❤️ 详解KMP算法
Posted 陈子青 :See
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️ 详解KMP算法相关的知识,希望对你有一定的参考价值。
由于KMP算法描述起来很抽象,所以很多人难以理解,那么这篇博客将帮你解决这个难题,带你彻底了解KMP的原理以及实现。
KMP算法是一种改进的字符串匹配算法,KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next数组实现,next数组本身包含了模式串的局部匹配信息。算法时间复杂度 O(m+n)
举个栗子,如
给定一个长度为 m 的模式串 S,以及一个长度为 n 模板串 P,判断 P 是否是 S 的字串
要想真正了解KMP算法,首先要来研究下朴素的匹配算法。
朴素模式匹配怎么做呢 ?
朴素的匹配其实很好理解,但为了后面更好的理解KMP算法,这里还是需要做一下图解

依次类推,有两种情况发生
①

②

文字描述
步骤 1:从 S 的第一个字符开始与 P 的第一个字符比较 ,如果相等则继续拿 S 的下一个字符开始与 P 的第二个字符比较,以此类推,如果P串达到末尾,那么 P 为 S 的字串。
步骤 2:如果出现不相等的情况,从 S 的第二个字符开始与 P 的第一个字符比较,如果相等则继续拿 S 的下一个字符开始与 P 的第二个字符比较,以此类推,如果P串达到末尾,那么 P 为 S 的字串。
步骤 3:如果 P串没有达到末尾,S却先到达末尾,那么 P 则不是 S 字串
算法实现
bool isMatch;
for (int i = 1; i + n - 1 <= m; i++) //字符串从下标为1的位置开始存储
{
isMatch = true;
for (int j = 1, k = i; j <= n; j++, k++)
{
if (s[k] != p[j])
{
isMatch = false;
break;
}
}
if (isMatch) break;
}我们可以看到朴素匹配的算法复杂度为O( n * m),那么有没有办法降低算法复杂度呢?
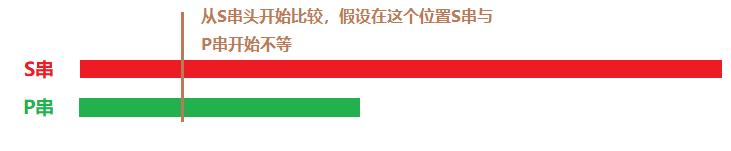
观察上述的图解(这里是关键)
此时可以看到第一次不相等的地方已经标了 标注了 棕色的小竖线 | ,表示S串与P串不相等的位置
那么,如果这一次能匹配成功的话,意味着什么呢?看图!


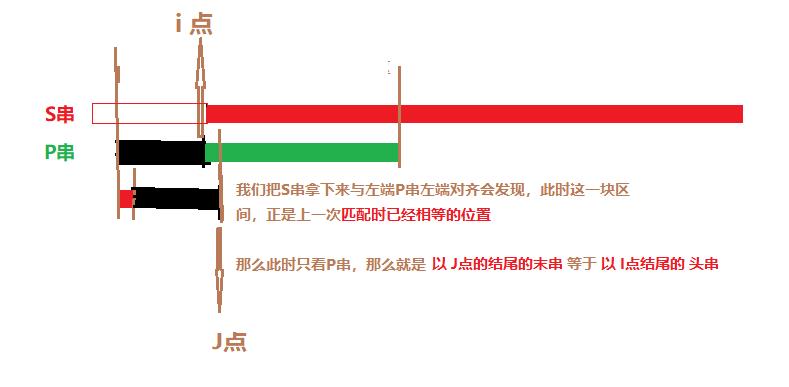
假设黑色部分不相等, 也就是 以 i点为结尾的头串 不等于 以 j点末串 ,显然这一次也不能匹配成功!那么就需要从S串的下下个位置开始比较。那如果 以 i点为结尾的头串 等于 以 j点末串 呢?
如果等于,显然 一直到 i点 都不需要再一次与S串比较,因为这一段已经是上一次匹配成功的了。这就是KMP的精髓所在。
那么说整个问题就变成了:只需要找到P串中 以 1~m 结尾的末串 分别和 哪一个 i 结尾的头串相等即可。 这样当 j+1点开始,P串与S串不相等时,只需要找到以 j点为结尾的末串 相等的 头串 i,从头串 i 的下一个位置开始与S串比较即可! 用以保存这些信息的就是 NEXT数组。
如何预处理next数组呢? 只需要 用P串的 与自己比较即可,开始位置是一定相等的 P[1] ==P[1],
为了使比较次数更少,next数组则是保存 以 j结尾 与 i开头相等的最长位置,但显然 i !=j,,否则就是自身与自身相等了,没意义。所以 P串一定要从第二个位置开始 与自身比较。
算法实现
//构建next数组
for(int i = 2, j = 0; i <= m; i++)
{
while(j && p[i] != p[j+1]) j = next[j];
if(p[i] == p[j+1]) j++;
next[i] = j;//每次移动 i 前,将 i 前面已经匹配的长度记录到next数组中
}next构建完毕,则开始 S串和P串的比较 ,方法几乎与构建next数组一致,因为构建next数组是自己与自己比较,而比较S和P 则是 不同的字符串比较。
算法实现
bool isMatch=false;
for(int i=1,j=0;i<=m;i++)
{
while(j && s[i]!=p[j+1]) j=ne[j];
if(s[i]==p[j+1]) j++;
if(j==n) //当j==n时则说明 P串最后一个字符已经和S串匹配,则P为S的字串
{
isMatch=true;
break;
}
}这么一看KMP并不复杂,读者理解之后,熟记代码即可。
最后感谢读者点赞支持!
以上是关于❤️ 详解KMP算法的主要内容,如果未能解决你的问题,请参考以下文章