稍微改一下网络结构、参数配置、或者是更换数据,迭代一次看到结果的周期是近百个小时。
但这些操作又是会频繁发生的,所以这样严重拖慢了技术迭代。
所以为了提升训练速度,除了常见的数据并行之外,还需要更精细的模型并行方法。
首先是数据并行,每块GPU上训练完整的网络,将数据切块以适应GPU。同时每层的梯度还会和其他GPU交互。这样可以进一步提高模型收敛速度,以更少的epoch达到同样的训练效果。
这种数据并行和模型并行的混合方式,叫做流水并行。
针对swin-transformer,就采用了流水并行的方案,整体可以提速50%-80%。
流水线生产测试场景
训练效率有了提升,新的问题随之而来:
模型迭代快、版本多,如何验证其有效性?
主流做法当然是把模型丢到仿真环境中测试,但是传统的仿真是一种非常低效的方式。
从场景设计,到设置道路模型、设置车辆模型、设置交通流模型、到最后进行仿真测试…每人每天只能做30个。

所以毫末开发了语义场景的自动化转化工具和参数泛化工具,可以将CSS中场景库的描述文本自动的转化为仿真测试场景,并且在合适的范围内离散采样得到巨量的仿真测试用例。
同时通过在云端并行,目前每天可以自动生成一万多个仿真测试用例。
简单理解,前面的数据诊断其实是一种数据标注自动化,而云端语义场景自动化转化,就是一种流水线生产测试场景的工具。
天下武功,无坚不摧,唯快不破。
自动驾驶也是如此,毫末智行参得最透。
数据大而多,处理快且准,一切以此为纲,才有了毫末不可思议的量产上车速度。
从技术看毫末智行
毫末智行内部把董事长张凯、CEO顾维灏称作测试狂,每周都要花大量时间亲自测试智能驾驶产品。
品牌日现场,董事长张凯也提到了长城汽车内部更是重视智能化,每周六都要求技术负责人、各公司高管必须参加智能化体验测试。
不光是自家产品,市场上每一款产品都要体验对比,有时魏建军还会亲自参加。

毫末的硬核技术底色尽显。
同时张凯还说,规模上量速度最重要,自动驾驶公司2022年前还找不到规模化落地路径的,无疑是致命的。
那么毫末到底是一家什么样的公司?
进展迅猛和打磨技术,在毫末这里其实一脉相承,丝毫不矛盾。
毫末智行为什么中意Transformer?
上个月的特斯拉AI Day,马斯克首次明确推出DOJO、并分享Transformer和大模型之于自动驾驶作用。
殊不知,类似思路在中国早有毫末智行团队在践行。
Q3品牌日上,我们看到Transformer已经成为了毫末重要的开发工具。
其实在毫末智行第一次公开亮相时,CEO顾维灏就表达了对Transformer的格外关注。
随后在公开场合也不断提及。
顾维灏认为,自动驾驶行业现状是传感器供应商、方案趋同,仅靠硬件堆料拉不开差距。
所以未来的决胜点一定在数据,数据多是前提,数据好是基础。
如果时常关注AI技术前沿的一定有所了解,Transformer最早是进行语言处理任务的,具有避免循环 (recurrent) 的模型结构,完全依赖于注意力机制对输入输出的全局依赖关系进行建模。
也就是说,只需要数据足够大,就能训练一个超大的模型。
近两年,Transformer的对图像识别的准确率、效率、鲁棒性不断刷新各种榜单,一骑绝尘。
这是真·大力出奇迹,因为这种方法要求庞大的数据集,恰好与毫末智行的数据采集、泛化的优势完美match。
为什么自动驾驶在云端决胜负?
谈到毫末智行自研的算力平台ICU 3.0时,顾维灏说现在有观点认为车端算力已经达到几个T,完全够用了。
但毫末却从实践中得出了完全不一样的结论。
单从摄像头来看,今天汽车主流的摄像头还是100万像素的,而即将搭载毫末智能驾驶系统的长城车型,即将开始使用200万像素和800万像素摄像头。
所以为长久计,长城汽车、毫末智行共同联合高通推出了目前全球算力最高的可量产自动驾驶计算平台ICU 3.0(即毫末智行“小魔盒3.0”)。
平台采用8450和9000芯片,算力高,缓存大,推理快,路数多,延迟低,覆盖广,好部署。大缓存这使得芯片可以同时支撑多个高分辨率的视频流进行实时感知推断。

毫末把多任务感知网络部署在高通芯片上,主干网是优化后resnet50,基于这个主干做了一层多特征融合层,视觉摄像头和激光雷达数据分别通过网络提前3D感知结果,在BEV空间里面再融合毫米波雷达以及多帧关联。

这样后续的车道线和障碍物识别等任务就可以基于共同的特征要素进行,大大加快了识别速度。

但即使强如高通,车端算力也不无法永远增加下去。
在未来,车端单个摄像头的数据量可能还会增加100倍,而车端用的摄像头数量也会增加十几倍。
以此来看,车载计算芯片的算力再增加几百倍都是不够。
所以,大数据量带来大计算量,非云端不能解决。
前面讲到的服务(云)端大模型训练车端小模型,核心逻辑就在于此。
整个Q3品牌日,毫末智行所分享的技术细节可以看出,企业核心就是大数据大模型、快速迭代。
具体方法,是打开一个迅速落地上量的场景,然后根据场景特征设计自己的高效数据方案,避免在有限场地内经年累月测试,迟迟不能落地。

有了场景后,毫末智行走的是渐进式的商业化落地路线,智能驾驶从加强人向取代人发展。
毫末的“快”,背后既有毫末董事长张凯代表的长城基因,另一方面还有顾维灏这样中国最早在科技公司展开智能车探索的先驱。
这种行业罕见的强力配置,共同决定了毫末“最懂量产的自动驾驶公司”的底色。
以上是关于中国最懂自动驾驶量产公司秀肌肉:自动驾驶算力怪兽百亿参数云端超大模型百万公里路测里程...的主要内容,如果未能解决你的问题,请参考以下文章