Flink流处理随笔(上)
Posted HUTEROX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink流处理随笔(上)相关的知识,希望对你有一定的参考价值。
文章目录
Flink 基本处理流程(上)
目前对于我对flink的基本的一个流程的了解来看的话,对于Flink其实的流处理我们其实完整的步骤只需要大概四步。
1.对数据的读取
2.对数据的筛选
3.对数据的处理,也就是这个数据的处理
4.对数据的分类
其实在总结一下其实就两大块,数据读取,数据处理,只是在数据处理这一块我们又可以细分几大块
我们可以继续回到那个最经典的程序(当然这个并不是流处理模式,不过都是一样的)
package com.java;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class HelloOffline {
public static void main(String[] args) throws Exception{
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();//创建环境
//读取数据逐行读取
DataSource<String> data = env.readTextFile("F:\\\\FlinkDome1\\\\src\\\\main\\\\resources\\\\Hello.txt");
//数据处理
FlatMapOperator<String, Tuple2<String, Integer>> dataout = data.flatMap(new MyFunction());
//数据聚类处理(分组,求和)
AggregateOperator<Tuple2<String, Integer>> sum = dataout.groupBy(0).sum(1);
//输出
sum.print();
}
public static class MyFunction implements FlatMapFunction<String,Tuple2<String,Integer>> {
@Override
//如何对数据进行处理,这里是把数据返回成一个数组,输入String,输出Tuple2<String,Integer>
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] worlds = s.split(" ");
for(String world:worlds){
collector.collect(new Tuple2<>(world,1));//输出处理好的数据
}
}
}
}
那么我们接下来就来我们按照流程来说一说这几大块的流程怎么玩。
也就是说对这几个模块部分经行细分。
数据读取
首先明确一点我们是基于流处理环境来进行的,也就是**StreamExecutionEnvironment**
直接读取文件
这个没什么好说的。
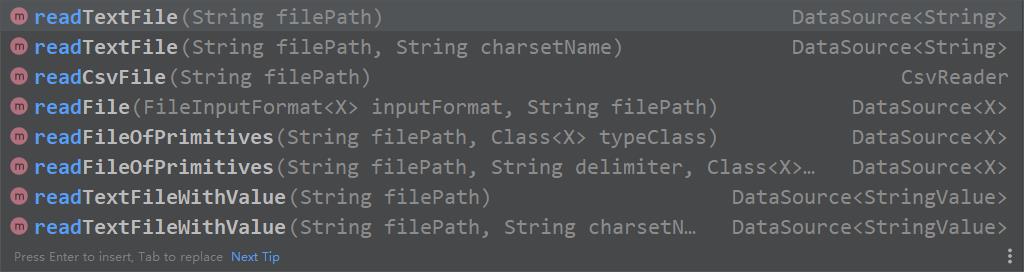
这里面的API看参数就知道怎么搞了。
从列表当中读取文件

这里主要使用fromCollection
现在做个小小的演示。
现在我们简单的搞一下,我们现在统计一下,学生的一些信息。
1.创建学生类
package com.java; public class Student { public Student(){ } public Student(String name, Integer age, double height) { this.name = name; this.age = age; this.height = height; } private String name; private Integer age; private double height; public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public double getHeight() { return height; } public void setHeight(double height) { this.height = height; } @Override public String toString() { return "Student{" + "name='" + name + '\\'' + ", age=" + age + ", height=" + height + '}'; } } //这里那啥重写一下那个toString方法,不然输出的是地址2.我们现在这样做,我们先把数据写死,只是单纯的读取一下内容。
package com.java; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Arrays; public class CollectionClass { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<Student> studentdata = env.fromCollection(Arrays.asList( new Student("小明", 20, 195), new Student("小李", 21, 192), new Student("小王", 22, 175), new Student("小夏", 20, 195) )); //我们来计算一下年龄相同的小伙子的总部身高。 SingleOutputStreamOperator<Student> sum = studentdata.keyBy("age").sum("height"); sum.print(); env.execute(); } }
结果
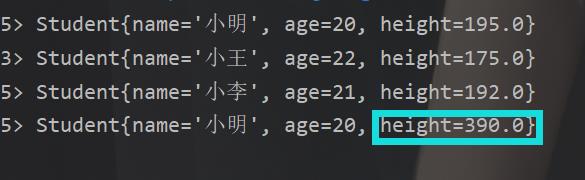
补充
这里先补充一下那个keyby()方法和sum()方法,我这里是直接把student里面的属性名给他了,然后他自己通过一套机制,毕竟传过来的时候其实那个学生类的地址已经传过来,做个反序列化什么的是可以拿到值的。
那么也还可以换个写法,只是不方便。
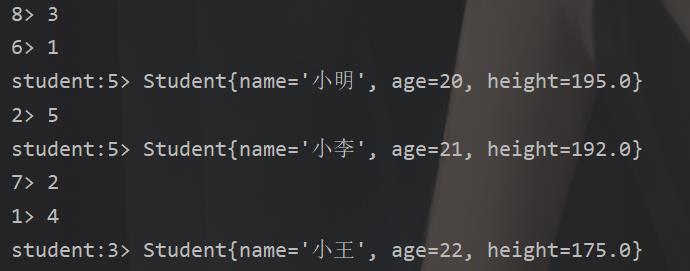
SingleOutputStreamOperator<Student> sum = studentdata.keyBy(Student::getAge).sum("height"); //sum不能这样
当然除此之外还有个那个fromElements,这个看看就好

结果:
从socket读取网络数据
这个早就在先前的博客当中演示过了,这里就不做过多的二次描述了。
DataStreamSource<String> stringDataStreamSource = env.socketTextStream("localhost",7777);
从Kafka读取数据
这个惭愧,目前手头上没有东西演示不了,暂时也接触不到,但是搞这个还是简单的,也一样就两个步骤
1.添加Kafka依赖。
<groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.11_2.12</artifactId> <version>1.10.1</version>这里说一下目前我当前项目的配置(按道理应该是没问题的,先前踩的坑不少了)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>FlinkDome1</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.21</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId> org.apache.cassandra</groupId>
<artifactId>cassandra-all</artifactId>
<version>0.8.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
</project>
这个还是很重要的,我先前把平台迁移回windows就是出现这个问题了。然后注意Java版本,先前的是14的真的坑,强行换回8。
2.使用addSource()这个方法去实现一个kafka的接口,还是很简单的,就是换个数据源罢了,操作还是一样的。那么关于addSource()这个就是我们读取数据的重中之重了。
addSource自定义数据源
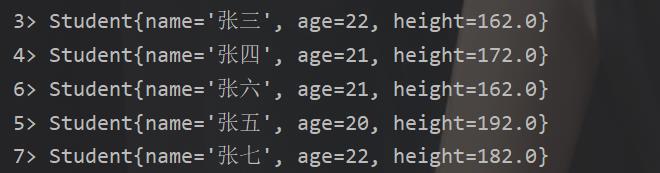
这个我们对刚才的的那个从列表读取数据做个处理,我们把相关的学生信息写到一个文件里面,然后我们返回Student()类
package com.java;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.io.BufferedReader;
import java.io.FileReader;
public class MyAddSource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Student> studentDataStreamSource = env.addSource(new MySource());
studentDataStreamSource.print();
env.execute();
}
public static class MySource implements SourceFunction<Student> {
@Override
public void run(SourceContext<Student> sourceContext) throws Exception {
//读取数据
BufferedReader reader = new BufferedReader(new FileReader("F:\\\\FlinkDome1\\\\src\\\\main\\\\resources\\\\Student.txt"));
String line = reader.readLine();
while (line!=null){
String[] args = line.split(" ");
sourceContext.collect(new Student(args[0],new Integer(args[1]),new Double(args[2])));
line = reader.readLine();
}
reader.close();
return;
}
@Override
public void cancel() {
//停止的标准,我们这里自己会停下就没必要写了
}
}
}

结果
数据处理
map与flatmap的区别
这是个大头了,也是比较重要的。
这块我们先来说说单纯的数据来一个数据处理一个数据的方式。这里主要有两个一个是map 还有一个是flatmap()
至于怎么用首先flatmap就不再做介绍了,前面的例子太多了。那么我们先简单说说map()这个玩意,这玩意有什么特点,这里就做个对比,因为功能几乎一样,只是有些许差别。
先来看看map

再来看看flatmap()
```java`
public static class MyFunction implements FlatMapFunction<String,Tuple2<String,Integer>> {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] worlds = s.split(" ");
for(String world:worlds){
collector.collect(new Tuple2<>(world,1));
}
}
}
直接看到返回类型你就发现不一样
1.前者返回object换句话说,你基本上输入什么类型就输出一个object.
2.后者,我的输出是完全自定义的,在这里我定义了一个元组,此外这里有个叫采集器的玩意,也就是说,我的数据
在flatmap()里面其实可以做个’停留‘,而前者直接返回。
所以发现了么,前者返回数据return 那么返回了就结束了当前数据处理,
但是后者是使用采集器,换句话说,在当前我通过采集器发送出一个数据并不意味着我当前的这个数据处理完了!
也就是前者,一个数据对应一个数据(或者数据类型)的输出,但是后者可不是,我可以输出多个!
那么对应map还是举个例子:
package com.java;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.io.BufferedReader;
import java.io.FileReader;
public class MyAddSource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Student> studentDataStreamSource = env.addSource(new MySource());
SingleOutputStreamOperator<Object> map = studentDataStreamSource.map(new MapFunction<Student, Object>() {
@Override
public Object map(Student student) throws Exception {
return new Tuple2<Integer, Double>(student.getAge(), student.getHeight());
}
});
map.print();
env.execute();
}
public static class MySource implements SourceFunction<Student> {
@Override
public void run(SourceContext<Student> sourceContext) throws Exception {
//读取数据,返回身高,年龄的元组
BufferedReader reader = new BufferedReader(new FileReader("F:\\\\FlinkDome1\\\\src\\\\main\\\\resources\\\\Student.txt"));
String line = reader.readLine();
while (line!=null){
String[] args = line.split(" ");
sourceContext.collect(new Student(args[0],new Integer(args[1]),new Double(args[2])以上是关于Flink流处理随笔(上)的主要内容,如果未能解决你的问题,请参考以下文章