华人团队用Transformer做风格迁移,速度快可试玩,网友却不买账
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了华人团队用Transformer做风格迁移,速度快可试玩,网友却不买账相关的知识,希望对你有一定的参考价值。
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
选自丨机器之心 杜伟
利用神经网络进行风格迁移是一项非常常见的任务,方法也很多,比如基于优化和基于 RL 的方法。最近,来自百度 VIS 团队的研究者提出了一种基于 Transformer 的风格迁移框架,速度快于基线方法,实现效果也不错。然而,研究遭到了网友的质疑,这是为什么呢?
在图像渲染领域,神经绘画(Neural painting)指的是为一张给定图像生成一系列笔画(stroke),并借助神经网络对其进行非真实性重建。如下图第一行每张图像的左下角为真实图像,以及重建后的非真实图像;第二行为渐进的绘画过程。

对于神经绘画任务,虽然基于强化学习(RL)的智能体可以一步步地生成笔画序列,但训练一个稳健的 RL 智能体并不容易。另一方面,笔画优化方法在一个大的搜索空间中迭代地搜索一系列笔画参数。因此,这种低效率的搜索方法极大地限制了基于 RL 方法的泛化性和实用性。
上个月,在一篇 ICCV 2021 Oral 论文中,来自百度 VIS 团队和罗格斯大学等机构的研究者将神经绘画视作一个集合预测问题,提出了全新的、基于 Transformer 的框架——Paint Transformer,从而利用前馈网络来预测笔画集合的参数。就其效果而言,研究者提出的模型可以并行地生成一系列笔画,并几乎能够实时地得到尺寸为 512×512 的重建绘画。
更重要的是,由于训练 Paint Transformer 没有可用的数据集,研究者设计了一个自训练的 pipeline,这样既可以在不使用任何现成数据集的情况下训练,又依然能够实现极好的泛化能力。实验结果表明,Paint Transformer 在训练和推理成本更低的情况下,实现了较以往方法更好的性能。

论文地址:https://arxiv.org/pdf/2108.03798.pdf
项目地址:https://github.com/wzmsltw/PaintTransformer
研究者在 Hugging Face 上提供了一个试玩界面,用户只需上传图像即可生成动态重建过程和重建后的绘画。小编也尝试上传了一张图像,生成效果如下所示:

原图与重建后的绘画。
动态重建过程如下:

试玩地址:https://huggingface.co/spaces/akhaliq/PaintTransformer
不过,虽然 Paint Transformer 的效果不错,但一些 reddit 网友似乎并不买账。有人认为,「这么简单的任务根本不需要使用机器学习或神经网络来解决。」

更有网友表示,「我曾使用 Processing,仅用 50 行 Scala 代码就实现了类似的结果。」

方法
研究者将神经绘画视作一个渐进的笔画预测过程。在每一步并行地预测多个笔画,以前馈的方式最小化当前画布和目标图像之间的差异。就其结构而言,Paint Transformer 由两个模块组成,分别是笔画预测器(Stroke Predictor)和笔画渲染器(Stroke Renderer)。

图 2Paint Transformer 的自训练 pipeline。
如上图 2 所示,给定一张目标图像 I_t 和中间画布图像 I_c,笔画预测器生成一系列参数以确定当前笔画集合 S_r。接着,笔画渲染器在 S_r 中为每个笔画生成笔画图像,并将它们画在画布 I_c 上,从而生成结果图像 I_r。这一过程可以用以下公式(1)来描述:

在 Paint Transformer 中,只有笔画预测器包含可训练的参数,而笔画渲染器是无参数和可微的模块。为了训练笔画预测器,研究者提出了一个利用随机合成笔画的自训练 pipeline。
笔画定义与渲染器
该研究主要考虑了直线笔画,这种笔画可以通过形状参数和颜色参数来表征。如下图 3 所示,一个笔画的形状参数包括:中心点坐标 X 和 Y,高度 h,宽度 w 和渲染角θ。
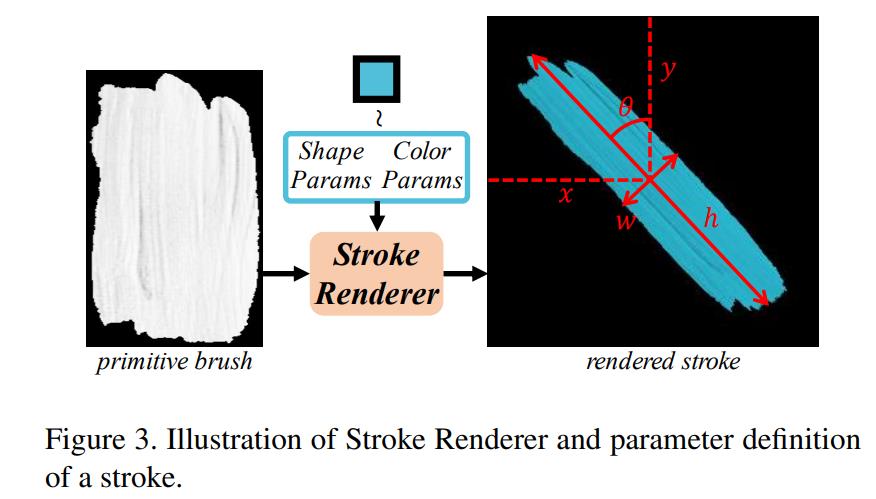
笔画渲染器和参数定义。
对于神经绘画任务而言,可微渲染是基于笔画参数合成笔画图像并由此实现笔画预测器端到端训练的一个重要问题。但是,对于该研究中的特定笔画定义,研究者没有采用神经网络,而是使用了基于笔画渲染器的几何变换,从而如预期一样不需要训练并且是可微的。笔画渲染器可以用以下公式(3)来描述:
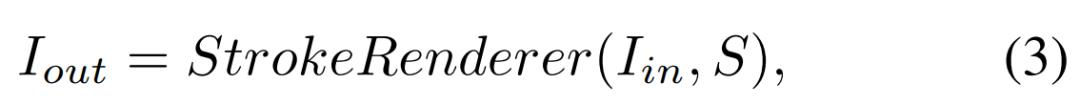
笔画预测器
笔画预测器的目标是为了预测一系列「cover 中间画布图像和目标图像之间差异」的笔画。此外,为了达到可以模拟真实绘画过程的抽象程度,研究者希望笔画预测器在预测很少笔画的同时,依然可以 cover 大部分的差异区域。
为了实现这一目标,他们在 DETR 的启发下,提出了一个基于 Transformer 的预测器。该预测器输入 I_c 和 I_t,生成一个笔画集合,可以用以下公式(5)来描述:

如下图 4 所示,笔画预测器以 I_c 和 I_t ∈ R^3×P ×P 作为输入,首先采用两个独立的卷积神经网络来提取它们的特征映射 F_c 和 F_t ∈ R^C×P/4×P/4。

损失函数
研究者介绍了像素损失、笔画之间差异的测量以及笔画损失。
首先是像素损失。神经绘画的一个直观目标是重新创建目标图像。因此,I_r 和 I_t 之间的像素损失 L_pixel 在图像级别受到惩罚:

然后是笔画损失。训练期间,有效真值笔画的数量是变化的。因此,按照 DETR,在预定义最大笔画数 N 的情况下,研究者首先需要在 N 笔画的预测集 ¯S_r 和真值集 S_g 之间生成匹配机制以计算损失。
推理
为了模仿人类画家,研究者设计了一种从粗到精(coarse-to-fine)的算法,在推理过程中生成绘画结果。Paint Transformer 的推理算法如下所示:

实验
定性比较。如下图 5 所示,研究者将 Paint Transformer 分别与基于优化和基于强化学习的 SOTA 笔画绘画生成方法进行了比较。其中,相较于基于优化的方法,Paint Transformer 可以生成渲染力更强、更清晰的结果。不过,Paint Transformer 的生成效果明显不如基于强化学习的方法。

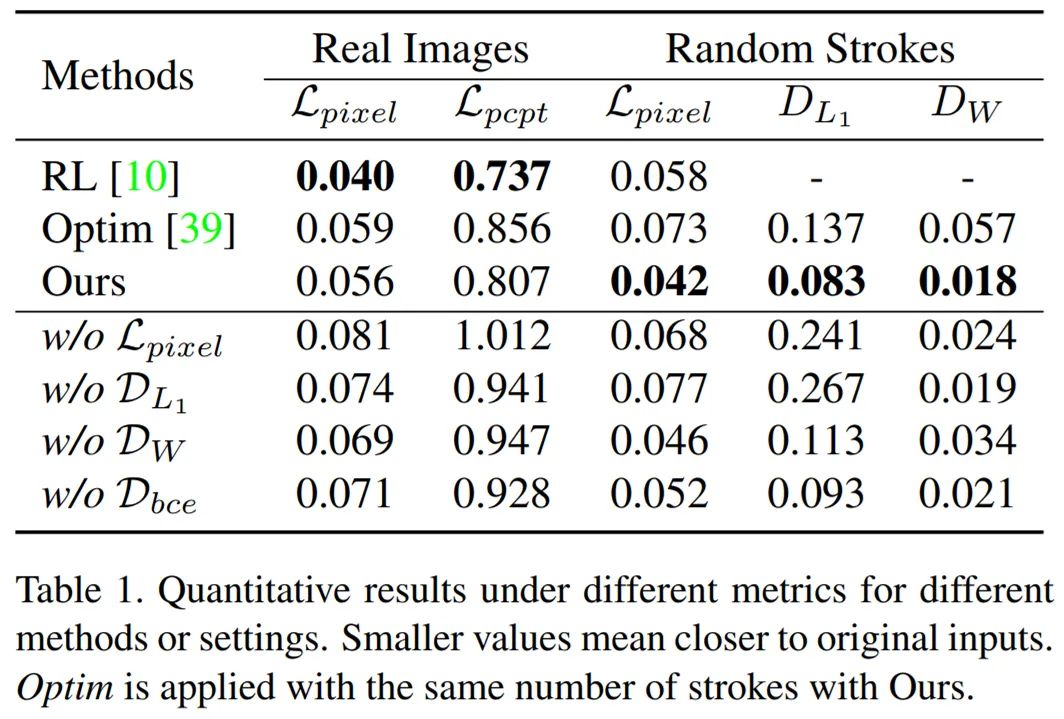
定量比较。如下表 1 所示,定量比较的结果与定性比较保持一致。借助生动的画笔纹理,Paint Transformer 能够较基于优化的方法更好地表征原始内容。Zhewei Huang 等人论文《 Learning to paint with model-based deep reinforcement learning 》中提出的方法实现了最佳内容保真度,但在抽象处理上较弱。
数值结果表明,Paint Transformer 可以成功地预测笔画,并优于其他方法。
效率比较。如下表 2 所示,研究者在一个英伟达 2080Ti 上评估了训练与推理时间。在推理期间,Paint Transformer 以前馈的方式并行地生成一系列笔画,因而运行速度明显快于优化基线方法,也略快于强化学习基线方法;对于训练而言,研究者仅需要几个小时就可以训练一个笔画预测器,从总训练时长方面比基于优化和强化学习的方法更方便。并且,无模型笔画渲染器和无数据笔画预测器可以高效和方便地使用。

消融实验结果如下图 6 所示:

风格化绘画。Paint Transformer 可以方便地与艺术风格迁移方法融合,从而生成更吸引人和风格化的绘画。研究者使用 LapStyle 和 AdaAttN 等现有风格迁移方法,在风格化内容图像上生成自然的绘画。如下图 8 所示,借助这种富有想象力的方式,研究者生成了具有丰富颜色和纹理的风格化绘画。

更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!
© THE END
投稿或寻求报道微信:MaiweiE_com
GitHub中文开源项目《计算机视觉实战演练:算法与应用》,“免费”“全面“”前沿”,以实战为主,编写详细的文档、可在线运行的notebook和源代码。


项目地址 https://github.com/Charmve/computer-vision-in-action
项目主页 https://charmve.github.io/L0CV-web/
推荐阅读
(更多“抠图”最新成果)
迈微AI研习社
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve

如果觉得有用,就请点赞、转发吧!
以上是关于华人团队用Transformer做风格迁移,速度快可试玩,网友却不买账的主要内容,如果未能解决你的问题,请参考以下文章