Flink学习随笔(项目结构预览&HELLO DOME )
Posted HUTEROX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink学习随笔(项目结构预览&HELLO DOME )相关的知识,希望对你有一定的参考价值。
环境
系统:ubuntu 20
java : open-java 11( 为了支持vscode 插件)
IDE: IDEA2021.2
设备:DELL G5-5590 8x inter 16GB RAM
准备阶段
1.打开IDEA 创建 MAVEN 项目
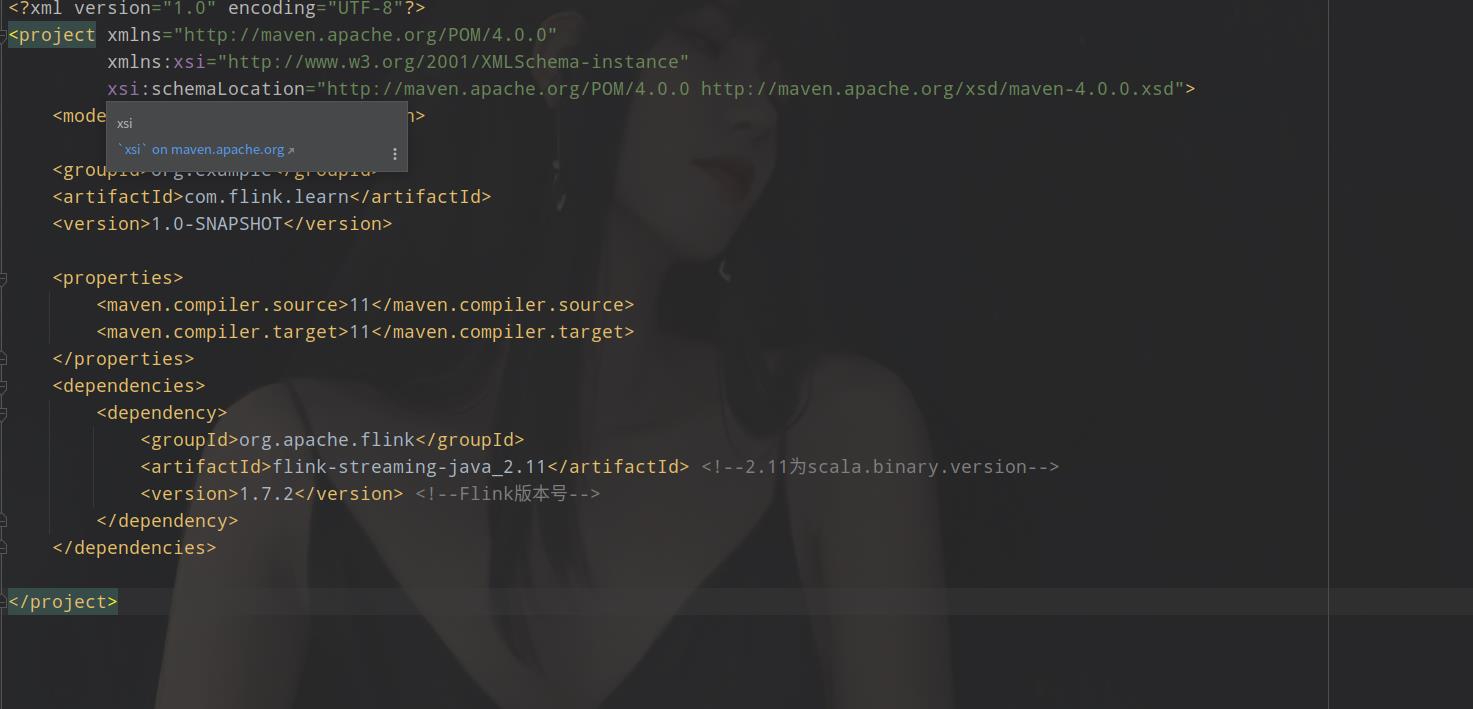
2.编辑 opm.xml 配置文件
3.添加依赖(也就是配置MAVEN,安装FLINK 的依赖)
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId> <!--2.11为scala.binary.version-->
<version>1.7.2</version> <!--Flink版本号-->
</dependency>
</dependencies>
在opm.xml当中添加这样的配置信息。
5.刷新,点击右上角的MAVEN然后点击刷新,他会自己安装依赖包。
等待。
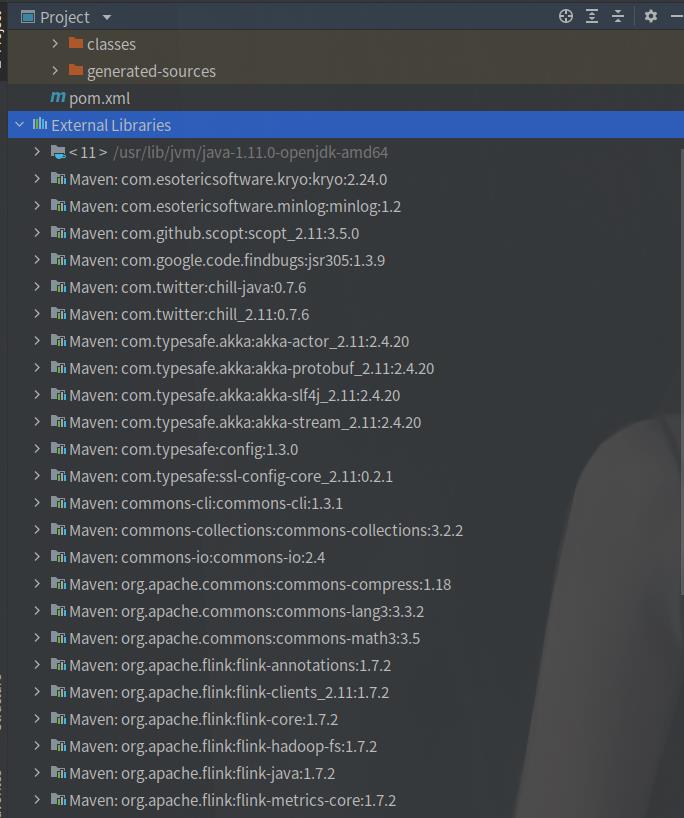
6.查看依赖是否安装好
FLINK 的 HELLO WORLD
第一个HEELO WORLD 的作用其实很简单,那就是统计以下一个文件当中出现的单词的次数,也就是统计单词频率,这个和我以前在那个python 爬虫数据可视化的时候很像。
那么在 FLINK 当中还是有两大种数据处理方式的一个还是类似于spark的 micro batch 还有一个就算真正意义上的流处理,这个在接下来的dome的演示当中是很明显的。
块处理
我们创建个文件也就是需要被处理的文件
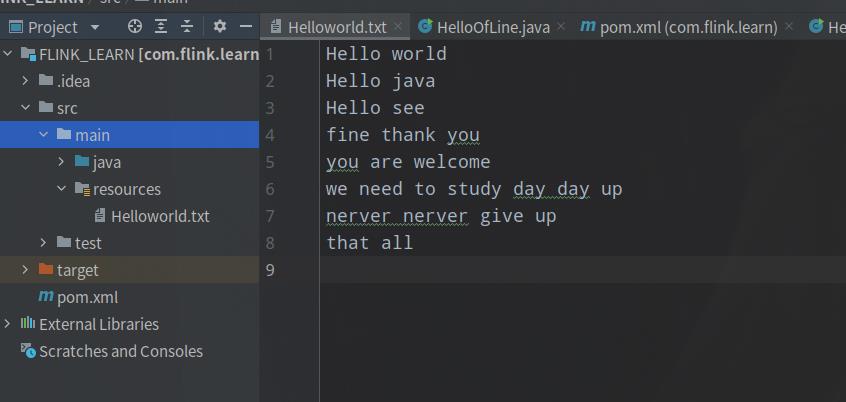
那么接下来看代码就好了,每一步都有注释,说明我这里就不再解释了,(为了学习英语,我的注释使用英文注释,英语比较菜,见谅!)
package com.java;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class HelloOfLine {
//This API just for data which off-line
public static void main(String[] args) throws Exception {
//creat run environment and environment is batch processing !
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//this environment is give us for better to use flink
//use flink to read data file in resources
String inputPath = "/home/huterox/CODE/JAVA/FLINK_LEARN/src/main/resources/Helloworld.txt";
DataSource<String> inputstraemdata = env.readTextFile(inputPath); // now we have a really to read file data
//but we want to count data number so we need to do something make data like (key,nmber)
//this function maybe like python map ,but we need to send a class for that
AggregateOperator<Tuple2<String, Integer>> outputcount = inputstraemdata.flatMap(new MyFlatMap())
.groupBy(0).sum(1);//we group tuple by first element and sum secnend element last we print it
outputcount.print();
}
//defind a class for flatmap to make data like (key,number)
public static class MyFlatMap implements FlatMapFunction<String, Tuple2<String,Integer>>{
//ok the String is we input data the Tuple2 is output data which want to out
//this class is like map function in python but in there you need implements FlatMapFunction
//yet this class must be static type!
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
//new we split string by space
String[] words = s.split(" ");
//and then we need out the data
for(String word:words){
collector.collect(new Tuple2<>(word,1));
}
}
}
}
这里主要就是创建环境,也就是用哪一中哪一种方式处理。
然后读取数据
我们使用flatmap()这个函数来处理数据我们返回(单词,1)这样的数据结构(处理好之后)
之后我们在对数据分组,求和。
还一句话来说就是flatmap()是做数据处理,处理好之后的操作就是数据运算部分
对于flatmap()这个函数我们要传入一个类,这个就相当于过滤函数。代码里面有说明
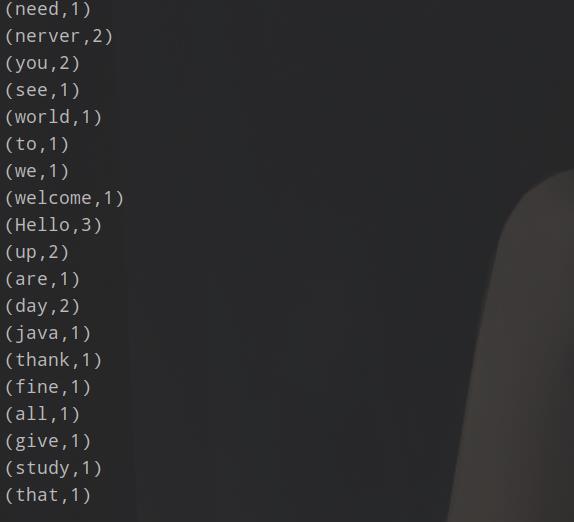
结果
流处理
基于有界数据的流处理
这个有界的意思是说,那个数据有有固定大小的,还句话说就是相当于直接读取本地的文件,文件是指导大小的。
package com.java;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class HelloStream {
public static void main(String[] args) throws Exception{
//now we shou StreamExectionEnvironment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//we also do something like Class HelloOffLine Function
//this process just defind how to do when stream coming!
String inputstream = "/home/huterox/CODE/JAVA/FLINK_LEARN/src/main/resources/Helloworld.txt";
DataStreamSource<String> stringDataStreamSource = env.readTextFile(inputstream);
SingleOutputStreamOperator<Tuple2<String, Integer>> outputStream = stringDataStreamSource.flatMap(new HelloOfLine.MyFlatMap()).keyBy(0).sum(1);
outputStream.print();
//with different batch processing the stream processing need event trigger!
env.execute();
}
}
这个其实后面那个处理是一样的,也就是环境不同
无界的流处理
这个就很符合实际的情况,那么实际处理也简单,就是把接收数据那一边改一下,读取从网络上读取。
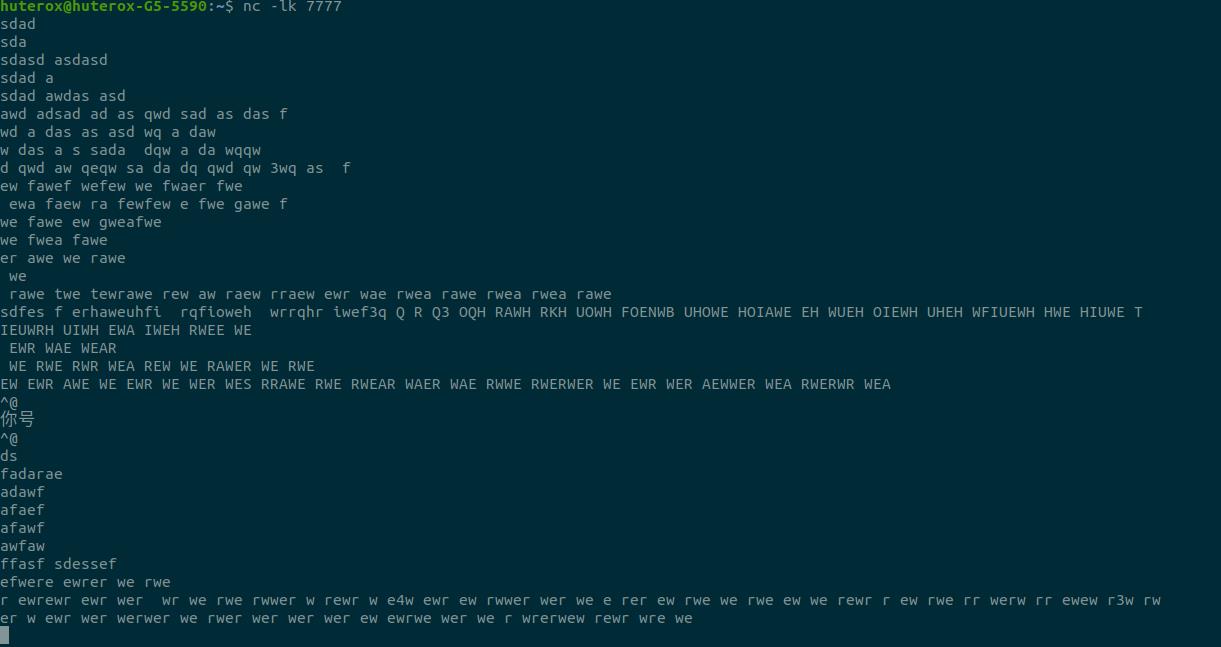
我启动了nc实时发送数据
那我这边处理就是
DataStreamSource<String> stringDataStreamSource = env.socketTextStream("localhost",7777);
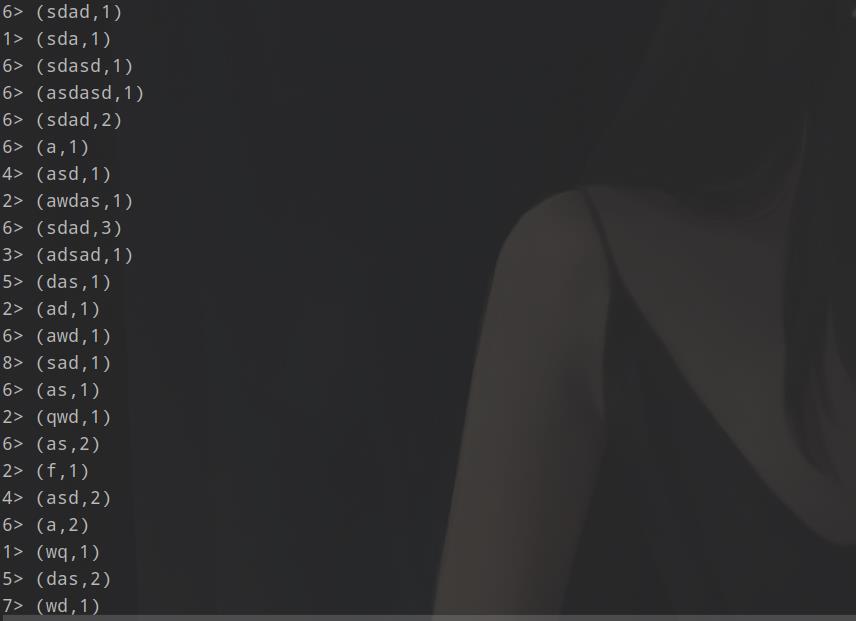
结果:
对比
通过结果都可以发现后面那个多了个 2> 这样的东西,这个其实就是节点,哪个节点返回的。当然我现在是单机的,这个是模拟的,我的电脑是8核心的,所以默认开启八个并行模拟节点。
优化
通过设置参数启动,这个和python 的sys.args类似.我们自己输入主机和端口运行.
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
Integer port = parameterTool.getInt("port");
DataStreamSource<String> stringDataStreamSource = env.socketTextStream(host,port);
以上是关于Flink学习随笔(项目结构预览&HELLO DOME )的主要内容,如果未能解决你的问题,请参考以下文章