[Spark精进]必须掌握的4个RDD算子之mapPartitions算子
Posted manor的大数据奋斗之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Spark精进]必须掌握的4个RDD算子之mapPartitions算子相关的知识,希望对你有一定的参考价值。
返回第一章
第二个mapPartitions:以数据分区为粒度的数据转换
按照介绍算子的惯例,我们还是先来说说 mapPartitions 的用法。mapPartitions,顾名思义,就是以数据分区为粒度,使用映射函数 f 对 RDD 进行数据转换。对于上述单词哈希值计数的例子,我们结合后面的代码,来看看如何使用 mapPartitions 来改善执行性能:
// 把普通RDD转换为Paired RDD
import java.security.MessageDigest
val cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码
val kvRDD: RDD[(String, Int)] = cleanWordRDD.mapPartitions( partition => {
// 注意!这里是以数据分区为粒度,获取MD5对象实例
val md5 = MessageDigest.getInstance("MD5")
val newPartition = partition.map( word => {
// 在处理每一条数据记录的时候,可以复用同一个Partition内的MD5对象
md5.digest(word.getBytes).mkString
})
newPartition
})
可以看到,在上面的改进代码中,mapPartitions 以数据分区(匿名函数的形参 partition)为粒度,对 RDD 进行数据转换。具体的数据处理逻辑,则由代表数据分区的形参 partition 进一步调用 map(f) 来完成。你可能会说:“partition. map(f) 仍然是以元素为粒度做映射呀!这和前一个版本的实现,有什么本质上的区别呢?”
仔细观察,你就会发现,相比前一个版本,我们把实例化 MD5 对象的语句挪到了 map 算子之外。如此一来,以数据分区为单位,实例化对象的操作只需要执行一次,而同一个数据分区中所有的数据记录,都可以共享该 MD5 对象,从而完成单词到哈希值的转换。
通过下图的直观对比,你会发现,以数据分区为单位,mapPartitions 只需实例化一次 MD5 对象,而 map 算子却需要实例化多次,具体的次数则由分区内数据记录的数量来决定。
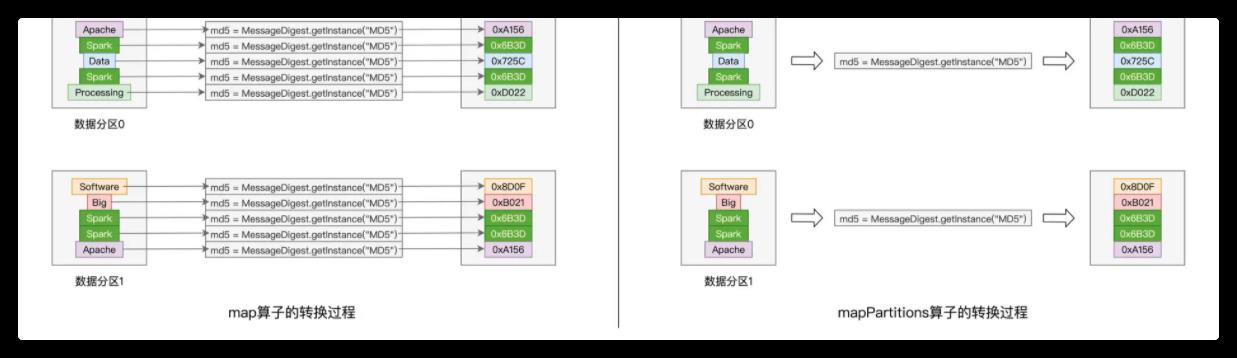
对于一个有着上百万条记录的 RDD 来说,其数据分区的划分往往是在百这个量级,因此,相比 map 算子,mapPartitions 可以显著降低对象实例化的计算开销,这对于 Spark 作业端到端的执行性能来说,无疑是非常友好的。
实际上。除了计算哈希值以外,对于数据记录来说,凡是可以共享的操作,都可以用 mapPartitions 算子进行优化。这样的共享操作还有很多,比如创建用于连接远端数据库的 Connections 对象,或是用于连接 Amazon S3 的文件系统句柄,再比如用于在线推理的机器学习模型,等等,不一而足。你不妨结合实际工作场景,把你遇到的共享操作整理到留言区,期待你的分享。
相比 mapPartitions,mapPartitionsWithIndex 仅仅多出了一个数据分区索引,这个数据分区索引可以为我们获取分区编号,当你的业务逻辑中需要使用到分区编号的时候,不妨考虑使用这个算子来实现代码。除了这个额外的分区索引以外,mapPartitionsWithIndex 在其他方面与 mapPartitions 是完全一样的。
介绍完 map 与 mapPartitions 算子之后,接下来,我们趁热打铁,再来看一个与这两者功能类似的算子:flatMap。
点击跳转到下一讲
以上是关于[Spark精进]必须掌握的4个RDD算子之mapPartitions算子的主要内容,如果未能解决你的问题,请参考以下文章
[Spark精进]必须掌握的4个RDD算子之filter算子
[Spark精进]必须掌握的4个RDD算子之filter算子
[Spark精进]必须掌握的4个RDD算子之flatMap算子
[Spark精进]必须掌握的4个RDD算子之flatMap算子